Oracle索引总结- Oracle索引种类之表簇索引(cluster index)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Oracle索引总结- Oracle索引种类之表簇索引(cluster index)相关的知识,希望对你有一定的参考价值。
表簇索引(cluster index)
对于表簇索引而言,必须使用表簇。
由于簇索引与索引表簇关联紧密,无法单独拿出来总结,因此一并进行总结。
1.1 表簇的定义
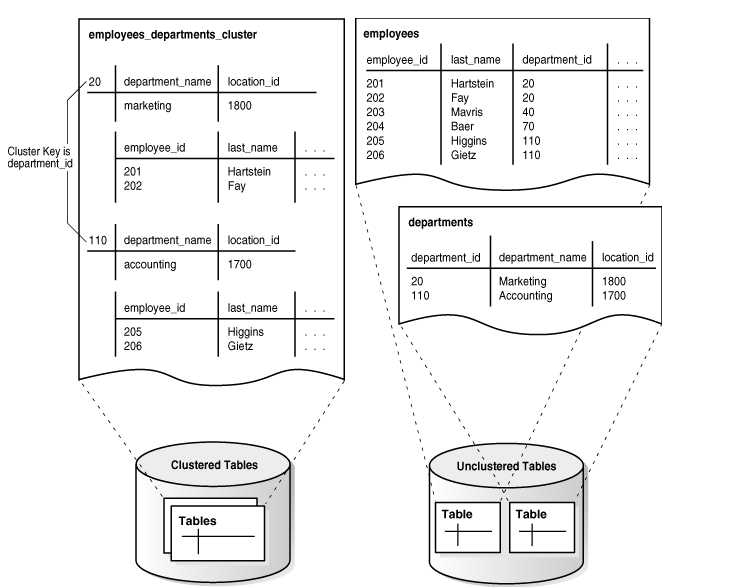
- 表簇是一组通过相同公共列(簇键),构成的表的集合。
- 如上图,右侧独立的两张表,employees员工表与departments部门表,通过簇键department_id列,构成了左侧的一个表簇(cluster)。
- 当构成表簇后,一个单独的数据块会包含多个表的数据行信息。
1.2 表簇的分类
- 对于oracle数据库,主要支持两种表簇:索引聚簇以及哈希聚簇
1.3 索引聚簇与哈希聚簇定位数据的区别
- 索引聚簇:oracle使用簇索引,将簇键键值与相应数据所在数据块地址(DBA)关联进行数据定位。
- 哈希聚簇:oracle使用散列函数替代索引,计算出相应数据的物理存储位置,减少了针对索引块的I/O,进而实现了更快地定位。
1.4 表簇的意义
- 通过簇键的关联,将不同表的相关数据行尽可能地存储在相同的数据块上,不但可以减少存储数据时使用的空间,而且可以降低数据访问时的磁盘I/O数量,提高访问速度。
1.5 表簇的优点
- 对于表簇,在物理层面上,尽可能将与簇键关联的数据,存储在相同的数据块,进而减少块调用时的磁盘I/O操作(非簇关系的表,如emp表跟dept表中的各自行数据,一定不在同一个数据块。块调用时读取更多的块。原因:不同的segments,segment-extents-blocks)。
- 对于表簇,簇键的键值无论在被簇表中出现几次,数据块中,只存储一次,且与相关数据行一并存储,减少了占用的空间。
1.6 表簇使用的注意事项
-
对于存在大量DML操作的表,不适合建立表簇。
-
对于需要经常进行全表扫描的表,不适合建立表簇。(不再像非簇表那样,一个数据块中仅包含一张表中的数据,还包含了与簇键相关的其他表数据行的数据,这意味着扫描簇中单独的一张表,需要扫描更多的数据块)
-
对于需要频繁进行TRUNCATE操作的表,不适合建立表簇。(簇表中无法针对单独的被簇表进行truncate操作)
此外,对于哈希表簇,不用也不能创建索引
1.7 表簇索引
- 表簇索引,即B-tree簇索引,由B-tree结构构成。主要针对索引表簇(index cluster)
- 与普通B-tree索引的不同在于,普通B-tree索引的索引键将键值与数据的rowid进行关联。聚簇索引的索引键值与相应数据所在数据块的地址(DBA)相关联。
1.8 关于索引表簇(index cluster)创建
- 创建的顺序如下:建立簇 - 建立簇表 - 建立簇索引 - 加载数据。
- 创建簇的参数SIZE,决定了每个簇键值可以关联多少字节的数据,进而计算出每个数据块能容纳多少个簇键。
- 当SIZE设置过高,单独的数据块可以容纳的簇键会减少,且对于单个簇键会占用比实际需求更多的空间,造成空间的浪费。
- 当SIZE设置过低,单个的簇键无法在单独的数据块中容纳一条完整的数据,进而导致溢出数据部分串联至新块,影响聚合度。
- 当SIZE设置为1024时,对于一个8K(8192)的标准块,由于数据块的pct_free,实际可容纳7个簇键。
- 对于索引表簇,当不创建簇索引时,无法进行数据的加载。
- 下面进行创建的演示,及cluster、index、cluster table在数据存储上的一些区别的说明。
- 红色字体为创建的关键语句
- 绿色字体为步骤说明
- 绿色粗体字体为对象存储分布的一些特点的说明
-
--创建一个表簇
[email protected] >create cluster clu_info_employee (deptno number) size 1024; Cluster created. Yumiko@Sunny >select * from tab where TNAME like ‘%CLU%‘; TNAME TABTYPE CLUSTERID ------------------------------ ------- ---------- CLU_INFO_EMPLOYEE CLUSTER
--通过查询user_clusters视图(或者dba_clusters视图),可以看到创建的表簇为index cluster,且SIZE设置为1024 Yumiko@Sunny >select cluster_name, tablespace_name, cluster_type, key_size from user_clusters; CLUSTER_NAME TABLESPACE_NAME CLUST KEY_SIZE ------------------------------ ------------------------------ ----- ---------- CLU_INFO_EMPLOYEE USERS INDEX 1024
--通过user_objects视图(或者dba_objects视图),同样可以查阅cluster的信息。
