Spark详解
Posted 阿德小仔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark详解相关的知识,希望对你有一定的参考价值。
目录
第1章:Spark概述
1.1 Spark是什么
Spark 是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
1.2 Spark and Hadoop
在之前的学习中,Hadoop的 MapReduce 是大家广为熟知的计算框架,那为什么咱们还要学习新的计算框架 Spark 呢,这里就不得不提到 Spark 和 Hadoop 的关系。
从时间节点上来看:
- Hadoop
- 2006 年 1 月,Doug Cutting 加入 Yahoo,领导 Hadoop 的开发;
- 2008 年 1 月,Hadoop 成为 Apache 顶级项目;
- 2011 年 1.0 正式发布;
- 2012 年 3 月稳定版发布;
- 2013 年 10 月发布 2.X (Yarn)版本;
- Spark
- 2009 年,Spark 诞生于伯克利大学的 AMPLab 实验室;
- 2010 年,伯克利大学正式开源了 Spark 项目;
- 2013 年 6 月,Spark 成为了 Apache 基金会下的项目;
- 2014 年 2 月,Spark 以飞快的速度成为了 Apache 的顶级项目;
- 2015 年至今,Spark 变得火爆,大量的国内公司开始重点部署或者使用Spark;
从功能上来看:
- Hadoop
- Hadoop 是由java 语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架;
- 作为Hadoop分布式文件系统,HDFS处于Hadoop生态圈的最下层,存储着所有的数据,支持着Hadoop的所有服务。它的理论基础源于Google的TheGoogleFileSystem这篇论文,它是GFS的开源实现。
- MapReduce 是一种编程模型,Hadoop 根据 Google 的 MapReduce 论文将其实现,作为 Hadoop 的分布式计算模型,是 Hadoop 的核心。基于这个框架,分布式并行程序的编写变得异常简单。综合了 HDFS 的分布式存储和MapReduce 的分布式计算,Hadoop 在处理海量数据时,性能横向扩展变得非常容易。
- HBase是对Google的Bigtable的开源实现,但又和Bigtable存在许多不同之处。HBase是一个基于HDFS的分布式数据库,擅长实时地随机读/写超大规模数据集。它也是Hadoop非常重要的组件。
- Spark
- Spark是一种由Scala语言开发的快速、通用、可扩展的大数据分析引擎;
- Spark Core中提供了Spark最基础与最核心的功能;
- Spark SQL是Spark用来操作结构化数据的组件。通过Spark SQL,用户可以使用SQL或者Apache Hive版本的SQL方言(HQL)来查询数据。
- Spark Streaming是Spark平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的API。
由上面的信息可以获知,Spark出现的时间相对较晚,并且主要功能主要是用于数据计算,所以其实Spark一直被认为是Hadoop框架的升级版。
1.3 Spark on Hadoop
Hadoop的MR框架和Spark框架都是数据处理框架,那么我们在使用时如何选择呢?
