ElasticSearchRepository和ElasticsearchRestTemplate的使用
Posted ZNineSun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearchRepository和ElasticsearchRestTemplate的使用相关的知识,希望对你有一定的参考价值。
上一章:《SpringBoot整合ElasticSearch实现模糊查询,批量CRUD,排序,分页,高亮》
文章目录
在上一章节,我们学习到了es通过RestHighLevelClient实现最基本的增删改查的语法,在本章我们继续深入实践一下es的相关操作,在SpringBoot的相关依赖中,es已经帮我们将基本的操作都进行了封装,我们只需要掌握这些api,便可以轻松的操作我们的es
本章主角:ElasticSearchRepository,ElasticsearchRestTemplate
Spring-data-elasticsearch是Spring提供的操作ElasticSearch的数据层,封装了大量的基础操作,通过它可以很方便的操作ElasticSearch的数据。
对于相关的依赖以及配置请参考第四章信息
5.1 ElasticSearchRepository的基本使用
@NoRepositoryBean
public interface ElasticsearchRepository<T, ID extends Serializable> extends ElasticsearchCrudRepository<T, ID>
<S extends T> S index(S var1);
Iterable<T> search(QueryBuilder var1);
Page<T> search(QueryBuilder var1, Pageable var2);
Page<T> search(SearchQuery var1);
Page<T> searchSimilar(T var1, String[] var2, Pageable var3);
void refresh();
Class<T> getEntityClass();
我们是通过继承ElasticsearchRepository来完成基本的CRUD及分页操作的,和普通的JPA没有什么区别。
我们使用方式也很简单,写一个接口然后继承它即可
ElasticsearchRepository<,>
- 第一个就是所准备的实体类
- 第二个是id的类型
public interface EsUserService extends ElasticsearchRepository<User, Integer>
然后便可以进行相关的增删改查以及批量操作
特殊情况下,ElasticsearchRepository里面有几个特殊的search方法,这些是ES特有的,和普通的JPA区别的地方,用来构建一些ES查询的。
主要是看QueryBuilder和SearchQuery两个参数,要完成一些特殊查询就主要看构建这两个参数。
我们先来看看它们之间的类关系
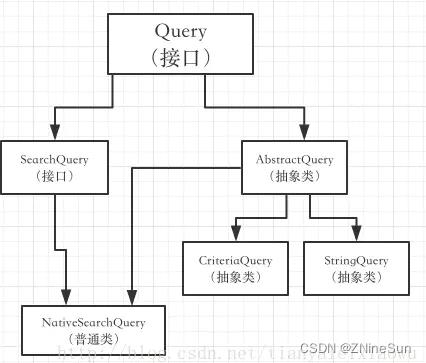
从这个关系中可以看到ES的search方法需要的参数SearchQuery是一个接口,有一个实现类叫NativeSearchQuery,实际使用中,我们的主要任务就是构建NativeSearchQuery来完成一些复杂的查询的。
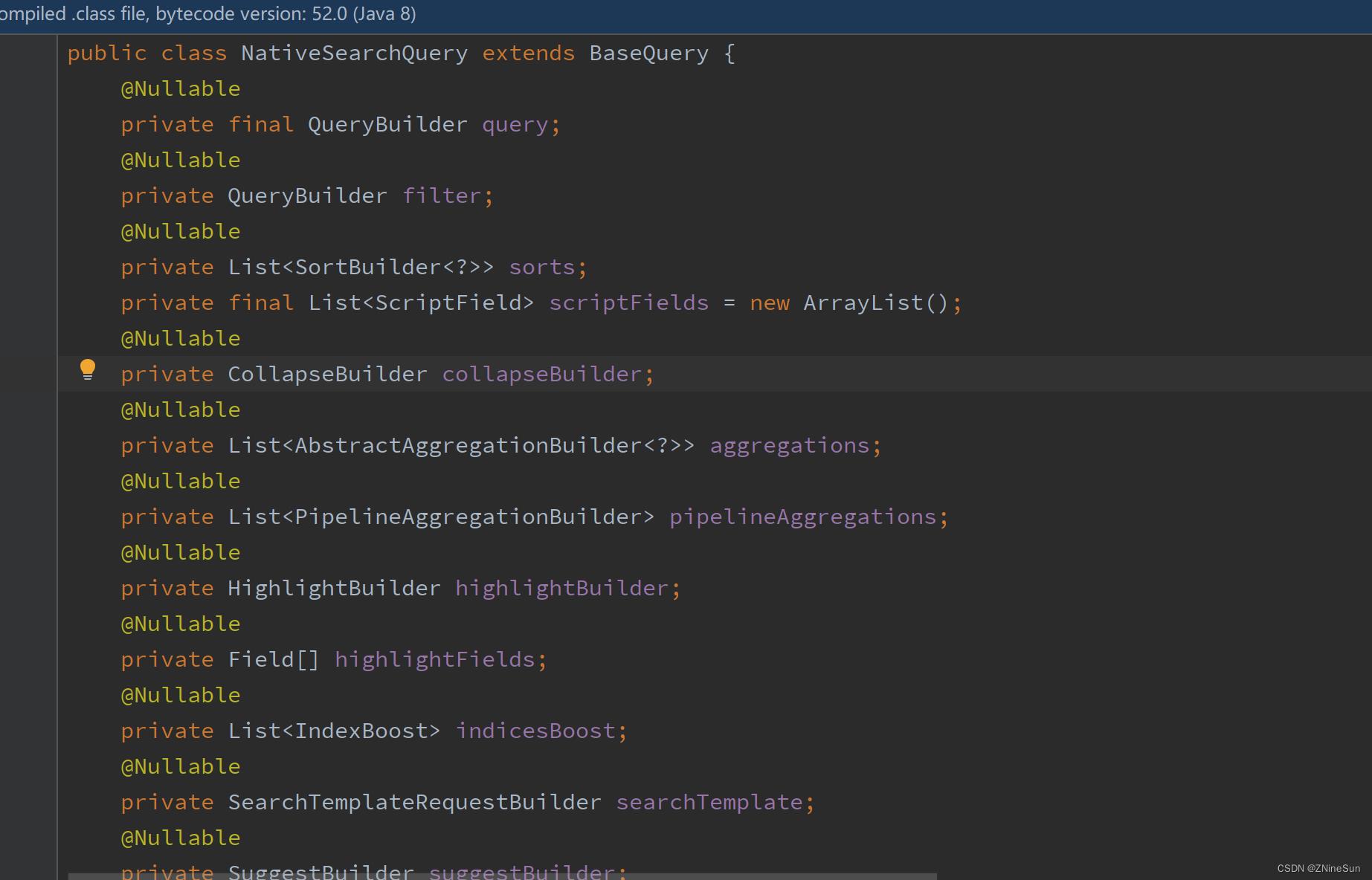
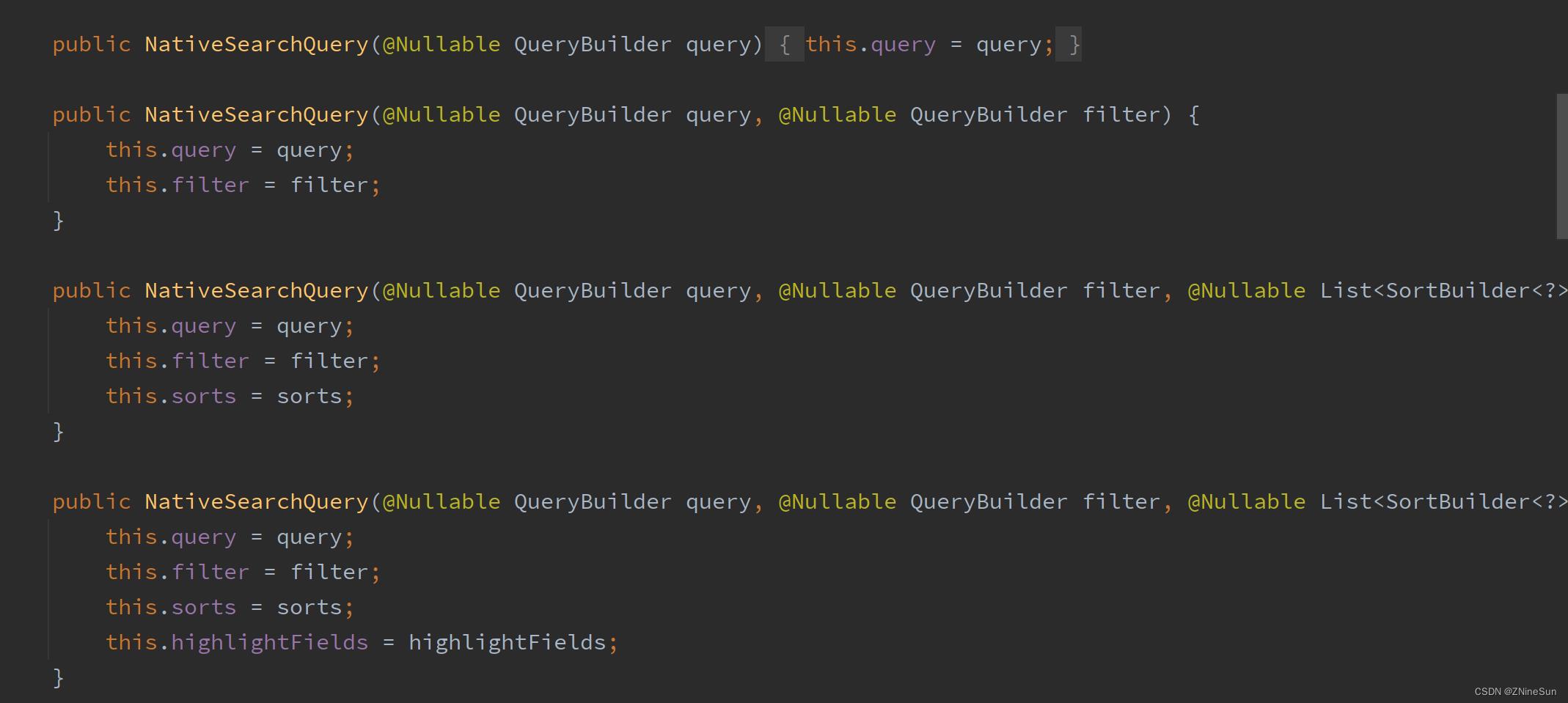
我们可以看到要构建NativeSearchQuery,主要是需要几个构造参数
public NativeSearchQuery(QueryBuilder query, QueryBuilder filter, List<SortBuilder> sorts, Field[] highlightFields)
this.query = query;
