[redis读书笔记] 第三部分 多机数据库的实现 复制
Posted jiangz222
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[redis读书笔记] 第三部分 多机数据库的实现 复制相关的知识,希望对你有一定的参考价值。
另外一篇写的很好很深入的文章:http://www.tuicool.com/articles/fAnYFb ; RDB持久化 http://www.tuicool.com/articles/F3Erii2
复制即主服务器向从服务器的数据同步,REDIS的实现具有参考意义,尤其对于有主从同步需求,数据量不是特别大,可以用内存存储,其中巧妙之处在于 offset和缓冲区的配对使用,让主服务器能够很快的知道应该同步哪些数据,即使面对多个从服务器可以做到处理流程一样。
书中分析了老版本和新版本在复制过程中,断链发生时的不同处理,来描述复制的过程。
老版本复制主要2个方式:
1. 从服务器主动发送SYNC给主服务器,主服务器启动BGSAVE,生成一个DB文件,传给从服务器,从服务器加载DB文件,然后主服务器将这个过程中接收到的写命令也同步给从服务器,从服务器也执行这些写命令,同步结束。
SYNC的过程是非常耗费资源的,CPU,内存,带宽都会在不同时期被占用

2. 主从服务器DB相同,主服务器执行了写命令,主动同步给从服务器,称之为命令传播
老版本的bug:上面第2点,假如主服务器和从服务器断链,主服务器无法感知,依然进行命令传播,将主服务器上的写命令传送给从服务器,而从服务器接收不到,最后建连后数据就不一致了。
当然,建链后可以直接来一次SYNC,不过这样过于耗费资源。
新版本:
有了PSYNC命令,断链后,等到建链,从服务器发送PSYNC给主服务器,主服务器会将断链时间段的所有写命令同步给从服务器。
下图中+CONTINUE回复标识开始部分同步。

二 部分复制的实现细节:
1. 首先,主从服务器都会记下同步的字节数,所谓复制偏移量,主服务器上记录 同步多少字节给从服务器,从服务器记录接收到主服务器同步多少个字节,下图15-7中同步了10086字节的数据
如果断链后恢复,从服务器发送PSYNC给主服务器,带上本地的复制偏移量,主服务器比较后发现和本地的不一样,就意味着主从数据不一致,需要进行数据同步。


2. 主服务发现本地的offset和从服务器的offset不一致,意味着要进行数据同步,怎么同步呢?
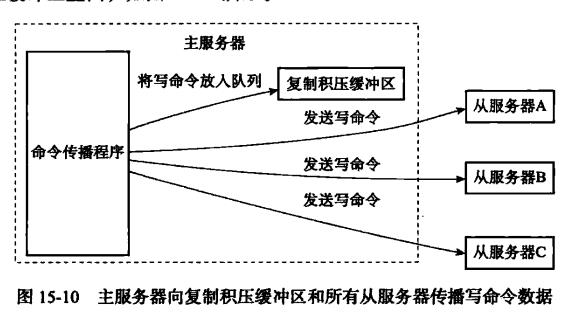
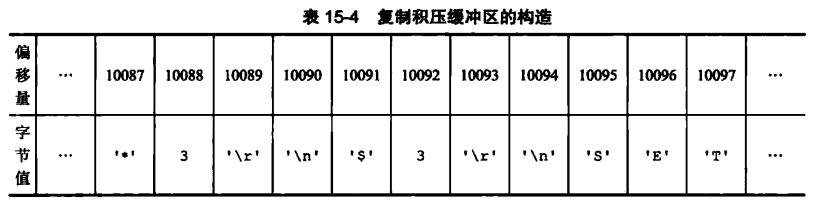
主服务器中会有一个固定长度(1MB)的FIFO的复制积压缓冲区(server.repl_backlog),每个复制到从服务器的字节,都会储存在这个缓冲区中,每个字节都对应到一个offset.(实现在feedReplicationBacklog)
(masterTryPartialResynchronization)当从服务器发送PSYNC,带来自己的offset,主服务器会在复制积压缓冲区中查找,如果offset+1依然在缓冲区中,没有被挤压出队列(固定长度FIFO,存储最新的命令,如果队列满,最老的命令会被挤压出队列),就可以执行部分复制(addReplyReplicationBacklog进行复制哪一部分的挑选)。否则就要进行全部复制,即SYNC
2.服务器运行ID,从服务器会存储主服务器的运行ID,此ID是全局唯一的。如果断链再建联,主服务器发现从服务器发来的主服务器运行ID(伴随PSYNC命令)和自己的不一样,那么就要进行完整的复制,如果ID一致,可以选择进行部分复制。

三 心跳检测 -- 补发缺失数据
从服务器会定时向主服务器发送ACK(replicationSendAck中实现),进行心跳保活,消息会带上server.master->reploff,那么当主向从同步时,消息有丢失,导致slave的offset没有更新,那么主服务器通过比较本地的offset和消息里salve的offset,就知道需要重新发送部分数据给slave.
这个方法主要是防止master和slave都没有断线,只是有通信的丢包,无法触发上面说到的部分重同步功能,因为部分重同步是建立在断链后恢复的前提的。
以上是关于[redis读书笔记] 第三部分 多机数据库的实现 复制的主要内容,如果未能解决你的问题,请参考以下文章