网易严选离线数仓治理实践
Posted @SmartSi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网易严选离线数仓治理实践相关的知识,希望对你有一定的参考价值。

1. 背景
任何一个系统,为了保证其良好地运行下去,一定是需要持续的维护和治理,数仓也不例外。本文主要分享下今年严选数仓团队从规范、计存、质量、安全几块入手对现有数据资产进行的一些治理的思路和方案。
网易严选是个自营品牌电商,这意味着严选的业务会覆盖C端的用户营销,商品到B端的供应链以及财务业务。业务和数据的整体复杂度会相对较高,各个不同业务域也呈现出不同的特点和问题。所以我们需要结合现有的资产特点去设计治理方法论和效果评估方法,然后围绕着治理方法论去建设我们的治理工具。
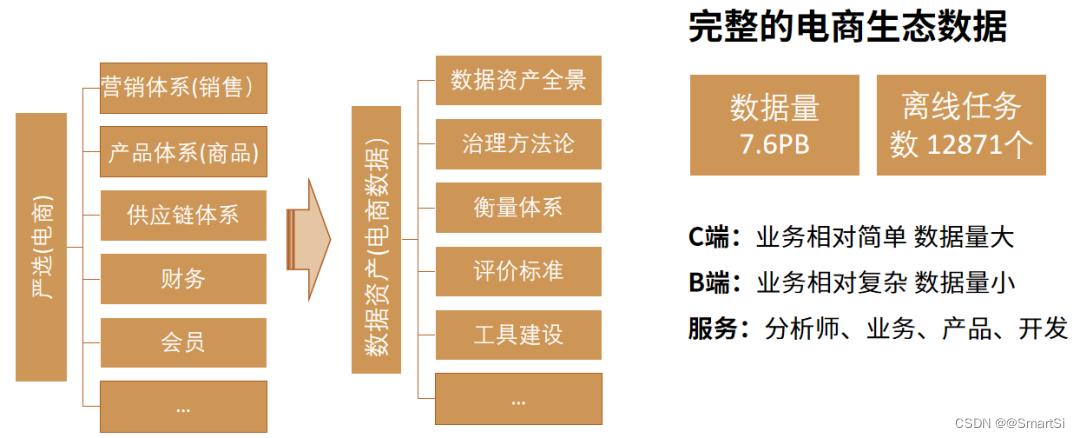
治理开始前,先盘一下我们可用的资源,设计下整体的方向。从人力上来说,项目整体设计与推动大概可投入1.5人力,治理实施可以拉上资产对应的数据开发配合,这个人力方案决定了我们肯定是不会去设计开发个整体的治理系统来做这个事情,而是应该把重点放在规范和治理方案设计上,依托现有基础能力,以最低程度的开发资源投入来推动这个事情。
基础能力上来说,已经沉淀的能力有:
- 数据地图:由数据开发治理平台的数据地图及严选数据资产中心提供,大部分数据沉淀在产品,未入仓;
- 全链路血缘:由严选数据资产中心提供,数据沉淀在产品,未入仓;
- 数据探查能力:由数据开发治理平台的测试中心提供;
- 影响评估能力:主要由严选数据资产中心提供,结合血缘和数据分级能力得出影响程度。
整体资产全景见下图:
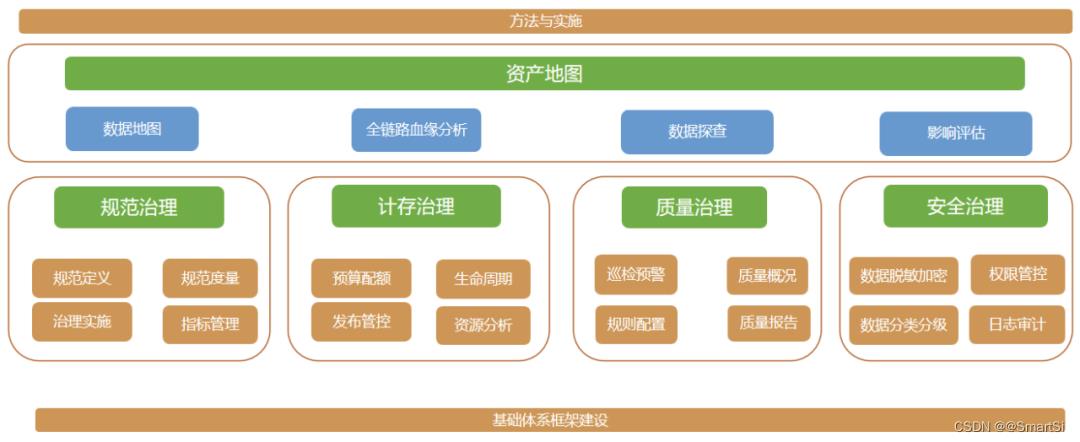
历史我们也做过不少数据治理相关投入,但存在一些问题,比如缺乏体系化设计,导致多个项目/团队交叉治理,重复治理等问题,同时,治理效果也缺乏持续的追踪和效果衡量。这些是本次治理项目需要解决的问题。
