SQLAlchemy
Posted pyrene
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQLAlchemy相关的知识,希望对你有一定的参考价值。
一、介绍
SQLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作,简言之便是:将对象转换成SQL,然后使用数据API执行SQL并获取执行结果。
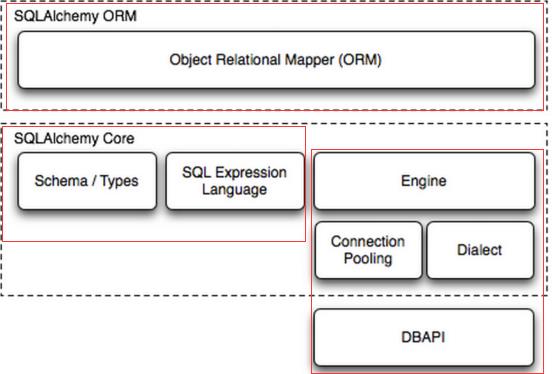
这是分了三层,上层和下面两层
ORM是用类来封装的
SQLALCHEMY Core 是用函数封装的,是核心层,不是执行数据库语句,是吧写成的类,翻译成sql语句
执行流程顺序:
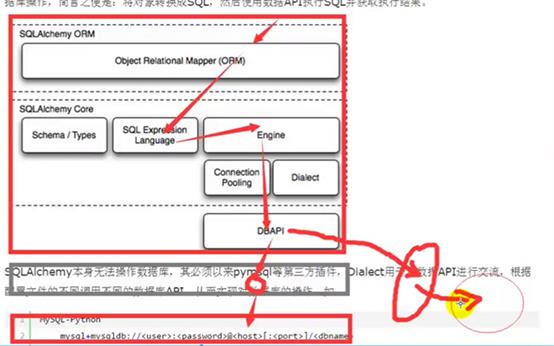
创建类,先通过上面的连接,经过DBAPI连接第三方插件,把类转化成sql语句,这里的第三方插件
SQLAlchemy本身无法操作数据库,其必须以来pymsql等第三方插件,Dialect用于和数据API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作,如:
mysql-Python mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname> pymysql mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>] MySQL-Connector mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname> cx_Oracle oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...] 更多详见:http://docs.sqlalchemy.org/en/latest/dialects/index.html
具体细节:
通过Engine引擎找到pooling,这里其实就是一个数据库连接池,在数据库连接池里面连接就找到Dialect就相当于一个大字典,字典里面有很多很多的(如mysql,oracle,mongodb)等的选项,找到选项,带着选项去DBAPI里面找到第三方插件,然后连接数据库。这里的dialect就是进行选择到底用那个插件来选择数据库
底层处理
思想:
1、首先连接数据库
2、执行sql,拿到游标
3、获取数据
一、


#!/usr/bin/env python # -*- coding:utf-8 -*- from sqlalchemy import create_engine engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/t1", max_overflow=5) 连接数据库 # 执行SQL,拿到游标 # cur = engine.execute( # "INSERT INTO hosts (host, color_id) VALUES (\'1.1.1.22\', 3)" # ) # 新插入行自增ID # cur.lastrowid # 执行SQL # cur = engine.execute( # "INSERT INTO hosts (host, color_id) VALUES(%s, %s)",[(\'1.1.1.22\', 3),(\'1.1.1.221\', 3),] # ) # 执行SQL # cur = engine.execute( # "INSERT INTO hosts (host, color_id) VALUES (%(host)s, %(color_id)s)", # host=\'1.1.1.99\', color_id=3 # ) # 执行SQL # cur = engine.execute(\'select * from hosts\') # 获取第一行数据 # cur.fetchone() # 获取第n行数据 # cur.fetchmany(3) # 获取所有数据 # cur.fetchall()
#!/usr/bin/env python # -*- coding:utf-8 -*- from sqlalchemy import create_engine engine = create_engine("mysql+mysqldb://root:123@127.0.0.1:3306/s11", max_overflow=5) # 事务操作 with engine.begin() as conn: conn.execute("insert into table (x, y, z) values (1, 2, 3)") conn.execute("my_special_procedure(5)") conn = engine.connect() # 事务操作 with conn.begin(): conn.execute("some statement", {\'x\':5, \'y\':10})
注:查看数据库连接:show status like \'Threads%\';
二:
使用 Schema Type/SQL Expression Language/Engine/ConnectionPooling/Dialect 进行数据库操作。Engine使用Schema Type创建一个特定的结构对象,之后通过SQL Expression Language将该对象转换成SQL语句,然后通过 ConnectionPooling 连接数据库,再然后通过 Dialect 执行SQL,并获取结果。
#!/usr/bin/env python # -*- coding:utf-8 -*- from sqlalchemy import create_engine, Table, Column, Integer, String, MetaData, ForeignKey metadata = MetaData() user = Table(\'user\', metadata, Column(\'id\', Integer, primary_key=True), Column(\'name\', String(20)), ) color = Table(\'color\', metadata, Column(\'id\', Integer, primary_key=True), Column(\'name\', String(20)), ) engine = create_engine("mysql+mysqldb://root:123@127.0.0.1:3306/s11", max_overflow=5) metadata.create_all(engine) # metadata.clear() # metadata.remove()