this.filter = filter;
this.sorts = sorts;
this.highlightFields = highlightFields;
当然了,我们没必要实现所有的参数。
可以看出来,大概是需要QueryBuilder,filter,和排序的SortBuilder,和高亮的字段。
一般情况下,我们不是直接是new NativeSearchQuery,而是使用NativeSearchQueryBuilder。
通过如下所示的方式来完成NativeSearchQuery的构建。
NativeSearchQueryBuilder.withQuery(QueryBuilder1).withFilter(QueryBuilder2).withSort(SortBuilder1).withXXXX().build();
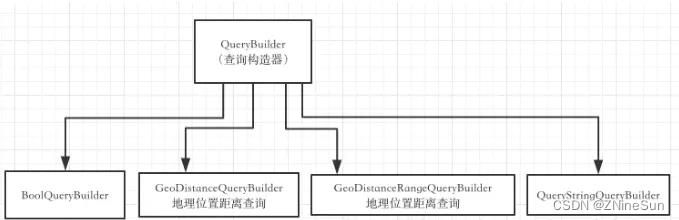
从名字就能看出来,QueryBuilder主要用来构建查询条件、过滤条件,SortBuilder主要是构建排序。
譬如,我们要查询距离某个位置100米范围内的所有人、并且按照距离远近进行排序:
double lat = 39.929986;
double lon = 116.395645;
Long nowTime = System.currentTimeMillis();
//查询某经纬度100米范围内
GeoDistanceQueryBuilder builder = QueryBuilders.geoDistanceQuery("address").point(lat, lon)
.distance(100, DistanceUnit.METERS);
GeoDistanceSortBuilder sortBuilder = SortBuilders.geoDistanceSort("address")
.point(lat, lon)
.unit(DistanceUnit.METERS)
.order(SortOrder.ASC);
Pageable pageable = new PageRequest(0, 50);
NativeSearchQueryBuilder builder1 = new NativeSearchQueryBuilder().withFilter(builder).withSort(sortBuilder).withPageable(pageable);
SearchQuery searchQuery = builder1.build();
要完成字符串的查询:
SearchQuery searchQuery = new NativeSearchQueryBuilder().withQuery(QueryBuilders.queryStringQuery("spring boot OR 书籍")).build();
要构建QueryBuilder,我们可以使用工具类QueryBuilders,里面有大量的方法用来完成各种各样的QueryBuilder的构建,字符串的、Boolean型的、match的、地理范围的等等。
要构建SortBuilder,可以使用SortBuilders来完成各种排序。
然后就可以通过NativeSearchQueryBuilder来组合这些QueryBuilder和SortBuilder,再组合分页的参数等等,最终就能得到一个SearchQuery了。
至此,我们明白了ElasticSearchRepository里那几个search查询方法需要的参数的含义和构建方式了。
5.2 ElasticsearchRestTemplate的使用
ElasticSearchTemplate更多是对ESRepository的补充,里面提供了一些更底层的方法。
原来的ElasticsearchTemplate已经过时了
这里主要是一些查询相关的,同样是构建各种SearchQuery条件。
虽然ElasticsearchRestTemplate里也包括save之类的JPA操作,但适用于小数据量,要完成超大数据的插入就要用ES自带的bulk了,可以迅速插入百万级的数据。