2. 思路
整体思路上我们分4步走。
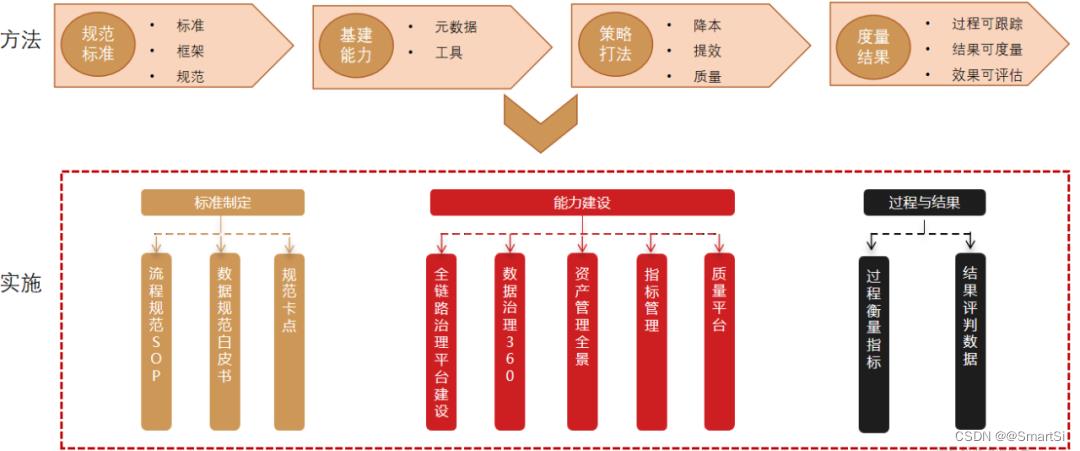
2.1 规范制定
数据建模规范,即数据开发在设计模型阶段需要遵循的规范,比如dwd不能加工指标等。
数据开发SOP,为了系统能帮我们自动做一些规范校验和补全,我们可能制定一些流程上的规范,比如建表必须走模型设计中心,dw层全部先评审后开发等。
2.2 能力建设
即我们数据治理过程中需要用到的系统能力补全,包含元数据建设,数据平台的迭代及治理工具的开发。
2.3 治理实施
从治理目标上来说,我们围绕降本、提效、质量3个点去规划治理方案;从实施方案上来说,主要落实在规范、计算存储、数据质量、数据安全4个方面。
2.4 结果衡量
治理结果目标制定;治理过程指标衡量。
3. 实施
3.1 规范治理
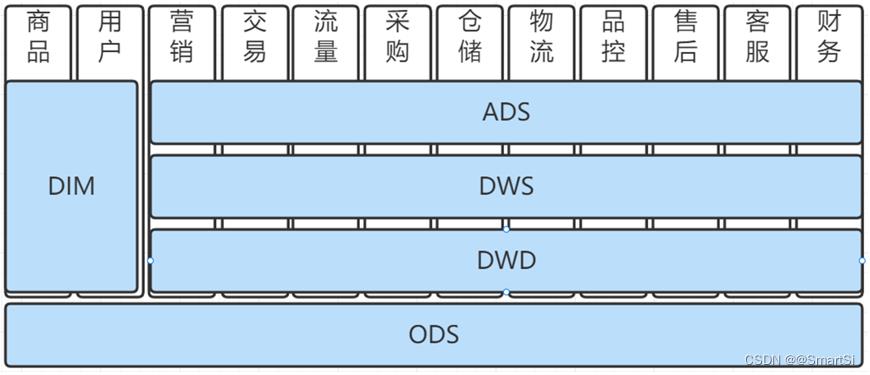
严选数仓建模规范主要基于Kimball维度建模理论,结合严选业务实际情况制定,大致架构如下图:
有了规范定义,那我们首先需要的就是看下当前数仓的规范程度,这里我们基于元数据ETL加工得到我们的监测指标,并基于有数BI进行的可视化呈现。

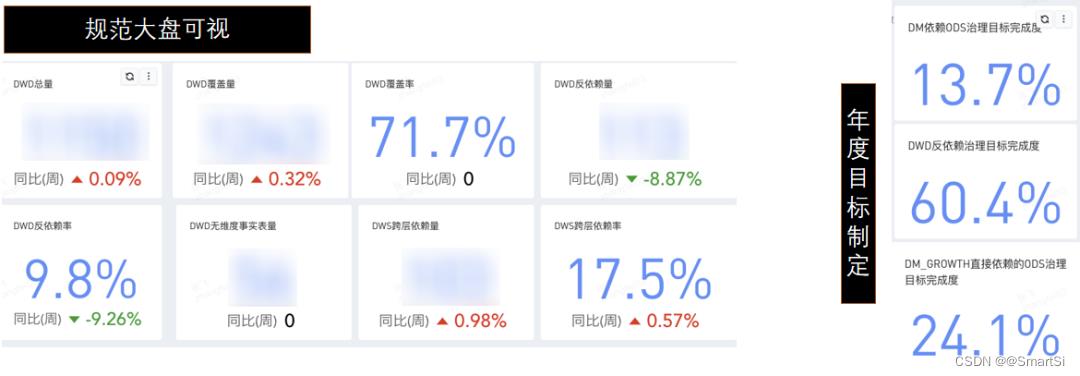
然后基于当前数仓规范的达成情况,我们制定了今年主要要解决的问题及规范治理的目标,并同样对治理目标做了可视化。主要问题及解决方式如下:
- 跨层依赖——巡检及待办分发
- DWS依赖ODS
- DM依赖ODS
- 反向依赖——巡检及待办分发
- DWD依赖DM
- DWD依赖DWS
- DWS依赖DM
- 单一事实建模——运动式治理
- 一张DWD只依赖一张ODS
3.2 指标治理
