Android 之IPC详解
Posted 小陈乱敲代码
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Android 之IPC详解相关的知识,希望对你有一定的参考价值。
1.1 android IPC简介
IPC是Inter-Process Communication的缩写,含义为进程间通信或者跨进程通信,是指两个进程之间进行数据交换的过程。
按照操作系统中的描述,线程是CPU调度的最小单元,同时线程是一种有限的系统资源。而进程一般指一个执行单元,在PC和移动设备上指一个程序或者一个应用。
一个进程可以包含多个线程,因此进程和线程是包含与被包含的关系。最简单的情况下,一个进程中可以只有一个线程,即主线程,在Android里面主线程也叫UI线程,在UI线程里才能操作界面元素。很多时候,一个进程中需要执行大量耗时的任务,如果这些任务放在主线程中去执行就会造成界面无法响应,严重影响用户体验,这种情况在PC系统和移动系统中都存在,在Android中有一个特殊的名字叫做ANR(Application Not Responding),即应用无响应。解决这个问题就需要用到线程,把一些耗时的任务放在线程中即可。
1.2 Android中的多进程模式
1.2.1 开启多进程模式
正常情况下,在Android中多进程是指一个应用中存在多个进程的情况,因此这里不讨论两个应用之间的多进程情况。
首先,在Android中使用多进程只有一种方法,那就是给四大组件(Activity、Service、Receiver、ContentProvider)在AndroidMenifest中指定android:process属性,除此之外没有其他办法,也就是说我们无法给一个线程或者一个实体类指定其运行时所在的进程。
其实还有另一种非常规的多进程方法,那就是通过JNI在native层去fork一个新的进程,但是这种方法属于特殊情况,也不是常用的创建多进程的方式,因此我们暂时不考虑这种方式。
假如当前App的包名为com.dream.shoppe,SecondActivity和ThirdActivity的android:process属性分别为“:remote”、“com.dream.shoppe2.remote”,那么这两种方式有区别吗?
其实是有区别的,区别有两方面:
首先,“:”的含义是指要在当前的进程名前面附加上当前的包名,这是一种简写的方法,对于SecondActivity来说,它完整的进程名为com.dream.shoppe:remote,而对于ThirdActivity中的声明方式,它是一种完整的命名方式,不会附加包名信息,即是属性值本身”com.dream.shoppe2.remote“;
其次,进程名以“:”开头的进程属于当前应用的私有进程,其他应用的组件不可以和它跑在同一个进程中,而进程名不以“:”开头的进程属于全局进程,其他应用通过ShareUID方式可以和它跑在同一个进程中。
Android系统会为每个应用分配一个唯一的UID,具有相同UID的应用才能共享数据。这里要说明的是,两个应用通过ShareUID跑在同一个进程中是有要求的,需要这两个应用有相同的ShareUID并且签名相同才可以。在这种情况下,它们可以互相访问对方的私有数据,比如data目录、组件信息等,不管它们是否跑在同一个进程中。当然如果它们跑在同一个进程中,那么除了能共享data目录、组件信息,还可以共享内存数据,或者说它们看起来就像是一个应用的两个部分。
1.2.2 多进程模式的运行机制
一般来说,使用多进程会造成如下几方面的问题:
- (1)静态成员和单例模式完全失效。 Android为每一个应用分配了一个独立的虚拟机,或者说为每个进程都分配一个独立的虚拟机,不同的虚拟机在内存分配上有不同的地址空间,这就导致在不同的虚拟机中访问同一个类的对象会产生多份副本。
