kafaka ElasticSearch 集群,解决问题,工作流程及配置
Posted 石工记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafaka ElasticSearch 集群,解决问题,工作流程及配置相关的知识,希望对你有一定的参考价值。
一、作用
性能优化:jvm多线程和I/O,kafka+es 组合的架构,是为了降低es io瓶颈
二、工作流程
如下两图示意,
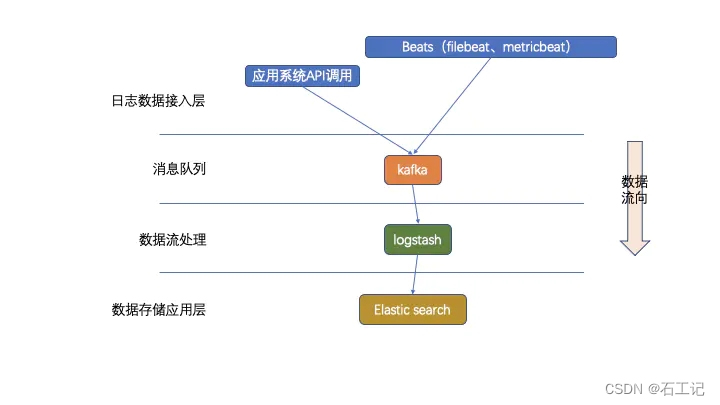
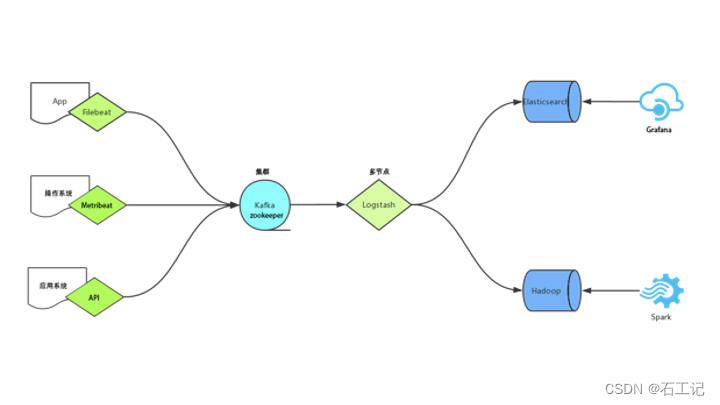
agent(指的是filebeat、metricbeat、auditbeat、API服务、logstash)收集需要提取的日志文件,包括syslog、nginx、tomcat、apache、windows event、snmptrap等,将日志转存到kafka集群中。logstash处理kafka日志,格式化处理,并将日志输出到elasticsearch中,前台页面通过grafana展示日志。
使用kafka集群做缓存层,而不是直接将agent收集到的日志信息写入logstash节点,让整体结构更健壮。agent负责将收集到的数据写入kafka,logstash取出数据并处理。
硬件条件支持
一共使用了4台服务器,需要先做好ntp时钟同步。CentOS7.4:
192.168.50.180/181/182:ES子节点,Kafka集群,Logstash多节点日志转换,Zookeeper+Kafka+Logstash+
ElasticSearch
192.168.50.187:ES主节点,Logstash节点(收集snmp日志),Grafana前台展示,管理系统,nginx+ElasticSearch+Grafana
每台服务器都需要安装JDK,配置环境变量。修改全局配置文件/etc/profile,应用于所有用户:
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_201
export CLASSPATH=$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:.
