1.Google文件系统(GFS)
使用一堆便宜的商用计算机支撑大规模数据处理。
GFSClient: 应用程序的訪问接口
Master(主控server):管理节点。在逻辑上仅仅有一个(另一台“影子server“,在主控server失效时提供元数据,但并非完整的热备server),保存系统的元数据,负责整个文件系统的管理。
Chunk Server(数据库server):负责详细的存储工作,数据以文件的形式存储在Chunk Server上;对应GFSclient的读写请求。
总体架构:
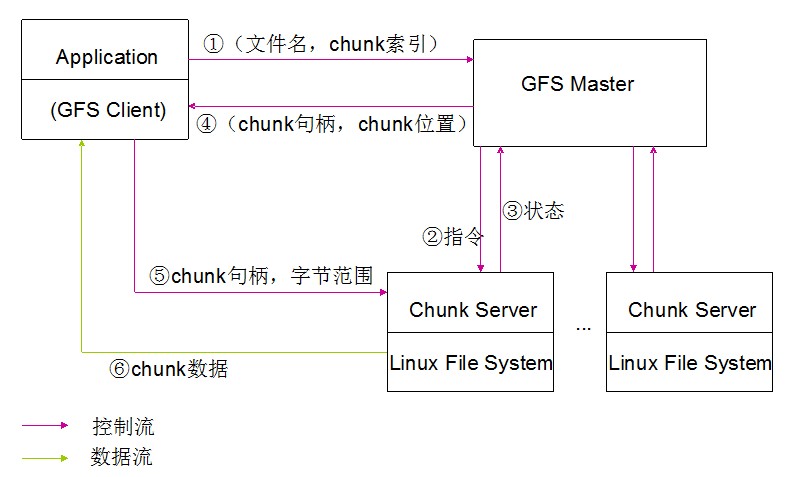
读取数据的流程:
应用开发人员提交读数据请求: 读取文件file,从某个位置P開始。读出大小为L的数据。
GFS系统收到这样的请求后。在内部做转换,由于Chunk大小固定,所以从位置P和大小L能够推算出要读的数据位于file的第几个chunk,即请求被转换为<文件file,Chunk序列号>的形式。
随后,GFS系统将这个请求发送给主控server,由于主控server保存了一些管理信息,通过主控server能够知道要读的数据在哪台Chunkserver上,同一时候把Chunk序号转化为系统内唯一的Chunk编号,把这两个信息传回到GFSclient。
GFS和对应的Chunkserver建立联系。发送要读取的Chunk编号和读取范围。Chunkserver接到请求后把请求数据发送给GFSclient。
採用这样的主从结构的优劣:
优点:管理相对简单
坏处:非常多服务请求都经过主控server,easy成为整个系统的瓶颈。可能存在单点失效问题。
PS:要做数据冗余,每一个Chunk多个备份在不同的Chunkserver上。
写数据的流程:
GFS系统必须把这个写操作应用到Chunk的全部备份。为了方便管理,GFS从多个相互备份的Chunk中选出一个主备份,其它的作为次级备份,由主备份决定次级备份的数据写入顺序。
GFSclient首先和主控server通信,获知哪些Chunkserver存储了要写入的Chunk,包含主备份和其它的次级备份的地址数据,然后GFSclient将要写入的数据推送给全部的备份Chunk,备份Chunk首先将这些待写入的数据放在缓存中,然后通知GFSclient是否接受成功。假设全部的备份都接受数据成功。GFSclient通知主备份可运行写入操作,主备份将自己缓存的数据写入Chunk。通知次级备份依照指定顺序写入数据。次级备份写完后答复主备份写入成功。主备份才会通知GFSclient这次写操作成功完毕。假设待写入的数据跨Chunk或者须要多个Chunk才干容纳,client自己主动将其分解为多个写操作。
Colossus
Google下一代GFS分布式文件系统,几个改进例如以下:
将单一主控server改造为多主控server构成的集群。将全部管理数据进行数据分片后分配到不同的主控server上。
Chunk数据的多个备份尽管添加了系统可用性。可是付出了很多其它的存储成本,一种常见的折中方案是採用纠删码算法。
Colossus的client能够依据需求指定数据存放地点。
PS:
纠删码算法的基本原理例如以下:
给定n个数据块d1, d2,..., dn,n和一个正整数m。 RS依据n个数据块生成m个校验块。 c1, c2,..., cm。 对于随意的n和m, 从n个原始数据块和m
个校验块中任取n块就能解码出原始数据, 即RS最多容忍m个数据块或者校验块同一时候丢失(纠删码仅仅能容忍数据丢失。无法容忍数据篡改,纠删码正是得名与此)。
关于纠删码的很多其它细节能够參考:http://blog.sina.com.cn/s/blog_3fe961ae0102vpxu.html