- Hadoop MapReduce由于其设计初衷并不是为了满足循环迭代式数据流处理,因此在多并行运行的数据可复用场景(如:机器学习、图挖掘算法、交互式数据挖掘算法)中存在诸多计算效率等问题。所以Spark应运而生,Spark就是在传统的MapReduce计算框架的基础上,利用其计算过程的优化,从而大大加快了数据分析、挖掘的运行和读写速度,并将计算单元缩小到更适合并行计算和重复使用的RDD计算模型。
- 机器学习中ALS、凸优化梯度下降等。这些都需要基于数据集或者数据集的衍生数据反复查询反复操作。MR这种模式不太合适,即使多MR串行处理,性能和时间也是一个问题。数据的共享依赖于磁盘。另外一种是交互式数据挖掘,MR显然不擅长。而Spark所基于的scala语言恰恰擅长函数的处理。
- Spark是一个分布式数据快速分析项目。它的核心技术是弹性分布式数据集(ResilientDistributedDatasets),提供了比MapReduce丰富的模型,可以快速在内存中对数据集进行多次迭代,来支持复杂的数据挖掘算法和图形计算算法。
- Spark和Hadoop的根本差异是多个作业之间的数据通信问题:Spark多个作业之间数据通信是基于内存,而Hadoop是基于磁盘。
- Spark Task的启动时间快。Spark采用fork线程的方式,而Hadoop采用创建新的进程的方式。
- Spark只有在shuffle的时候将数据写入磁盘,而Hadoop中多个MR作业之间的数据交互都要依赖于磁盘交互。
- Spark的缓存机制比HDFS的缓存机制高效。
经过上面的比较,我们可以看出在绝大多数的数据计算场景中,Spark确实会比MapReduce更有优势。但是Spark是基于内存的,所以在实际的生产环境中,由于内存的限制,可能会由于内存资源不够导致Job执行失败,此时,MapReduce其实是一个更好的选择,所以Spark并不能完全替代MR。
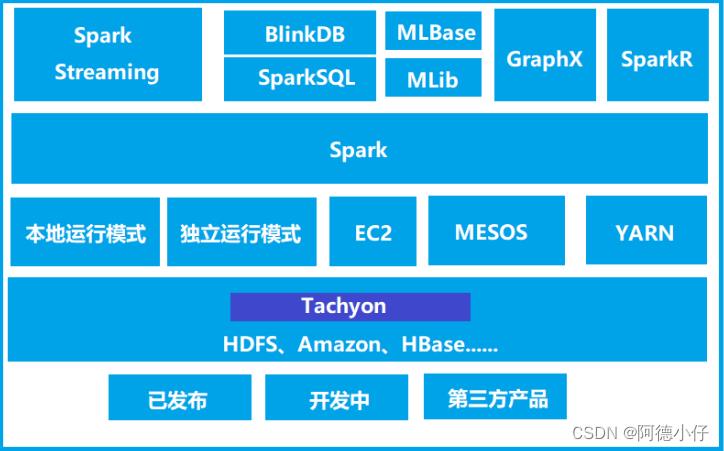
1.4 Spark核心模块

- Spark Core
Spark Core中提供了Spark最基础与最核心的功能,Spark其他的功能如:Spark SQL,Spark Streaming,GraphX,MLlib都是在Spark Core的基础上进行扩展的。
- Spark SQL
Spark SQL是Spark用来操作结构化数据的组件。通过Spark SQL,用户可以使用SQL或者Apache Hive版本的SQL方言(HQL)来查询数据。
- Spark Streaming
Spark Streaming是Spark平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的API。
- Spark MLlib
MLlib是Spark提供的一个机器学习算法库。MLlib不仅提供了模型评估、数据导入等额外的功能,还提供了一些更底层的机器学习原语。
- Spark GraphX
GraphX是Spark面向图计算提供的框架与算法库。
第2章:Spark快速上手
在大数据早期的课程中我们已经学习了MapReduce框架的原理及基本使用,并了解了其底层数据处理的实现方式。接下来,就让我们走进Spark的世界,了解一下它是如何带领我们完成数据处理的。
2.1 创建Maven项目
2.1.1 增加Scala插件
Spark由Scala语言开发的,所以本课件接下来的开发所使用的语言也为Scala,咱们当前使用的Spark版本为2.4.5,默认采用的Scala编译版本为2.12,所以后续开发时。我们依然采用这个版本。开发前请保证IDEA开发工具中含有Scala开发插件。
2.1.2 增加依赖关系
修改Maven项目中的POM文件,增加Spark框架的依赖关系。本课件基于Spark2.4.5版本,使用时请注意对应版本。