在ElasticsearchRestTemplate里也提供了对应的方法

public void bulkIndex(List<Person> personList)
int counter = 0;
try
if (!elasticsearchTemplate.indexExists(PERSON_INDEX_NAME))
elasticsearchTemplate.createIndex(PERSON_INDEX_TYPE);
List<IndexQuery> queries = new ArrayList<>();
for (Person person : personList)
IndexQuery indexQuery = new IndexQuery();
indexQuery.setId(person.getId() + "");
indexQuery.setObject(person);
indexQuery.setIndexName(PERSON_INDEX_NAME);
indexQuery.setType(PERSON_INDEX_TYPE);
//上面的那几步也可以使用IndexQueryBuilder来构建
//IndexQuery index = new IndexQueryBuilder().withId(person.getId() + "").withObject(person).build();
queries.add(indexQuery);
if (counter % 500 == 0)
elasticsearchTemplate.bulkIndex(queries);
queries.clear();
System.out.println("bulkIndex counter : " + counter);
counter++;
if (queries.size() > 0)
elasticsearchTemplate.bulkIndex(queries);
System.out.println("bulkIndex completed.");
catch (Exception e)
System.out.println("IndexerService.bulkIndex e;" + e.getMessage());
throw e;
这里是创建了100万个Person对象,每到500就用bulkIndex插入一次,速度飞快,以秒的速度插入了百万数据。
讲了那么多理论,下面我们具体实践一下
5.3 实战
1.实体类
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
@Data
@Document(indexName = "user")//索引名称 建议与实体类一致
public class User
@Id
private Integer id;
@Field(type = FieldType.Auto)//自动检测类型
private Integer age;
@Field(type = FieldType.Keyword)//手动设置为keyword 但同时也就不能分词
private String name;
@Field(type = FieldType.Text, analyzer = "ik_smart", searchAnalyzer = "ik_max_word")//设置为text 可以分词
private String info;
如果没有看过第三章:es的相关概念的话,这些注解看起来可能比较麻烦,为了节约大家时间,我把用到的相关概念在重复说一下
-
Keyword 用于索引结构化内容的字段,例如电子邮件地址,主机名,状态代码,邮政编码或标签。它们通常用于过滤,排序,和聚合。Keyword 字段只能按其确切值进行搜索。
-
Text 用于索引全文值的字段,例如电子邮件正文或产品说明。
这些字段是被分词的,它们通过分词器传递 ,以在被索引之前将字符串转换为单个术语的列表。