#!/usr/bin/env python # -*- coding:utf-8 -*- from sqlalchemy import create_engine, Table, Column, Integer, String, MetaData, ForeignKey metadata = MetaData() user = Table(\'user\', metadata, Column(\'id\', Integer, primary_key=True), Column(\'name\', String(20)), ) color = Table(\'color\', metadata, Column(\'id\', Integer, primary_key=True), Column(\'name\', String(20)), ) engine = create_engine("mysql+mysqldb://root:123@127.0.0.1:3306/s11", max_overflow=5) conn = engine.connect() # 创建SQL语句,INSERT INTO "user" (id, name) VALUES (:id, :name) conn.execute(user.insert(),{\'id\':7,\'name\':\'seven\'}) conn.close() # sql = user.insert().values(id=123, name=\'wu\') # conn.execute(sql) # conn.close() # sql = user.delete().where(user.c.id > 1) # sql = user.update().values(fullname=user.c.name) # sql = user.update().where(user.c.name == \'jack\').values(name=\'ed\') # sql = select([user, ]) # sql = select([user.c.id, ]) # sql = select([user.c.name, color.c.name]).where(user.c.id==color.c.id) # sql = select([user.c.name]).order_by(user.c.name) # sql = select([user]).group_by(user.c.name) # result = conn.execute(sql) # print result.fetchall() # conn.close()
二、sqlalchemy基本使用
#/usr/bin/env python import sqlalchemy from sqlalchemy import create_engine from sqlalchemy .ext.declarative import declarative_base from sqlalchemy import Column,INTEGER,String from sqlalchemy.orm import sessionmaker print(sqlalchemy.__version__) #连接数据库 engine=create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/com") #生成一个url基类 Base=declarative_base() #写一个类,这个类代表一张表 class User(Base): 给这个表起名字 __tablename__="users" #字段属性,主键属性:非空且唯一,autoincrement=True自增 id=Column(INTEGER,primary_key=True,autoincrement=True) name=Column(String(40),index=True) #添加普通索引 fullname=Column(String(40),unique=True) #添加唯一索引 password=Column(String(40)) #以正常的方式来显示,但是显示出来的还是对象 def __repr__(self): return self.name #创建所有表结构 engine(引擎) Base.metadata.create_all(engine) #删除表,这里删除所有表 # Base.metadata.drop_all(engine) # ed_user=User(name="pyrene",fullname="pyrene wang",password="123") # print(ed_user) #这里对象加上括号就是执行call方法 MySession=sessionmaker(bind=engine) session=MySession() #把数据添加到session # session.add(ed_user) #如果要添加多条数据,那么需要 session.add_all([ User(name="aa",fullname="aaa",password="123"), User(name="bb",fullname="bbb",password="456"), User(name="cc",fullname="ccc",password="789") ]) #提交数据 session.commit() #查询表内容 这个要和__repr__方法来显示 print(session.query(User).all()) #遍历按照从大到小来排列 遍历方法一 # for row in session.query(User).order_by(User.id): # print(row) #遍历表内容,如果内容和列表中的匹配,那么就打印出来 # for row in session.query(User).filter(User.name.in_(["aa","bb","dd"])): # print(row) #遍历表内容,获取不是列表中匹配的内容 # for row in session.query(User).filter(~User.name.in_(["aa","bb"])): # print(row) #查询表内容获取表名字等于aa的个数 # print(session.query(User).filter(User.name=="aa").count()) # from sqlalchemy import and_,or_ # #这个是如果name为aa并且fullname为aaa的时候,遍历出来 # # for row in session.query(User).filter(and_(User.name=="aa",User.fullname=="aaa")): # # print(row) # #这个是如果name为aa的时候或者fullname为bbb的时候,就遍历这个表 # for row in session.query(User).filter(or_(User.name=="aa",User.fullname=="bbb")):