- (2)线程同步机制完全失效。 既然都不是一块内存了,那么不管是锁对象还是锁全局类都无法保证线程同步,因为不同进程锁的不是同一个对象。
- (3)SharedPreferences的可靠性下降。 因为SharedPreferences不支持两个进程同时去执行写操作,否则会导致一定几率的数据丢失,这是因为SharedPreferences底层是通过读/写XML文件来实现的,并发写显然是可能出问题的,甚至并发读/写都有可能出问题。(题外话,SP是一个xml文件对应一个SP对象,初次读取SP时会加载一次对应xm文件,后续增删改查无论异步操作还是同步操作都只是对内存中的SP对象的操作,并不会立刻同步更新到对应xml文件中。)
- (4)Application会多次创建。 当一个组件跑在一个新的进程中的时候,由于系统要在创建新的进程同时分配独立的虚拟机,所以这个过程其实就是启动一个应用的过程。因此,相当于系统又把这个应用重新启动了一遍,既然重新启动了,那么自然会创建新的Application。
1.3 IPC基础概念介绍
1.3.1 Serializable序列化
/**
* @author Huadao
* @date Created in 2022/10/20
* @desc
*/
public class User implements Serializable
/**
* 是否声明序列化版本皆可,但是反序列化必需版本号相同。
* 可以手动指定,也可以让IDE根据当前类的结构自动去生成它的hash值。
*/
private static final long serialVersionUID = 1L;
/**
* 静态变量属于类不属于对象,所以不会参与序列化过程。
*/
public static boolean IS_SERIAL = true;
/**
* transient关键字标记的成员变量不参与序列化过程
*/
private transient String mName;
public String getName()
return mName;
public void setName(String name)
mName = name;
String FILE_PATH = "xxx/cache.txt";
// 序列化过程
User user = new User("张三");
ObjectOutputStream outputStream = null;
try
outputStream = new ObjectOutputStream(new FileOutputStream(FILE_PATH));
outputStream.writeObject(user);
catch (IOException e)
e.printStackTrace();
finally
if (outputStream != null)
try
outputStream.close();
catch (IOException e)
e.printStackTrace();
// 反序列化
ObjectInputStream inputStream = null;
try
inputStream = new ObjectInputStream(new FileInputStream(FILE_PATH));
User newUser = (User) inputStream.readObject();
catch (IOException | ClassNotFoundException e)
e.printStackTrace();
finally
if (inputStream != null)
try
inputStream.close();
catch (IOException e)
e.printStackTrace();
