数据竞赛思路分享:机场客流量的时空分布预测
Posted ZJun310
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据竞赛思路分享:机场客流量的时空分布预测相关的知识,希望对你有一定的参考价值。


历时两个月的比赛终于结束了,最终以第32名的成绩告终,在此和大家分享下解决问题的思路。
从初赛到复赛,有走过弯路,也有突然灵光一现的时刻。一路走来,对数据各种把玩,分析了各种可能的情况,尽可能得挖掘数据中潜在的信息来构建更为准确的模型。
本文无法涵盖所有的分析历程,但是会涉及解决问题的主要思路以及部分代码,详细的代码见Github页面
竞赛详细信息参见比赛官方网站
1. 问题描述
机场拥有巨大的旅客吞吐量,与巨大的人员流动相对应的则是巨大的服务压力。安防、安检、突发事件应急、值机、行李追踪等机场服务都希望能够预测未来的旅客吞吐量,并据此提前调配人力物力,更好的为旅客服务。本次大赛以广州白云机场真实的客流数据为基础,每天数万离港旅客在机场留下百万级的数据记录。希望参赛队伍通过数据算法来构建客流量预测模型。
2. 数据概览
提供的数据:
| Table |
|---|
| 连接WIFI AP (Access Point)的人数表 airport_gz_wifi_ap |
| 安检旅客过关人数表 airport_gz_security_check |
| 旅客进入-离开机场的行程表 airport_gz_departure |
| 航班排班表airport_gz_flights [比赛一段时间后才提供] |
| 机场登机口区域表 airport_gz_gates [比赛一段时间后才提供] |
| 机场WIFI接入点坐标表 airport_gz_wifi_coor [复赛提供的] |
例如airport_gz_wifi_ap 表数据概览:
| wifi_ap_tag | passenger_count | time_stamp |
|---|---|---|
| E1-1A-1 | 15 | 2016-09-10-18-55-04 |
| E1-1A-2 | 15 | 2016-09-10-18-55-04 |
| E1-1A-3 | 38 | 2016-09-10-18-55-04 |
| E1-1A-4 | 19 | 2016-09-10-18-55-04 |
提交表格案例:
| passenger_count | wifi_ap_tag | slice10min |
|---|---|---|
| 1.1 | E1-1A-1 | 2016-09-14-15-0 |
| 2.2 | E1-1A-1 | 2016-09-14-15-1 |
| 3.3 | E1-1A-1 | 2016-09-14-15-2 |
| 4.4 | E1-1A-1 | 2016-09-14-15-3 |
| 5.5 | E1-1A-1 | 2016-09-14-15-4 |
3. 初赛
3.1初赛数据描述
初赛提供了2016-10-09至2016-09-25的数据
3.2初赛问题描述
选手需要预测未来三小时(9月25日15:00:00到18:00)的时间窗口里,机场内每个WIFI AP点每10分钟内的平均设备连接数量3.3初赛解决方案
简要概括:均值加趋势
数据预处理:
提供的表格中时间数据都是精确到秒,而所提交的结果要求是每10分钟的平均情况,所以我们首先需要将数据按照每十分钟的间隔汇总起来(详细代码见Github)
此处提供两种方案:
以airport_gz_wifi_ap表为例截取time_stamp的部分字符串,然后按照截取的time_stamp和wifi_ap_tag进行aggregate
t = t0[:15] # 例如将t0 = 2016-09-10-18-55-04截取为t = 2016-09-10-18-5将数据按照时间排序,然后抽出每十分钟的数据进行处理后整合,这个方式可能会比较麻烦,但是这个方式有他的优势,我们只需调整一个参数,便能让数据按照任意的时间间隔进行统计,便于以后复用函数
此处附加Python处理时间格式的一些函数
我们可以直接使用pandas中的参数解析时间数据
# Normal
df =pd.read_csv(path, parse_dates=['column name'])
# Special
dateparse = lambdax: pd.datetime.strptime(x, '%Y-%m-%d %H:%M:%S')
df =pd.read_csv(path, parse_dates=['column name'], date_parser=dateparse)当然也可以自己写函数处理
