学成在线项目开发技巧整理---第二部分
Posted 热爱编程的大忽悠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学成在线项目开发技巧整理---第二部分相关的知识,希望对你有一定的参考价值。
1.静态资源处理
通常项目会采用动静分离架构,利用nginx作为静态资源服务器,存放所有静态资源:
#访问动态资源时,将请求负载均衡到多个服务器实例或者多个网关实例
upstream webservice
server 192.168.200.146:8080;
server
listen 80;
server_name localhost;
#动态资源
location /demo
proxy_pass http://webservice;
#静态资源
location ~/.*\\.(png|jpg|gif|js)
root html/web;
gzip on;
location /
root html/web;
index index.html index.htm;
学成在线项目在解决课程界面预览需求时,有如下两种思路:
第一种: nginx负责管理所有静态页面,ajax发起请求,获取数据

第二种: nginx管理部分静态资源,如:css,js,大部分的静态页面。 后端服务器将需要填充大量数据的页面通过模板引擎技术提前在服务器端填充好,然后直接返回给浏览器。

为什么最终选择第二种,因为课程预览界面大部分信息都需要查询数据库获取:

如果采用ajax发起请求查询,需要查询多次,而如果采用在服务器填充好数据并返回,那么只需要一次http请求,因此最终实现方案如下:
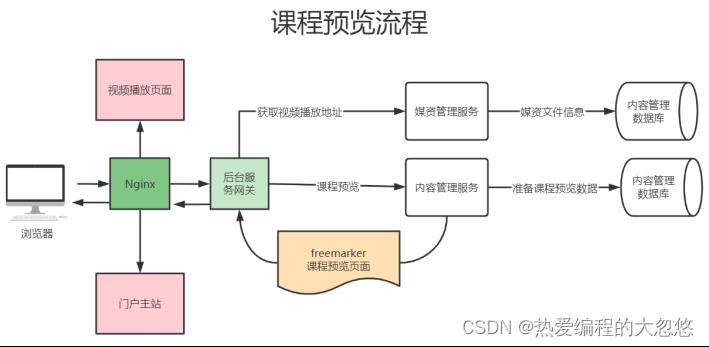
2.课程发布怎么实现

课程发布前需要先提交审核,只有在审核通过后才能发布:

因此,我们需要给课程基本表添加一个审核状态字段,只有审核通过的课程,才能进行发布:
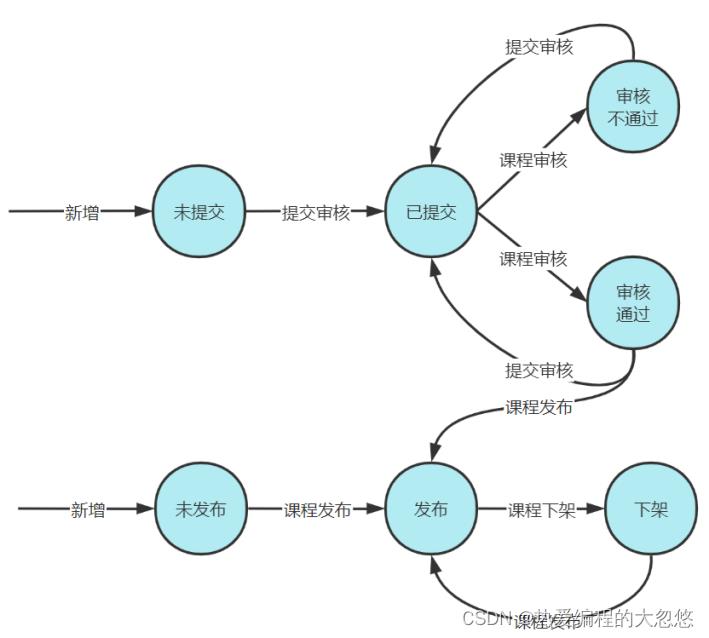
注意: 在本次课程审核还未结束前,即使对当前课程做出了修改,也不能再次提交审核,需等待此次课程审核结束.