分析过程允许 Elasticsearch 搜索单个单词中每个完整的文本字段。文本字段不用于排序,很少用于聚合。 -
IK提供两种分词ik_smart和ik_max_word,其中ik_smart为最少切分,ik_max_word为最细粒度划分。
由于在本章之前还未教大家安装ik分词器,所以可以跳过它,暂时不用考虑
2.Elasticsearch Service
public interface EsUserService extends ElasticsearchRepository<User,Integer>
//根据name查询
List<User> findByName(String name);
//根据name和info查询
List<User> findByNameAndInfo(String name,String info);
3.查询
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Pageable;
import org.springframework.data.domain.Sort;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.data.elasticsearch.core.SearchHit;
import org.springframework.data.elasticsearch.core.SearchHits;
import org.springframework.data.elasticsearch.core.query.NativeSearchQuery;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.Random;
@RestController
public class EsController
@Autowired
private ElasticsearchRestTemplate elasticsearchTemplate;
@Autowired
private EsUserService esUserService;
private String[] names = "诸葛亮", "曹操", "李白", "韩信", "赵云", "小乔", "狄仁杰", "李四", "诸小明", "王五";
private String[] infos = "我来自中国的一个小乡村,地处湖南省", "我来自中国的一个大城市,名叫上海,人们称作魔都"
, "我来自杭州,这是一个浪漫的城市";
/**
* 保存数据
*
* @return
*/
@GetMapping("saveUser")
public Object saveUser()
//添加索引mapping索引会自动创建但mapping自只用默认的这会导致分词器不生效 所以这里我们手动导入mapping
Random random = new Random();
List<User> users = new ArrayList<>();
for (int i = 0; i < 20; i++)
User user = new User();
user.setId(i);
user.setName(names[random.nextInt(9)]);
user.setAge(random.nextInt(40) + i);
user.setInfo(infos[random.nextInt(2)]);
users.add(user);
Iterable<User> users1 = esUserService.saveAll(users);
return users1;
/**
* 通过id查询数据
*
* @return
*/
@GetMapping("getDataById")
public Object getDataById(@RequestParam(value = "id") Integer id)
return esUserService.findById(id);
/**
* 分页查询
*
* @return
*/
@GetMapping("getAllDataByPage")