import pandas as pd
def ReturnTimeElement(Date):
return [int(t) for t in Date.split('-')]
def TransToTime(TimeElement):
return pd.datetime(*(TimeElement))
def GetTime(Date):
TimeElement = ReturnTimeElement(Date)
Time = TransToTime(TimeElement)
return Time
T = '2016-10-19-9-47-00'
>>> GetTime(T)
datetime.datetime(2016, 10, 19, 9, 47)处理后可以得到如下数据,命名为WIFITAPTag_Mean_All
| PassengerCountMean | Time | WIFIAPTag |
|---|---|---|
| 16.2 | 2016/9/10 19:00 | E1-1A-1 |
| 19.7 | 2016/9/10 19:10 | E1-1A-1 |
| 19.7 | 2016/9/10 19:20 | E1-1A-1 |
| 20.5 | 2016/9/10 19:30 | E1-1A-1 |
| 20.5 | 2016/9/10 19:40 | E1-1A-1 |
| 24.8 | 2016/9/10 19:50 | E1-1A-1 |
问题分析:
对于这个预测问题有以下关键两点:
- 机场每天的排班表基本稳定,用户在机场内的行走模式也基本稳定
- 时间序列具有一定程度的连续性,下午三点至六点的情况会一定程度延续此前几小时的情况
基于以上两点想法,就得到了两个基本模型:均值模型和时间序列模型
比赛初期只提供了前三个表格,所以开始就注重分析了这几个表格,例如从WIFIAPTag中可以提取出大概的位置信息和楼层信息,分组统计不同区域的WIFIAP是否有接近的模式,同时也可从安检和出发表格中寻找一定的关联等等。
但是经过分析发现,airport_gz_security_check及airport_gz_departure的数据虽然和airport_gz_wifi_ap的数据有一定的关联,但是其本身存在较大的随机因素,用随机预测随机存在太大的变数,不如只使用airport_gz_wifi_ap中的数据进行更稳定的预测(当然肯定也有队伍能很好得从airport_gz_security_check及airport_gz_departure中提出很很棒的特征)。后期提供的几个表格由于数据质量问题,经分析后发现贡献不是特别大,故也没有进一步利用。
因而之后要说的均值模型和时间序列模型都基于WIFITAPTag_Mean_All表格的数据,并且是以WIFIAP为对象, 每一个分开预测。
数据探索:
接下来让我们对数据有一个大概的了解
def GetTimeSeries(WIFIAPTag):
'''
Get WIFIAPTag 's Time Series
'''
Tag_Data = WIFITAPTag_Mean_All[WIFITAPTag_Mean_All.WIFIAPTag == WIFIAPTag]
MinTime = min(Tag_Data.Time)
MaxTime = max(Tag_Data.Time)
DataTimeRange = pd.date_range(start = MinTime , end = MaxTime , freq = '10Min')
ts_0 = pd.Series([0]*len(DataTimeRange),index=DataTimeRange)
ts =pd.Series(Tag_Data.PassengerCountMean.values , index = Tag_Data.Time)
TS = ts_0+ts
TS = TS.fillna(0)
return TS以上函数能提取出特定WIFIAP的时间序列数据,及每10分钟的平均连接数
ts = GetTimeSeries('E1-1A-1<E1-1-01>')
ts
Out[7]:
2016-09-10 19:00:00 16.2
2016-09-10 19:10:00 19.7
2016-09-10 19:20:00 19.7
...
2016-09-25 14:30:00 11.1
2016-09-25 14:40:00 8.0
2016-09-25 14:50:00 10.9