export PATH=$JAVA_HOME/bin:$PATH
系统参数调优,修改hosts,sysctl.conf和limits.conf文件,在末尾增加一些配置:
# vim /etc/hosts
192.168.50.180 node1 192-168-50-180
192.168.50.181 node2 192-168-50-181
192.168.50.182 node3 192-168-50-182
# vim /etc/sysctl.conf
fs.file-max=65536
vm.max_map_count = 262144
# vim /etc/security/limits.conf
* soft nofile 65535
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
# sysctl -p
软件安装包下载地址:链接: https://pan.baidu.com/s/1JPuyifWBlbA58TBczkNMQQ 密码: apdb
三、应用安装
3.1 kafka集群搭建
在192.168.50.180/181/182服务器中搭建kafka集群,关闭防火墙
关闭防火墙命令:systemctl stop firewalld
查看防火墙状态:systemctl status firewalld
3.2搭建zookeeper
直接使用kafka自带的zookeeper
解压安装包到/usr/local/kafka目录下
vim config/zookeeper.properties
修改配置内容:
clientPort=2181
maxClientCnxns=100
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/kafka/zookeeper/data
dataLogDir=/usr/local/kafka/zookeeper/log
server.1=192.168.50.180:12888:13888
server.2=192.168.50.181:12888:13888
server.3=192.168.50.182:12888:13888
注意:dataDir、dataLogDir文件目录需要手动创建。
三台服务器配置内容一致,需要在dataDir目录下创建myid文件,文件的内容必须与zookeeper.properties中的编号保持一致,分别为1、2、3。
3.3搭建kafka
vim config/server.properties
修改配置内容:
broker.id=1
advertised.port = 9092
advertised.host.name = 192.168.50.180
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/usr/local/kafka-logs
num.partitions=16
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.50.180:2181,192.168.50.181:2181,192.168.50.182:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
注意:每台服务器除broker.id 和 host.name 两个属性需要修改之外,其他属性保持一致。
验证
启动zookeeper:
nohup zookeeper-server-start.sh ../config/zookeeper.properties &
启动kafka
nohup kafka-server-start.sh ../config/server.properties &
创建topic:
/usr/local/kafka/bin/kafka-topics.sh --create --zookeeper 192.168.50.180:2181,192.168.50.181:2181,192.168.50.182:2181 --replication-factor 1 --partitions 2 --topic testtopic
查看topic:
/usr/local/kafka/bin/kafka-topics.sh --zookeeper 192.168.50.180:2181,192.168.50.181:2181,192.168.50.182:2181 --list
写入消息命令:
/usr/local/kafka/bin/kafka-console-producer.sh --broker-list 192.168.50.180:9092 --topic testtopic
消费消息命令:
/usr/local/kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.50.180:9092 --from-beginning --topic testtopic
能正常的写入消息、消费消息,kafka集群完成。
ES及相关组件搭建
在192.168.50.180/181/182/187搭建elasticsearch,注意es的启动必须是非root用户启动,需要先创建用户esuser:useradd esuser -s /bin/bash -d /home/esuser -m
3.4安装elasticsearch
解压文件到/usr/local/目录下,以192.168.50.187为主节点master
vim elasticsearch/config/elasticsearch.yml
修改配置:
# cluster.name 集群名称
# node.name 节点主机名
# node.master 是否参与主节点竞选
# node.data:true 指定该节点是否存储索引数据,默认为true。本例没配置,所有节点都存储包括主节点
# cluster.initial_master_nodes 引导启动集群的机器IP或者主机名
# http.port http端口。
# transport.tcp.port 设置节点间交互的tcp端口,默认是9300。
cluster.name: esmaster
node.name: 192.168.50.187
node.master: true
path.logs: /usr/local/data/log/
network.host: 192.168.1.187
http.port: 9200
discovery.seed_hosts: ["192.168.50.180","192.168.50.181","192.168.50.182"]
cluster.initial_master_nodes: ["192.168.50.187"]