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>2.4.5</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 该插件用于将 Scala 代码编译成 class 文件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<!-- 声明绑定到 maven 的 compile 阶段 -->
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.1.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
2.1.3 WordCount
为了能直观地感受Spark框架的效果,接下来我们实现一个大数据学科中最常见的教学案例WordCount。
/**
* spark实现单词计数
*/
object WordCountSpark
def main(args: Array[String]): Unit =
//创建spark运行配置对象
val spark: SparkConf = new SparkConf()
.setMaster("local[*]")
.setAppName("WordCountSparkApps")
//创建spark上下文对象
val sc: SparkContext = new SparkContext(spark)
//读文件数据
val wordsRDD: RDD[String] = sc.textFile("data/word.txt")
//讲文件中的数据进行分词
val word: RDD[String] = wordsRDD.flatMap(_.split(","))
//转换数据结构word ---->(word,1)
val word2: RDD[(String, Int)] = word.map((_, 1))
//将转换结构后的数据按照相同的单词进行分组聚合
val word2CountRDD: RDD[(String, Int)] = word2.reduceByKey(_ + _)
//将数据聚合结果采集到内存中
val word2Count: Array[(String, Int)] = word2CountRDD.collect()
//打印结果
word2Count.foreach(println)
//关闭spark连接
sc.stop()
执行过程中,会产生大量的执行日志,如果为了能够更好的查看程序的执行结果,可以在项目的resources目录中创建log4j.properties文件,并添加日志配置信息:
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%dyy/MM/dd
HH:mm:ss %p %c1: %m%n
# Set the default spark-shell log level to ERROR. When running the spark-shell,
the
# log level for this class is used to overwrite the root logger's log level, so
that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=ERROR
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=ERROR
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERROR
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERROR
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent
UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
2.1.4 异常处理
如果本机操作系统是Windows,在程序中使用了Hadoop相关的东西,比如写入文件到HDFS,则会遇到如下异常:
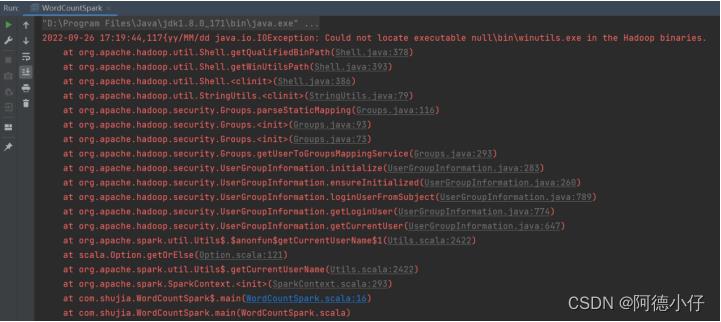
出现这个问题的原因,并不是程序的错误,而是windows系统用到了hadoop相关的服务,解决办法是通过配置关联到windows的系统依赖就可以了。
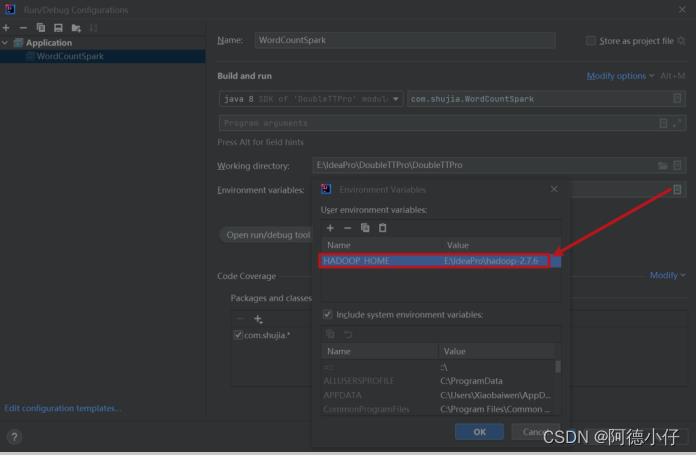
在IDEA中配置RunConfiguration,添加HADOOP_HOME变量或者在windows上配置环境变量:
第3章:Spark运行环境
Spark作为一个数据处理框架和计算引擎,被设计在所有常见的集群环境中运行, 在国内工作中主流的环境为Yarn,不过逐渐容器式环境也慢慢流行起来。接下来,我们就分别看看不同环境下Spark的运行。
3.1 Local模式
所谓的Local模式,就是不需要其他任何节点资源就可以在本地执行 Spark 代码的环境,一般用于教学,调试,演示等,之前在IDEA中运行代码的环境我们称之为开发环境,不太一样。
3.1.1 上传并解压缩文件
将spark-2.4.5-bin-hadoop2.6.tgz文件上传到Linux并解压缩,放置在指定位置,路径中不要包含中文或空格。
(1)上传文件至/usr/local/packages中:

(2)解压缩到指定目录:
[root@master local]# tar -zxvf spark-2.4.5-bin-hadoop2.6.tgz -C /usr/local/soft/
(3)重命名:
[root@master soft]# mv spark-2.4.5-bin-hadoop2.6/ spark-local
3.1.2 启动Local环境
(1)进入解压缩(spark-local)目录,执行以下命令:
[root@master spark-local]# bin/spark-shell
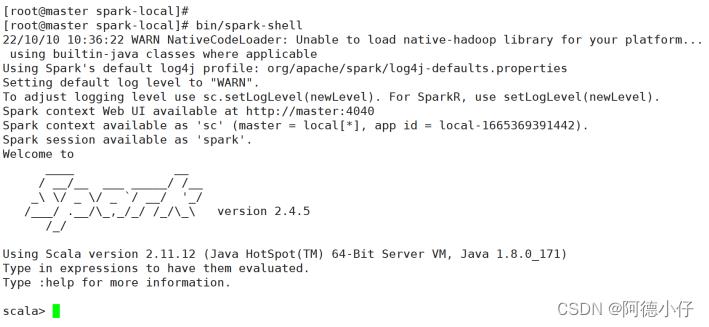
(2)启动成功后,可以输入网址进行Web UI监控页面访问:
http://master:4040

3.1.3 命令行工具
在解压缩文件夹(spark-local)下的data目录中,添加word.txt文件。在命令行工具中执行如下代码指令(和IDEA中代码简化版一致)。
sc.textFile("data/word.txt").flatMap(_.split(",")).map((_,1)).reduceByKey(_+_).collect
3.1.4 退出本地模式
按键Ctrl+C或输入Scala指令:
scala> :quit
3.1.5 提交应用
bin/spark-submit \\
--class org.apache.spark.examples.SparkPi \\
--master local[1] \\
./examples/jars/spark-examples_2.11-2.4.5.jar \\
10
参数解释:
(1)--class表示要执行程序的主类,此处可以更换为我们自己写的应用程序
(2)--master local[2]部署模式,默认为本地模式,数字表示分配的虚拟CPU核数量
(3)spark-examples_2.11-2.4.5.jar运行的应用类所在的jar包,实际使用时,可以设定为我们自己打的jar包
(4)数字10表示程序的入口参数,用于设定当前应用的任务数量
3.2 Standalone模式
local本地模式毕竟只是用来进行练习演示的,真实工作中还是要将应用提交到对应的集群中去执行,这里我们来看看只使用Spark自身节点运行的集群模式,也就是我们所谓的独立部署(Standalone)模式。Spark的Standalone模式体现了经典的master-slave模式。集群规划:
| master | node1 | node2 | |
| Spark | Worker Master | Worker | Worker |
3.2.1 上传并解压缩文件
将spark-2.4.5-bin-hadoop2.6.tgz文件上传到Linux并解压缩,放置在指定位置,路径中不要包含中文或空格。