filter()是过滤:括号里面放的都是条件判断 注意:(==两个等号属于条件)
filter_by()过滤:括号中里面必须是键值对的方式 注意:(=属于键值对,赋值)
1、 连接数据库
2、 生成url基类
3、 写一张表,并且添加字符,在字段中放入属性
4、 添加打印对象的属性
5、 添加引擎
6、 添加表,或者删除表
7、 为对象添加call方法,获取session对象
8、 把数据添加到session对象里面
9、 提交到数据库
三、ORM之一对多
#!/usr/bin/env python # -*- coding:utf-8 -*- from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index from sqlalchemy.orm import sessionmaker, relationship from sqlalchemy import create_engine engine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/com") Base=declarative_base() class Men(Base): __tablename__ = \'men\' id = Column(Integer, primary_key=True) name = Column(String(32)) age= Column(String(16)) # __table_args__ = ( # UniqueConstraint(\'id\', \'name\', name=\'uix_id_name\'), # Index(\'ix_id_name\', \'name\', \'extra\'), # ) def __repr__(self): return self.name class Women(Base): __tablename__ =\'women\' id = Column(Integer, primary_key=True) name = Column(String(32)) age= Column(String(16)) #这个在那个表中,那个就是多的 men_id=Column(Integer, ForeignKey(\'men.id\')) # def __repr__(self): # return self.age Base.metadata.create_all(engine) # Base.metadata.drop_all(engine) # Session = sessionmaker(bind=engine) # session = Session() # select * from # select id,name from women # sql=session.query(Women).all() # select * from women inner join men on women.men_id = men.id # sql = session.query(Women.age,Men.name).join(Men).all() # print(sql) # print(sql) # r = session.query(session.query(Women.name.label(\'t1\'), Men.name.label(\'t2\')).join(Men).all()).all() # print(r) # r = session.query(Women).all() # print(r) # m1=Men(name=\'alex\',age=18) # w1=Women(name=\'如花\',age=40) # w2=Women(name=\'铁锤\',age=45) # m1.gf=[Women(name=\'如花\',age=40),Women(name=\'铁锤\',age=45)] # m1=Men(name=\'alex\',age=18) # w1=Women(name=\'如花\',age=40,men_id = 1) # w2=Women(name=\'铁锤\',age=45,men_id = 1) # session.add_all([w1,w2]) # session.commit()
!/usr/bin/env python # -*- coding:utf-8 -*- from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index from sqlalchemy.orm import sessionmaker, relationship from sqlalchemy import create_engine engine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/com") Base = declarative_base() class Son(Base): __tablename__ = \'son\' id = Column(Integer, primary_key=True) name = Column(String(32)) age= Column(String(16)) #foreugnkey就是多的那边 father_name=Column(Integer,ForeignKey(\'father.id\')) #relationship 是基于join的方法来做的,关联两个表。下面通过对象来产生联系 father=relationship(\'Father\') # __table_args__ = ( # UniqueConstraint(\'id\', \'name\', name=\'uix_id_name\'), # Index(\'ix_id_name\', \'name\', \'extra\'), # ) class Father(Base): __tablename__ =\'father\' id = Column(Integer, primary_key=True) name = Column(String(32)) age= Column(String(16)) son=relationship(\'Son\') Base.metadata.create_all(engine) #删除表 # Base.metadata.create_all(engine) Session = sessionmaker(bind=engine) session = Session() #添加数据,并且让其完成一对多 f1=Father(name=\'alvin\',age=50) w1=Son(name=\'little alvin1\',age=4) w2=Son(name=\'little alvin2\',age=5) #这里的son是relationship的对象 f1.son=[w1,w2] session.add_all([f1,w1,w2]) session.commit()