--需要注意,同一个cluster下的对象,其DATA_OBJECT_ID的值一致。 Yumiko@Sunny >select OBJECT_ID,OBJECT_NAME,DATA_OBJECT_ID,OBJECT_TYPE from user_objects where OBJECT_NAME like ‘%CLU%‘; OBJECT_ID OBJECT_NAME DATA_OBJECT_ID OBJECT_TYPE ---------- ------------------------- -------------- ------------------- 52626 CLU_INFO_EMPLOYEE 52626 CLUSTER
--通过user_clu_columns视图可以看到,此时未显示刚刚创建的cluster信息,表明该簇目前为空簇。 Yumiko@Sunny >select * from USER_CLU_COLUMNS; no rows selected
--此处应该注意到,通过dba_segments视图查看,虽然当前是空簇,但已出现刚刚创建的cluster,证明此时已占用了空间。 Yumiko@Sunny >select SEGMENT_NAME,SEGMENT_TYPE, extents, HEADER_FILE, HEADER_BLOCK, BYTES, BLOCKS from dba_segments where owner=‘SCOTT‘ and segment_name like ‘%CLU%‘; SEGMENT_NAME SEGMENT_TYPE EXTENTS HEADER_FILE HEADER_BLOCK BYTES BLOCKS ---------------------------------------------------------------------------------------- CLU_INFO_EMPLOYEE CLUSTER 1 4 395 65536 8
--创建簇表 Yumiko@Sunny >create table clu_info_dept(DEPTNO number,DNAME VARCHAR2(14),LOC VARCHAR2(13)) cluster CLU_INFO_EMPLOYEE(deptno); Table created. Yumiko@Sunny >create table clu_info_emp(DEPTNO number,ENAME VARCHAR2(10),JOB VARCHAR2(9)) cluster CLU_INFO_EMPLOYEE(deptno); Table created.
--查询user_clu_columns视图可以注意到,此时出现了簇及簇表的相应信息,说明此时,簇已不再是空簇。 Yumiko@Sunny >select * from USER_CLU_COLUMNS; CLUSTER_NAME CLU_COLUMN_NAME TABLE_NAME TAB_COLUMN_NAME ----------------------------------------------------------------------------------------- CLU_INFO_EMPLOYEE DEPTNO CLU_INFO_DEPT DEPTNO CLU_INFO_EMPLOYEE DEPTNO CLU_INFO_EMP DEPTNO Yumiko@Sunny >select * from tab where TNAME like ‘%CLU%‘; TNAME TABTYPE CLUSTERID ------------------------------ ------- ---------- CLU_INFO_DEPT TABLE 1 CLU_INFO_EMP TABLE 2 CLU_INFO_EMPLOYEE CLUSTER
--同上面所说,查询user_objects视图可以看到簇的所有信息,此外可以注意到DATA_OBJECT_ID列是一致的,如前所说 Yumiko@Sunny >select OBJECT_ID,OBJECT_NAME,DATA_OBJECT_ID,OBJECT_TYPE from user_objects where OBJECT_NAME like ‘%CLU%‘; OBJECT_ID OBJECT_NAME DATA_OBJECT_ID OBJECT_TYPE ---------- ------------------------- -------------- ------------------- 52627 CLU_INFO_DEPT 52626 TABLE 52628 CLU_INFO_EMP 52626 TABLE 52626 CLU_INFO_EMPLOYEE 52626 CLUSTER --查询此时的dba_segments视图,并未发现添加的两张簇表 Yumiko@Sunny >select SEGMENT_NAME,SEGMENT_TYPE, extents, HEADER_FILE, HEADER_BLOCK, BYTES, BLOCKS from dba_segments where owner=‘SCOTT‘ and segment_name like ‘%CLU%‘; SEGMENT_NAME SEGMENT_TYPE EXTENTS HEADER_FILE HEADER_BLOCK BYTES BLOCKS ------------------------------------------------------------------------------------ CLU_INFO_EMPLOYEE CLUSTER 1 4 395 65536 8