严选的指标管理基于自研的指标管理系统,该系统会对指标的口径进行管理,并强制绑定到数据网关,实现从数据网关输出的数据,都附带明确的口径定义。但该系统存在一个问题,那就是定义和研发分离。指标口径基于该系统定义,但是指标的开发和该系统并没关联,那么在开发过程中,口径定义和实际开发的口径可能就会出现偏差,并且在dws和ads的加工上,建模设计完全由数据开发把关,也就可能出现模型设计质量参差不齐的情况。
对于以上问题,我们的解法是新设计一套指标管理系统,将指标定义和开发工作耦合起来,实现定义即研发的效果。目前该系统已经在部分场景实现了落地,系统详细设计这里就不展开了,感兴趣的同学可以线下交流。
3.3 计算存储治理
计算存储资源的消耗直接关系数据的生产成本以及数据产出的稳定性和及时性,所以这块也是比较重要的。
3.3.1 计算治理
计算资源可优化的点主要在于因代码或参数的不合理导致的低效任务上,主要思路是识别出这部分任务,然后通过by任务的优化去提高资源利用率。治理方法如下:
- 触发条件:
- 数据开发治理平台openAPI获取yarn资源消耗明细
- 内存空闲时间分布聚类取前20%阈值
- RAM实际申请大于1TB
- 利用率小于10%
- 防治:
- 全局:整体消耗资源(RMB/RAM/CPU/TIME)分布监控
- 个人:触发条件发飞书push任务治理通知
- 过程记录(已治理/待治理)效果统计
- 优化方法:
- 谓词下推/小文件合并/join优化/data skew优化/提高任务并行度/Spark AQE 参数调整
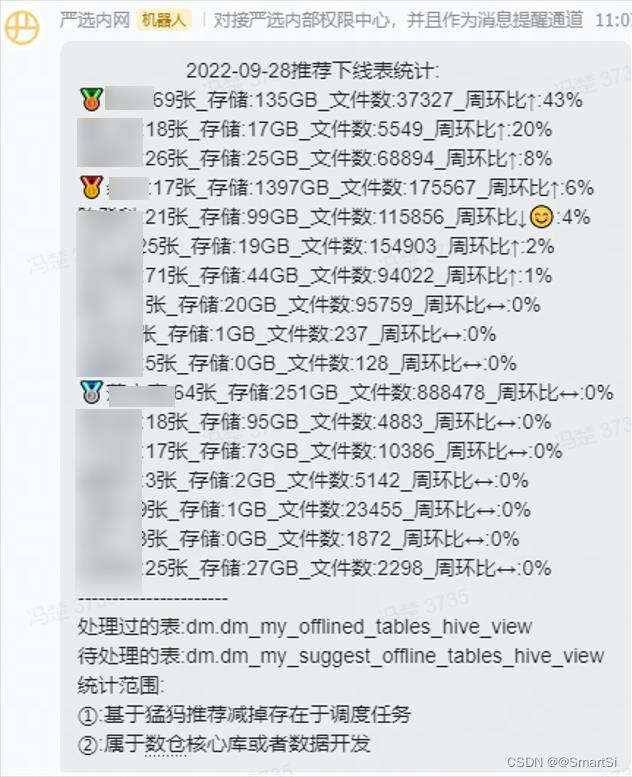
首先我们起个数据开发治理平台的任务,按照触发条件去巡检,筛选出待治理列表。然后发现这部分任务有着明显的长尾分布特性,极少数任务占用了大部分资源。所以我们针对top100的任务由专人挨个进行的by case的优化,剩余的任务则通过待办分发的形式推送给任务的负责人进行优化跟进。同时,我们做了全局的和个人的计算资源监控大盘,通过消息通知的形式,每天进行监控和公示。

