SQL SERVER大话存储结构_数据行的行结构
Posted 苏家小萝卜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL SERVER大话存储结构_数据行的行结构相关的知识,希望对你有一定的参考价值。
一行数据是如何来存储的呢?
变长列与定长列,NULL与NOT NULL,实际是如何整理存放到 8k的数据页上呢?
对表格进行增减列,修改长度,添加默认值等DDL SQL,对行存储结构又会有怎么样的影响呢?
什么是大对象,什么是行溢出,存储引擎是如何处理它们呢?

如果转载,请注明博文来源: www.cnblogs.com/xinysu/ ,版权归 博客园 苏家小萝卜 所有。望各位支持!
本系列上一篇博文链接:SQL SERVER大话存储结构(2)_非聚集索引如何查找到行记录
1 引入
在一个DB内,每一个table都能在sys.sysobjects中找到对应的描述,每一个列,都能从sys.columns中找到说明。
这里发个SQL是日常管理中使用到的,用于描述一个表格的数据结构情况。


1 SELECT 2 3 表名 = CASE WHEN A.COLORDER=1 THEN D.NAME ELSE \'\' END, 4 表说明 = CASE WHEN A.COLORDER=1 THEN ISNULL(F.VALUE,\'\') ELSE \'\' END, 5 列序列号 = A.COLORDER, 6 列名 = A.NAME, 7 标识 = CASE WHEN COLUMNPROPERTY( A.ID,A.NAME,\'ISIDENTITY\')=1 THEN \'√\'ELSE \'\' END, 8 约束 = CASE WHEN EXISTS( 9 SELECT 1 10 FROM SYSOBJECTS 11 WHERE XTYPE=\'PK\' AND PARENT_OBJ=A.ID AND NAME IN ( 12 SELECT 13 NAME 14 FROM SYSINDEXES 15 WHERE INDID IN( SELECT INDID FROM SYSINDEXKEYS WHERE ID = A.ID AND COLID=A.COLID ) 16 ) 17 ) THEN \'PK\' 18 WHEN EXISTS ( 19 SELECT 1 FROM sys.foreign_key_columns 20 WHERE parent_object_id=A.ID AND parent_column_id=A.COLID 21 ) THEN \'FK\'+\'(\'+(SELECT OBJECT_NAME(referenced_object_id)+\'.\'+COL_NAME(referenced_object_id,referenced_column_id)+\')\' FROM sys.foreign_key_columns WHERE parent_object_id=A.ID AND parent_column_id=A.COLID) 22 ELSE \'\' END, 23 数据类型 = CASE WHEN B.NAME IN (\'CHAR\',\'NCHAR\',\'VARCHAR\',\'NVARCHAR\') THEN B.NAME+\'(\'+ISNULL(CAST(case when COLUMNPROPERTY(A.ID,A.NAME,\'PRECISION\')=-1 then null else COLUMNPROPERTY(A.ID,A.NAME,\'PRECISION\') end AS VARCHAR(10)),\'MAX\')+\')\' 24 WHEN B.NAME =\'DECIMAL\' THEN B.NAME+\'(\'+CAST(COLUMNPROPERTY(A.ID,A.NAME,\'PRECISION\') AS VARCHAR(10))+\',\'+CAST(ISNULL(COLUMNPROPERTY(A.ID,A.NAME,\'SCALE\'),0) AS VARCHAR(10))+\')\' 25 ELSE B.NAME END, 26 占用字节长度 = A.LENGTH, 27 --长度 = COLUMNPROPERTY(A.ID,A.NAME,\'PRECISION\'), 28 --小数位数 = ISNULL(COLUMNPROPERTY(A.ID,A.NAME,\'SCALE\'),0), 29 允许空 = CASE WHEN A.ISNULLABLE=1 THEN \'√\'ELSE \'\' END, 30 默认值 = case when E.TEXT is not null then 31 32 case when substring(e.text,1,2)=\'((\' then substring(e.text,3,len(e.text)-4) 33 when substring(e.text,1,1)=\'(\' then substring(e.text,2,len(e.text)-2) 34 else e.text end 35 else \'\' end , 36 列说明 = ISNULL(G.[VALUE],\'\') 37 FROM SYSCOLUMNS A LEFT JOIN SYSTYPES B ON A.XUSERTYPE=B.XUSERTYPE 38 INNER JOIN SYSOBJECTS D ON A.ID=D.ID AND D.XTYPE=\'U\' AND D.NAME<>\'DTPROPERTIES\' 39 LEFT JOIN SYSCOMMENTS E ON A.CDEFAULT=E.ID 40 LEFT JOIN sys.extended_properties G ON A.ID=G.major_id AND A.COLID=G.minor_id 41 LEFT JOIN sys.extended_properties F ON D.ID=F.major_id AND F.minor_id=0 42 WHERE D.NAME IN (\'area\',\'\',\'\') 43 ORDER BY A.ID,A.COLORDER

