spss:得到一个多元线性回归模型之后,如何比较预测值和真实值?如何判断模型是不是有预测能力?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spss:得到一个多元线性回归模型之后,如何比较预测值和真实值?如何判断模型是不是有预测能力?相关的知识,希望对你有一定的参考价值。
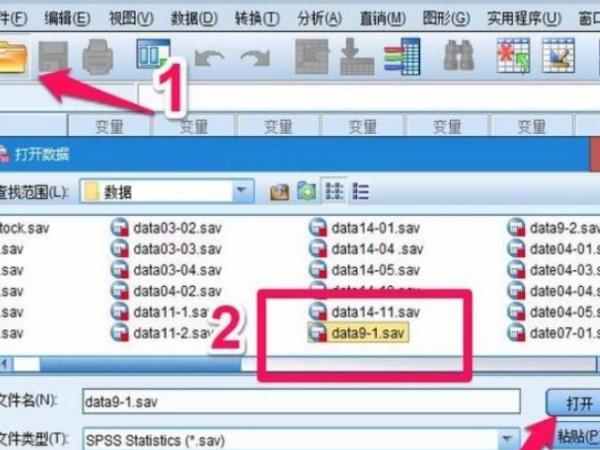
1、打开SPSS软件后点击右上角的【打开文件按钮】打开你需要分析的数据文件。
2、接下来就是开始做回归分析建立模型,研究其变化趋势,因为回归分析分为线性回归和非线性回归,分析它们的办法是不同的,所以先要把握它们的变化趋势,可以画散点图,点击【图形】---【旧对话框】---【散点/点状】。
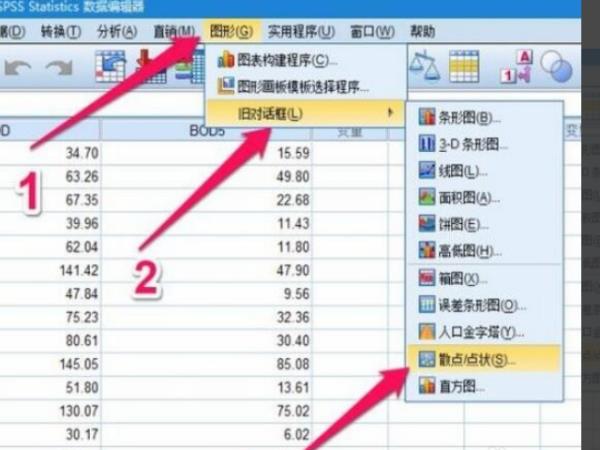
3、选择【简单分布】,并点击【定义】。

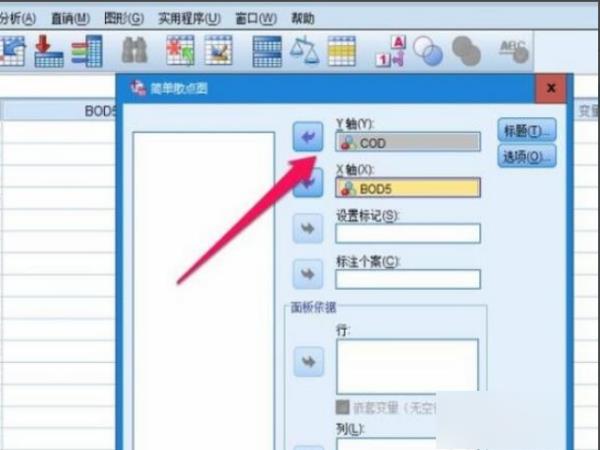
4、在接下来的弹出框中设置x轴和y轴,然后点击确定,其他都不要管,然后得到散点图,可以看出x轴和y轴明显呈线性关系,所以接下来的回归分析就要用线性回归方法,假设图像呈曲线就需要选择曲线拟合的方法。
5、点击【分析】---【回归】---【线性】。
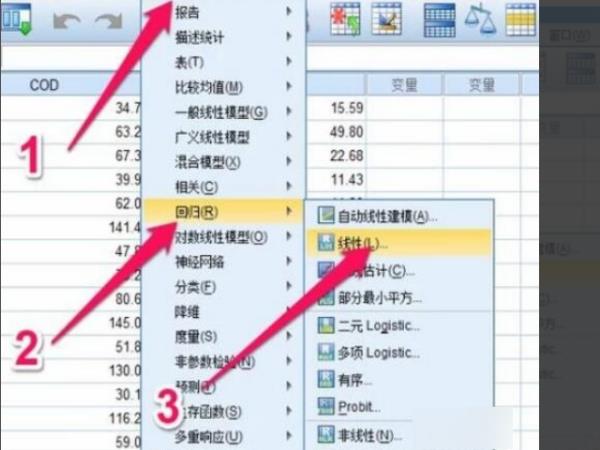
6、在弹出的线性回归框中设置自变量和因变量,其他的选项用默认设置即可,其他的选项只是用来更加精确地去优化模型。

7、【模型汇总表】中R表示拟合优度,值越接近1表示模型越好。至此回归分析就完成了图中的这个模型就是比较合理的。

注意事项:
SPSS注意事项:
1,数据编辑器、语法编辑器、输出查看器、脚本编辑器都可以同时打开多个。
2,关闭所有的输出查看器后,并不退出SPSS系统。数据编辑器都退出后将关闭SPSS系统。关闭所有的数据文件时并不一定退出SPSS系统。说明:仅新建一个数据文件,并没有保存,既没有生成数据文件。此时关闭其它所有已保存的数据文件时,不退出SPSS系统。
3,可以在不同的数据编辑器窗口打开同一个数据文件。对话框中提示“恢复为已保存”或“在新窗口中打开”选项。
参考技术A用SPSS进行多元回归以后,系统会自动给出x1、x2和x3(从大到小)的R的平方和,相减就是解释率。
多元线性回归中求出模型后,可以做趋势外推预测,把多个解释变量在预测期的值代入,就可以算出被解释变量的预测值了。
如果分类变量只有两类的话 不需要进行处理设置哑变量 直接进行回归就好
如果分类变量超过两类的话 则需要设置哑变量。
在线性回归中
