上手DocumentDB On Azure
Posted Capt2008
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了上手DocumentDB On Azure 相关的知识,希望对你有一定的参考价值。
- 什么是Document?
DocumentDB基于PaaS(Platform-as-a-Service),是Microsoft配置在Azure上的一个数据服务
它通过:数据库账户,数据库,数据集来发挥作用.一个数据库账户下可以拥有多个数据库,每个数据库有可以拥有多个数据集合.
- 如何配置
DocumentDB 中的一致性级别:DocumentDB配置中有这个设置,暂且不管它是干什么的,先用默认再说。
DocumentDB 中的一致性级别
来自 <https://www.azure.cn/documentation/articles/documentdb-consistency-levels/>
|

创建好DoucmentDB之后Azure的仪表板(Dashboard)如下:
|
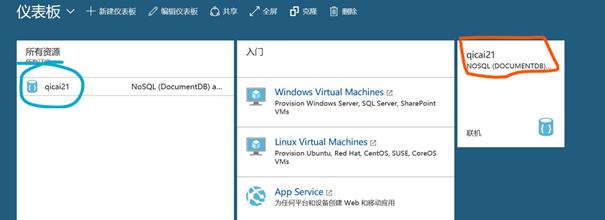
因为Azure的版本也在不停的更新,特别是DashBoard布局的更新,可能本笔记中的样式已经不一样了,内容大概相同就行。(2017-5-14)
- 在控制ConsoleApp中链接数据库
如何查到DocumentDB的Uri和PrimaryKey?
打开"键"页面后一片空白不要怕,点击"读写键"就出来了。读写键和只读键的区别应该是App端使用的键不同,访问数据库的权限也不同吧。
|
|


参照MongoDB来看DoucmentDB的链接创建过程:
MongoDB | DoucmentDB | |
DataRepositoryObject通常是通过Database来操作数据库的 | DataRepositoryObject通常包含如下 | |
创建Client; 利用Client.GetDatabase()方法拿到Database对象;
| 创建Client
他们的返回值类型都是ResourceResponse<Database>>类型 这里还涉及了UriFactory和Database两个类
通过对GetDatabaseAsync()方法的调用,来开看一下 | |
|
| |
ResourceResponse<Database>的成员1 |
ResourceResponse<Database>的成员2 | |

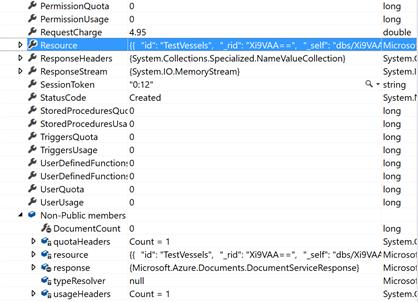
再看UriFactory.CreateDatabaseUri()返回的是个什么鬼Uri:啥也没有,估计也只有个OriginalString能用
|
这一步操作完成后,我们再Dashboard中已经可以看到我们刚刚建好的数据库了:
|

- 创建数据集
数据集由数据本身所占用的空间和索引数据所需要的索引缓存空间共同组成.创建一个数据集时,需要配置数据的索引策略.
如何从DoucumentDB中查询和操作数据,DocumentDB的索引策略是定义在DocumentCollection一级别的.
也就是说,在一个DocumentDatabase里,不同的数据集可以有不同的索引规则.
索引策略包含了:索引模式,索引路径的限制,索引使用的数据类型和精度
作为数据库小白的我,所能理解到的关于索引的概念是:
以下边的Vessel类型数据为例:
VesselObject
{
"id": | #int |
"name": | #string |
"type": | #enum -handy,-panama, -cape, -other |
"Imo": | #int |
"nationality": | #string |
"size":{"loa":,"wid":} | #{double,double} |
"description" | #string |
}
- 索引规则直接影响了基本库的大小(就是在Azure上为目标数据存储所开辟的基本的空间),这是因为同样的数据(),如果只支持id索引,那么这个数据集的索引层就会小的多,而增加了imo和type和nationality索引后,索引层就会大很多.
- 索引规则直接影响了cpu开销:一次查询如果索引是根据vsl的id,假设有100条数据,那么Azure的cpu开销是要比根据某个string值遍历所有vslitem.description所造成的开销小的多得多.
- 索引规则同时也影响了网络流量的大小:比如现在要查找一个vsl,中国籍,handysize,船宽22米以下的船,如果索引只支持ID索引,那么不得不返回所有记录给客户端,或1个也不返回(因为无法匹配数据);如果只支持nationality和type的索引,那么将返回所有中国籍的handy,假设共计200条;如果全部条件索引都支持,那么将返回10条船.因此而产生的流量也是不同的.
那么磁盘空间的大小,计算资源的开销和流量三种资源都会影响Azure的计费.因此如何合理配置collection的indexpolicy属性就显得十分重要了.
DocumentDB的索引策略和索引模式和索引精度DocumentDB的IndexingPolicy&IndexingMode&IndexingPrecision
索引模式:public enum IndexingMode: Consistent,Lazy,None
数据库索引模式 DocumentDB 支持三种索引模式,可通过索引策略对 DocumentDB 集合进行配置:一致、延迟和无。 一致︰如果将 DocumentDB 集合的策略指定为"一致",针对指定 DocumentDB 集合的查询将按照为点读取指定的一致性级别进行(即强、有限过期性、会话或最终)。索引会作为文档更新(即插入、替换、更新和删除 DocumentDB 集合中的文档)的一部分进行同步更新。一致索引支持一致的查询,但代价是可能降低写入吞吐量。这种减少受需要索引的唯一路径和"一致性级别"的影响。一致的索引模式适用于"快速写入、立即查询"工作负荷。 延迟︰若要实现最大的文档引入吞吐量,可为 DocumentDB 集合配置延迟一致性;也就是说,查询最终是一致的。DocumentDB 集合处于静止状态时(即为用户请求提供服务时没有完全利用集合的吞吐量),将以异步方式更新索引。对于需要无阻碍文档引入的"现在引入、稍后查询"工作负荷,可能适合"延迟"索引模式。 无︰索引模式标记为"无"的集合没有与之关联的索引。如果 DocumentDB 用作键值存储,并且只通过其 ID 属性访问文档,则通常使用该模式。
来自 <https://www.azure.cn/documentation/articles/documentdb-indexing-policies/>
|
官方介绍简直不是人话啊,看了半天撸出个大概的意思就是数据改变之后什么时候可以在索引层查得到,一致就是不论系统忙不忙,任何数据的改变都即刻更新到索引层,延迟就是不忙的时候更新,一会儿就能查到;无就是对数据值的改变根本不反应到索引层,只通过数据的键能检索到数据.
而更多关于索引策略参见:
索引路径来自 <https://docs.microsoft.com/zh-cn/azure/documentdb/documentdb-indexing-policies>
索引数据类型、种类和精度来自 <https://docs.microsoft.com/zh-cn/azure/documentdb/documentdb-indexing-policies>
按照Guidance中的方法执行完后,可以看到新建的collection的属性如下图,其中默认的IndexingMode为Consistent.
|

再来看Azure的Dashboard,新建的数据集显示出来了.
|

- 创建数据
- 增改删查
以上是关于上手DocumentDB On Azure 的主要内容,如果未能解决你的问题,请参考以下文章