1、 创建两张表,一张son一张father,
2、 在son中创建foreignkey创建外键,对应father。也就是son是多,father是一。之后在son中创建relationship,并且声成对象,关联father和son这两张表
3、 创建Base下的所有表结构,对应的引擎
4、 执行call方法
5、 为两张表添加数据,并且把这些数据生成对象
6、 根据relationship对象添加上面创建的对象放入到father表中,之后提交
#!/usr/bin/env python # -*- coding:utf-8 -*- from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index from sqlalchemy.orm import sessionmaker, relationship from sqlalchemy import create_engine engine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/com") Base = declarative_base() class Son(Base): __tablename__ = \'son\' id = Column(Integer, primary_key=True) name = Column(String(32)) age= Column(String(16)) #foreugnkey就是多的那边 father_id=Column(Integer,ForeignKey(\'father.id\')) #relationship 是基于join的方法来做的,关联两个表。下面通过对象来产生联系 father=relationship(\'Father\') # __table_args__ = ( # UniqueConstraint(\'id\', \'name\', name=\'uix_id_name\'), # Index(\'ix_id_name\', \'name\', \'extra\'), # ) class Father(Base): __tablename__ =\'father\' id = Column(Integer, primary_key=True) name = Column(String(32)) age= Column(String(16)) son=relationship(\'Son\') Base.metadata.create_all(engine) # # 删除表 # Base.metadata.drop_all(engine) Session = sessionmaker(bind=engine) session = Session() # 另一种方式 f1=Father(name="aa",age=50) session.add(f1) session.commit() w1=Son(name="aaa",age=11,father_id=1) w2=Son(name="aaaa",age=25,father_id=1) session.add_all([f1,w1,w2]) session.commit()
这里不是用的relationship的方式而是首先创建father的数据,之后把这些数据提交到数据库,之后再创建son对象,对应之后上传到数据库
1、 通过father找son的信息 首先在father中创建son=relationship(“son”),或者在son中添加father=relation(“father”,backref=”son”) 之后在下面创建father对象 再找到son,对象.son,由于father对应多个son,所以要遍历 2、 通过son找father的信息 在son中创建father=relationship(“father”),或者在father中添加son=relationship(“son”,backref=”father”) 之后创建son对象 由于这里所有的son只对应一个father,所以 直接用对象.father就能找到father的对象然后用.id等的方法找到对应的信息 3、让两个表建立关系 #这里就是前面father和后面joinson,也就是father INNER JOIN son ON father.id = son.father_id # ret=session.query(Father).join(Son) #这里查找出father对应的son中的名字后面all方法,是获取所有,这里也可以用first方法 #这里的join比着sql语句少一个on的原因是因为上面的relationship的方法已经创建了关系,替代了on # ret=session.query(Father.name,Son.name).join(Son).all() # print(ret)
#!/usr/bin/env python # -*- coding:utf-8 -*- from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index from sqlalchemy.orm import sessionmaker, relationship from sqlalchemy import create_engine engine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/com") Base = declarative_base() class Son(Base): __tablename__ = \'son\' id = Column(Integer, primary_key=True) name = Column(String(32)) age= Column(String(16)) #foreugnkey就是多的那边 father_id=Column(Integer,ForeignKey(\'father.id\')) #relationship 是基于join的方法来做的,关联两个表。