YOLO学习笔记
Posted 神遁克里苏
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了YOLO学习笔记相关的知识,希望对你有一定的参考价值。
YOLOv1论文:You Only Look Once: Unified, Real-Time Object Detection
YOLO是一种目标检测算法,核心思想是将目标检测转化为回归问题求解,并基于一个单独的end-to-end网络,完成从原始图像的输入到物体位置和类别的输出。YOLO与Faster RCNN有以下区别:
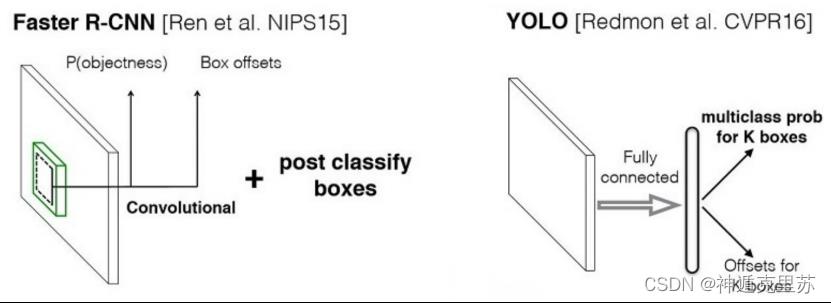
- Faster RCNN将目标检测分解为分类为题和回归问题分别求解:首先采用独立的RPN网络专门求取region proposal,即计算图1中的 P(objetness);然后对利用bounding box regression对提取的region proposal进行位置修正,即计算图1中的Box offsets(回归问题);最后采用softmax进行分类(分类问题)。
- YOLO将物体检测作为一个回归问题进行求解:输入图像经过一次网络,便能得到图像中所有物体的位置和其所属类别及相应的置信概率。
可以看出,YOLO将整个检测问题整合为一个回归问题,使得网络结构简单,检测速度大大加快;由于网络没有分支,所以训练也只需要一次即可完成。这种“把检测转化为回归问题”的思路非常有效,之后的很多检测算法(包括SSD)都借鉴了此思路。
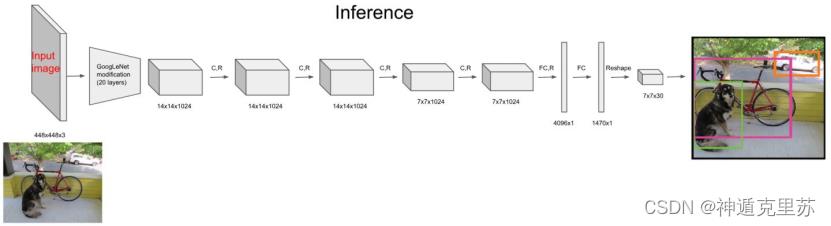
- 网络结构如下
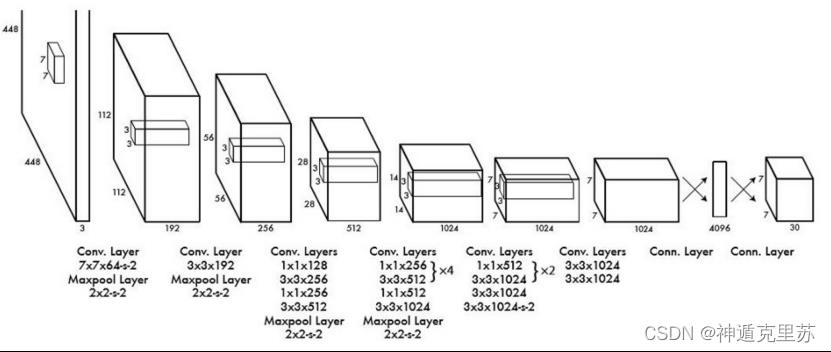
相比Faster RCNN,YOLO结构简单,网络中只包含conv,relu,pooling和全连接层,以及最后用来综合信息的detect层。其中使用了1x1卷积用于多通道信息融合。
YOLO共有24个卷积层
Fast-YOLO共有9个卷积层
YOLO核心思想
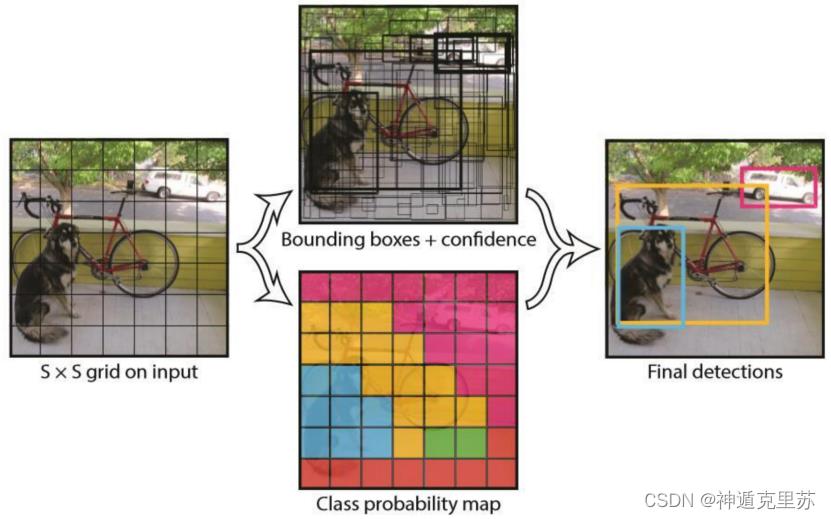
YOLO的工作过程分为以下几个过程:
(1) 将原图划分为SxS的网格
如果一个目标的中心落入某个格子,这个格子就负责检测该目标。

(2) 每个网格预测下面两项内容
C个类别概率Pr(classi|object),C是网络分类总数,由训练时决定。文中C=20。
B个bounding boxes,每个bounding boxes包含(x, y, w, h, confidence)5个信息,文中B=2。
其中,confidence代表了所预测的box中含有目标的置信度和这个bounding box预测的有多准两重信息:
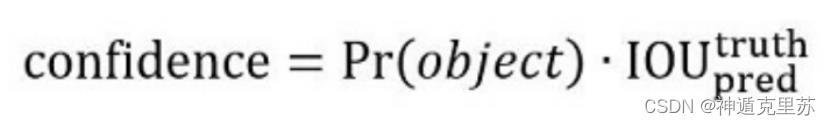
Pr(Object)=1,表示有目标落中心在格子里;Pr(Object)=0,表示没有目标落中心在格子里;
IOU表示预测的bounding box和实际的ground truth之间的IOU。
(其中Pr(Object)和IOU是训练时的信息,模型要朝着这个方向去训练,训练完后再测试时直接输出confidence,不会知道其中Pr(Object)和IOU是多少)
(3)模型输出信息:
Pr(classi|object)以及(x, y, w, h, confidence)