2 数据行
2.1 数据行结构
数据行在数据页面的存储结构详见下表,分为几个部分:基础信息4字节、定长列相关、变长列相关及null位图。详见下表。这部分的内容具体参考《SQL server技术内幕:存储引擎》第6章。
参考下图,一行数据的大小是这么计算的:Row_Size=Fixed_Data_Size+Variable_Data_Size+Null_Bitmap+4 。

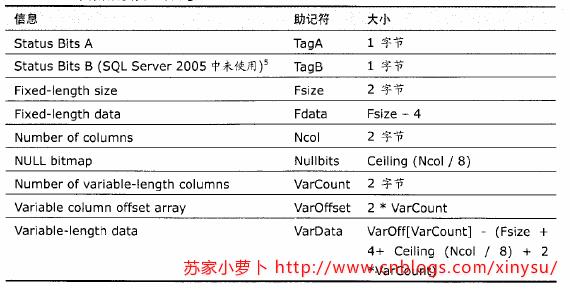
各个部分其实都比较好理解,状态B位未使用,状态A位,详细描述如下。
- 状态位A:表示行属性的位图,1字节,8bit
-
- Bit 0 位,版本信息
- Bits 1-3 位,行记录类型
-
- 0,primary record,主记录
- 1,forwarded record
- 2,forwarding stub
- 3,index record,索引记录
- 4,blob或者行溢出数据
- 5,ghost索引记录
- 6,ghost数据记录
- Bit 4 位,NULL位图
- Bit 5 位,表示行中有变长列
- Bit 6 位,保留
- Bit 7 位,ghost record(幽灵记录)
- 列偏移矩阵
-
- 如果一个表格,没有变长列,那么这个表格则不需要列偏移矩阵
- 一个变长列,有一个列偏移矩阵,一个列偏移矩阵2个字节,用于表示变长列中每个列的结束位置。
2.2 特殊情况(大对象、行溢出及forword)
2.2.1 大对象
text, ntext, image, nvarchar(max), varchar(max), varbinary(max), and xml这种数据列,称为大对象列, 注意,变长数据类型nvarchar,varchar,varbinary只有当存储内容大于8k才变为大对象列。
行不能跨页,但是行的部分可以移出行所在的页,因此行实际可能非常大。页的单个行中的最大数据量和开销是 8,060 字节 (8 KB)。考虑大对象列极为占用空间,所以在一行数据的主记录中,是不存储大对象列的,仅存储 16字节 指向 大对象列实际存储到LOB data页面的位置。
比如,一个大对象列text,text列存储5000的字符,其他列占用50个字符,如果是放在一起存储的话,10行数据就需要10个page,扫描就需要10次IO;而如果不放在一次,一个IN-ROW-DATA page就能存储这10行数据,text列单独存放在 LOB data列,那么,扫描这10行的主记录,仅需要1次IO。所以,大对象列是不跟主记录存储在一起。
这样,一个8k的数据页,就能尽可能多的存储主记录,可以在查询的时候,避免 大对象列占用主记录空间,导致IO次数增增加。
2.2.2 行溢出
超过 8,060 字节的行大小限制可能会影响性能,因为 SQL Server 仍保持每页 8 KB 的限制。当合并 varchar、nvarchar、varbinary、sql_variant 或 CLR 用户定义类型的列超过此限制时,SQL Server 数据库引擎 将把最大宽度的记录列移动到 ROW_OVERFLOW_DATA 分配单元的另一页上,然后在主记录记录一个24字节的指针,用与描述 被移出的列 实际存储位置。比如,一行数据总大小超过8k,那么在insert的过程中,会把最大宽度的记录移动到另外的数据页面。
如果更新操作使记录变长,大型记录将被动态移动到另一页。如果更新操作使记录变短,记录可能会移回 IN_ROW_DATA 分配单元中的原始页。此外,执行查询和其他选择操作(例如,对包含行溢出数据的大型记录进行排序或合并)将延长处理时间,因为这些记录将同步处理,而不是异步处理。