3.3.2 存储治理
历史对于冷表冷任务这块我们没有系统关注和清理过,所以随着业务的不断发展积累的大量的冷表冷任务。对于这块儿的治理主要借助数据开发治理平台的数据资产中心的存储优化功能。但因为数据资产中心对于特殊存储比如kudu、iceberg,以及仓外血缘没有做逻辑判断。所以拿到数据资产中心的推荐下线数据后,我们结合严选维护的全链路血缘做了交叉校验,得到最终的待下线任务集。任务集的判断条件如下:
- 触发条件:
- 强推荐:30天打开次数+近30天引用次数+近30天访问次数+近30天写入次数 = 0
- 弱推荐 :近30天打开次数+近30天引用次数+近30天访问次数 = 0
- 不存在于调度任务
得到任务集后,先大致分析了下待下线表的分布,发现有几个占比较大且风险较低的库,比如kylin cube build的临时数据,库存中心的流水日志等,我们判断风险较小,且数量较大,就让数据开发治理平台的同学帮忙批量下线掉。对于是dw,dm等db的表,因为谁也没办法保证血缘100%的准确性,且摊分到每个人头上后量不算大,所以就采取待办分发的形式push表负责人去进行治理。然后我们再通过open API去监控集群整体,和每个数据开发的冷表治理情况,针对需要改进的点再单独push。
防治:
- 全局:整体情况及占比变化效果群消息
- 个人:单独push需要治理的表
- 数据开发治理平台的数据资产存储模块操作
- API获取处理结果统计
3.4 数据安全治理
这个事情大的背景是目前数仓关于数据加密脱敏,数据权限管理等工作基本靠共识,比如大家都知道用户手机号是敏感数据,有人要这份数据时也会多走个流程审批一下。但是到底哪些表里面有存用户手机号,这些手机号有没有被妥善地加密或脱敏,表授权时有没有去判断里面是否有敏感数据,这些我们都是不知道的。所以我们考虑基于实体识别的方法,把数据资产的敏感程度给分级打标出来。