dtype: float64绘图结果如下,可以看出每天还是有一定的规律,但是有异常的日子
| ts.plot() |
|---|
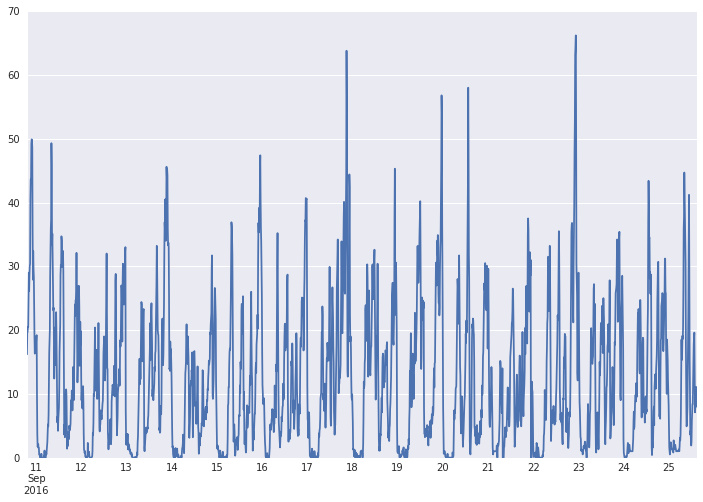 |
由于我们需要预测的是特定某几个小时的数据,所以需要如下函数提取部分的时间序列
def Get_Part_of_TimeSeries(TS,TimeRange):
'''
Input [start_time,end_time]
'''
return TS[TimeRange[0]:TimeRange[1]]均值模型需要考虑之前每一天同一时间段的情况,所以有如下函数
def GenerateTs_0(Time):
timerange = pd.date_range(start = Time[0],end = Time[1] ,freq = '10Min')
ts = pd.Series(np.zeros(len(timerange)),index = timerange)
return ts
def TsList(WIFIAPTag,Time):
ts_list=[]
ts = GetTimeSeries(WIFIAPTag)
for i in range(1,15):
TimeRange = Time - timedelta(i)
ts_part = Get_Part_of_TimeSeries(ts,TimeRange)
if len(ts_part) == 0 or ts_part.isnull().any():
ts_list.append(GenerateTs_0(TimeRange))
else:
ts_list.append(ts_part)
return np.array(ts_list)使用以上函数便可以得到如下结果,其中array的每一行是之前每天下午三点到下午6点的数据
Time = np.array([pd.datetime(2016,9,25,15,0,0),pd.datetime(2016,9,25,17,50,0)])
Time
Out[11]:
array([datetime.datetime(2016, 9, 25, 15, 0),
datetime.datetime(2016, 9, 25, 17, 50)], dtype=object)
ts_list = TsList('E1-1A-1<E1-1-01>',Time)
ts_list
Out[25]:
array([[ 1.5, 0.4, 1.8, ..., 15. , 15.9, 18.4],
[ 11. , 11.3, 13.4, ..., 6.3, 7.2, 9.4],
[ 7. , 5.5, 4.9, ..., 4.9, 4. , 6.4],
...,
[ 13.6, 16.4, 16.7, ..., 4.7, 3.9, 4.1],
[ 3.8, 4.2, 6. , ..., 10.2, 9.6, 19.4],
[ 5.2, 3.2, 4.2, ..., 5. , 4.5, 4.3]])但是之前这么多天必然有比较异常的日子,所以需要写如下函数将异常的日子过滤掉,此处的过滤策略是:
对每天特定时间段的数据求均值与标准差,然后将均值与标准差落在10%分位数以下和90%分位数以上的日子去除
def TrueFalseListCombine(TFlist1,TFlist2):
return [l1 and l2 for l1,l2 in zip(TFlist1,TFlist2)]
def ExceptOutlier(ts_list):
Mean = pd.DataFrame([np.mean(i) for i in ts_list])
mean_low = Mean > Mean.quantile(0.1)
mean_up = Mean < Mean.quantile(0.9)
TF = TrueFalseListCombine(mean_low.values,mean_up.values)
mean_index = Mean[TF].index.values
Std = pd.DataFrame([np.std(i) for i in ts_list])
std_low = Std > Std.quantile(0.1)
std_up = Std < Std.quantile(0.9)
TF = TrueFalseListCombine(std_low.values,std_up.values)
std_index = Std[TF].index.values
