从核酸检测平台崩盘看性能工程的范围
Posted zuozewei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从核酸检测平台崩盘看性能工程的范围相关的知识,希望对你有一定的参考价值。
近几年疫情肆虐,健康码系统和核酸检测系统成了民生的保障。在疫情张狂的时候,这类系统的稳定性、可用性是关键的技术支撑能力。
每个地方的健康码平台都或多或少地出现过问题,影响每个人的生活。
从我工作十几年的性能工作经验,来聊一下系统性能容量这个话题。
先放几张图,让你直观感受一下系统的崩溃状态。

(本文图均来自网络)
我有幸也参与过某市的扫码和核酸检测系统的项目。对其中细节略知一二。
但今天我不是来做键盘侠来评价做这些系统的机构或企业有什么不足之处的,也不是想讥讽嘲笑技术人员能力薄弱的。
而是想通过这样的事故来说一下性能工程在一个系统中的重要性。
首先,没有一个系统是不存在性能瓶颈的,即便是调优到再完美的系统,它的性能容量也是有上限的。要想让系统稳定的运行,做为I T 技术支撑的技术人员,要保障的是在性能容量上限的位置能够稳定的运行下去。
在性能容量达到上限时,系统可以提示“请稍后再试”,但不能一直稍后,稍太久了影响面太大。
要做这样的系统性能容量整体规划,首先要看看我们面对的是什么需求。在健康码相关的的众多系统中,像扫码系统(就是你到各个地方都要扫的,还有一些卡口刷码、刷脸的)、核酸系统(这里就包括你要拿着身份证去做数据采集、核酸预约、数据上报、数据推送等)、疫苗服务(疫苗信息、接种信息等)是面对大众的,还有一些是必须存在的系统(像登录认证系统、管理后台、网关等),还有像大数据平台、数据抽取、大屏展示、数据同步、管理后台等系统。重要系统如下:

扫码、核酸这样的业务场景不算复杂,但技术栈一点也不比其他系统少。
要想做这样的系统的容量规划,首先得确定的是容量目标。这个容量目标是全链路的容量目标,而不是某一个系统的。
主要的链路有两个:一个是扫码链路、一个是核酸采集链路。疫苗接种的链路相对来说量不算大。
根据一个健康码系统要面对的人群总量来计算,通常这这样的系统是以省、直辖市为单位,从2022年所有省份人口排名来看,广东省人最多,澳门人最少。排名前十的省份如下:
- 广东——1.1346亿
- 山东——1.0047亿
- 河南——9605万
- 四川——8341万
- 江苏——8051万
- 河北——7556万
- 湖南——6899万
- 安徽——6324万
- 湖北——5917万
- 浙江——5737万
以最近出问题的四川省天府健康通为例,四川省 2022 年总人口 8341 万,成都市人口 2000 多万。这个系统需要支持的总人口基数就是 8000 多万。
当然这个是全链路的容量峰值需求,虽然在平时系统不会一直处在峰值状态,但系统的容量上限应该是能够支撑容量上限。
如果支撑不了,就返回“稍后再试”之类的界面,虽然这样返回,但仍然有个前提就是:系统不能宕机!
我们拿一个人一次扫码只发一次接口请求来算。四川省所有人口,由于近期成都疫情严重,所以扫码及核酸采集的人就会比较集中。根据之前的一个扫码系统的经验,在上班高峰期的时候,扫码并发度在2%左右。
考虑到成都近期疫情严重,扫码峰值会比平时上班峰值更高,按2倍于上班峰值4%计算,也即是成都市疫情高峰期的扫码峰值:2100万x4%=84万,也就是一秒会产生的接口请求有84万。这个接口级TPS的容量需求已经是相当大了。这是扫码服务的容量需求。而这只是支持成都一个市,如果按全省来算的话,你可以自己算一下。
而这一次成都市的系统问题是在核酸检测前的那次确认身份扫码。

这次扫码的前提是天府健康通的二维码已经亮出来了,给工作人员扫,这时是走的核酸采集系统。
所以我们得来聊聊核酸检测系统。
对于核酸检测的系统来说,容量需求会低很多,毕竟核酸采集点是有限的,并且得有一个人坐在那里扫你的码或身份证,还要拿棍子捅你的嗓子,这最快也得5秒左右吧。
据公开信息显示,成都市锦江区核酸采样点在100个左右,成华区在123个左右,这些是采集点比较多的区,也有低的,像青白江在50个左右,我们就算平均每个区150个采集点吧(往高了估,毕竟我没有一个个去数),成都市总共有20个区县,也就是在3000个左右。
根据人口比例推算,四川全省核酸采样点应该在12000个左右,核酸采样的时候扫一次在业务级请求也只发送一次即可,就算按并发度10%计算,12000个采样点也只需要业务级TPS达到1200即可,即便是达到20%的并发度(这个值在我经历过的系统中从来没有出现过),也只需要业务级TPS 2400而已。
据我对核酸采集系统架构的了解和做过的容量评估项目,这个值需要的硬件资源、网络带宽都不会特别高,除非在架构设计时拿图片来实时传输。
拿一些压力数据来看,这是我在一个核酸系统中刚开始做的第一次业务级的容量场景数据(保密信息已隐藏)。