Serializable是Java所提供的一个序列化接口,它是一个空接口,为对象提供标准的序列化和反序列化操作。使用Serializable来实现序列化相当简单,只需要在类的声明中指定一个标识即可自动实现默认的序列化过程。
即使不指定serialVersionUID也可以实现序列化,那到底要不要指定呢?
如果指定的话,serialVersionUID后面那一长串数字又是什么含义呢?
我们要明白,系统既然提供了这个serialVersionUID,那么它必须是有用的。这个serialVersionUID是用来辅助序列化和反序列化过程的,原则上序列化后的数据中的serialVersionUID只有和当前类的serialVersionUID相同才能够正常地被反序列化。
serialVersionUID的详细工作机制是这样的:序列化的时候系统会把当前类的serialVersionUID写入序列化的文件中(也可能是其他中介),当反序列化的时候系统会去检测文件中的serialVersionUID,看它是否和当前类的serialVersionUID一致,如果一致就说明序列化的类的版本和当前类的版本是相同的,这个时候可以成功反序列化;否则就说明当前类和序列化的类相比发生了某些变换,比如成员变量的数量、类型可能发生了改变,这个时候是无法正常反序列化的,会报错误。
一般来说,我们应该手动指定serialVersionUID的值,比如1L,也可以让IDE根据当前类的结构自动去生成它的hash值,这样序列化和反序列化时两者的serialVersionUID是相同的,因此可以正常进行反序列化。
如果不手动指定serialVersionUID的值,反序列化时当前类有所改变,比如增加或者删除了某些成员变量,那么系统就会重新计算当前类的hash值并把它赋值给serialVersionUID,这个时候当前类的serialVersionUID就和序列化的数据中的serialVersionUID不一致,于是反序列化失败,程序就会出现crash。
所以,我们可以明显感觉到serialVersionUID的作用,当我们手动指定了它以后,就可以在很大程度上避免反序列化过程的失败。比如当版本升级后,我们可能删除了某个成员变量也可能增加了一些新的成员变量,这个时候我们的反向序列化过程仍然能够成功,程序仍然能够最大限度地恢复数据,相反,如果不指定serialVersionUID的话,程序则会挂掉。当然我们还要考虑另外一种情况,如果类结构发生了非常规性改变,比如修改了类名,修改了成员变量的类型,这个时候尽管serialVersionUID验证通过了,但是反序列化过程还是会失败,因为类结构有了毁灭性的改变,根本无法从老版本的数据中还原出一个新的类结构的对象。
根据上面的分析,我们可以知道,给serialVersionUID指定为1L或者采用IDE根据当前类结构去生成的hash值,这两者并没有本质区别,效果完全一样。
以下两点需要特别提一下:
首先,静态成员变量属于类不属于对象,所以不会参与序列化过程;
其次,用transient关键字标记的成员变量不参与序列化过程。
另外,系统的默认序列化过程也是可以改变的,通过重写readObject()和writeObject()这两个方法即可。
1.3.2 Parcelable序列化
/**
* @author Huadao
* @date Created in 2022/10/20
* @desc
*/
public class User implements Parcelable
private String mName;
/**
* 模拟一个可序列化的成员变量
*/
private User mUser;
public User(String name,User user)
mName = name;
mUser = user;
/**