(1)上传文件至/usr/local/packages中:
(2)解压缩到指定目录:
[root@master local]# tar -zxvf spark-2.4.5-bin-hadoop2.6.tgz -C /usr/local/soft/
(3)重命名:
[root@master soft]# mv spark-2.4.5-bin-hadoop2.6/ spark-standalone
3.2.2 修改配置文件
(1)进入解压缩路径(spark-standalone)的conf目录,修改slaves.template文件名为slaves:
[root@master conf]# mv slaves.template slaves
(2)修改slaves文件,添加work节点:
[root@master conf]# vim slaves
master
node1
node2

(3)修改spark-env.sh.template文件名为spark-env.sh:
[root@master conf]# mv spark-env.sh.template spark-env.sh
(4)修改spark-env.sh文件,添加JAVA_HOME环境变量和集群对应的master节点:
[root@master conf]# vim spark-env.sh
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171
PARK_MASTER_HOST=master
SPARK_MASTER_PORT=7077
注意:7077端口,相当于hadoop3内部通信的8020端口,此处的端口需要确认自己的Hadoop配置。
(5)分发spark-standalone目录
[root@master soft]# scp -r spark-standalone/ node1:`pwd`
[root@master soft]# scp -r spark-standalone/ node2:`pwd`
3.2.3 启动集群
(1)执行以下命令:
[root@master spark-standalone]# sbin/start-all.sh
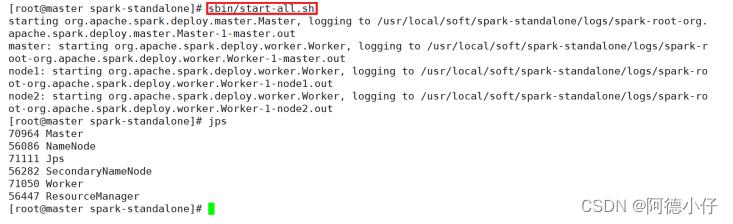
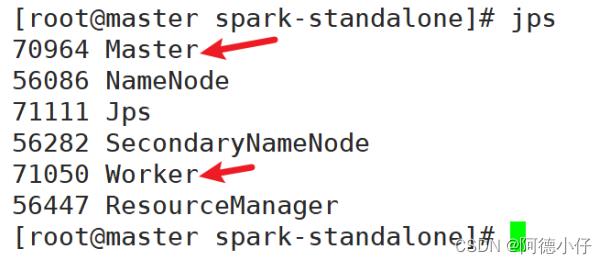
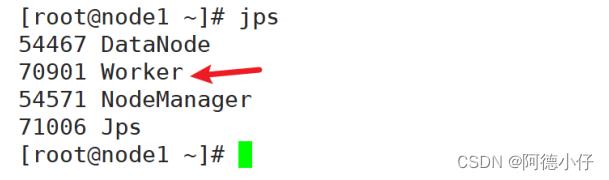
(2)查看三台服务器运行进程
master:
node1:

node2:
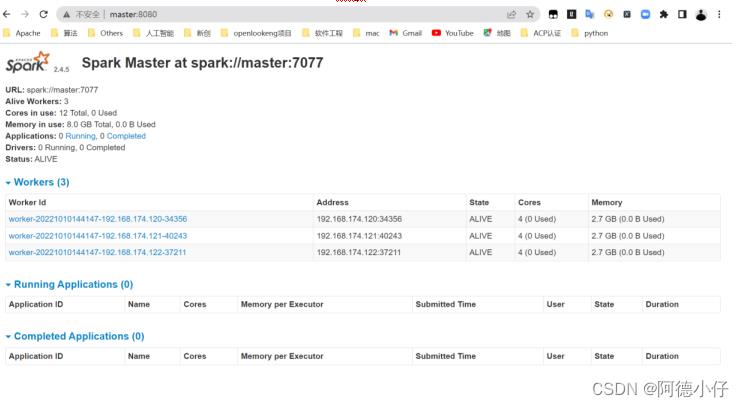
(3)查看Master资源监控Web UI界面:http://master:8080
3.2.4 提交应用
bin/spark-submit \\
--class org.apache.spark.examples.SparkPi \\
--master spark://master:7077 \\
./examples/jars/spark-examples_2.11-2.4.5.jar \\
10
参数解释:
(1)--class 表示要执行程序的主类
(2)--master spark://master:7077 独立部署模式,连接到Spark集群
(3)spark-examples_2.11-2.4.5.jar运行类所在的jar包
(4)数字10表示程序的入口参数,用于设定当前应用的任务数量
执行任务时,会产生多个 Java 进程:

执行任务时,默认采用服务器集群节点的总核数,每个节点内存1024M。

3.2.5 提交参数说明
在提交应用中,一般会同时一些提交参数
bin/spark-submit \\
--class <main-class>
--master <master-url> \\
... # other options
<application-jar> \\
[application-arguments]
| 参数 | 解释 | 可选值举例 |