valid_index = list(set(mean_index)&set(std_index))
return valid_index 例如对刚生成的ts_list处理得到
ExceptOutlier(ts_list)
Out[26]: [0, 1, 2, 3, 4, 6, 8, 9, 10, 12]为了更直观我们使用如下函数绘图
def DrawTsList(ts_list):
plt.plot(ts_list.T)| DrawTsList(ts_list) | DrawTsList(ts_list[ExceptOutlier(ts_list)]) |
|---|---|
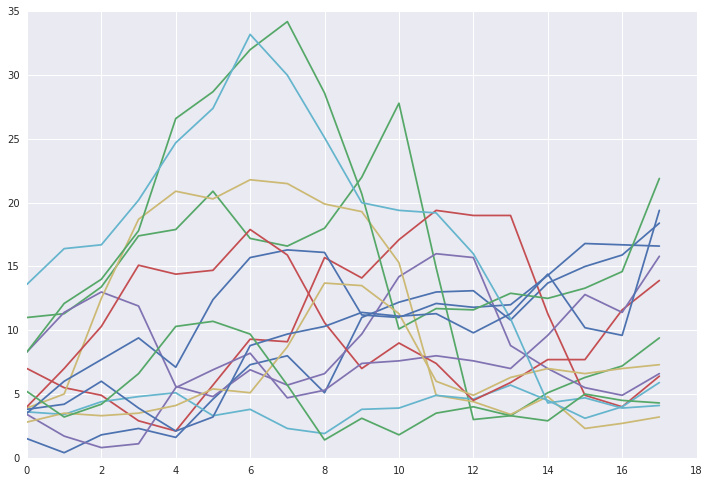 | 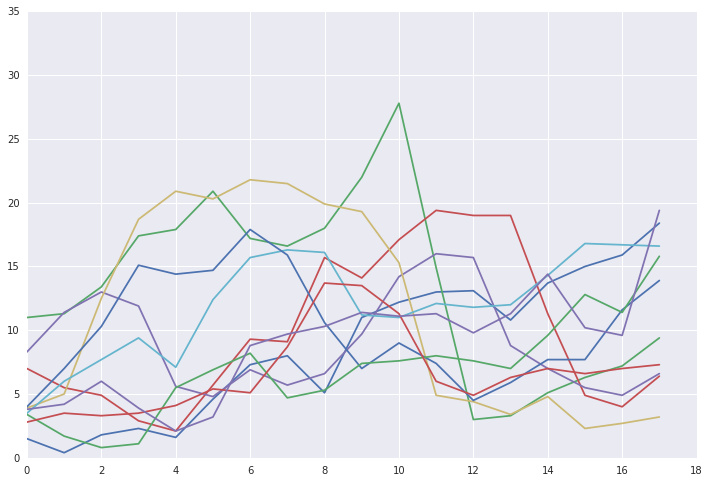 |
上图左侧为所有日子的时间序列,右图为去除异常日子之后的时间序列,可以看出已经将特别异常的几天去除了
均值模型:
每天的量值都存在一定的差异,直接将所有去除异常之后的日子取均值并不是特别好的策略,在此我们认为,机场下午3点至6点的人流总量应当与当天这个时刻之前的人流量存在一定的关系,所以我们取了上午6点到下午3点这一时间段的数据作为人流量值的参考。我们是有预测当天上午6点到下午3点的数据的,故可以依据此和之前去除异常后的多天该时间段的数据计算之前各天下午3点到下午6点数据的贡献度。
基于以上思想,并做了一点小修改写了如下两个模型,两个模型比较接近,但是在某些WIFIAP上其中一个会表现好很多,这使得我们之后利用误差分析挑选模型时多一个候选模型。
def Ratio(L):
return np.array(L*1.0/sum(L))
def Imitate1(WIFIAPTag,TrainTime,PredictTime):
TrainTimeTsList = TsList(WIFIAPTag,TrainTime)
PredictTimeTsList = TsList(WIFIAPTag,PredictTime)
IndexWithoutOutlier = ExceptOutlier(PredictTimeTsList)
ValidTrainTimeTsList = TrainTimeTsList[IndexWithoutOutlier]
ValidPredictTimeTsList = PredictTimeTsList[IndexWithoutOutlier]
PredictDayTrainTs = Get_Part_of_TimeSeries(GetTimeSeries(WIFIAPTag),TrainTime)
if len(PredictDayTrainTs) == 0:
PredictTs = ValidPredictTimeTsList.mean(axis=0)
else:
MeanPredictDayTrainTs = PredictDayTrainTs.mean()
MeanValidTrainTimeTsList = ValidTrainTimeTsList.mean(axis=1)
RatioList = Ratio(MeanPredictDayTrainTs/MeanValidTrainTimeTsList)
PredictTs = np.dot(ValidPredictTimeTsList.T,RatioList)
PredictTimeRange = pd.date_range(start = PredictTime[0],end = PredictTime[1] ,freq = '10Min')
TS_Predict = pd.Series(PredictTs,index = PredictTimeRange)
return TS_Predict
def Imitate2(WIFIAPTag,TrainTime,PredictTime):
TrainTimeTsList = TsList(WIFIAPTag,TrainTime)
PredictTimeTsList = TsList(WIFIAPTag,PredictTime)
IndexWithoutOutlier = ExceptOutlier(PredictTimeTsList)
ValidTrainTimeTsList = TrainTimeTsList[IndexWithoutOutlier]
ValidPredictTimeTsList = PredictTimeTsList[IndexWithoutOutlier]