* 从序列化后的对象中创建原始对象
* @param in
*/
protected User(Parcel in)
// 属性输入
mName = in.readString();
// mUser是一个可序列化的成员变量对象,所以它的反序列化过程需要传递当前线程的上下文类加载器,否则会报无法找到类的错误。
mUser = in.readParcelable(Thread.currentThread().getContextClassLoader());
public static final Creator<User> CREATOR = new Creator<User>()
/**
* 从序列化后的对象中创建原始对象
*
* @param in
* @return
*/
@Override
public User createFromParcel(Parcel in)
return new User(in);
/**
* 创建指定长度的原始对象数组
* @param size
* @return
*/
@Override
public User[] newArray(int size)
return new User[size];
;
/**
* 返回当前对象的内容描述符,如果含有文件描述符,返回1,否则返回0,几乎所有情况都返回0。
* @return
*/
@Override
public int describeContents()
return 0;
/**
* 将当前对象写入序列化结构中
*
* @param dest
* @param flags 0 或者 1。为1时标识当前对象需要作为返回值返回,不能立即释放资源,几乎所有情况都为0。
*/
@Override
public void writeToParcel(Parcel dest, int flags)
// 属性输出
dest.writeString(mName);
dest.writeParcelable(mUser,0);
public String getName()
return mName;
public void setName(String name)
mName = name;
public User getUser()
return mUser;
public void setUser(User user)
mUser = user;
Parcelable也是一个接口,只要实现这个接口,一个类的对象就可以实现序列化并可以通过Intent和Binder传递。
Parcel内部包装了可序列化的数据,可以在Binder中自由传输。在序列化过程中需要实现的功能有序列化、反序列化和内容描述。
序列化功能由writeToParcel方法来完成,最终是通过Parcel中的一系列write方法来完成的;
反序列化功能由CREATOR来完成,其内部标明了如何创建序列化对象和数组,并通过Parcel的一系列read方法来完成反序列化过程;
内容描述功能由describeContents方法来完成,几乎在所有情况下这个方法都应该返回0,仅当当前对象中存在文件描述符时,此方法返回1。
系统已经为我们提供了许多实现了Parcelable接口的类,它们都是可以直接序列化的,比如Intent、Bundle、Bitmap等,同时List和Map也可以序列化,前提是它们里面的每个元素都是可序列化的。
1.3.3 序列化方式对比
既然Parcelable和Serializable都能实现序列化并且都可用于Intent间的数据传递,那么二者该如何选取呢?
Serializable是Java中的序列化接口,其使用起来简单但是开销很大,序列化和反序列化过程需要大量I/O操作。
而Parcelable是Android中的序列化方式,因此更适合用在Android平台上,它的缺点就是使用起来稍微麻烦点,但是它的效率很高,这是Android推荐的序列化方式,因此我们要首选Parcelable。