| --class | Spark程序中包含主函数的类 | |
| --master | Spark程序运行的模式(环境) | 模式:local[*]、spark://master:7077、Yarn |
| --executor-memory 1G | 指定每个executor可用内存为1G | 符合集群内存配置即可,具体情况具体分析。 |
| --total-executor-cores 2 | 指定所有executor使用的cpu核数为2个 | |
| --executor-cores | 指定每个executor使用的cpu核数 | |
| application-jar | 打包好的应用jar,包含依赖。这个URL在集群中全局可见。比如 hdfs://共享存储系统,如果是file://path,那么所有的节点的path都包含同样的jar | |
| application-arguments | 传给main()方法的参数 |
3.2.6 配置历史服务
由于spark-shell停止掉后,集群监控master:4040页面就看不到历史任务的运行情况,所以开发时都配置历史服务器记录任务运行情况。
(1)修改spark-defaults.conf.template文件名为spark-defaults.conf
[root@master conf]# mv spark-defaults.conf.template spark-defaults.conf
(2)修改spark-default.conf文件,配置日志存储路径
[root@master conf]# vim spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master:9000/directory

注意:需要启动hadoop集群,HDFS上的directory目录需要提前存在。
hadoop fs -mkdir /directory
(3)修改spark-env.sh文件, 添加日志配置
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://master:9000/directory
-Dspark.history.retainedApplications=30"
参数含义:
(1)参数1含义:WEB UI访问的端口号为18080
(2)参数2含义:指定历史服务器日志存储路径
(3)参数3含义:指定保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
(4)分发配置文件
[root@master spark-standalone]# scp -r conf/ node1:`pwd`
[root@master spark-standalone]# scp -r conf/ node2:`pwd`
(5)重新启动集群和历史服务
sbin/start-all.sh
sbin/start-history-server.sh
(6)重新执行任务
bin/spark-submit \\
--class org.apache.spark.examples.SparkPi \\
--master spark://master:7077 \\
./examples/jars/spark-examples_2.11-2.4.5.jar \\
10
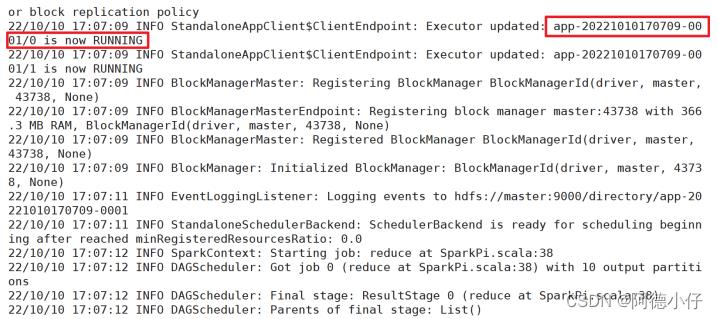
(7)查看历史服务:http://master:18080

3.2.7 配置高可用(HA)
所谓的高可用是因为当前集群中的 Master 节点只有一个,所以会存在单点故障问题。所以为了解决单点故障问题,需要在集群中配置多个 Master 节点,一旦处于活动状态的 Master发生故障时,由备用 Master 提供服务,保证作业可以继续执行。这里的高可用一般采用Zookeeper 设置。
集群规划:
| master | node1 | node2 | |