如果不允许修改是不合理的,因为提交审核后可以继续做下一个阶段的课程内容,比如添加课程计划,上传课程视频等。
如果允许修改,那么课程审核时看到的课程内容从哪里来?如果也从课程基本信息表、课程营销表、课程计划表查询那么存在什么问题呢?
运营人员审核课程和教学机构编辑课程操作的数据是同一份,此时会导致冲突。比如:运营人员正在审核时教学机构把数据修改了。
为了解决这个问题,专门设计课程预发布表。

提交课程审核,将课程信息汇总后写入课程预发布表,课程预发布表记录了教学机构在某个时间点要发布的课程信息。
课程审核人员从预发布表查询信息进行审核。
课程审核的同时可以对课程进行修改,修改的内容写入课程基本信息表。
课程审核通过执行课程发布,将课程预发布表的信息写入课程发布表。
3.如何快速搜索课程
在网站上展示课程信息需要解决课程信息显示的性能问题,如果速度慢(排除网速)会影响用户的体验性。
如何去快速搜索课程?
打开课程详情页面仍然去查询数据库可行吗?
为了提高网站的速度需要将课程信息进行缓存,并且要将课程信息加入索引库方便搜索,下图显示了课程发布后课程信息的流转情况:

1、向内容管理数据库的课程发布表存储课程发布信息。
2、向Redis存储课程缓存信息。
3、向Elasticsearch存储课程索引信息。
4.请求分布文件系统存储课程静态化页面(即html页面),实现快速浏览课程详情页面。
课程发布表的数据来源于课程预发布表,它们的结构基本一样,只是课程发布表中的状态是课程发布状
态,如下图:

redis中的课程缓存信息是将课程发布表中的数据转为json进行存储。
elasticsearch中的课程索引信息是根据搜索需要将课程名称、课程介绍等信息进行索引存储。
MinIO中存储了课程的静态化页面文件(html网页),查看课程详情是通过文件系统去浏览课程详情页面。
4.分布式事务
一次课程发布操作需要向数据库、redis、elasticsearch、MinIO写四份数据,这里存在分布式事务问题。
什么是本地事务(局部事务)?
平常我们在程序中通过spring去控制事务是利用数据库本身的事务特性来实现的,因此叫数据 库事务,由于应用主要靠关系数据库来控制事务,而数据库通常和应用在同一个服务器,所以基于关系型数据库的事务又被称为本地事务。
本地事务具有ACID四大特性,数据库事务在实现时会将一次事务涉及的所有操作全部纳入到一个不可分割的执行单元,该执行单元中的所有操作要么都成功,要么都失败,只要其中任一操作执行失败,都将导致整个事务的回滚。
什么是分布式事务(全局事务)?
现在的需求是课程发布操作后将数据写入数据库、redis、elasticsearch、MinIO四个地方,这四个地方已经不限制在一个数据库内,是由四个分散的服务去提供,与这四个服务去通信需要网络通信,而网络存在不可到达性,这种分布式系统环境下,通过与不同的服务进行网络通信去完成事务称之为分布式事务。
在分布式系统中分布式事务的场景很多:用户注册送积分,银行转账,创建订单减库存,这些都是分布式事务。
微服务场景下:
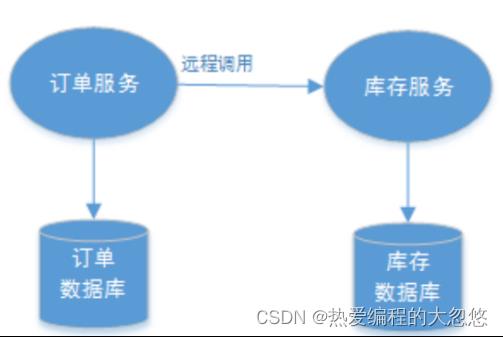
单服务多数据库

多服务单数据库
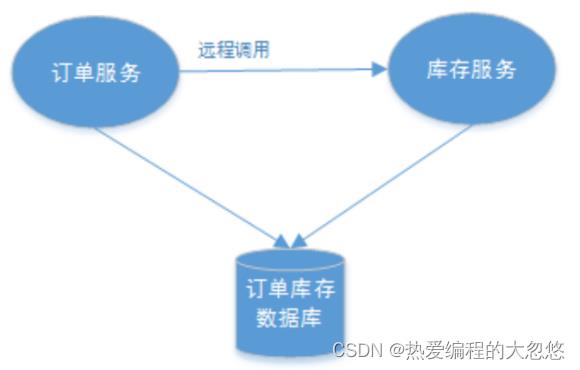
4.1 CAP理论
CAP是 Consistency、Availability、Partition tolerance三个词语的缩写,分别表示一致性、可用性、分区容忍性。
使用下边的分布式系统结构进行说明:
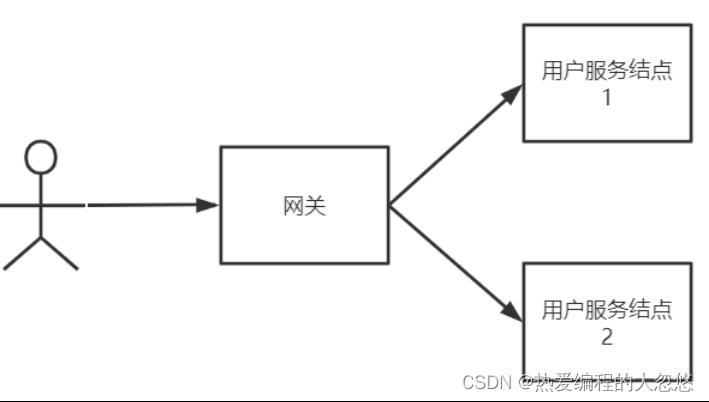
客户端经过网关访问用户服务的两个结点,一致性是指用户不管访问哪一个结点拿到的数据都是最新的,比如查询小明的信息,不能出现在数据没有改变的情况下两次查询结果不一样。
可用性是指任何时候查询用户信息都可以查询到结果,但不保证查询到最新的数据。
分区容忍性也叫分区容错性,由于网络通信异常导致请求中断、消息丢失,但服务依然对外提供服务。
CAP理论要强调的是在分布式系统中这三点不可能全部满足,由于是分布式系统就要满足分区容忍性,因为服务之间难免出现网络异常,不能因为局部网络异常导致整个系统不可用。
满足P那么C和A不能同时满足:
比如我们添加一个用户小明的信息,该信息先添加到结点1中,再同步到结点2中,如下图:

如果要满足C一致性,必须等待小明的信息同步完成系统才可用(否则会出现请求到结点2时查询不到数据,违反了一致性),在信息同步过程中系统是不可用的,所以满足C的同时无法满足A。
如果要满足A可用性,要时刻保证系统可用就不用等待信息同步完成,此时系统的一致性无法满足。
所以在分布式系统中进行分布式事务控制,要么保证CP、要么保证AP。
4.2 分布式事务控制方案
学习了CAP理论我们知道进行分布式事务控制要在C和A中作出取舍,保证一致性就不要保证可用性,保证可用性就不要保证一致,首先你确认是要CP还是AP,具体要根据应用场景进行判断。
CP的场景:满足C舍弃A,强调一致性。
跨行转账:一次转账请求要等待双方银行系统都完成整个事务才算完成,只要其中一个失败另一方执行回滚操作。
开户操作:在业务系统开户同时要在运营商开户,任何一方开户失败该用户都不可使用,所以要满足CP。
AP的场景:满足A舍弃C,强调可用性。
订单退款,今日退款成功,明日账户到账,只要用户可以接受在一定时间内到账即可。
注册送积分,注册成功积分在24分到账。
支付短信通信,支付成功发短信,短信发送可以有延迟,甚至没有发送成功。
在实际应用中符合AP的场景较多,其实虽然AP舍弃C一致性,实际上最终数据还是达到了一致,也就满足了最终一致性,所以业界定义了BASE理论。
4.3 Base理论
BASE 是 Basically Available(基本可用)、Soft state(软状态)和 Eventually consistent (最终一致性)三个短语的缩写。
基本可用:当系统无法满足全部可用时保证核心服务可用即可,比如一个外卖系统,每到中午12点左右系统并发量很高,此时要保证下单流程涉及的服务可用,其它服务暂时不可用。
软状态:是指可以存在中间状态,比如:打印自己的社保统计情况,该操作不会立即出现结果,而是提示你打印中,请在XXX时间后查收。虽然出现了中间状态,但最终状态是正确的。
最终一致性:退款操作后没有及时到账,经过一定的时间后账户到账,舍弃强一致性,满足最终一致性。
4.4 课程发布的分布式事务控制
学习了这么多的理论,回到课程发布,执行课程发布操作后要向数据库、redis、elasticsearch、MinIO写四份数据,这个场景用哪种方案?
满足CP?
如果要满足CP就表示课程发布操作后向数据库、redis、elasticsearch、MinIO写四份数据,只要有一份写失败其它的全部回滚。
满足AP?
课程发布操作后,先更新数据库中的课程发布状态,更新后向redis、elasticsearch、MinIO写课程信息,只要在一定时间内最终向redis、elasticsearch、MinIO写数据成功即可。
课程发布满足AP即可,使用BASE理论实现。

1、在内容管理服务的数据库中添加一个消息表,消息表和课程发布表在同一个数据库。
2、点击课程发布通过本地事务向课程发布表写入课程发布信息,同时向消息表写课程发布的消息。两条记录保证同时存在或同时不存在。
3、启动任务调度系统定时调度内容管理服务去定时扫描消息表的记录。
4、当扫描到课程发布的消息时即开始完成向redis、elasticsearch、MinIO同步数据的操作。
5、同步数据的任务完成后删除消息表记录。
下图是课程发布操作的流程:

1、执行发布操作,内容管理服务存储课程发布表的同时向消息表添加一条“课程发布任务”。这里使用本地事务保证课程发布信息保存成功,同时消息表也保存成功。
2、任务调度服务定时调度内容管理服务扫描消息表,由于课程发布操作后向消息表插入一条课程发布任务,此时扫描到一条任务。
3、拿到任务开始执行任务,分别向redis、elasticsearch及文件系统存储数据。
4.任务完成后删除消息表记录。
4.5 事务型消息解决AP型分布式事务
服务通常需要在更新数据库的事务中发布消息,例如: 在创建或更新业务实体时发布领域事件。
数据库更新和消息发送都必须在一个事务中进行,不能是服务一个数据库,事务型消息表另一个数据库,这会导致分布式事务问题,而我们采用事务型消息解决AP型分布式事务,就是为了避免实现CP的复杂和低效。
在事务型消息解决方案中,最简单的方法是使用数据库作为消息队列:
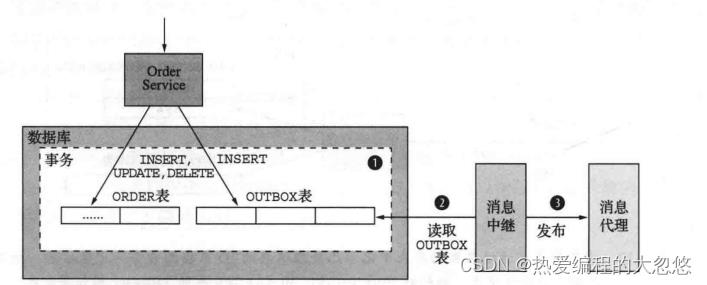
通过轮询模式发布事件: 不断轮询消息表,然后将轮询得到的消息发送给消息代理; 轮询数据库会占用数据库连接和资源,需要考虑项目是否对性能敏感。
使用事务日志拖尾模式发布事件: 每次应用程序提交到数据库的更新都对应着数据库事务日志中的一个条目,事务日志挖掘器(如: Canal)可以读取事务日志(如: mysql的binglog),把每条跟消息有关的记录发送给消息代理。