Parcelable主要用在内存序列化上,通过Parcelable将对象序列化到存储设备中或者将对象序列化后通过网络传输也都是可以的,但是这个过程会稍显复杂,因此在这两种情况下建议大家使用Serializable。
1.3.4 Binder
直观来说,Binder是Android中的一个类,它集成了IBinder接口。
从IPC角度来说,Binder是Android中的一种跨进程通信方式;
Binder还可以理解为一种虚拟的物理设备,它的设备驱动是/dev/binder,该通信方式在Linux中没有;
从AndroidFramework角度来说,Binder是ServiceManager连接各种Manager(ActivityManager、WindowManager,等等)和相应ManagerService的桥梁;
从Android应用层来说,Binder是客户端和服务端进行通信的媒介,当bindService的时候,服务端会返回一个包含了服务端业务调用的Binder对象,通过这个Binder对象,客户端就可以获取服务端提供的服务或者数据,这里的服务包括普通服务和基于AIDL的服务。
1.3.5 AIDL
首先,当客户端发起远程请求时,由于当前线程会被挂起直至服务端进程返回数据,所以如果一个远程方法是很耗时的,那么不能在UI线程中发起此远程请求;其次,由于服务端的Binder方法运行在Binder的线程池中,所以Binder方法不管是否耗时都应该采用同步的方式去实现,因为它已经运行在一个线程中了。
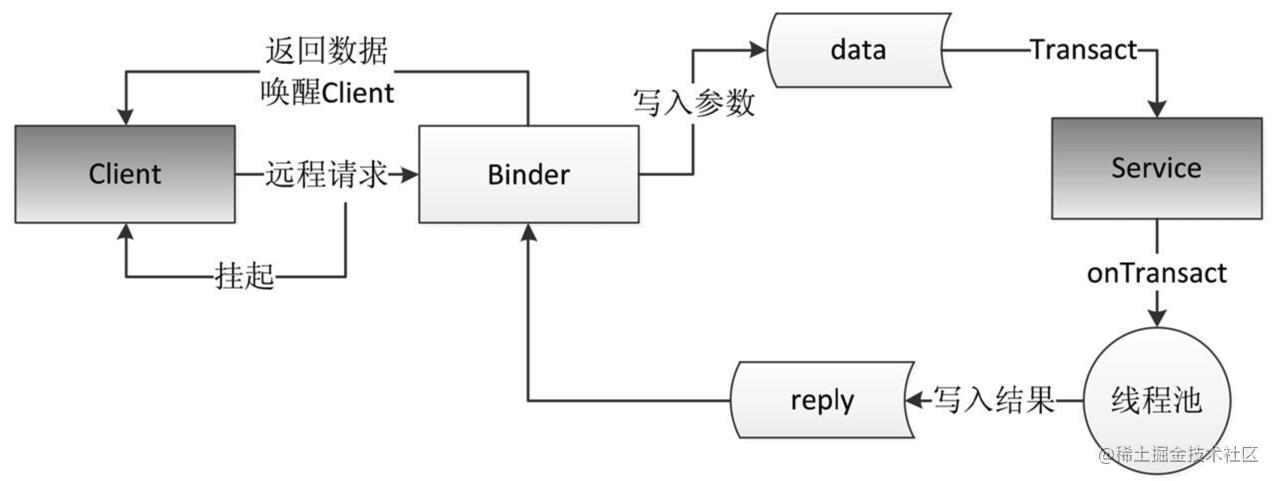
我们在实际开发中完全可以通过AIDL文件让系统去自动生成,手动去写的意义在于可以让我们更加理解Binder的工作原理,同时也提供了一种不通过AIDL文件来实现Binder的新方式。也就是说,AIDL文件并不是实现Binder的必需品。是否手动实现Binder没有本质区别,二者的工作原理完全一样,AIDL文件的本质是系统为我们提供了一种快速实现Binder的工具,仅此而已。
手动实现一个Binder可以通过如下步骤来完成:
-
(1)声明一个AIDL性质的接口,只需要继承IInterface接口即可,IInterface接口中只有一个asBinder方法。
-
(2)实现Stub类和Stub类中的Proxy代理类。
1.3.6 linkToDeath()与unlinkToDeath()
我们知道,Binder运行在服务端进程,如果服务端进程由于某种原因异常终止,这个时候我们到服务端的Binder连接断裂(称之为Binder死亡),会导致我们的远程调用失败。更为关键的是,如果我们不知道Binder连接已经断裂,那么客户端的功能就会受到影响。为了解决这个问题,Binder中提供了两个配对的方法linkToDeath和unlinkToDeath,通过linkToDeath我们可以给Binder设置一个死亡代理,当Binder死亡时,我们就会收到通知,这个时候我们就可以重新发起连接请求从而恢复连接。
-
linkToDeath()
-
unlinkToDeath()
1.4 Android中的IPC方式
1.4.1 使用Bundle
四大组件中的三大组件(Activity、Service、Receiver)都是支持在Intent中传递Bundle数据的,由于Bundle实现了Parcelable接口,所以它可以方便地在不同的进程间传输,这是一种最简单的进程间通信方式,
1.4.2 使用文件共享
文件共享方式适合在对数据同步要求不高的进程之间进行通信,并且要妥善处理并发读/写的问题。