一行数据(不包括大对象列)总长度超过了8k,则会把最大宽度的列内容移动到ROW_OVERFLOW_DATA页面上,主记录上留下一个24字节的指针 描述 被溢出挪走的列内容 实际存储位置,这个称为行溢出。
2.2.3 forword
在一堆表内的一个数据页面,存储了N行数据,现在,其中一行数据的某一列发生修改,导致其列的长度加大,而剩余的页面空间无法存储该列数据,那么这个时候,就会把该列数据移动到新的 IN_ROW_DATA 页面上,在主记录留下一个 9个字节的 指针,指向实际列的存储位置,这个称之为 forword。
forward的条件是:堆表、变长列、更新操作及其数据页面剩余空间不足存储新列内容。
为什么一定要是堆表呢?因为如果是聚集索引表格,遇到这种情况,数据页会split,把一半的内容另外存储到新的数据页,由于聚集索引上的非聚集索引键值查询根据是主键,所以split操作不会影响到非聚集索引,但是堆表的非聚集索引结构查找行是根据RID,如果也split,那么所有非聚集索引都需要修改键值RID,故在堆表上,使用了forword。
为什么是更新操作呢?因为如果是INSERT操作,一开始就出现空间不足的情况,它老早就跑路到新的数据页上了,不会再空间不足的数据页面坐INSERT操作。
比如,一行数据原本存储在一个数据页面中,但是update某一列,增大其存储内容,发现该数据页没有空闲的空间可以存储该列内容,该列则会forword到另外的数据页IN_ROW_DATA存储,主记录留下一个9字节的指针。
3 测试存储情况
测试思路
- 先建立一个只有2列非空定长列的堆表,然后INSERT一行数据,检查page页面存储内容
- 添加主键,检查存储页面内容
- 增加一列:可空变长列
- 增加一列:非空变长列+默认值(分大对象和非大对象)
- 删除无数据的列
- 删除有数据的列
- 行溢出
- forword
3.1 堆表分析
create table tbrow(id int not null identity(1,1),name char(20) not null)
insert into tbrow(name) select \'xinysu\';
dbcc traceon(3604)
dbcc ind(\'dbpage\',\'tbrow\',-1)
--根据返回结果,判断324为数据页,如果不理解,请查看本系列第一篇博文
dbcc page(\'dbpage\',1,324,3)


查看 `消息` 内容,可以看到 slot 0 存储的行数据大小为21字节,由于现在的 tbrow表格中,只有两列 int 跟 char ,由于都是定长列,所有变长列的存储模块均为空,但是注意一点,即使整个表格都没有允许Null的列,Null位图仍然会占用一个字节。
所以 该行记录的长度=状态A+状态B+定长字段长度+定长字段内容+总烈属+null位图=1+1+2+(4+10)+2+1= 21 bytes。
根据行的16进制记录:10001200 01000000 78696e79 73752020 2020020000,来详细分析这行数据的存储情况。先把这串字符按照字节数区分,其中注意部分需要反序后再转换十进制。详细分析及推导见下图。

3.2 添加主键
alter table tbrow add constraint pk_tbrow primary key(id)
dbcc traceon(3604)
dbcc ind(\'dbpage\',\'tbrow\',-1)