PredictDayTrainTs = Get_Part_of_TimeSeries(GetTimeSeries(WIFIAPTag),TrainTime)
if len(PredictDayTrainTs) == 0:
PredictTs = ValidPredictTimeTsList.mean(axis=0)
else:
MeanPredictDayTrainTs = PredictDayTrainTs.mean()
MeanValidTrainTimeTsList = ValidTrainTimeTsList.mean(axis=1)
RatioList = MeanPredictDayTrainTs/MeanValidTrainTimeTsList
PredictTs = np.dot(ValidPredictTimeTsList.T,RatioList) / len(RatioList)
PredictTimeRange = pd.date_range(start = PredictTime[0],end = PredictTime[1] ,freq = '10Min')
TS_Predict = pd.Series(PredictTs,index = PredictTimeRange)
return TS_Predict
时间序列模型:
如果只用上文提及的均值模型,很可能在3点那个时刻出现断点的情况,比如前一时刻是15人,后10分钟突然变成2人,考虑到人们在机场移动具有连续性的特征,我们使用ARMA来对预测进行一定的修正,正所谓稳中求变,模型如下
def Do_ARMA(WIFIAPTag,TrainTime,PredictTime,p,q,Draw = False):
Tag_Time_Series = GetTimeSeries(WIFIAPTag)
ARMA_Time = [PredictTime[0]-timedelta(2),PredictTime[0] - timedelta(0,0,0,0,10,0)]
#ARMA_Time = [pd.datetime(2016,9,11,6,0,0),pd.datetime(2016,9,14,15,0,0)]
Tag_Time_Series = Get_Part_of_TimeSeries(Tag_Time_Series,ARMA_Time)
# ARMA model
from statsmodels.tsa.arima_model import ARMA
arma_mod = ARMA(Tag_Time_Series,(p,q)).fit()
Predict = arma_mod.predict(start=str(PredictTime[0]),end=str(PredictTime[1]))
if Draw == True:
plt.rc('figure', figsize=(12, 8))
plt.plot(arma_mod.fittedvalues,'r')
plt.plot(Tag_Time_Series)
plt.plot(Predict,'g-')
return Predict试运行如下
| Do_ARMA(‘E1-1A-1’,TrainTime,PredictTime,4,2,Draw=True) |
|---|
 |
模型整合:
现在我们有了三个基本模型,单单使用一个模型去预测所有的WIFIAP效果必然不好,每个WIFIAP都有自己最适合的模型,所以我们通过对前一周每天下午3点到6点的数据进行预测,计算每个WIFIAP在每个模型上的平均误差,让每个WIFIAP挑选误差最小的那个模型进行预测。数据有缺失的情况,所有模型中包含了蛮多的异常处理部分。
代码如下
def ErrorAnalysis(i,day):
Est_TrainTime = np.array([pd.datetime(2016,9,day,6,0,0),pd.datetime(2016,9,day,14,50,0)])
Est_PredictTime = np.array([pd.datetime(2016,9,day,15,0,0),pd.datetime(2016,9,day,17,50,0)])
y = Get_Part_of_TimeSeries(GetTimeSeries(WIFIAPTag_List[i]),Est_PredictTime)
prey0 =Imitate1(WIFIAPTag_List[i],Est_TrainTime,Est_PredictTime)
prey1 =Imitate2(WIFIAPTag_List[i],Est_TrainTime,Est_PredictTime)