下面通过对象来产生联系 father=relationship(\'Father\',backref="son") # __table_args__ = ( # UniqueConstraint(\'id\', \'name\', name=\'uix_id_name\'), # Index(\'ix_id_name\', \'name\', \'extra\'), # ) class Father(Base): __tablename__ =\'father\' id = Column(Integer, primary_key=True) name = Column(String(32)) age= Column(String(16)) #这里面绑定的是类,这个不会在表中出现 # son=relationship(\'Son\',backref="father") Base.metadata.create_all(engine) # 删除表 # Base.metadata.drop_all(engine) Session = sessionmaker(bind=engine) session = Session() #这里就是前面father和后面joinson,也就是father INNER JOIN son ON father.id = son.father_id # ret=session.query(Father).join(Son) #这里查找出father对应的son中的名字后面all方法,是获取所有,这里也可以用first方法 #这里的join比着sql语句少一个on的原因是因为上面的relationship的方法已经创建了关系,替代了on # ret=session.query(Father.name,Son.name).join(Son).all() # print(ret) #获取一个对象,这里的filter_by的方法括号里面是放的键值对。后面用first方法才是一个对象,all方法是获取的列表 f1=session.query(Father).filter_by(id=1).first() #上面创建了relationship这样就能获取和father绑定的son的信息 # print(f1.son) # for i in f1.son: # print(i.name) #这里是根据上面的relationship创建了 w3,然后根据父亲对象的son的列表中添加一个son w3=Son(name="little alvin",age=5) f1.son.append(w3) #创建son的对象,查找某一个确定的son s1=session.query(Son).filter_by(id=2).first() #这里是多找一,由于所有的son都只对应一个father,所以直接用son.father就能找到father对象 print(s1.father.name) # # 添加数据,并且让其完成一对多 # f1=Father(name=\'alvin\',age=50) # # w1=Son(name=\'little alvin1\',age=4) # w2=Son(name=\'little alvin2\',age=5) # # #这里的son是relationship的对象 # f1.son=[w1,w2] # # # # # 另一种方式 # # # f1=Father(name="aa",age=50) # # # session.add(f1) # # # session.commit() # # # w1=Son(name="aaa",age=11,father_id=1) # # # w2=Son(name="aaaa",age=25,father_id=1) # # session.add_all([f1,w1,w2]) # session.commit()
四、ORM多对多实例
1、创建第三章表的时候,要放到那两张表的最上面,因为如果不放到最上面会找不到
这里创建relationship的时候要和第三章表创建关系,relationship里面的secondary表示:如果创建的有第三章表,那么就必须要加入里面,并且要在后面加入.__table__
2、 创建第三章表,要在前两张表中和第三张表中创建关系。所以用到relationship这里用relathionship有两种方法
第一种方法在Women中和men中分别添加
a) bf=relationship("Men",secondary=Men_to_Wemon.__table__)
b) gf=relationship("Women",secondary=Men_to_Wemon.__table__)
第二种方法,用backref的方法,这是在Women中添加的
bf=relationship("Men",secondary=Men_to_Wemon.__table__,backref=\'gf\')
3、如果往数据库中添加的数据中有中文,那么需要在连接数据库的时候声明是utf8的方式
#!/usr/bin/env python # -*- coding:utf-8 -*- from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index from sqlalchemy.orm import sessionmaker, relationship from sqlalchemy import create_engine engine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/com?charset=utf8") Base = declarative_base() class Men_to_Wemon(Base): __tablename__ = \'men_to_wemon\' nid = Column(Integer, primary_key=True) men_id = Column(Integer, ForeignKey(\'men.id\')) women_id = Column(Integer, ForeignKey(\'women.id\')) class Men(Base): __tablename__ = \'men\' id = Column(Integer, primary_key=True) name = Column(String(32)) age= Column(String(16)) gf=relationship("Women",secondary=Men_to_Wemon.__table__) class Women(Base): __tablename__ =\'women\' id = Column(Integer, primary_key=True) name = Column(String(SQLAlchemy的同步和异步的代码对比