hadoop hadoop 单机伪分布式安装
Posted xwolf
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop hadoop 单机伪分布式安装相关的知识,希望对你有一定的参考价值。
准备:
虚拟机(CentOS 6.9)
JDK1.8
hadoop2.8.0
一.JDK安装及配置
rpm -ivh jdkxxxx 安装
配置环境变量
vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_121 export PATH=$JAVA_HOME/bin:$PATH export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
source /etc/profile 使其立即生效
java -version 验证

二. hadoop 下载安装
官网下载:http://hadoop.apache.org/releases.html ,下载 2.8.0 版本。
解压缩到 /opt/hadoop/下
此处用root 用户来操作hadoop(推荐用新添加用户来操作).
开始配置hadoop
1. hadoop-env.sh
配置java
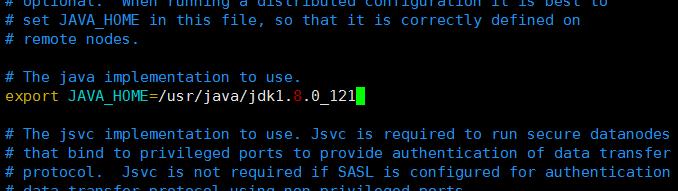
2. core-site.xml
<configuration> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop/hadoop/data</value> </property> <property> <name>fs.default.name</name> <value>hdfs://hadoop02:9000</value> </property> </configuration>
3. hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/opt/hadoop/hadoop/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/opt/hadoop/hadoop/dfs/data</value> </property> </configuration>
4.mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
5.yarn-env.sh
修改java
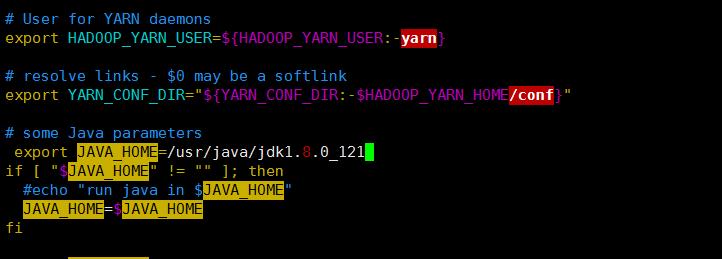
6. yarn-site.xml
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
三.启动hadoop
执行 hdfs namenode -format
启动hadoop
start-all.sh
停止hadoop
stop-all.sh
四、验证
jps 查看
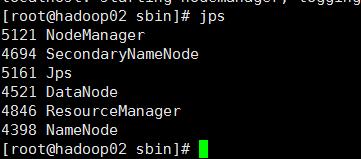
表示启动成功。
浏览器 输入 http://localhost:50070 查看hdfs 状态

查看yarn 信息 http://localhost:8088

各个配置的详细信息 参考官网:
以上是关于hadoop hadoop 单机伪分布式安装的主要内容,如果未能解决你的问题,请参考以下文章