| spark | Master Zookeeper Worker | Master Zookeeper Worker | Zookeeper Worker |
(1)停止集群
[root@master spark-standalone]# sbin/stop-all.sh
(2)启动Zookeeper
bin/zkServer.sh start
注意:三台都需要启动。
(3)修改spark-env.sh文件添加如下配置
#PARK_MASTER_HOST=master
#SPARK_MASTER_PORT=7077
#Master 监控页面默认访问端口为 8080,但是可能会和 Zookeeper 冲突,所以改成 8989,也可以自定义,访问 UI 监控页面时请注意
SPARK_MASTER_WEBUI_PORT=8989
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=master,node1,node2
-Dspark.deploy.zookeeper.dir=/spark"
(4)分发配置文件
[root@master spark-standalone]# scp -r conf/ node1:`pwd`
[root@master spark-standalone]# scp -r conf/ node2:`pwd`
(5)启动集群
[root@master spark-standalone]# sbin/start-all.sh
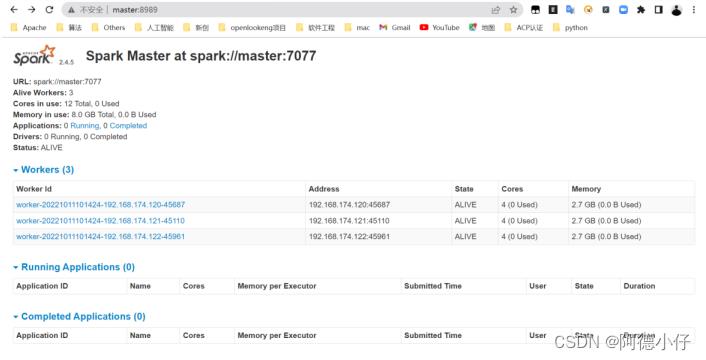
(6)启动node1的单独Master节点,此时node1节点Master状态处于备用状态。
[root@node1 spark-standalone]# sbin/start-master.sh
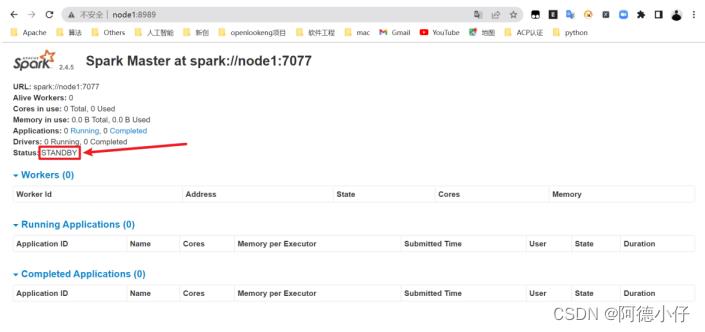
(7)提交应用到高可用集群
bin/spark-submit \\
--class org.apache.spark.examples.SparkPi \\
--master spark://master:7077,node1:7077 \\
./examples/jars/spark-examples_2.11-2.4.5.jar \\
10
(8)停止master的Master资源监控进程

(9)查看node1的Master资源监控Web UI,稍等一段时间后,node1节点的Master状态提升为活动状态
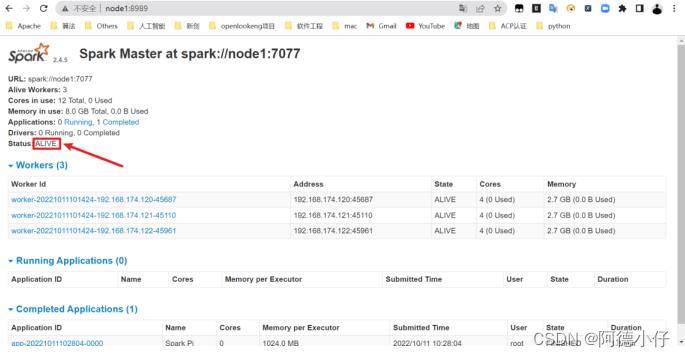
3.3 Yarn模式
独立部署(Standalone)模式由Spark自身提供计算资源,无需其他框架提供资源。这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但是你也要记住,Spark主要是计算框架,而不是资源调度框架,所以本身提供的资源调度并不是它的强项,所以还是和其他专业的资源调度框架集成会更靠谱一些。所以接下来我们来学习在强大的Yarn环境下Spark是如何工作的(其实是因为在国内工作中,Yarn使用的非常多)。
3.3.1 上传并解压缩文件
将spark-2.4.5-bin-hadoop2.6.tgz文件上传到Linux并解压缩,放置在指定位置,路径中不要包含中文或空格。
(1)上传文件至/usr/local/packages中:
(2)解压缩到指定目录:
[root@master local]# tar -zxvf spark-2.4.5-bin-hadoop2.6.tgz -C /usr/local/soft/
(3)重命名:
[root@master soft]# mv spark-2.4.5-bin-hadoop2.6/ spark-yarn
3.3.2 修改配置文件
(1)修改hadoop配置文件/usr/local/soft/hadoop-2.7.6/etc/hadoop/yarn-site.xml, 并分发
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>