def error(a,b):
return sum([n*n for n in (a-b)])
imitate1_error = error(prey0,y)
imitate2_error = error(prey1,y) # sometimes y is empty [expection]
if np.isnan(imitate1_error):
imitate1_error = 1
if np.isnan(imitate2_error):
imitate2_error = 1
try:
prey2=Do_ARMA(WIFIAPTag_List[i],Est_TrainTime,Est_PredictTime,4,2)
arma_error = error(prey2,y)
except:
arma_error = 10000000
if np.isnan(arma_error):
arma_error = 10000000
Error_list = [imitate1_error,imitate2_error,arma_error]
return Error_list
def GetRatio():
import time
Error_Analysis = []
for i in range(len(WIFIAPTag_List)):
t1 = time.time()
Error = np.array([0,0,0])
for j in range(1,8):
try:
e = ErrorAnalysis(i,25-j)
Error = np.c_[Error,e]
except:
print 'Error Com'
ratio = Ratio(1.0/Error.mean(axis=1))
Error_Analysis.append(ratio)
t2 = time.time()
print '===== Got '+str(i)+'th Ratio base on error analysis=====Cost '+str(t2-t1)+' Seconds==='
def Save_Obj(Obj,File_Name):
import pickle
File = File_Name + '.pkl'
output = open(File, 'wb')
pickle.dump(Obj, output)
output.close()
Ratio_Dict = dict(zip(WIFIAPTag_List,Error_Analysis))
Save_Obj(Ratio_Dict,'Ratio_Dict')
return Ratio_Dict
def Combine(WIFIAPTag,TrainTime,PredictTime,Ratio_Dict):
num = list(Ratio_Dict[WIFIAPTag]).index(Ratio_Dict[WIFIAPTag].max())
if num ==0:
Predict = Imitate1(WIFIAPTag,TrainTime,PredictTime)
if num ==1:
Predict = Imitate2(WIFIAPTag,TrainTime,PredictTime)
if num ==2:
try:
Predict = Do_ARMA(WIFIAPTag,TrainTime,PredictTime,4,2)
if np.isnan(Predict.values).any():
print 'Nan in ARMA'
Predict = Imitate2(WIFIAPTag,TrainTime,PredictTime)
except:
print 'ARMA Failed'
Predict = Imitate2(WIFIAPTag,TrainTime,PredictTime)
return Predict为了看下混合模型的效果,可以使用如下代码
def Compare(i,day,Ratio_Dict):
Est_TrainTime = np.array([pd.datetime(2016,9,day,6,0,0),pd.datetime(2016,9,day,14,50,0)])
Est_PredictTime = np.array([pd.datetime(2016,9,day,15,0,0),pd.datetime(2016,9,day,17,50,0)])
y = Get_Part_of_TimeSeries(GetTimeSeries(WIFIAPTag_List[i]),Est_PredictTime)