当然,SharedPreferences是个特例,众所周知,SharedPreferences是Android中提供的轻量级存储方案,它通过键值对的方式来存储数据,在底层实现上它采用XML文件来存储键值对,每个应用的SharedPreferences文件都可以在当前包所在的data目录下查看到。一般来说,它的目录位于/data/data/package name/shared_prefs目录下,其中package name表示的是当前应用的包名。
从本质上来说,SharedPreferences也属于文件的一种,但是由于系统对它的读/写有一定的缓存策略,即在内存中会有一份SharedPreferences文件的缓存,因此在多进程模式下,系统对它的读/写就变得不可靠,当面对高并发的读/写访问, Sharedpreferences有很大几率会丢失数据,
因此,不建议在进程间通信中使用SharedPreferences。
1.4.3 使用Messenger
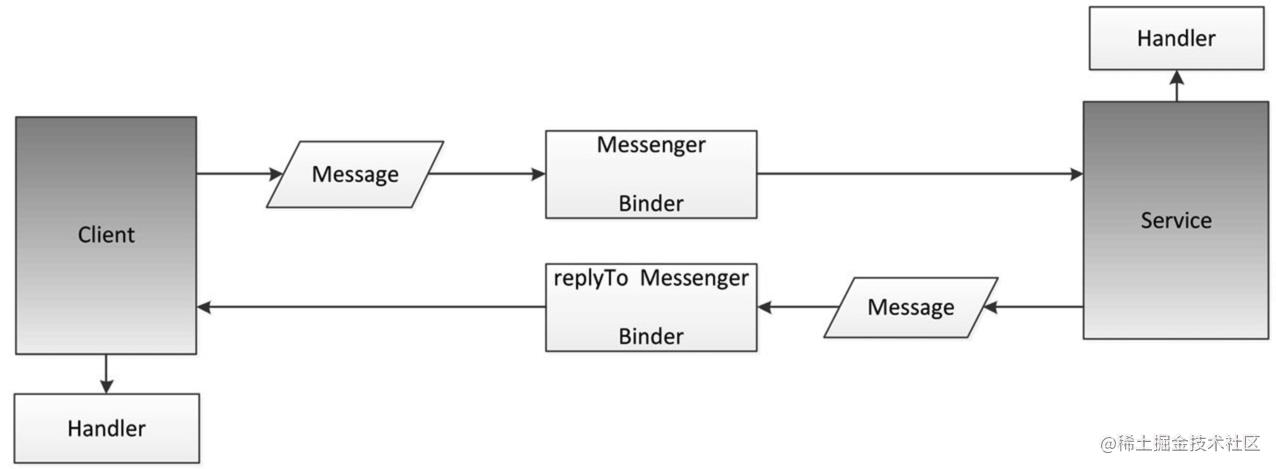
Messenger可以翻译为信使,顾名思义,通过它可以在不同进程中传递Message对象,在Message中放入我们需要传递的数据,就可以轻松地实现数据的进程间传递了。
Messenger是一种轻量级的IPC方案,它的底层实现是AIDL,从构造方法的实现上我们可以明显看出AIDL的痕迹,不管是IMessenger还是Stub.asInterface,这种使用方法都表明它的底层是AIDL。
实现一个Messenger有如下几个步骤,分为服务端和客户端:
1.服务端进程
首先,我们需要在服务端创建一个Service来处理客户端的连接请求,同时创建一个Handler并通过它来创建一个Messenger对象,然后在Service的onBind中返回这个Messenger对象底层的Binder即可。
2.客户端进程
客户端进程中,首先要绑定服务端的Service,绑定成功后用服务端返回的IBinder对象创建一个Messenger,通过这个Messenger就可以向服务端发送消息了,发消息类型为Message对象。如果需要服务端能够回应客户端,就和服务端一样,我们还需要创建一个Handler并创建一个新的Messenger,并把这个Messenger对象通过Message的replyTo参数传递给服务端,服务端通过这个replyTo参数就可以回应客户端。
1.4.4 使用AIDL
Messenger是以串行的方式处理客户端发来的消息,如果大量的消息同时发送到服务端,服务端仍然只能一个个处理,如果有大量的并发请求,那么用Messenger就不太合适了。同时,Messenger的作用主要是为了传递消息,很多时候我们可能需要跨进程调用服务端的方法,这种情形用Messenger就无法做到了,但是我们可以使用AIDL来实现跨进程的方法调用。
AIDL也是Messenger的底层实现,因此Messenger本质上也是AIDL,只不过系统为我们做了封装从而方便上层的调用而已。
1.服务端服务端首先要创建一个Service用来监听客户端的连接请求,然后创建一个AIDL文件,将暴露给客户端的接口在这个AIDL文件中声明,最后在Service中实现这个AIDL接口即可。
2.客户端客户端所要做事情就稍微简单一些,首先需要绑定服务端的Service,绑定成功后,将服务端返回的Binder对象转成AIDL接口所属的类型,接着就可以调用AIDL中的方法了。
在AIDL文件中,并不是所有的数据类型都是可以使用的,AIDL文件支持数据类型有:
- 基本数据类型(int、long、char、boolean、double等);
- String和CharSequence;
- List:只支持ArrayList,里面每个元素都必须能够被AIDL支持;
- Map:只支持HashMap,里面的每个元素都必须被AIDL支持,包括key和value;