关于数据可靠性:对冷数据进行编码冗余,对热数据进行副本冗余。(前者降低存储成本,后者降低计算成本,应该非常好理解)
2.HDFS
是Hadoop中的大规模分布式文件系统,在整个架构上与GFS大致同样,更简化,比方同一时刻仅仅同意一个client对文件进行追加写操作。
它具有下面几个特点:
1)适合存储很大的文件
2)适合流式数据读取。即适合“仅仅写一次,读多次”的数据处理模式
3)适合部署在便宜的机器上
但HDFS不适合下面场景(不论什么东西都要分两面看。仅仅有适合自己业务的技术才是真正的好技术):
1)不适合存储大量的小文件。由于受Namenode内存限制大小
2)不适合实时数据读取,高吞吐量和实时性是相悖的,HDFS选择前者
3)不适合须要常常改动数据的场景
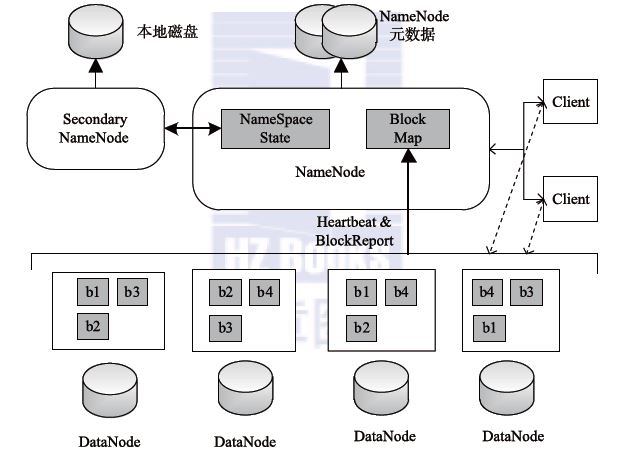
总体架构
由NameNode,DataNode。Secondary NameNode以及client组成。
NameNode
(
负责管理整个分布式文件系统的元数据,包含文件文件夹树结构、文件到数据块的映射关系、Block副本及其存储位置等各种管理数据。
这些数据保存在内存中。
还负责DataNode的状态监控。通过心跳来传递管理信息和数据信息。
Secondary NameNode
职责并不是是NameNode的热备机,而是定期从NameNode拉取fsimage(内存命名空间元数据在外存的镜像文件))和editlog文件(各种元数据操作的write-ahead-log
文件。在体现到内存数据变化前先把操作记录到此文件防止数据丢失)并对这两个文件进行合并。形成新的fsimage文件并传回给NameNode,以减轻NameNode的工作压力。
DataNode
类似于GFS的Chunkserver。负责数据块的实际存储和读写。
client
与GFSclient类似。HDFSclient和NameNode联系获取所需读/写文件的元数据,实际的数据读写都是和DataNode直接通信完毕的。
HA方案
主控server由Active NameNode和Standby NameNode一主一从两台server构成,ANN是当前响应client请求的server,SNN是冷备份或者热备份机。
为了使SNN成为热备份机,SNN的全部元数据须要与ANN元数据保持一致。通过下面两点来保证这一要求:
1.使用第三方共享存储来保存文件夹文件等命名空间元数据。
本质是把NN的单点失效问题转换成第三方存储的单点失效问题,可是第三方存储自带非常强的冗余和容错机制。所以可靠性较强。
2.全部DataNode同一时候把心跳信息发送给ANN和SNN。
增加独立于NN之外的故障切换控制器,在ANN故障时。选举SNN为主控server。在Hadoop系统刚刚启动时,两台都是SNN。通过选举使得某台成为ANN。
由此要增加隔离措施防止脑裂现象(即同一时候有多个活跃的主控server):
1)同一时刻上仅仅有一个NN可以写入第三方共享存储
2)仅仅有一个NN发出与管理数据副本有关的删除命令
3)同一时刻是有一个NN可以对client请求发出正确对应
解决方式:
QJM:
利用Paxos协议。在2F+1GE JournalNode中存储NN的editlog,每次写入操作假设有F台server返回成功就可以觉得成功写入。
最多能够容忍F个Journal Node同一时候故障。
NameNode联盟
核心思想:把一个大的命名空间分割为若干子命名空间,每一个子命名空间由单独的NN负责管理,NN之间独立,全部DataNode被共享。
DataNode和子命名空间之间由数据块管理层建立映射关系,数据块管理层由若干数据块池构成。每一个数据块唯一属于某个固定的数据块池,一个子命名空间能够相应多个数据块池。
ps:HDFS看的云里雾里。以后研究Hadoop的时候再好好回想吧。