prey0 =Imitate1(WIFIAPTag_List[i],Est_TrainTime,Est_PredictTime)
prey1 =Imitate2(WIFIAPTag_List[i],Est_TrainTime,Est_PredictTime)
prey2=Do_ARMA(WIFIAPTag_List[i],Est_TrainTime,Est_PredictTime,4,2)
prey3 = Combine(WIFIAPTag_List[i],Est_TrainTime,Est_PredictTime,Ratio_Dict)
y.plot()
prey0.plot()
prey1.plot()
prey2.plot()
prey3.plot()
plt.legend(['real','imitate1','imitate2','arma','combine'])
title = '2016-9-'+str(day)
plt.title(title)| Imitate1 占优势例子 | Imitate2 占优势例子 | Do_ARMA 占优势例子 |
|---|---|---|
 | 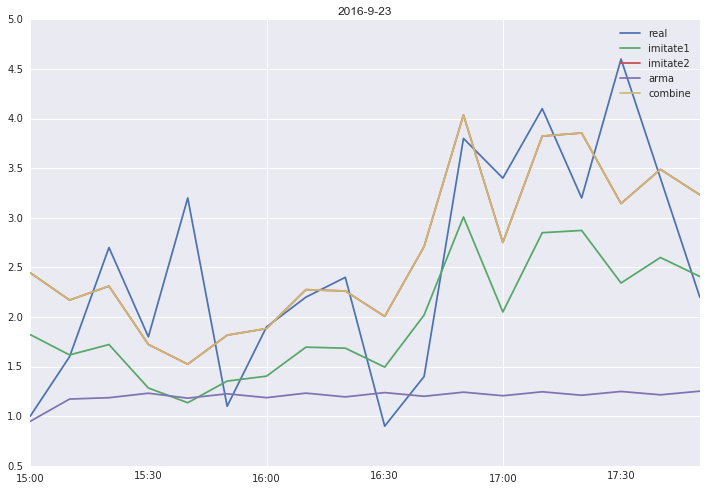 | 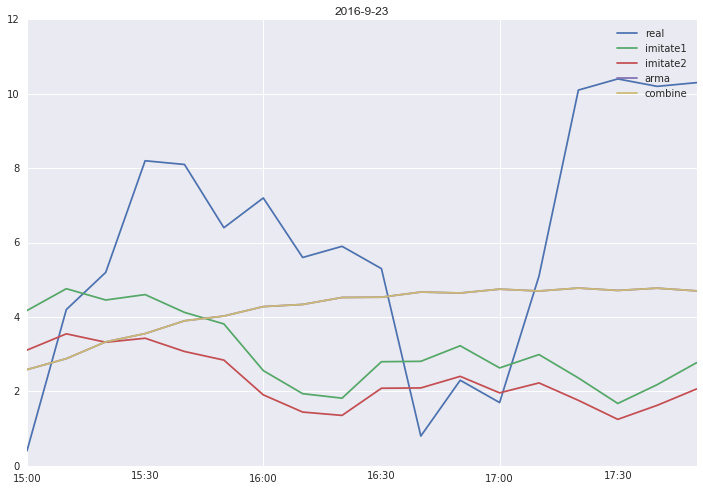 |
基于以上组件,便可以进行开心地预测了,结果保存为airport_gz_passenger_predict.csv
def Predict(TrainTime,PredictTime,Ratio_Dict):
count=0
tag = WIFIAPTag_List[0]
Predict = Combine(tag,TrainTime,PredictTime,Ratio_Dict)
def TransTime(time):
date = str(time.date())
hour = time.hour
minute = time.minute
output = date + '-' + str(hour) + '-' + str(minute / 10)
return output
slice10min = [TransTime(time) for time in Predict.index]
passengerCount = Predict.values
WIFIAPTag = [tag]*len(Predict)
Predict_Result = pd.DataFrame('passengerCount':passengerCount,'WIFIAPTag':WIFIAPTag,'slice10min':slice10min)
Predict_Result = Predict_Result[['passengerCount','WIFIAPTag','slice10min']]
for tag in WIFIAPTag_List[1:]:
Predict = Combine(tag,TrainTime,PredictTime,Ratio_Dict)
slice10min = [TransTime(time) for time in Predict.index]
passengerCount = Predict.values
WIFIAPTag = [tag]*len(Predict)
Predict_Result_Part = pd.DataFrame('passengerCount':passengerCount,'WIFIAPTag':WIFIAPTag,'slice10min':slice10min)
Predict_Result_Part = Predict_Result_Part[['passengerCount','WIFIAPTag','slice10min']]
Predict_Result = pd.concat([Predict_Result,Predict_Result_Part])
count += 1
print count
Path_Result = './Data/airport_gz_passenger_predict.csv'
Predict_Result['passengerCount'] = np.nan_to_num(Predict_Result.passengerCount)
Save_DataFrame_csv(Predict_Result,Path_Result)
return Predict_Result 4. 复赛
4.1 复赛数据描述
