hadoop权威指南学习 - 天气预报MapReduce程序的开发和部署
Posted Master HaKu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop权威指南学习 - 天气预报MapReduce程序的开发和部署相关的知识,希望对你有一定的参考价值。
看过Tom White写的Hadoop权威指南(大象书)的朋友一定得从第一个天气预报的Map Reduce程序所吸引,
殊不知,Tom White大牛虽然在书中写了程序和讲解了原理,但是他以为你们都会部署了,这里轻描淡写给
带过了,这样就给菜鸟们留了课题,其实在跑书中的程序的时候,如果没经验,还是会踩坑的。
这里笔者就把踩过的坑说一下,以防后来人浪费时间了。
1. 首先,你得下载书中的ncdc气象原始数据,这个可以从书中的官网下载。
作者比较做人家,只给了2年的历史数据,无妨,2年也可以运行。
下载下来你会看到1901.gz,1902.gz
2. 然后我们可以开始我们的编码之旅了
新建一个maven项目,然后按照书中的例子,编写如下3个类(这里Mapper, Reducer, Job的原理我就不多解释了,自己去看大牛的书去)
MaxTemperatureMapper.java
package org.genesis.hadoop.temperature; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class MaxTemperatureMapper extends Mapper<LongWritable, Text, Text, IntWritable> { private static final int MISSING = 9999; @Override public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String year = line.substring(15, 19); int airTemperature; if (line.charAt(87) == \'+\') { // parseInt doesn\'t like leading plus signs airTemperature = Integer.parseInt(line.substring(88, 92)); } else { airTemperature = Integer.parseInt(line.substring(87, 92)); } String quality = line.substring(92, 93); if (airTemperature != MISSING && quality.matches("[01459]")) { context.write(new Text(year), new IntWritable(airTemperature)); } } }
MaxTemperatureReducer.java
package org.genesis.hadoop.temperature; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class MaxTemperatureReducer extends Reducer<Text, IntWritable, Text, IntWritable> { @Override public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int maxValue = Integer.MIN_VALUE; for (IntWritable value : values) { maxValue = Math.max(maxValue, value.get()); } context.write(key, new IntWritable(maxValue)); } }
MaxTemperature.java
package org.genesis.hadoop.temperature; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class MaxTemperature { public static void main(String[] args) throws Exception { if (args.length != 2) { System.err.println("Usage: MaxTemperature <input path> <output path>"); System.exit(-1); } Job job = new Job(); job.setJarByClass(MaxTemperature.class); job.setJobName("Max temperature"); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.setMapperClass(MaxTemperatureMapper.class); job.setReducerClass(MaxTemperatureReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
然后把我们的Java程序打包,你认为自己是一个Java熟手,不是吗,熟练的命令或者IDE都可以(mvn clean install)
Ok, 包打完了,得到如下jar包: xxx.jar
好了,你可能会试着用书中或者网上的命令(前提是你已经配置好$hadoop_home)
hadoop jar xxx.jar 你的主类名 你的本地gz文件存放的目录 你本地另外一个输出目录
然而,很不幸,你的程序跑不了,理由很简单,根本就找不到你的gz文件的目录。
喔,查了下网上的资料,发现我似乎应该把本地文件拷贝到HDFS,赶快查资料,下一步。。。
3. 将本地数据拷贝到HDFS(前提是你已经安装了hadoop并且把服务给启动了起来)
3-1) 我们先在hdfs根目录下建个data目录
hadoop fs -mkdir /data
3-2) 把我们的gz数据拷贝到刚刚新建的目录
hadoop fs -copyFromLocal /Users/KG/Documents/MyWork/Hadoop/data/ncdc/*.gz /data
3-3)把我们的jar包拷贝到一个地方,然后进入命令行,进入哪个目录
cd /Users/KG/Documents/MyTest/Jar
3-4) 使用hadoop jar运行命令
但是,这里你会报错: 找不到主类名
解决方案:你需要给自己的pom配置shade插件
我的pom.xml
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.genesis</groupId> <artifactId>MaxTemperature</artifactId> <version>1.0-SNAPSHOT</version> <dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-core</artifactId> <version>1.2.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.2</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>2.4.1</version> <executions> <execution> <phase>package</phase> <goals><goal>shade</goal></goals> <configuration> <transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <mainClass>org.genesis.hadoop.temperature.MaxTemperature</mainClass> </transformer> </transformers> </configuration> </execution> </executions> </plugin> </plugins> </build> </project>
3-5)再次运行完整命令,如下:
hadoop jar original-MaxTemperature-1.0-SNAPSHOT.jar org.genesis.hadoop.temperature.MaxTemperature /data /data/output
如果你看到如下输出,那么你成功了
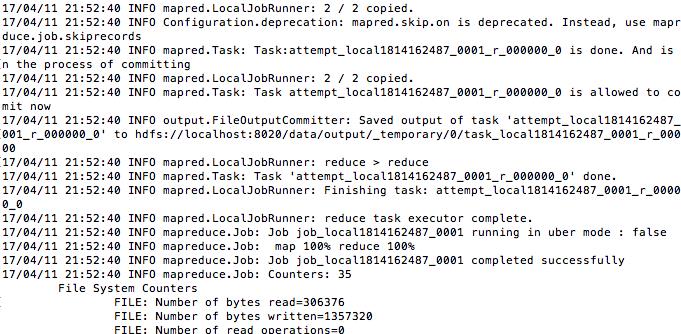
4. 验证分析结果
使用如下命令:
hadoop fs -cat /data/output/*
输出结果如下:
1901 317
1902 244
以上是关于hadoop权威指南学习 - 天气预报MapReduce程序的开发和部署的主要内容,如果未能解决你的问题,请参考以下文章