注意:其他几台服务器,作为子节点,需要修改cluster.name、node.name、network.host为自身的配置,修改node.master:false。最后两个属性根据服务器内容进行修改。
3..5安装Grafana
解压后执行nohup bin/grafana-server &
3.6安装agent
上传beats.tar.gz及setup.sh文件(下载地址:)到/usr/local/src下,使用root用户执行setup.sh脚本。
默认启动filebeat收/var/log下所有日志文件,默认启动metricbeat收系统日志,默认启动auditbeat进行系统级别操作审计日志。如需收集其他日志则使用不同的配置文件即可。
3.7安装logstash
在192.168.1.180/181/182/187搭建logstash服务,
在logstash中input配置如下:
input
kafka
bootstrap_servers => ["192.168.50.180:9092,192.168.50.181:9092,192.168.50.182:9092"]
group_id => "logk"
auto_offset_reset => "earliest"
consumer_threads => "5"
decorate_events => "false"
topics => ["metric", "syslog"]
type => "kafka_logs"
codec => json
其中192.168.1.187上的logstash用于接收snmptrap日志。
解压文件到/usr/local/目录下,创建用于本次处理的配置文件logstash4snmp.conf
启动logstash命令:nohup sh logstash -f ../config/logstash4snmp.conf &
四、安装管理系统
4.1安装nginx
上传nginx包,解压后编译安装
# yum install gcc-c++
# yum install -y pcre pcre-devel
# yum install -y zlib zlib-devel
# yum install -y openssl openssl-devel
# ./configure --with-http_ssl_module --with-http_gzip_static_module --with-stream
# make
# make install
配置nginx日志格式
log_format main
'"@timestamp":"$time_iso8601",'
'"host":"$hostname",'
'"server_ip":"$server_addr",'
'"client_ip":"$remote_addr",'
'"xff":"$http_x_forwarded_for",'
'"domain":"$host",'
'"url":"$uri",'
'"referer":"$http_referer",'
'"args":"$args",'
'"upstreamtime":"$upstream_response_time",'
'"responsetime":"$request_time",'
'"request_method":"$request_method",'
'"status":"$status",'
'"size":"$body_bytes_sent",'
'"request_body":"$request_body",'
'"request_length":"$request_length",'
'"protocol":"$server_protocol",'
'"upstreamhost":"$upstream_addr",'
'"file_dir":"$request_filename",'
'"http_user_agent":"$http_user_agent"'
'';
access_log /var/log/nginx/access.log main;
重启nginx,/usr/local/bin/nginx -s reload
安装mysql、tomcat
卸载系统自带的 mariadb-lib
# rpm -qa|grep mariadb
mariadb-libs-5.5.44-2.el7.centos.x86_64
# rpm -e mariadb-libs-5.5.44-2.el7.centos.x86_64 --nodeps
解压安装包tar -xvf mysql-5.7.16-1.el7.x86_64.rpm-bundle.tar
安装
依次执行(几个包有依赖关系,所以执行有先后)下面命令安装
# rpm -ivh mysql-community-common-5.7.16-1.el7.x86_64.rpm
# rpm -ivh mysql-community-libs-5.7.16-1.el7.x86_64.rpm
# rpm -ivh mysql-community-client-5.7.16-1.el7.x86_64.rpm
# rpm -ivh mysql-community-server-5.7.16-1.el7.x86_64.rpm
注:在安装rpm -ivh mysql-community-server-5.7.16-1.el7.x86_64.rpm的时候如果报错,需要安装libaio包和net-tools包,完成之后就可以顺利安装。
4.2数据库初始化
为了保证数据库目录为与文件的所有者为 mysql 登陆用户,如果你是以 root 身份运行 mysql 服务,需要执行下面的命令初始化mysqld --initialize --user=mysql
如果是以 mysql 身份运行,则可以去掉 --user 选项。
另外 --initialize 选项默认以“安全”模式来初始化,会生成一个 root 账户密码,密码在log文件里,如下示意:
# cat /var/log/mysqld.log
2019-12-07T04:41:58.420558Z 1 [Note] A temporary password is generated for root@localhost: )1r3gi,hjgQa
现在启动mysql数据库
systemctl start mysqld.service
然后mysql -uroot -p,使用初始密码。
修改密码
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY 'new_password';
上传并解压tomcat,启动tomcat即可。
以上是关于kafaka ElasticSearch 集群,解决问题,工作流程及配置的主要内容,如果未能解决你的问题,请参考以下文章