「深度学习一遍过」必修28:基于C3D预训练模型训练自己的视频分类数据集的设计与实现
Posted 大展鸿兔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了「深度学习一遍过」必修28:基于C3D预训练模型训练自己的视频分类数据集的设计与实现相关的知识,希望对你有一定的参考价值。
本专栏用于记录关于深度学习的笔记,不光方便自己复习与查阅,同时也希望能给您解决一些关于深度学习的相关问题,并提供一些微不足道的人工神经网络模型设计思路。
专栏地址:「深度学习一遍过」必修篇
目录
开源项目代码:https://github.com/jfzhang95/pytorch-video-recognition
1 DownLoad or Clone
Linux:
git clone https://github.com/jfzhang95/pytorch-video-recognition.git
cd pytorch-video-recognitionWindows:

2 数据集准备
数据集目录树如下所示:
数据集文件夹名
├── 类别1
│ ├── 类别1_1.mp4
│ └── ...
├── 类别2
│ ├── 类别2_1.mp4
│ └── ...
└── 类别3
│ ├── 类别2_1.mp4
│ └── ...
经过预处理后,输出目录的结构如下:
数据集文件夹名
├── 类别1
│ ├── 类别1_1
│ │ ├── 类别1_1_1.jpg
│ │ └── ...
│ └── ...
├── 类别2
│ ├── 类别2_1
│ │ ├── 类别2_1_1.jpg
│ │ └── ...
│ └── ...
└── 类别3
│ ├── 类别3_1
│ │ ├── 类别3_1_1.jpg
│ │ └── ...
│ └── ...
补充:预处理代码
#!/usr/bin/python
# -*- coding:utf-8 -*-
import cv2
VideoCap = cv2.VideoCapture('此处填写mp4/avi文件地址')
# eg:VideoCap = cv2.VideoCapture('E:/DATA/one/1.mp4')
i = 1
while True:
_, img = VideoCap.read()
save_path = '此处填写保存的每一帧图像的文件路径'
# eg:save_path = 'E:/data/one/1/' + str(i) + '.jpg'
cv2.imwrite(save_path, img)
print(save_path)
i = i + 1
if _ == False:
break3 代码调试
3.1 下载预训练模型
从百度云或 GoogleDrive下载预训练模型。目前仅支持 C3D 的预训练模型。

3.2 配置数据集和预训练模型路径
在 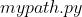 中配置数据集和预训练模型路径 。
中配置数据集和预训练模型路径 。

这一步仅修改上图红框内的路径内容即可。
3.3 修改 label.txt 文件
源码中 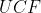 数据集包括
数据集包括  类视频,分别是:
类视频,分别是:

根据自己数据集改写 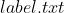 文件(如上图修改
文件(如上图修改 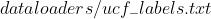 文件)
文件)
比如修改成:

3.4 运行 train.py
解决报错一:ValueError: could not broadcast input array from shape (720,1280,3) into shape (128,171,3)
方法一: 输入数据集图像大小为
输入数据集图像大小为 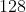 ×
×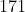
方法二:修改 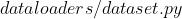 中约
中约  ~
~ 行变量参数为
行变量参数为  ×
×
修改前:

修改后:

解决报错二:RuntimeError: Expected object of scalar type Long but got scalar type Int for argument #2 'target' in call to _thnn_nll_loss_forward
方法:将变量强制转换为  型
型
将  文件中约第
文件中约第 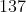 行代码改写为
行代码改写为  。
。
修改前:

修改后:

解决报错三:ValueError: num_samples should be a positive integer value, but got num_samp=0
方法: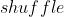 参数设置为
参数设置为 
将 文件中约 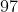 行位置的
行位置的  修改为
修改为 
修改前:

修改后:

一般而言,解决完这三个问题即可训练自己的数据集。
3.5 运行 inference.py
修改 行模型运行路径

修改 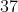 行测试视频路径
行测试视频路径

欢迎大家交流评论,一起学习
希望本文能帮助您解决您在这方面遇到的问题
感谢阅读
END
以上是关于「深度学习一遍过」必修28:基于C3D预训练模型训练自己的视频分类数据集的设计与实现的主要内容,如果未能解决你的问题,请参考以下文章