在刚接触的时候,业务级 TPS 大概就是在 1200 左右吧。经过了一轮轮的努力,项目上所有人的配合,性能瓶颈定位、分析、优化之后,达到这样的业务级TPS量级(保密信息已隐藏)。
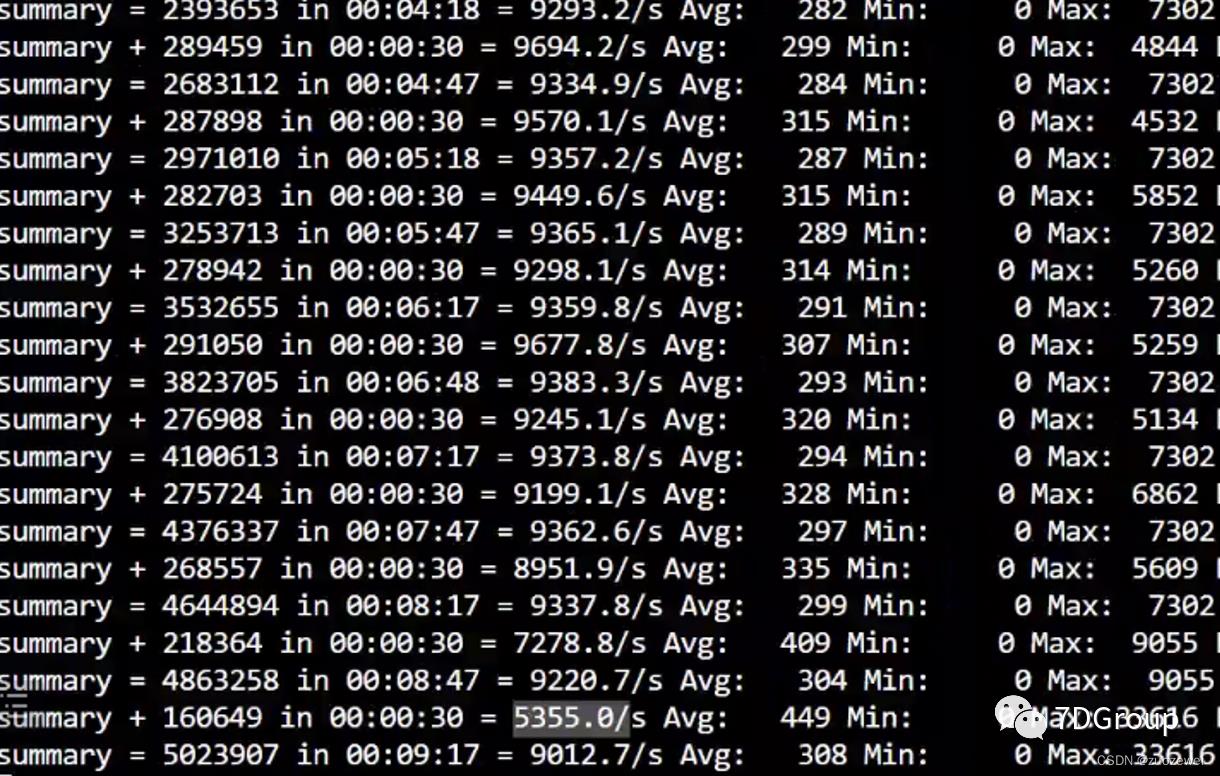
接近 10000 的业务级TPS。这样的业务级 TPS 量级,支持一个省的核酸检测场景是完全足够的。
对于四川成都市的这次故障,并不是容量要求更高的扫码系统故障,而是核酸采集的故障,要说对容量评估不足、带宽不足、后台系统故障等等原因导致的,做为供应商,你是怎么好意思说得出口呢?
各地疫情严重的时候,系统都或多或少的出现过技术问题,但大多是扫码系统,你一个核酸检测系统怎么好意思把故障归罪到技术层面呢?
是技术人员能力太差了吗?还是项目实施的过程管理有问题?
当然一个系统的故障不应该只把目光放在技术细节上,其中还有更复杂的因素。这个不能提,也不敢提。只有去悟了。
一个系统的容量要靠性能测试去做具体的评估,仅从技术细节去估计一个系统的容量是不行的,要从管理层、销售层、技术层(包括架构、开发、测试、运维等各个角度的技术)去评估一个系统。
系统的容量如果仅靠性能测试工程师的一个报告来判断结果,那就完全丢掉了性能工程的逻辑和方法论。
所以一个系统的容量评估是完整的性能工程级的活动,涉及面不仅有技术,还有非技术面,工程级的活动是需要系统的所有干系人都参与的,都要负起责任的,环环相扣,一环扣不上,就是系统级的故障!
以上是关于从核酸检测平台崩盘看性能工程的范围的主要内容,如果未能解决你的问题,请参考以下文章