4.6 消息处理SDK
通过上面对事务型消息的介绍,我们可以知道课程发布解决分布式事务控制最终采用的方案其实借鉴了事务型消息思想;并且这种解决方案针对大多数AP型分布式事务都是通解,我们可以考虑将其封装为一个通用SDK类。
我们先来分析一下具体的需求:
课程发布操作执行后需要扫描消息表的记录,有关消息表处理的有哪些?
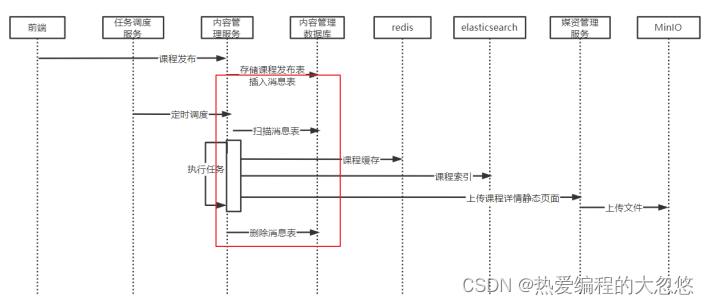
上图中红色框内的都是与消息处理相关的操作:
1、新增消息表
2、扫描消息表。
3、更新消息表。
4、删除消息表。
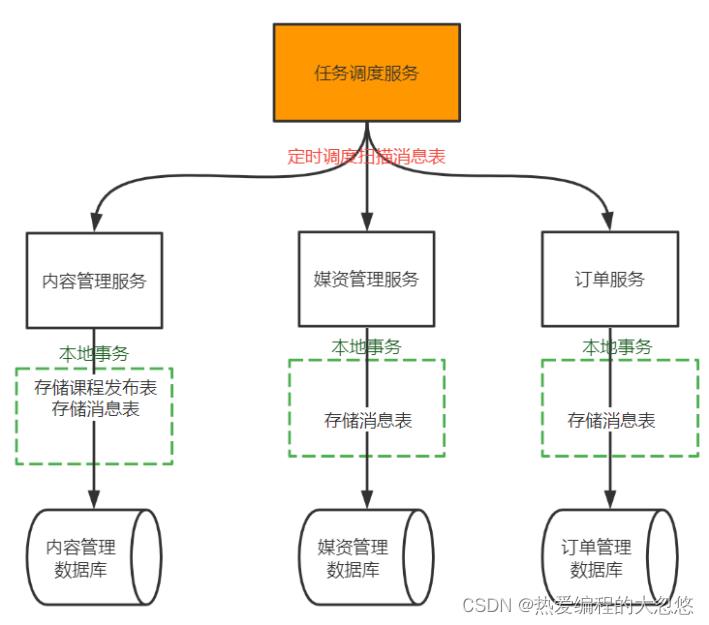
如果在每个地方都实现一套针对消息表定时扫描、处理的逻辑基本上都是重复的,软件的可复用性太低,成本太高。
如何解决这个问题?
针对这个问题可以想到将消息处理相关的逻辑做成一个通用的东西。
是做成通用的服务,还是做成通用的代码组件呢?
通用的服务是完成一个通用的独立功能,并提供独立的网络接口,比如:项目中的文件系统服务,提供文件的分布式存储服务。
代码组件也是完成一个通用的独立功能,通常会提供API的方式供外部系统使用,比如:fastjson、Apache commons工具包等。
如果将消息处理做成一个通用的服务,该服务需要连接多个数据库,因为它要扫描微服务数据库下的消息表,并且要提供与微服务通信的网络接口,单就针对当前需求而言开发成本有点高。
如果将消息处理做一个SDK工具包相比通用服务不仅可以解决将消息处理通用化的需求,还可以降低成本。
所以,本项目确定将对消息表相关的处理做成一个SDK组件供各微服务使用,如下图所示:
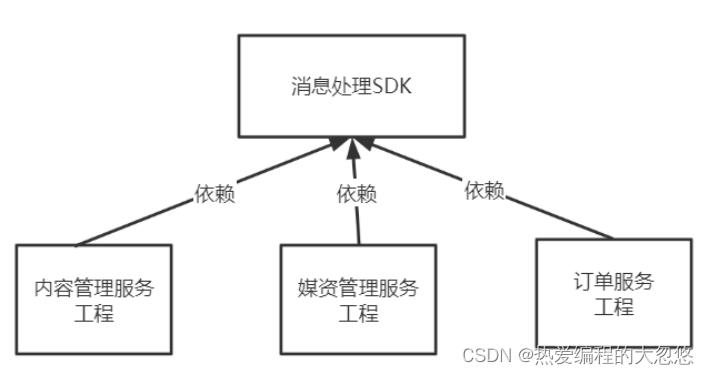
下边对消息SDK的设计内容进行说明:
执行任务应该是sdk包含的功能吗?
拿课程发布任务举例,执行课程发布任务是要向redis、索引库等同步数据,其它任务的执行逻辑是不同的,所以执行任务在sdk中不用实现,只需要提供一个抽象方法由具体的执行任务方去实现。
如何保证任务的幂等性?
任务执行完成后会从消息表删除,如果消息的状态是完成或不存在消息表中,则不用执行。
如何保证任务不重复执行?
除了保证任务的幂等性外,任务调度采用分片广播,获取等处理消息根据分片参数去获取,另外阻塞调度策略为丢弃任务。
根据消息表记录是否存在或消息表中的任务状态去保证任务的幂等性,如果一个任务有好几个小任务,比如:课程发布任务需要执行三个同步操作:存储课程到redis、存储课程到索引库,存储课程页面到文件系统。如果其中一个小任务已经完成也不应该去重复执行。这里该如何设计?
将小任务作为任务的不同的阶段,在消息表中设计阶段状态。
给出一个事务型消息表的具体实现:
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
DROP TABLE IF EXISTS `transaction_message`;
CREATE TABLE `transaction_message` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键',
`message_type` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '消息类型',
`business_key1` varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci COMMENT '关联业务信息,如: 用户ID',
`business_key2` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci COMMENT '关联业务信息,如: 订单信息',
`business_key3` varchar(256) CHARACTER SET utf8 COLLATE utf8_general_ci COMMENT '关联业务信息,如: 更加复杂的信息',
`retry_num` int NOT NULL DEFAULT '0' COMMENT '重试次数',
`state` smallint NOT NULL DEFAULT '0' COMMENT '处理状态,0:初始,1:成功,2:失败',
`stage_state` smallint NOT NULL DEFAULT '0' COMMENT '各个小阶段的处理状态',
`return_failure_msg` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci COMMENT '失败原因',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`latest_execute_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '最近一次被消费的时间',
PRIMARY KEY (id)