public Object getAllDataByPage()
//本该传入page和size,这里为了方便就直接写死了
//表示通过Id正序排序
Pageable page = PageRequest.of(0, 3, Sort.Direction.ASC, "id");
Page<User> all = esUserService.findAll(page);
return all.getContent();
/**
* 根据名字查询
*
* @param name
* @return
*/
@GetMapping("getDataByName")
public Object getDataByName(@RequestParam(value = "name") String name)
return esUserService.findByName(name);
/**
* 通过名字和Info取交集查询
*
* @param name
* @param info
* @return
*/
@GetMapping("getDataByNameAndInfo")
public Object getDataByNameAndInfo(String name, String info)
//这里是查询两个字段取交集,即代表两个条件需要同时满足
return esUserService.findByNameAndInfo(name, info);
/**
* 分词高亮查询
*
* @param value
* @return
*/
@GetMapping("getHightByUser")
public Object getHightByUser(@RequestParam(value = "value") String value)
//根据一个值查询多个字段 并高亮显示 这里的查询是取并集,即多个字段只需要有一个字段满足即可
//需要查询的字段
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery()
.should(QueryBuilders.matchQuery("info", value))
.should(QueryBuilders.matchQuery("name", value));
//构建高亮查询
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(boolQueryBuilder)
.withHighlightFields(
new HighlightBuilder.Field("info")
, new HighlightBuilder.Field("name"))
.withHighlightBuilder(new HighlightBuilder().preTags("<span style='color:red'>").postTags("</span>"))
.build();
//查询
SearchHits<User> search = elasticsearchTemplate.search(searchQuery, User.class);
//得到查询返回的内容
List<SearchHit<User>> searchHits = search.getSearchHits();
//设置一个最后需要返回的实体类集合
List<User> users = new ArrayList<>();
//遍历返回的内容进行处理
for (SearchHit<User> searchHit : searchHits)
//高亮的内容
Map<String, List<String>> highlightFields = searchHit.getHighlightFields();
//将高亮的内容填充到content中
searchHit.getContent(以上是关于ElasticSearchRepository和ElasticsearchRestTemplate的使用的主要内容,如果未能解决你的问题,请参考以下文章