分级打标的依据是集团下发的《网易数据分类分级管理制度》,根据这个文件,我们手工把数仓的各项涉敏数据项给盘点出来,整理成结构化的数据。再用一个Spark Job的形式去批量对所有数仓表进行采样和字段打标。大致实现如下:↓
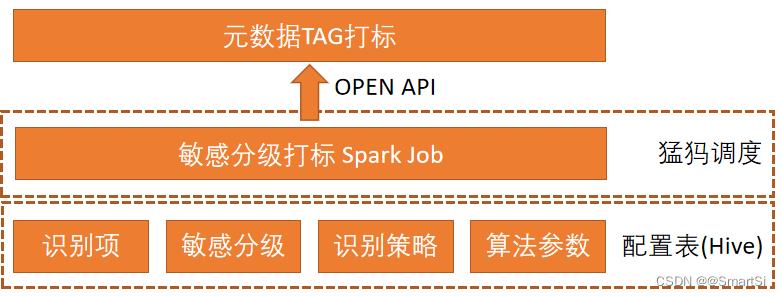
目前这个系统做了基本的实现,后续需要继续扩展识别项覆盖率和准确率,具体技术细节我们就不在这里讨论了,后面单开一篇文章分享。
得到分级结果后,我们就可以拿这份数据去重新盘点和治理我们的数据加密和权限管理情况了。
3.5 数据质量治理
质量这块儿我们分事前、事中、事后三块去实施。
3.5.1 事前
事前我们主要是规范数据需求流程,明确各个参与方职责,进行风险评估和保障定义:
- 业务:需求提出
- BI/PM:1、需求拆解 2、确定口径
- 数据开发:需求评审
- 数据系分评审、链路评估
- 验证方案、回滚方案
- 链路风险巡检/治理
- SLA 定义、保障方式定义
- QA:测试评审
- 测试测分及评审
- 自测标准、验收标准
- 测试报告、验收反馈
- 事故报告、事故复盘
3.5.2 事中
事中我们遵循数据开发->研发自测->QA自测->数据发布->产品发布->用户验收的流程,保证研发过程的质量合格。
3.5.3 事后
事后指的是需求交付后的运维保障及应急恢复,这里的策略包括:基线值班、DQC、变更感知、大促时的压测和发生故障后的复盘。

基线值班会有数据基线该怎么挂的问题,任务A到底要保障到7点产出还是9点产出,值班的资源是有限的,都保障就意味着保障力度都降低,同理DQC的配置也是。这里我们的做法是,先从数据的使用场景出发,看看线上服务和有数报表的重要性分级是什么样的。再根据血缘往上追踪,对整个上游链路的数据任务挨个打标,高优覆盖低优,以此来确认任务的保障等级。