) ENGINE = InnoDB AUTO_INCREMENT = 0 CHARACTER SET = 'utf8' COLLATE = 'utf8_general_ci' ROW_FORMAT = compact COMMENT '事务型消息表';
SET FOREIGN_KEY_CHECKS = 1;各个小阶段的状态采用一字节的位图来表示,如果一个任务只包含四个小阶段,那么只需要使用位图的前四位即可,1即为完成,0表示未完成。
我们利用小阶段状态可以实现消息的幂等性,因为消息处理失败,不意味着所有小阶段都执行失败,因此,再次调度处理消息时,需要跳过对处理成功的小阶段任务的执行。
SDK目录结构:
package dhy.com;
import java.util.List;
import java.util.Map;
/**
* 事务型消息服务类
* @author 大忽悠
* @create 2023/1/27 19:48
*/
public interface ITMService
/**
* @param messageType 要获取的消息类型,传入null表示获取所有消息类型
* @param count 扫描记录数
* @param examples 额外的查询条件
* @return 返回获取到的事务消息列表
*/
List<TransactionMessage> getTransactionMessageList(String messageType, int count,Map<Object,Object> examples);
/**
* @param tmId 事务消息ID
* @return 事务消息
*/
TransactionMessage getTransactionMessage(long tmId);
/**
* 事务型消息是否被成功消费
* @param tmId 事务消息ID
* @return 消费是否成功
*/
boolean completed(long tmId);
/**
* 获取小阶段完成状态
* @param tmId 事务消息ID
* @param stageSeq 小阶段任务序号
* @return 当前小阶段状态是否为完成
*/
boolean getStage(long tmId,byte stageSeq);
package dhy.com;
import dhy.com.util.BitUtil;
import dhy.com.util.TMUtil;
import lombok.extern.slf4j.Slf4j;
import java.util.List;
import java.util.Map;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
/**
* @author 大忽悠
* @create 2023/1/27 20:33
*/
@Slf4j
public abstract class AbstractTmMessageImpl implements ITMService
/**
* 线程池大小默认为CPU核心数
*/
private final ExecutorService THREAD_POOL= Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
/**
* 默认超时等待时间
*/
private final long TIME_OUT=1800;
/**
* 根据事务消息执行对应的任务
* @param transactionMessage 事务消息
* @return 此次事务消息是否处理成功
*/
public abstract boolean execute(TransactionMessage transactionMessage);
public void process(String messageType, int count, Map<Object,Object> examples)
try
List<TransactionMessage> tmList = getTransactionMessageList(messageType, count, examples);
log.info("扫描得到的事务消息个数为: ",tmList.size());
CountDownLatch countDownLatch = new CountDownLatch(tmList.size());
THREAD_POOL.execute(()->
for (TransactionMessage tm : tmList)
log.info("开始执行任务: ",tm);
try
boolean res = execute(tm);
clearAfterExecute(tm, res);
catch (Throwable t)
log.error("任务执行出现异常: ,任务信息: ",t.getMessage(),tm);
t.printStackTrace();
countDownLatch.countDown();
);
//等待指定时间,防止无限等待
countDownLatch.await(TIME_OUT, TimeUnit.SECONDS);
