朴素贝叶斯模型的训练(wdbc数据集)
Posted 耶瞳
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了朴素贝叶斯模型的训练(wdbc数据集)相关的知识,希望对你有一定的参考价值。
采用的是乳腺癌威斯康星州(原始)数据集,数据集特征如下:

训练代码如下,我在写的过程中为了让代码逻辑更清晰点,所以损失了一些性能;虽然是多次测试,但测试集并没有随机选取。。。。反正是作业,糊弄过去就行。
import pandas as pd
import random
import time
# 切分训练集和测试集
def randSplit(data):
n = data.shape[0]
m = int(n * random.uniform(0.1, 0.3))
return data, data.sample(m)
# 构建朴素贝叶斯分类器
def gnb_classify(train, test):
truePro = 0
for i in range(train.shape[0]):
if train.values[i, 10] == 2:
truePro += 1
truePro /= train.shape[0] # true的概率
falsePro = 1 - truePro # false的概率
# 统计频率
numContainer = [, , , , , , , , ]
for i in range(train.shape[0]):
if train.values[i, 10] == 2:
for j in range(9):
if train.values[i, j + 1] in numContainer[j]:
numContainer[j][train.values[i, j + 1]] += 1
else:
numContainer[j][train.values[i, j + 1]] = 1
else:
for j in range(9):
if -1 * train.values[i, j + 1] in numContainer[j]:
numContainer[j][-1 * train.values[i, j + 1]] += 1
else:
numContainer[j][-1 * train.values[i, j + 1]] = 1
# 计算概率
for i in numContainer:
sum = 0
for k, v in i.items():
sum += v
for k, v in i.items():
i[k] = v / sum
# 预测训练集
res = 0 # 存储预测正确的数量
for i in range(test.shape[0]):
trueP = truePro
falseP = falsePro
for j in range(9):
if test.values[i, j + 1] in numContainer[j]:
trueP *= numContainer[j][test.values[i, j + 1]]
if -1 * test.values[i, j + 1] in numContainer[j]:
falseP *= numContainer[j][-1 * test.values[i, j + 1]]
if (trueP > falseP and test.values[i, 10] == 2) or (trueP < falseP and test.values[i, 10] == 4):
res += 1
return res / test.shape[0]
# 测试分类器
def test_classify():
sum = 0
for i in range(10):
singleStart = time.time()
randomTrain, randomTest = randSplit(df)
p = gnb_classify(randomTrain, randomTest)
sum += p
singleEnd = time.time()
print("第次训练,预测准确率: ,训练用时:s".format(i + 1, p, singleEnd - singleStart))
return sum / 10
df = pd.read_csv(r'wdbc_discrete.data')
start = time.time()
probability = test_classify()
end = time.time()
print("\\n测试集平均准确率为:".format(probability))
print("平均训练用时:s".format((end - start) / 10))
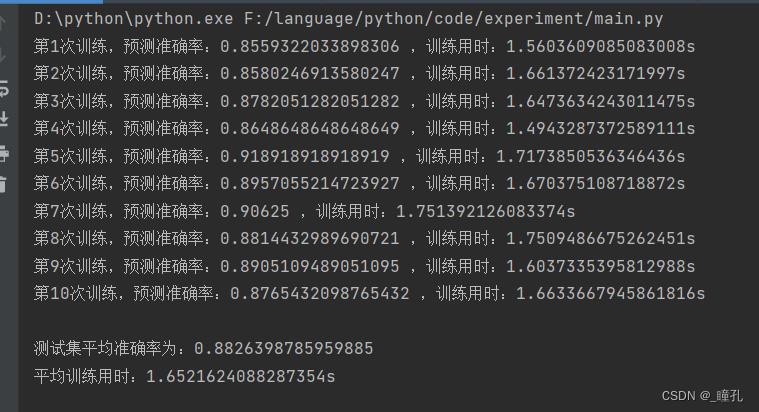
如果有兴趣了解更多相关内容,欢迎来我的个人网站看看:瞳孔空间
以上是关于朴素贝叶斯模型的训练(wdbc数据集)的主要内容,如果未能解决你的问题,请参考以下文章