--查询此时的dba_tables视图,却可以发现刚刚建立的表 Yumiko@Sunny >select TABLE_NAME,CLUSTER_NAME,STATUS from dba_tables where owner=‘SCOTT‘ and table_name like ‘%CLU%‘; TABLE_NAME CLUSTER_NAME STATUS ------------------------------ ------------------------------ -------- CLU_INFO_EMP CLU_INFO_EMPLOYEE VALID CLU_INFO_DEPT CLU_INFO_EMPLOYEE VALID
--尝试加载数据失败,报错明显提示了未建立簇索引,也符合之前说过的创建顺序 Yumiko@Sunny >insert into clu_info_dept select * from dept; insert into clu_info_dept select * from dept * ERROR at line 1: ORA-02032: clustered tables cannot be used before the cluster index is built
-- 创建簇索引,注意此时的关键字on cluster Yumiko@Sunny >create index CLU_INFO_index on cluster CLU_INFO_EMPLOYEE; Index created. --查询此时的dba_segments视图,同样有索引的segments信息。 Yumiko@Sunny >select SEGMENT_NAME,SEGMENT_TYPE, extents, HEADER_FILE, HEADER_BLOCK, BYTES, BLOCKS from dba_segments where owner=‘SCOTT‘ and segment_name like ‘%CLU%‘; SEGMENT_NAME SEGMENT_TYPE EXTENTS HEADER_FILE HEADER_BLOCK BYTES BLOCKS -------------------------------------------------------------------------------------- CLU_INFO_INDEX INDEX 1 4 403 65536 8 CLU_INFO_EMPLOYEE CLUSTER 1 4 395 65536 8 --加载数据 Yumiko@Sunny >insert into clu_info_dept select * from dept; 4 rows created.
--再次查询dba_segments视图,依然没有cluster table的信息
[email protected] >select SEGMENT_NAME,SEGMENT_TYPE, extents, HEADER_FILE, HEADER_BLOCK, BYTES, BLOCKS from dba_segments where owner=‘SCOTT‘ and segment_name like ‘%CLU%‘;SEGMENT_NAME SEGMENT_TYPE EXTENTS HEADER_FILE HEADER_BLOCK BYTES BLOCKS -------------------------------------------------------------------------------------- CLU_INFO_INDEX INDEX 1 4 403 65536 8 CLU_INFO_EMPLOYEE CLUSTER 1 4 395 65536 8
- 从以上不难看出,对于表簇,cluster table仅仅存储在cluster中,不会成为单独的segment占用空间。
1.9 关于索引表簇(index cluster)删除
- drop cluster cluster_name -- 用于删除空簇
- drop cluster cluster_name including tables -- 用于删除非空簇
- drop cluster cluster_name including tables cascade constraints --用于删除非空簇及外键约束
此外,对于簇表本身的删除,按照普通表方法即可。
1.10 哈希表簇(hash cluster)简介
下面引用oracle官方文档的例子:
CREATE CLUSTER call_detail_cluster (
telephone_number NUMBER,
call_timestamp NUMBER SORT,
call_duration NUMBER SORT )
HASHKEYS 10000
HASH IS telephone_number
SIZE 256;
其中:
HASH IS参数:
- 该参数可选,用于指明进行散列的列,可以不明确指定。
- 当目标列数据类型为number类型,且可以唯一标识行时,可以将该列指定为散列值。
- 不指明该参数时,oracle使用内部散列函数。
HASHKEYS参数:
- 该参数用于指定和限制散列函数可以产生的唯一的散列值的数量。
- 该参数越小,相对关联的数据块越多,发生的物理读越多。
SIZE参数:
- 该参数基本含义与索引聚簇相似。
-
该参数越大,虽然单独的数据块可以容纳的簇键会减少,甚至可能会由于单个簇键占用比实际需求更多的空间造成空间的浪费,但由于有更多的空间存储更多的相关数据,只要设置合理,一
定程度上却可以降低物理读。
以上是关于Oracle索引总结- Oracle索引种类之表簇索引(cluster index)的主要内容,如果未能解决你的问题,请参考以下文章
Oracle 12C 新特性之表分区带 异步全局索引异步维护(一次addtruncatedropspiltmerge多个分区)
SQL Server,Oracle,DB2索引建立语句的对比