catch (Exception e)
e.printStackTrace();
finally
THREAD_POOL.shutdown();
private void clearAfterExecute(TransactionMessage tm, boolean res)
if(res &&completed(tm.getId()))
doRemoveTm(tm.getId());
//TODO: 将此次处理的事务消息写入事务消息处理历史表中,方便回溯操作
log.info("任务执行成功: ", tm);
else
//设置当前事务消息状态为失败
tm.setState((byte) 2);
doUpdateTmAfterFailure(tm);
log.info("任务执行失败: ", tm);
/**
* @param tm 将事务消息失败状态更新到数据库中
*/
protected abstract void doUpdateTmAfterFailure(TransactionMessage tm);
/**
* @param id 删除某个被成功执行的tm
*/
protected abstract void doRemoveTm(Long id);
/**
* 设置某个小阶段任务状态为完成
*
* @param tmId 事务消息ID
* @param stageSeq 小阶段任务序号
* @return 设置是否成功
*/
protected boolean completedStage(long tmId, byte stageSeq)
TransactionMessage transactionMessage = getTransactionMessage(tmId);
TMUtil.completedStage(transactionMessage,stageSeq);
return doCompletedStage(transactionMessage);
protected abstract boolean doCompletedStage(TransactionMessage transactionMessage);
/**
* 事务型消息是否被成功消费
*
* @param tmId 事务消息ID
* @return 消费是否成功
*/
@Override
public boolean completed(long tmId)
return getTransactionMessage(tmId).getState()==1;
/**
* 获取小阶段完成状态
*
* @param tmId 事务消息ID
* @param stageSeq 小阶段任务序号
* @return 当前小阶段状态是否为完成
*/
@Override
public boolean getStage(long tmId, byte stageSeq)
return BitUtil.is1(getTransactionMessage(tmId).getStageState(),stageSeq);
package dhy.com;
import lombok.Data;
import java.time.LocalDateTime;
/**
* 事务消息实体类
* @author zdh
*/
@Data
public class TransactionMessage
private Long id;
private String messageType;
private String businessKey1;
private String businessKey2;
private String businessKey3;
private Integer retryNum;
private Byte state;
private Byte stageState;
private String returnFailureMsg;
private LocalDateTime createTime;
private LocalDateTime latestExecuteTime;
package dhy.com.util;
/**
* @author 大忽悠
* @create 2023/1/27 20:17
*/
public class BitUtil
/**
* 将x的第y位设置为1
*/
public static byte setBit1(byte x,byte y)
return x|=(1<<y);
/**
* 将x的第y位设置为0
*/
public static byte setBit0(byte x,byte y)
return x&=~(1<<y);
/**
* x的第index位是否为1
*/
public static boolean is1(byte x,byte index)
return (x>>(index-1) & 1)==1;
package dhy.com.util;
import dhy.com.TransactionMessage;
/**
* @author 大忽悠