- Parcelable:所有实现了Parcelable接口的对象;
- AIDL:所有的AIDL接口本身也可以在AIDL文件中使用。
以上6种数据类型就是AIDL所支持的所有类型,其中自定义的Parcelable对象和AIDL对象必须要显式import进来,不管它们是否和当前的AIDL文件位于同一个包内。
另外一个需要注意的地方是,如果AIDL文件中用到了自定义的Parcelable对象,那么必须新建一个和它同名的AIDL文件,并在其中声明它为Parcelable类型。
为了方便AIDL的开发,建议把所有和AIDL相关的类和文件全部放入同一个包中,这样做的好处是,当客户端是另外一个应用时,我们可以直接把整个包复制到客户端工程中,对于本例来说,就是要把com.ryg.chapter_2.aidl这个包和包中的文件原封不动地复制到客户端中。如果AIDL相关的文件位于不同的包中时,那么就需要把这些包一一复制到客户端工程中,这样操作起来比较麻烦而且也容易出错。需要注意的是,AIDL的包结构在服务端和客户端要保持一致,否则运行会出错,这是因为客户端需要反序列化服务端中和AIDL接口相关的所有类,如果类的完整路径不一样的话,就无法成功反序列化,程序也就无法正常运行。
1.4.5 使用ContentProvider
ContentProvider是Android中提供的专门用于不同应用间进行数据共享的方式,从这一点来看,它天生就适合进程间通信。和Messenger一样,ContentProvider的底层实现同样也是Binder,由此可见,Binder在Android系统中是何等的重要。虽然ContentProvider的底层实现是Binder,但是它的使用过程要比AIDL简单许多,这是因为系统已经为我们做了封装,使得我们无须关心底层细节即可轻松实现IPC。
1.4.6 使用Socket
Socket也称为“套接字”,是网络通信中的概念,它分为流式套接字和用户数据报套接字两种,分别对应于网络的传输控制层中的TCP和UDP协议。
TCP协议是面向连接的协议,提供稳定的双向通信功能,TCP连接的建立需要经过“三次握手”才能完成,为了提供稳定的数据传输功能,其本身提供了超时重传机制,因此具有很高的稳定性;
而UDP是无连接的,提供不稳定的单向通信功能,当然UDP也可以实现双向通信功能。在性能上,UDP具有更好的效率,其缺点是不保证数据一定能够正确传输,尤其是在网络拥塞的情况下。
1.5 Binder连接池
AIDL是一种最常用的进程间通信方式,是日常开发中涉及进程间通信时的首选。
随着AIDL数量的增加,我们不能无限制地增加Service,Service是四大组件之一,本身就是一种系统资源。而且太多的Service会使得我们的应用看起来很重量级,因为正在运行的Service可以在应用详情页看到,当我们的应用详情显示有10个服务正在运行时,这看起来并不是什么好事。针对上述问题,我们需要减少Service的数量,将所有的AIDL放在同一个Service中去管理。
Binder连接池的主要作用就是将每个业务模块的Binder请求统一转发到远程Service中去执行,从而避免了重复创建Service的过程,它的工作原理如图2-10所示:
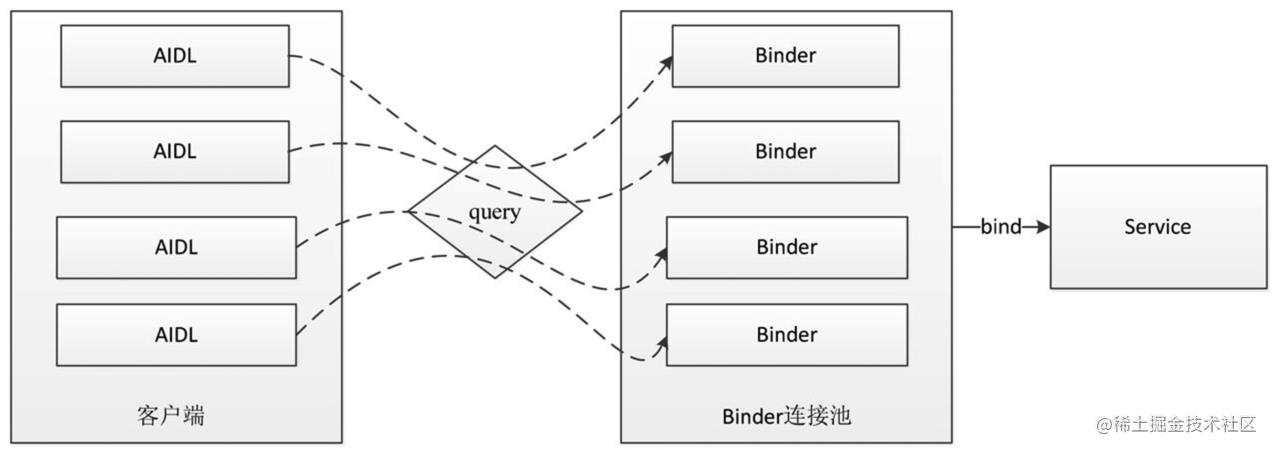
BinderPool能够极大地提高AIDL的开发效率,并且可以避免大量的Service创建,因此,建议在AIDL开发工作中引入BinderPool机制。
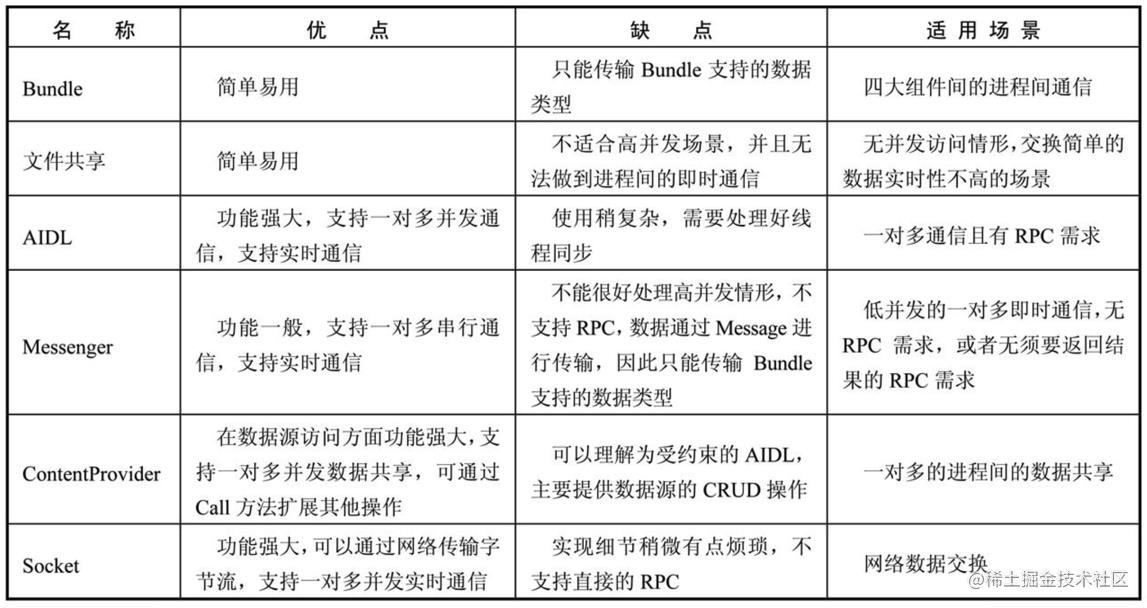
1.6 选用合适的IPC方式
链接:https://juejin.cn/post/7116408970620862472
作者:复制粘贴改改改
以上是关于Android 之IPC详解的主要内容,如果未能解决你的问题,请参考以下文章