Cloudera :一些关键组件的角色信息
Posted 花和尚也有春天
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Cloudera :一些关键组件的角色信息相关的知识,希望对你有一定的参考价值。

Hadoop 大数据平台集群角色简称如图:

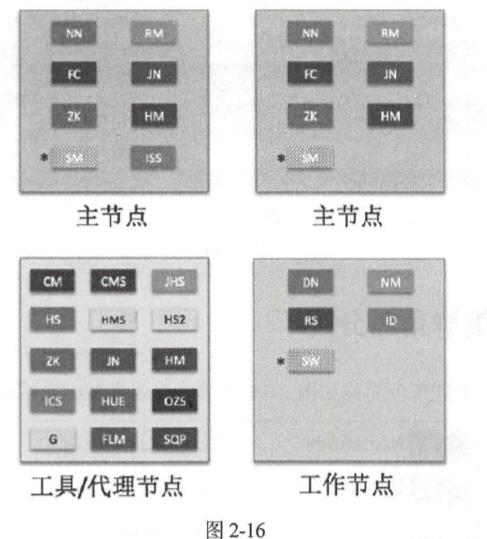
(1)搭建小规模集群一般是为了支撑专有业务,受限于集群的存储和处理能力,不太适合用于多业务的环境。可以部署成一个 HBase 的集群,也可以部署成一个分析集群,包含 YA阳、 Impala。在小规模集群中,为了最大化利用集群的存储和处理能力,节点的复用程度往往比较高, 如图 2-16 所示。对于那些需要两个以上节点来支持 HA 功能的,集群中分配有一个工具节点可以 承载这些角色,并可以同时部署一些其他工具角色(这些工具角色本身消耗不了多少资源),其余 节点可以部署为纯工作节点。
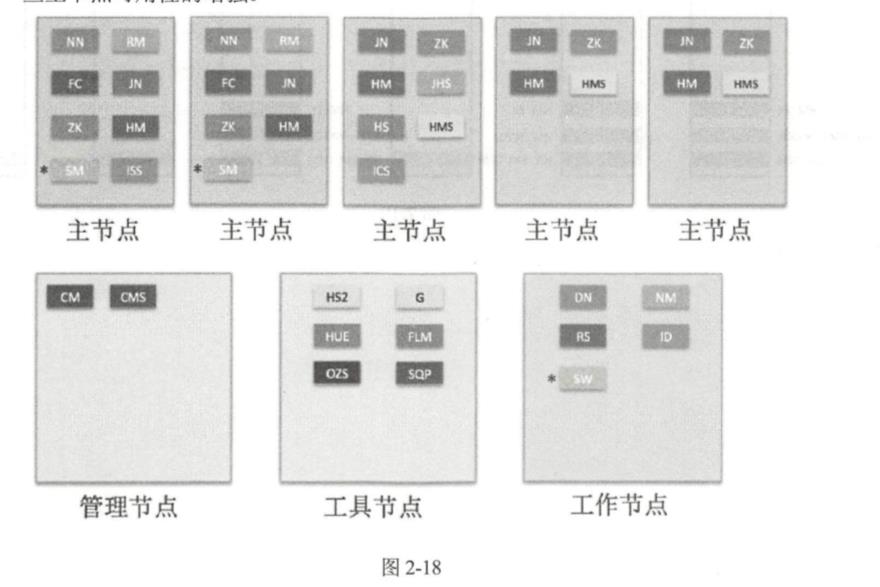
(2)对于一个中等规模的集群,节点数一般在 20 ~ 200,通常的数据存储可以规划到几百太字节,适用于一个中型企业的数据平台或者大型企业的业务部门数据平台。节点的复用程度可以降 低,可以按照管理节点、主节点、工具节点和工作节点来划分,如图 2-17 所示。
管理节点上安装 Cloudera Manager、 Cloudera Management Servie。主节点上安装 CDH 服务以 及 HA 的组件。工具节点部署 HiveServer2、 Hue Server、 Oozie Server、 Flum巳 Agent、 Sqoop Client、 Gateway。工作节点的部署和小规模集群类似。
(3 )大规模集群的数量一般会在 200 以上,存储容量可以是几百太字节(TB )甚至是拍字节 (PB )级别,适用于大型企业搭建全公司的数据平台,如图 2-18 所示。 这里 HDFS Jouma!Node 由 3 个增加到 5 个, ZooKeeper Server 和 HBase Master 也由 3 个增加 到 5 个, Hive Metastore 的数量由 1 个增加到 3 个。和中等规模的集群相比,部署的方案相差不大, 主要是一些主节点可用性的增强。
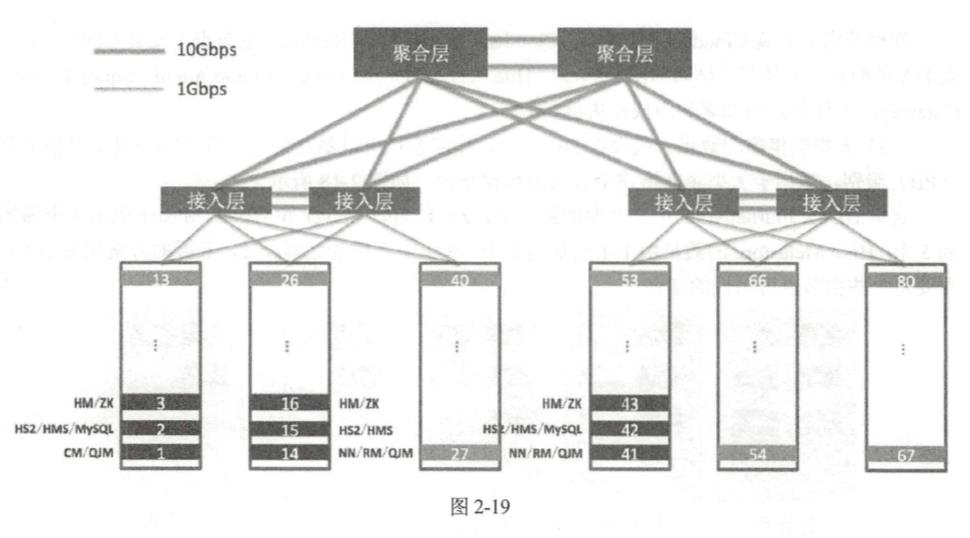
网络拓扑
对于一个小规模的集群或者单个 rack 的集群,所有的节点都连接到相同的接入层交换机。接 入层交换机配置为堆叠的方式,互为冗余井增加了交换机吞吐。所有的节点两个网卡配置为主备或 者负载均衡模式,分别连入两个交换机。在这种部署模式下,接入层交换机充当了聚合层的角色。 在多机架的部署模式下,除了接入层交换机,还需要聚合层交换机,用于连接各接入层交换 机,负责跨 rack 的数据存取。 在机架上分配角色时,为了避免接入层交换机的故障导致集群的不可用,需要将一些高可用 的角色部署到不同的接入层交换机之下(注意是不同的接入层之下,而不是不同的物理 rack 下, 很多时候,客户会将不同物理 rack 下的机器接入到相同的接入层交换机下) 。 一个 80 个节点的物 理部署示例如图 2-19 所示。

以上是关于Cloudera :一些关键组件的角色信息的主要内容,如果未能解决你的问题,请参考以下文章