由于输入图像被分为SxS网格,每个网格包括B*5个预测量(x, y, w, h, confidence)和一个C类,所以网络输出是SxSx(5xB+C)大小。
将bounding box的confidence与其对应格子的Pr(classi|object)相乘,得到每个bounding box的class-specific confidence score:
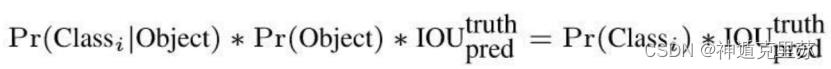
class-specific confidence score既包含了bounding box最终属于哪个类别的概率,又包含了bounding box位置的准确度。
然后将class-specific confidence score与阈值比较,留下较高的框。
最后进行NMS(非极大值抑制)就可以获得最终的输出框了。
- YOLO训练过程
对于任何一种网络,loss都是非常重要的,直接决定网络效果的好坏。YOLO的Loss函数设计时主要考虑了以下3个方面
(1) bounding box的(x, y, w, h)的坐标预测误差。由于对不同大小的bounding box预测中,相比于大box大小预测偏一点,小box大小测偏一点更不能被忍受。所以在Loss中同等对待大小不同的box是不合理的。为了解决这个问题,作者用了一个比较取巧的办法,即先对w和h求平方根压缩数值范围,再进行回归。
从后续效果来看,这样做有效,但是没有完全解决问题。
(2) bounding box的confidence预测误差。由于绝大部分网格中不包含目标,导致绝大部分box的confidence=0,所以在设计confidence误差时同等对待包含目标和不包含目标的box也是不合理的,否则会导致模型不稳定。作者在不含object的box的confidence预测误差中乘以惩罚权重 λnoobj =0.5。
除此之外,同等对待4个值(x, y, w, h)的坐标预测误差与1个值的conference预测误差也不合理,所以作者在坐标预测误差误差之前乘以权重 λcoord=5 。
(3) 分类预测误差。即每个box属于什么类别,需要注意一个网格只预测一次类别,即默认每个网格中的所有B个bounding box都是同一类。所以,YOLO的最终误差为下:
Loss = λcoord * 坐标预测误差 + (含object的box confidence预测误差 + λnoobj * 不含object的box confidence预测误差) + 类别预测误差
=

- 检测效果
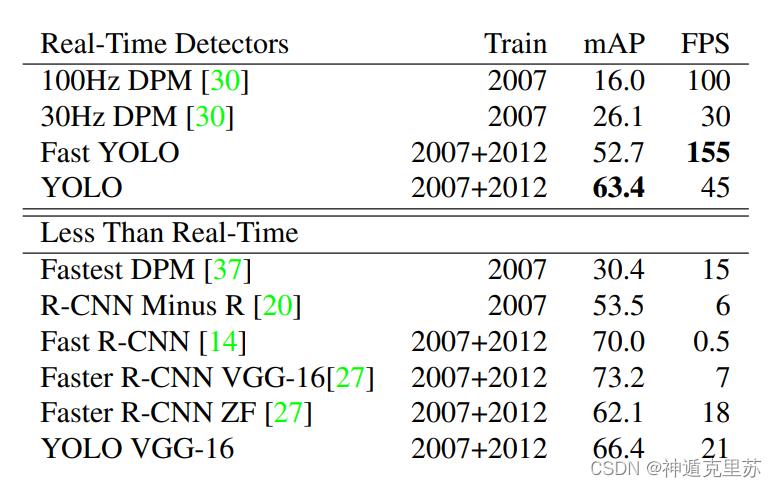
Real-Time Detectors表示能够进行实时检测
Less Than Real-Time表示未达到实时检测的速度
mAP(mean Average Precision)平均检索精度
衡量模型在所有类别上的好坏。mAP越高表示越精确。
FPS(每秒传输帧数-Frames Per Second)
FPS就是目标网络每秒可以处理(检测)多少帧(多少张图片),FPS简单来理解就是图像的刷新频率,也就是每秒多少帧,假设目标检测网络处理1帧要0.02s,此时FPS就是1/0.02=50。值越大表示速度越快。
因此图中可以看出YOLO以及Fast-YOLO的检测速度都达到了实时检测的水平,且mAP也处于偏高的水平。
以上是关于YOLO学习笔记的主要内容,如果未能解决你的问题,请参考以下文章