* @create 2023/1/27 20:02
*/
public class TMUtil
/**
* 设置某个小阶段任务状态为完成
* @param transactionMessage 事务消息
* @param stage 小阶段任务序号
*/
public static TransactionMessage completedStage(TransactionMessage transactionMessage, byte stage)
transactionMessage.setStageState(BitUtil.setBit1(transactionMessage.getStageState(),stage));
return transactionMessage;
/**
* 判断某个小阶段任务是否完成
* @param transactionMessage 事务消息
* @param stage 小阶段任务序号
* @return 小阶段任务是否完成
*/
public static boolean getStage(TransactionMessage transactionMessage,byte stage)
return BitUtil.is1(transactionMessage.getStageState(),stage);
5.页面静态化
根据课程发布的操作流程,执行课程发布后要将课程详情信息页面静态化,生成html页面上传至文件系统。
什么是页面静态化?
课程预览功能通过模板引擎技术在页面模板中填充数据,生成html页面,这个过程是当客户端请求服务器时服务器才开始渲染生成html页面,最后响应给浏览器,这个过程支持并发是有限的。
页面静态化则强调将生成html页面的过程提前,提前使用模板引擎技术生成html页面,当客户端请求时直接请求html页面,由于是静态页面可以使用nginx、apache等高性能的web服务器进行缓存,并发性能高。
什么时候能用页面静态化技术?
当数据变化不频繁,一旦生成静态页面很长一段时间内很少变化,此时可以使用页面静态化。因为如果数据变化频繁,一旦改变就需要重新生成静态页面,导致维护静态页面的工作量很大。
根据课程发布的业务需求,虽然课程发布后仍可以修改课程信息,但需要经过课程审核,且修改频度不大,所以适合使用页面静态化。
具体步骤:
使用模板引擎编写课程信息的模板
调用接口获取模板上需要的模型数据
调用模板引擎API生成静态页面
将静态页面上传到文件系统
开启nginx缓存功能,加速访问
6. OpenFeign采用扩展包支持文件上传
7. 远程调用中涉及到的组件
rpc远程调用在微服务中通常采用HTTP协议进行通信,因此可选的组件从底层的okhttp,httpclient到spring封装的restTemplate,再到更加方便的OpenFeign。
如果rpc远程调用采用的是二进制协议进行通信,可以考虑采用protocol buffers, 该协议具体应用有grpc。
OpenFeign远程调用在微服务中由于存在级联调用,因此存在导致服务雪崩的问题,这个时候需要采用Hystrix进行服务降级,还可以进行限流等操作。
如果想更加方便,可以考虑采用sentinel。
8. es进行课程搜索
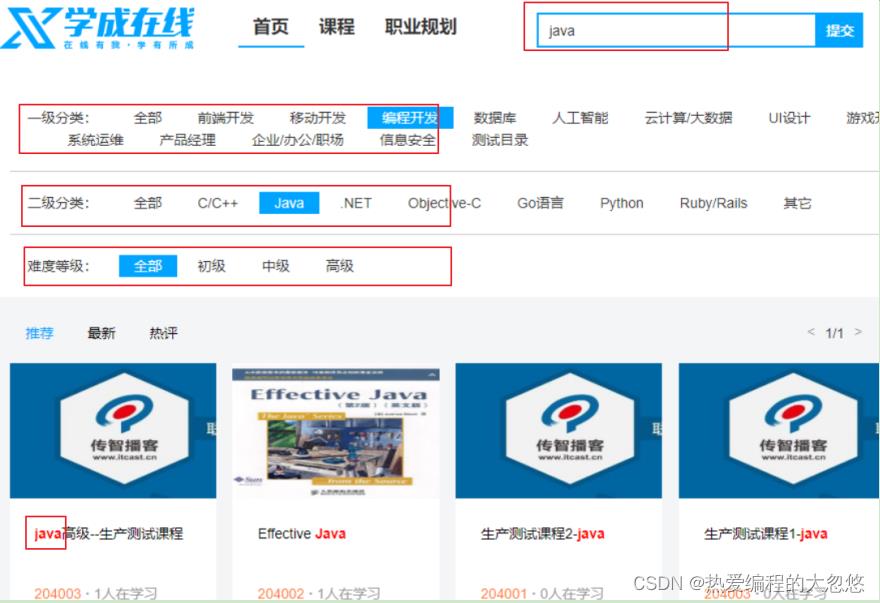
根据搜索界面,可知我们有如下搜索需求:
根据一级分类,二级分类搜索课程课程信息
根据关键字搜索课程信息,搜索方式文全文搜索,关键字需要匹配课程的名称和课程内容
根据难度等级搜索课程
搜索结果分页显示
具体实现:
整体采用布尔查询: 布尔查询可以实现多条件搜索
根据关键字搜索,采用MultiMatchQuery,搜索name,description字段
分类,课程等级搜索采用过滤器实现,因为我们无需考虑搜索相关性,因此采用过滤器实现,跳过算分过程,还可以利用过滤器缓存等优势
分页查询(es天然支持)
高亮显示
提升相关性细节:
多字段匹配时,提升name字段的boost值 (可以使用boosting查询,或者单独在字段上配置boost属性)
minimumShouldMatch提升查询精准度
minimum_should_match参数用于设置返回的文档必须匹配的最少should分支数。参数值合法格式如下:
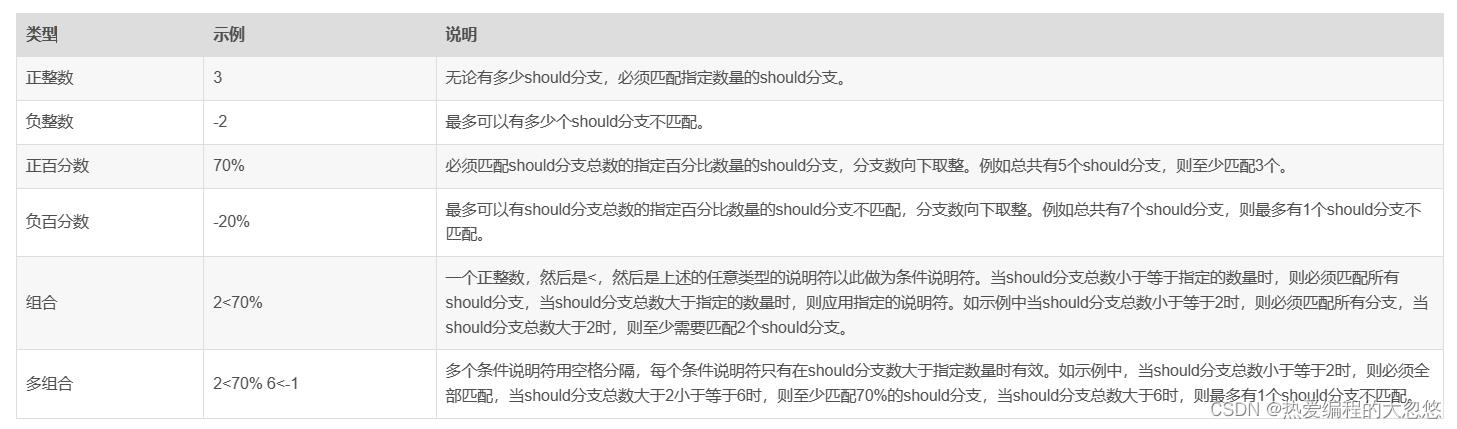
如果基于说明符计算后不需要匹配should分支,那么布尔查询的通用规则:当布尔查询中没有must分支时必须匹配至少一个should分支,在检索时仍适用。无论计算的结果有多大或多小,需要匹配的should分支数永远不会小于1或大于should分支总数。


每个课程文档中都包含当前课程所属于的一级分类和二级分类,如果用户可以在上传课程时,自定义一级分类和二级分类,并且我们没有在db中创建相关表来存储一级分类和二级分类,那么此时如果需要在搜索界面上显示一级分类和二级分类,该怎么实现呢?
利用es提供的聚合功能即可,还可以方便统计出每个分类下的课程数量。
以上是关于学成在线项目开发技巧整理---第二部分的主要内容,如果未能解决你的问题,请参考以下文章