获得任务分级后,我们把P0,P1的任务挂载到了7:30/9:30两条基线,P2任务挂载到了10:00基线,由数据值班来保障他们的按时产出,并对破线及任务失败进行记录和复盘,便于确认后续优化方向。同时,P0、P1的任务也强制要求大家配上了基本的数据稽核。
然后是变更感知这块儿,包含数据源变更感知和ETL变更感知。数仓不生产数据,我们在只是数据的搬运工,所以感知数据源的变更和“搬运程序”的变更对数据质量的保障特别重要。
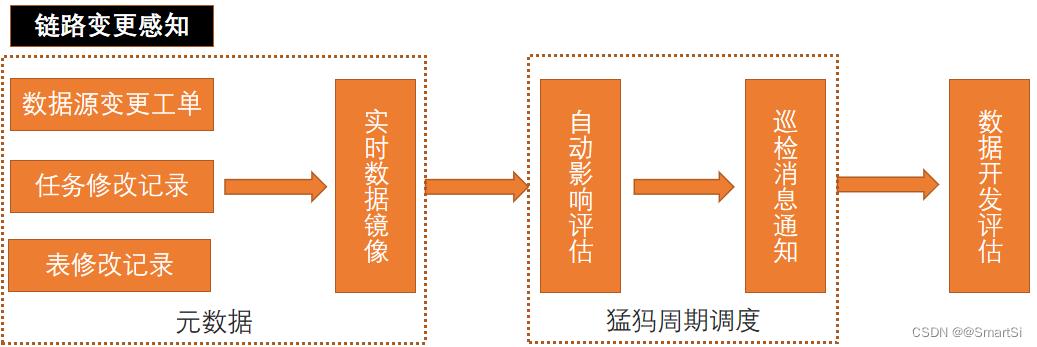
这里我们的做法是,收集数据源的变更工单日志以及数仓表和任务的修改记录,通过一个周期调度的spark sql任务去识别出风险变更以及影响范围,并推送消息给到对应的数据开发评估。
3.6 横向巡检机制
前面关于各个治理项目都有提到需要推送待办任务给数据开发处理,所以我们需要一个通用的消息通知机制。再结合到我们大多数巡检场景都可以基于元数据+SQL的形式识别,于是我们采用UDF的方法,对接消息中心的接口,实现了消息通知的SQL化。

4. 效果
治理效果这块儿,我们基于有数BI搭建了可视化看板,对整体的目标达成率和每个人的目标达成率进行了监控和跟进。
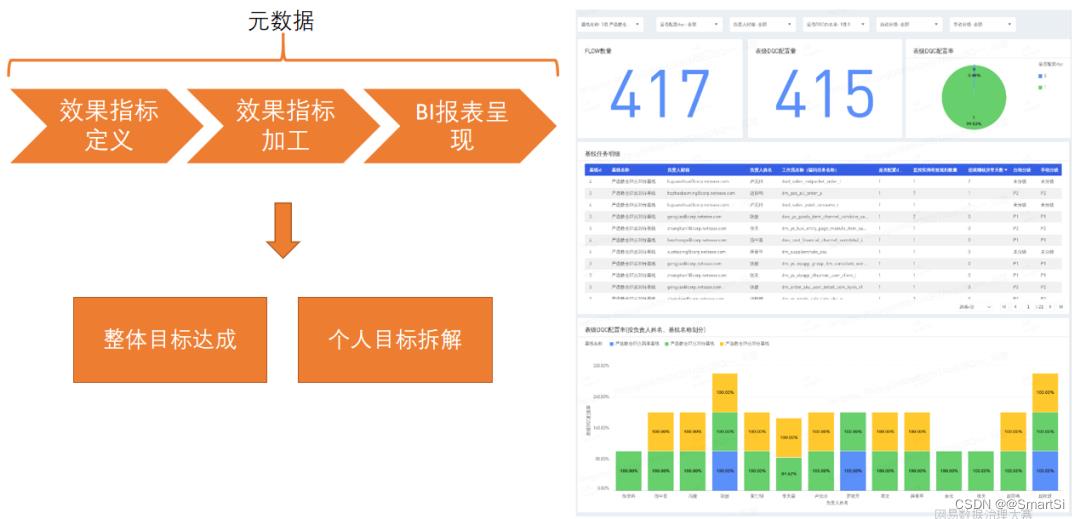
具体关键成果如下:
- 规范
- DWS跨层依赖率 21.2%->17.5%
- DWD反依赖率18.1%->11.5%
- 计存
- 冷表下线10W+张,累计下降存储2.8PB,净下降1.9PB(8.49-6.59)
- 资源费用 12k/day->2k/day
- 内存memory seconds 下降33%
- 高耗资源任务运行时间 下降90%
- 高耗资源任务成本消耗 下降69%
- 质量
- 基线破线率23.76%->0%
- DQC配置率10%->100%
原文:网易严选离线数仓治理实践
以上是关于网易严选离线数仓治理实践的主要内容,如果未能解决你的问题,请参考以下文章