可以看到,表格的IAM页及数据页全部都改变了,因为当一个堆表添加主键变为聚集索引表格的时候,需要重新组织数据页,按照聚集索引的键值顺序存储,所以看到,整个数据页存储情况发生了变化。如果是一个大堆表添加聚集索引,那么这是一个非常耗时及耗费IO、CPU的操作,并且会锁表直到操作结束,需谨慎操作。
再次来分析现在的行记录。
dbcc page(\'dbpage\',1,311,3)

可以看到,数据行的内容并没有发生变化,添加主键(聚集唯一索引),会重组整个表格的存储顺序,但是不会影响到行内的数据情况。
3.3 增加一列:可空变长列
alter table tbrow add constraint pk_tbrow primary key(id)
dbcc traceon(3604)
dbcc ind(\'dbpage\',\'tbrow\',-1)
dbcc page(\'dbpage\',1,311,3)


这里开始有趣了,发现,添加了一列可空可null的列后,行记录16进制并没有发生变化。对比如下。
/*
第一个行为堆表行记录
第二个行为添加主键后的行记录
第三个行为添加可空变长列后的行记录
10001200 01000000 78696e79 73752020 2020020000
10001200 01000000 78696e79 73752020 2020020000
10001200 01000000 78696e79 73752020 2020020000
*/
即使表格有为null的列,有变长的列,但是,只有这些列上没有值,是不会影响这一行的数据记录的,这非常重要!因为意味着,给一个表格添加可为空的列时,存储引擎不需要去修改表格内的行记录存储情况,只需要在数据字典上添加做变动即可,这需要获取到表格的架构锁,然后执行,这个执行速度非常快。
这一点的处理,跟mysql的处理极为不一样,虽然5.6添加了OnLine DDL,避免了DDL期间对表格锁表影响,但是处理添加列的时候,涉及表结构变动,需要新建临时文件来存储frm跟ibd文件,这是一个耗费IO的处理方式,详细可查看之前博文:MySQL Online DDL的改进与应用 。
3.4 增加一列:非空变长列+默认值
3.4.1 非大对象列
alter table tbrow add task varchar(20) not null default \'all A\' ;
dbcc traceon(3604)
dbcc ind(\'dbpage\',\'tbrow\',-1)
dbcc page(\'dbpage\',1,311,3)
查看16进制的行记录:10001200 01000000 78696e79 73752020 2020020000,发现与之前的是一样的,查看表格内容,设置了NOT NULL带默认值的列后,实际上,查询出来 task列是有值存储的,存储内容为 \'all A\',但是查看16进制内容的时候,却发现,这个数据页内的行记录存储内容并没有发生变化。

这是一个神奇的处理方式!为啥呢?
仔细查看page的解析内容,发现 :Slot 0 Column 4 Offset 0x0 Length 5 Length (physical) 0 。该列数据长度为5,但是,实际存储长度为0,也就是这一列压根没有存储在数据页面中。
个人推测:当添加了NOT NULL列+默认值(非大对象列)的情况下,不对以往数据存储记录发生修改,但是在查询的时候,会判断该列是否有存储数据,如果没有则使用默认值显示。 这样有一个非常大的好处:节约存储空间,不变更行记录,DDL期间,无需对以往记录做处理,仅需修改数据字典即可。
3.4.2 大对象列
alter table tbrow add descriptions text not null default \'i love sql server\' ;
dbcc traceon(3604)
dbcc ind(\'dbpage\',\'tbrow\',-1)

单薄的表格,一行的记录,因为添加了大对象列,来了个 LOB data的IAM页 以及 LOB data的数据页 。不过,这次仅分析主记录数据页面pageid=311。
--主记录数据页面pageid=311
dbcc page(\'dbpage\',1,311,3)