数据使用线性预测函数来建模,并且未知的模型参数也是通过数据来估计。这些模型被叫做线性模型。最常用的线性回归建模是给定X值的y的条件均值是X的仿射函数。不太一般的情况,线性回归模型可以是一个中位数或一些其他的给定X的条件下y的条件分布的分位数作为X的线性函数表示。
像所有形式的回归分析一样,线性回归也把焦点放在给定X值的y的条件概率分布,而不是X和y的联合概率分布(多元分析领域)。
以上内容参考:百度百科-线性回归
参考技术B 不知道你要怎样比较预测值和真实值,比如计算一下残差值,或者计算一下均方误差之类?在Linear Regression对话框,点Save按钮,会出现Linear Regression: Save对话框,在Predicted Values(预测值)和Residuals(残差)栏都选Unstandardized,会在数据表中输出预测值和残差,然后你想怎么比较都行。
判断模型是否有预测能力,其实就是模型检验,模型检验除了统计意义上的检验,还有实际意义上的检验,就是检验是否跟事实相符,比如收入与消费应该是正相关的,如果消费为被解释变量、收入为解释变量,如果收入的系数小于零,那肯定是不对的。
统计意义上的检验,包括参数的T检验,方程的F检验,还要检验残差是否白噪声。
检验模型是否具有外推预测能力,还可以这样做:比如,你收集了一个容量为50的样本,你可以用其中的48个样本点估计模型,然后估计另两个样本点,把估计值跟实际值做一个比较。追问
谢谢!我看到文献中将一个样本随机抽样分成两个样本,用第一个样本得出模型各变量的系数,再用这个模型估计第二个样本中的结果,拿这个估计值和样本二的实际值做比较,然后出来一个R平方和一个平均误差值,我就是不太明白这里是如何比较估计值和实际值的,R平方和这个平均误差值是怎么出来的呢?是否就是你最后说的外推预测能力?
追答R的平方就是实际值和预测值的相关系数,平均误差值可以是均方误差或者均方根误差,后者其实就是误差的标准差。这里所说的预测值,其实就是估计值,用样本一估计出各系数以后,就有了被解释关于解释变量的函数,把样本二的解释变量值代入,就得到预测值或者估计值,把这个值跟实际值做比较。
文献里说的,就是我说的外推预测能力。
谢谢解答!如何用SPSS计算这个R平方实际值和预测值相关系数还有平均误差值呢?具体是哪几个步骤,选项啊?
追答记真实值为y,估计值为y1.
Analyze -> Corrilate -> Bivariate,把y和y1选到Variables框里面,其他的默认就可以了,就能把R算出来了,得到的是R,是相关系数,不一定要平方。这个值越接近1,两者的相关性越高。
记z=y1-y,Analyze -> Descriptive Statistics -> Descriptives,把Z放到Variable(s),再点Options,把Std. deviation选中,算出来的就是误差的标准差了.