复赛提供了2016-10-09至2016-11-10的数据
4.2复赛问题描述
选手需要预测未来两整天(11月11日0点到12日23:59:59)的时间窗口里,机场内每个WIFI AP点每10分钟内的平均设备连接数量4.2复赛解决方案
简要概括:多层筛选加均值
基本思路:
复赛是对未来的两个整天进行预测,基本思路与初赛相似,但是做了如下修改
- ARMA模型不再作为一天之内连续性的调整策略,而是用于预测未来两天整体量值的趋势
- 修改了数据的筛选机制
由于复赛是在天池数加平台进行,第一次接触对于平台并不是太熟悉,所以选择在其机器学习平台使用SQL节点编写语句实现模型
解决方案:
首先在数据开发平台读取数据表
drop table if exists airport_gz_flights;
create table if not exists airport_gz_flights as
select * from odps_tc_257100_f673506e024.airport_gz_flights;然后在机器学习平台进行数据处理和模型搭建
读入初始数据预览如下
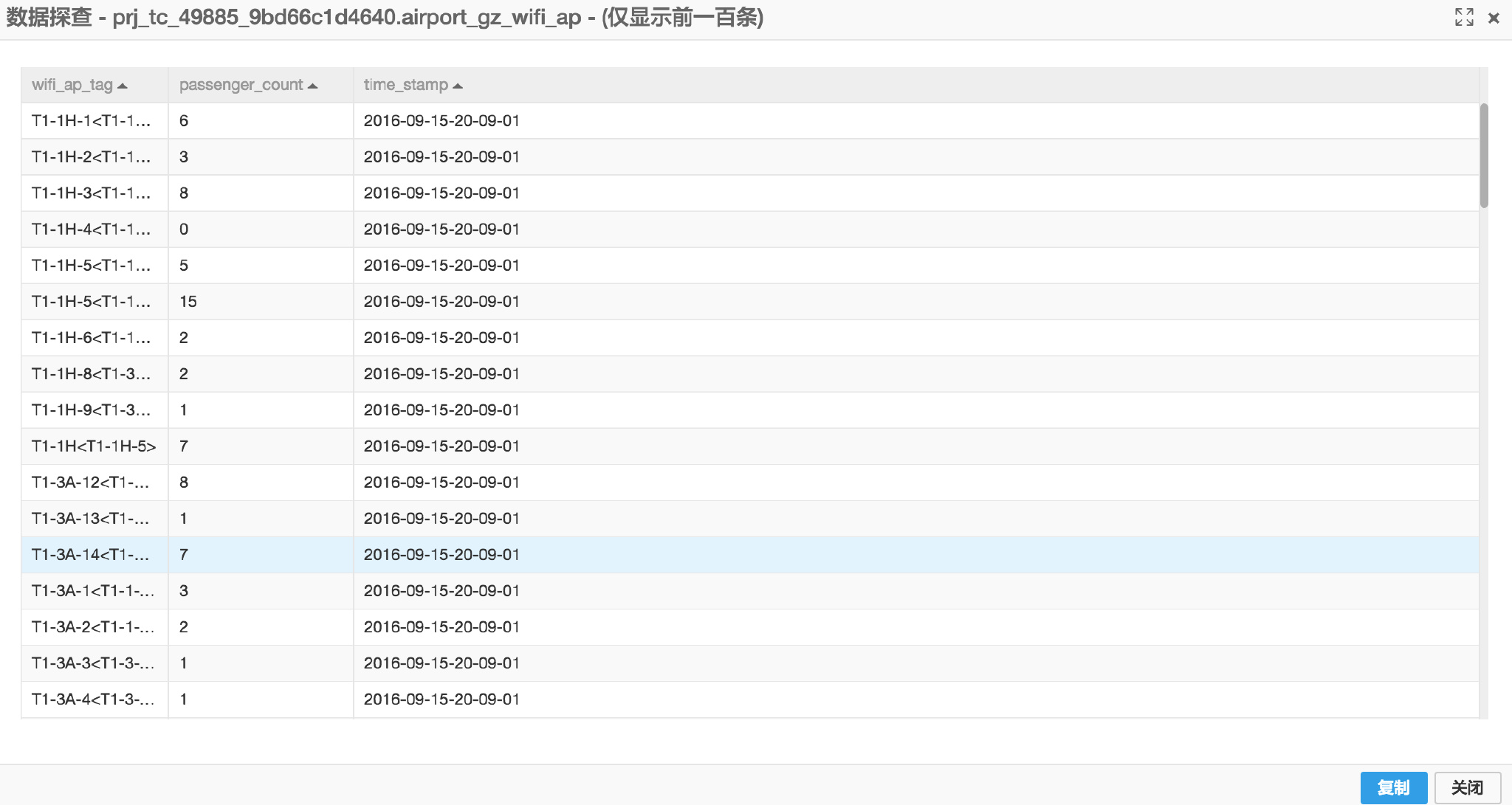
使用以下节点预处理数据(每个节点是一条SQL语句,将处理结果传入下一节点)
使用了如下等语句(这些语句应该可以再精简些,但是当初写好了就没再去修改了)
--tag_time(slice10min)_combine
select passenger_count , concat(wifi_ap_tag,'|',substr(time_stamp,1,15)) as tag_time
from airport_gz_wifi_ap;
--agg_tag_time
select avg(passenger_count) as mean_passenger_count , tag_time from $t1
group by tag_time;
--split_tag_time
select mean_passenger_count , split_part(tag_time, '|', 1) as tag , split_part(tag_time, '|', 2) as time_split from $t1;
--split_date_time
select mean_passenger_count , tag , time_split , substr(time_split,1,10) as d , substr(time_split,12,15) as t from $t1;
-- Add_Date_Column
select mean_passenger_count , tag ,d, to_date(d,'yyyy-mm-dd') as date_stamp ,t,time_split,c as day_avg from $t1;
--get_date
select substr(time_stamp,1,10) as t , passenger_count from $t1;
--date_mean
select avg(passenger_count) as c , t from $t1 group by t;得到如下结果

其中一个模型大概结构如下
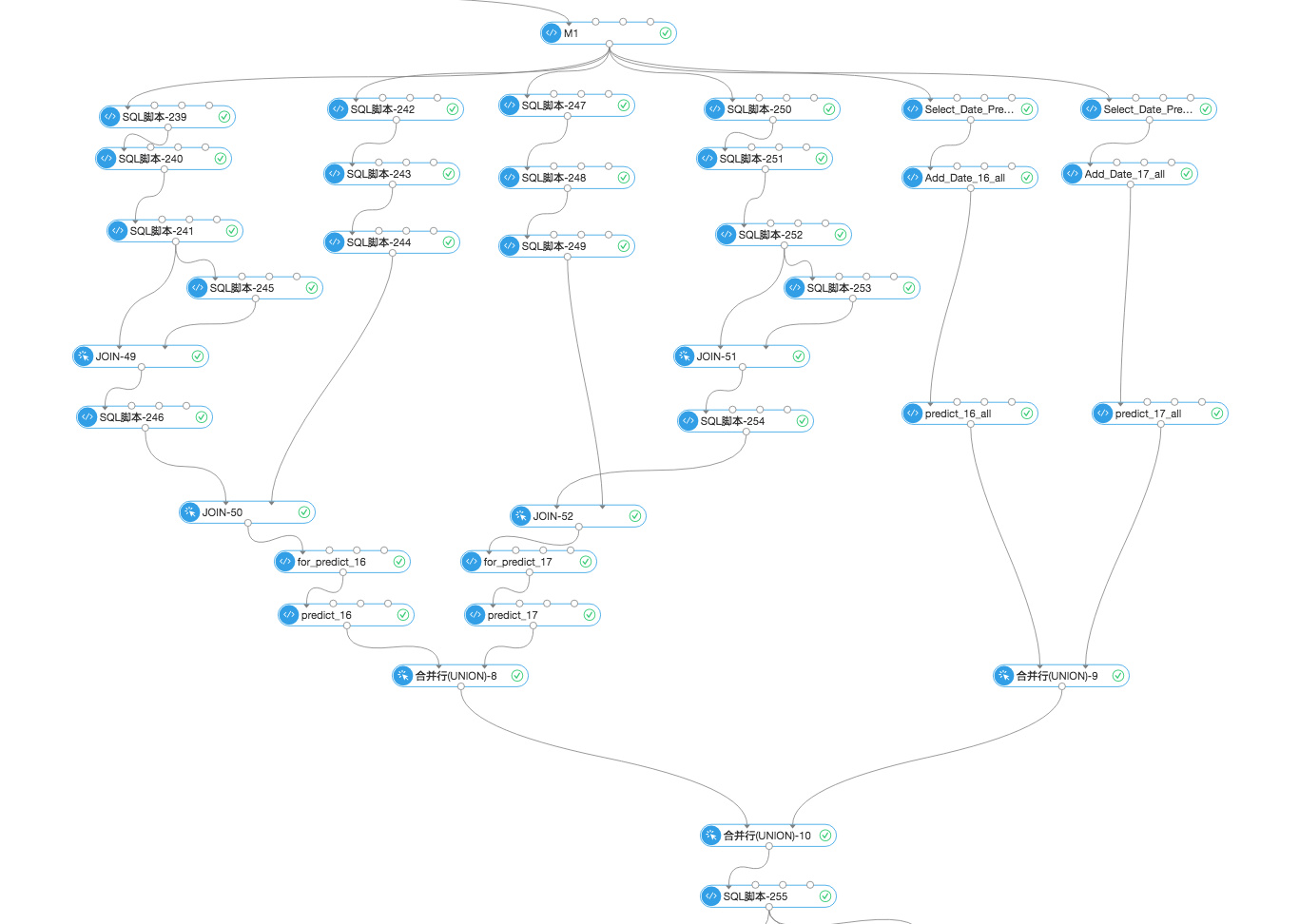
节点确实有点多具体细节就不在此展开,此处简要提一下复赛中的筛选策略:
首先计算所有日子全部节点每天的平均连接量,从而得到一个时间序列。如下图所示
利用这个时间序列依据ARMA模型估计出之后两天的量值,依据这量值建立一个区间,筛选出均值落在这个区间内的所有日子,然后对这些天的数据按照初赛的思路再进一步做异常筛选,此外还要进一步加大最近几日的数据权重,依据这些想法建立模型。最后在某些步骤上做些小修改,共建立三个候选模型,依据初赛的思路进行误差分析整合模型进行预测。
误差分析的的结果大概如下,基于误差值可以挑选使用哪个模型

5. 总结
比赛初期其实提取了很多特征,然后使用一些机器学习算法去预测,但是效果却强差人意,随后结合实际问题思考,发现其实不一定要使用各种特征,而且很多随机因素对各个特征的影响真的蛮大的。仅使用一些简单的想法也能达到比较好的效果。
所以这次比赛后,想说的就是模型真的不是越复杂越好,也不一定要用各种现成的模型,结合实际问题背景去分析可能会比一直纠结各种特征以及模型参数获得更大的收益。
以上是关于数据竞赛思路分享:机场客流量的时空分布预测的主要内容,如果未能解决你的问题,请参考以下文章