依旧来分析下这行存储记录,原先长度都是21,为啥添加了一个 text带默认值的列,长度就增加为50bytes呢?
这里注意两个地方:原先的 task列跟 description列。task列之前是实际不存储数据内容的,但是现在存储了数据内容,description大对象列并没有存储数据在主记录中,而是存储在另外的lob data数据页中,在主记录仅存储 描述 该列具体位置内容,占16bytes。
所以 该行记录的长度=状态A+状态B+定长字段长度+定长字段内容+总列数+null位图+变长列数量+列偏移矩阵+变长数据内容=1+1+2+(4+10)+2+1+2+2*3+(5+16)= 50 bytes。
来看看这个16进制的字符串:30001200 01000000 78696e79 73752020 20200500 0403001d 00220032 80616c6c 20410000 d1070000 00004b01 00000100 0000,详细分析这行数据的存储情况。先把这串字符按照字节数区分,详细分析及推导见下图。
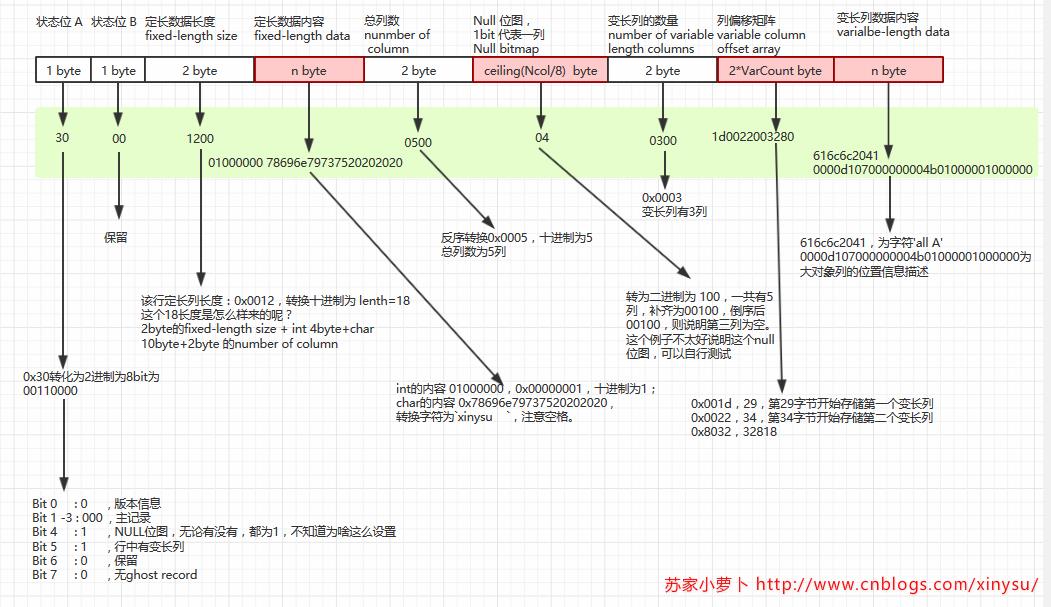
由此可以得到几个推论:大对象的列NOT NULL+默认值,是在数据页上实际存储默认值的,而且会对表格中的其他原本不存储默认值的列造成影响,整个表格变成了把默认值实际存储到数据页面中去。当一个大表,需要增加一列大对象列NOT NULL+默认值时,会影响到表格里面的每一行记录,每行记录都要增加一个16字节的来描述 大对象列的存储位置,同时,原本不存储默认值的列,也会实际存储默认值到数据页面中,这是一个锁表久耗费IO的操作,对于一个大表来说。
是不是发现自己 添加一个大对象列+默认值是一件可怕的事情?如果真有这种需求,而且还是个大表,请谨慎考虑。
3.5 删除无数据的列
--根据之前的查询结果,skill这一列是没有存储数据的
alter table tbrow drop column skill
dbcc traceon(3604)
dbcc ind(\'dbpage\',\'tbrow\',-1)
dbcc page(\'dbpage\',1,311,3)
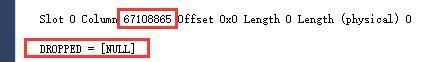
可以发现,删除这一列,对实际数据存储并没有影响,但是该列会有一个标识值 DROPPED=[NULL]表明该列已被删除,注意,这个表示只并不是存储在每一行数据中,而是数据库存储引擎记录。
截取数据页面里边的16进制内容:30 00 1200 01000000 78696e79737520202020 0500 04 0300 1d0022003280 616c6c2041 0000d107000000004b01000001000000,发现与删除前的是一样的,对比如下:
/*
第一个行记录为删除前
第二个行记录为删除后
30 00 1200 01000000 78696e79737520202020 0500 04 0300 1d0022003280 616c6c2041 0000d107000000004b01000001000000
30 00 1200 01000000 78696e79737520202020 0500 04 0300 1d0022003280 616c6c2041 0000d107000000004b01000001000000
*/
得出结论:删除一行无数据的列时,不需要修改行内数据存储情况,仅需要修改涉及的数据字典跟删除期间持有架构锁,这是一个非常快的过程(但是如果表格一直被其他用户进行操作,那么申请架构锁也会出现等待情况)。
3.6 删除有数据的列
--根据之前的查询结果,skill这一列是没有存储数据的
alter table tbrow drop column name
dbcc traceon(3604)
dbcc ind(\'dbpage\',\'tbrow\',-1)
dbcc page(\'dbpage\',1,311,3)