你的是指判别分析吧。看到文献中将一个样本随机抽样分成两个样本,用第一个样本得出模型各变量的系数,再用这个模型估计第二个样本中的结果,拿这个估计值和样本二的实际值做比较,然后出来一个R平方和一个平均误差值,我就是不太明白这里是如何比较估计值和实际值的。这些都是判别分析的作法。训练样本和验证样本 参考技术D 多元线性回归的计算模型[1]
一元线性回归是一个主要影响因素作为自变量来解释因变量的变化,在现实问题研究中,因变量的变化往往受几个重要因素的影响,此时就需要用两个或两个以上的影响因素作为自变量来解释因变量的变化,这就是多元回归亦称多重回归。当多个自变量与因变量之间是线性关系时,所进行的回归分析就是多元性回归。
设y为因变量,为自变量,并且自变量与因变量之间为线性关系时,则多元线性回归模型为:
其中,b0为常数项,为回归系数,b1为固定时,x1每增加一个单位对y的效应,即x1对y的偏回归系数;同理b2为固定时,x2每增加一个单位对y的效应,即,x2对y的偏回归系数,等等。如果两个自变量x1,x2同一个因变量y呈线相关时,可用二元线性回归模型描述为:
其中,b0为常数项,为回归系数,b1为固定时,x2每增加一个单位对y的效应,即x2对y的偏回归系数,等等。如果两个自变量x1,x2同一个因变量y呈线相关时,可用二元线性回归模型描述为:
y = b0 + b1x1 + b2x2 + e
建立多元性回归模型时,为了保证回归模型具有优良的解释能力和预测效果,应首先注意自变量的选择,其准则是:
(1)自变量对因变量必须有显著的影响,并呈密切的线性相关;
(2)自变量与因变量之间的线性相关必须是真实的,而不是形式上的;
(3)自变量之彰应具有一定的互斥性,即自变量之彰的相关程度不应高于自变量与因变量之因的相关程度;
(4)自变量应具有完整的统计数据,其预测值容易确定。
多元性回归模型的参数估计,同一元线性回归方程一样,也是在要求误差平方和()为最小的前提下,用最小二乘法求解参数。以二线性回归模型为例,求解回归参数的标准方程组为
解此方程可求得b0,b1,b2的数值。亦可用下列矩阵法求得
即
[编辑]
多元线性回归模型的检验[1]
多元性回归模型与一元线性回归模型一样,在得到参数的最小二乘法的估计值之后,也需要进行必要的检验与评价,以决定模型是否可以应用。
1、拟合程度的测定。
与一元线性回归中可决系数r2相对应,多元线性回归中也有多重可决系数r2,它是在因变量的总变化中,由回归方程解释的变动(回归平方和)所占的比重,R2越大,回归方各对样本数据点拟合的程度越强,所有自变量与因变量的关系越密切。计算公式为:
其中,
2.估计标准误差
估计标准误差,即因变量y的实际值与回归方程求出的估计值之间的标准误差,估计标准误差越小,回归方程拟合程度越程。
其中,k为多元线性回归方程中的自变量的个数。
3.回归方程的显著性检验
回归方程的显著性检验,即检验整个回归方程的显著性,或者说评价所有自变量与因变量的线性关系是否密切。能常采用F检验,F统计量的计算公式为:
根据给定的显著水平a,自由度(k,n-k-1)查F分布表,得到相应的临界值Fa,若F > Fa,则回归方程具有显著意义,回归效果显著;F < Fa,则回归方程无显著意义,回归效果不显著。
4.回归系数的显著性检验
在一元线性回归中,回归系数显著性检验(t检验)与回归方程的显著性检验(F检验)是等价的,但在多元线性回归中,这个等价不成立。t检验是分别检验回归模型中各个回归系数是否具有显著性,以便使模型中只保留那些对因变量有显著影响的因素。检验时先计算统计量ti;然后根据给定的显著水平a,自由度n-k-1查t分布表,得临界值ta或ta / 2,t > t − a或ta / 2,则回归系数bi与0有显著关异,反之,则与0无显著差异。统计量t的计算公式为:
其中,Cij是多元线性回归方程中求解回归系数矩阵的逆矩阵(x'x) − 1的主对角线上的第j个元素。对二元线性回归而言,可用下列公式计算:
其中,
5.多重共线性判别
若某个回归系数的t检验通不过,可能是这个系数相对应的自变量对因变量的影平不显著所致,此时,应从回归模型中剔除这个自变量,重新建立更为简单的回归模型或更换自变量。也可能是自变量之间有共线性所致,此时应设法降低共线性的影响。
多重共线性是指在多元线性回归方程中,自变量之彰有较强的线性关系,这种关系若超过了因变量与自变量的线性关系,则回归模型的稳定性受到破坏,回归系数估计不准确。需要指出的是,在多元回归模型中,多重共线性的难以避免的,只要多重共线性不太严重就行了。判别多元线性回归方程是否存在严惩的多重共线性,可分别计算每两个自变量之间的可决系数r2,若r2 > R2或接近于R2,则应设法降低多重线性的影响。亦可计算自变量间的相关系数矩阵的特征值的条件数k = λ1 / λp(λ1为最大特征值,λp为最小特征值),k<100,则不存在多重点共线性;若100≤k≤1000,则自变量间存在较强的多重共线性,若k>1000,则自变量间存在严重的多重共线性。降低多重共线性的办法主要是转换自变量的取值,如变绝对数为相对数或平均数,或者更换其他的自变量。
6.D.W检验
当回归模型是根据动态数据建立的,则误差项e也是一个时间序列,若误差序列诸项之间相互独立,则误差序列各项之间没有相关关系,若误差序列之间存在密切的相关关系,则建立的回归模型就不能表述自变量与因变量之间的真实变动关系。D.W检验就是误差序列的自相关检验。检验的方法与一元线性回归相同。
以上是关于spss:得到一个多元线性回归模型之后,如何比较预测值和真实值?如何判断模型是不是有预测能力?的主要内容,如果未能解决你的问题,请参考以下文章