分析到这里,可以发现,SQL SERVER在处理删除列这一块处理的非常巧妙,最大程度的减少了对表格可用性的影响,无论带不带数据,删除的时候,只处理数据字典类相关内容,标识该列已被删除,但是实际上没有去到每一个页面中去删除数据,而是把这些列占用的空间在逻辑上修改为不存在,允许以后写覆盖。
作为一名小小的DBA,个人觉得在行数据的存储结构这一块,针对于增加列或者删除列的处理,SQL SERVER 设计非常巧妙及高效!相对与 MySQL改进后的Online DDL,SQL SERVER将表格的可用性大大提高以及降低对系统资源的影响。(仅讨论列的增加删除DDL这一块)
3.7 行溢出
行溢出这块,不分析其16进制行记录,着重在 行溢出的处理方式上。
#新表格测试
create table tbflow(id int not null ,cola varchar(6000),colb varchar(6000),colc varchar(6000))
INSERT INTO tbflow SELECT 1,replicate(\'1\',1000),replicate(\'1\',5000),replicate(\'1\',3000)
dbcc traceon(3604)
dbcc ind(\'dbpage\',\'tbflow\',-1)

dbcc page(\'dbpage\',1,334,3)

cola列1000个字符,colb列5000个字符,colc列3000个字符,不算其他字节使用,光着3列长度之和就大于8k,按照行溢出的处理,可以推测出 是colb 被移动到 Row-overflow data列,所以,先分析page 334 ,看主记录的存储情况,实际情况与推测一致。
3.8 Forword
Forword这块,不分析其16进制行记录,着重在Forword的处理方式上。
create table tbforword(id int not null ,cola varchar(6000),colb varchar(6000),colc varchar(6000))
insert into tbforword select 1,replicate(\'1\',1000),replicate(\'1\',500),replicate(\'1\',500)
insert into tbforword select 2,replicate(\'1\',1000),replicate(\'1\',500),replicate(\'1\',500)
insert into tbforword select 3,replicate(\'1\',1000),replicate(\'1\',500),replicate(\'1\',500)
dbcc traceon(3604)
dbcc ind(\'dbpage\',\'tbforword\',-1) #记录 IAM是385,主记录是384页
update tbforword set colb=replicate(\'1\',4500) where id=2
dbcc traceon(3604)
dbcc ind(\'dbpage\',\'tbflow\',-1)

pageid=384数据页面中,存储3行记录大概用了6k+的空间,这时候,把id=2的colb列修改为4.5k长度,超过了一个页面8k的范围,也就意味着,这个被修改的列会被forword,根据新增的数据页386,可推测出 forword的列存储在386中。现在分析 pageid 384来验证推测。详见截图,发现与推测一致。
dbcc page(\'dbpage\',1,384,3)

4 行结构与DDL

以上是关于SQL SERVER大话存储结构_数据行的行结构的主要内容,如果未能解决你的问题,请参考以下文章