动手学CV-目标检测入门教程6:训练与测试
Posted 随煜而安
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了动手学CV-目标检测入门教程6:训练与测试相关的知识,希望对你有一定的参考价值。
3.6、训练与测试
本文来自开源组织 DataWhale 🐳 CV小组创作的目标检测入门教程。
对应开源项目 《动手学CV-Pytorch》 的第3章的内容,教程中涉及的代码也可以在项目中找到,后续会持续更新更多的优质内容,欢迎⭐️。
如果使用我们教程的内容或图片,请在文章醒目位置注明我们的github主页链接:https://github.com/datawhalechina/dive-into-cv-pytorch
3.6.1 模型训练
前面的章节,我们已经对目标检测训练的各个重要的知识点进行了讲解,下面我们需要将整个流程串起来,对模型进行训练。
目标检测网络的训练大致是如下的流程:
- 设置各种超参数
- 定义数据加载模块 dataloader
- 定义网络 model
- 定义损失函数 loss
- 定义优化器 optimizer
- 遍历训练数据,预测-计算loss-反向传播
首先,我们导入必要的库,然后设定各种超参数
import time
import torch.backends.cudnn as cudnn
import torch.optim
import torch.utils.data
from model import tiny_detector, MultiBoxLoss
from datasets import PascalVOCDataset
from utils import *
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
cudnn.benchmark = True
# Data parameters
data_folder = '../../../dataset/VOCdevkit' # data files root path
keep_difficult = True # use objects considered difficult to detect?
n_classes = len(label_map) # number of different types of objects
# Learning parameters
total_epochs = 230 # number of epochs to train
batch_size = 32 # batch size
workers = 4 # number of workers for loading data in the DataLoader
print_freq = 100 # print training status every __ batches
lr = 1e-3 # learning rate
decay_lr_at = [150, 190] # decay learning rate after these many epochs
decay_lr_to = 0.1 # decay learning rate to this fraction of the existing learning rate
momentum = 0.9 # momentum
weight_decay = 5e-4 # weight decay
按照上面梳理的流程,编写训练代码如下:
def main():
"""
Training.
"""
# Initialize model and optimizer
model = tiny_detector(n_classes=n_classes)
criterion = MultiBoxLoss(priors_cxcy=model.priors_cxcy)
optimizer = torch.optim.SGD(params=model.parameters(),
lr=lr,
momentum=momentum,
weight_decay=weight_decay)
# Move to default device
model = model.to(device)
criterion = criterion.to(device)
# Custom dataloaders
train_dataset = PascalVOCDataset(data_folder,
split='train',
keep_difficult=keep_difficult)
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
collate_fn=train_dataset.collate_fn,
num_workers=workers,
pin_memory=True)
# Epochs
for epoch in range(total_epochs):
# Decay learning rate at particular epochs
if epoch in decay_lr_at:
adjust_learning_rate(optimizer, decay_lr_to)
# One epoch's training
train(train_loader=train_loader,
model=model,
criterion=criterion,
optimizer=optimizer,
epoch=epoch)
# Save checkpoint
save_checkpoint(epoch, model, optimizer)
其中,我们对单个epoch的训练逻辑进行了封装,其具体实现如下:
def train(train_loader, model, criterion, optimizer, epoch):
"""
One epoch's training.
:param train_loader: DataLoader for training data
:param model: model
:param criterion: MultiBox loss
:param optimizer: optimizer
:param epoch: epoch number
"""
model.train() # training mode enables dropout
batch_time = AverageMeter() # forward prop. + back prop. time
data_time = AverageMeter() # data loading time
losses = AverageMeter() # loss
start = time.time()
# Batches
for i, (images, boxes, labels, _) in enumerate(train_loader):
data_time.update(time.time() - start)
# Move to default device
images = images.to(device) # (batch_size (N), 3, 224, 224)
boxes = [b.to(device) for b in boxes]
labels = [l.to(device) for l in labels]
# Forward prop.
predicted_locs, predicted_scores = model(images) # (N, 441, 4), (N, 441, n_classes)
# Loss
loss = criterion(predicted_locs, predicted_scores, boxes, labels) # scalar
# Backward prop.
optimizer.zero_grad()
loss.backward()
# Update model
optimizer.step()
losses.update(loss.item(), images.size(0))
batch_time.update(time.time() - start)
start = time.time()
# Print status
if i % print_freq == 0:
print('Epoch: [0][1/2]\\t'
'Batch Time batch_time.val:.3f (batch_time.avg:.3f)\\t'
'Data Time data_time.val:.3f (data_time.avg:.3f)\\t'
'Loss loss.val:.4f (loss.avg:.4f)\\t'.format(epoch,
i,
len(train_loader),
batch_time=batch_time,
data_time=data_time,
loss=losses))
del predicted_locs, predicted_scores, images, boxes, labels # free some memory since their histories may be stored
完成了代码的编写后,我们就可以开始训练模型了,训练过程类似下图所示:
$ python train.py
Loaded base model.
Epoch: [0][0/518] Batch Time 6.556 (6.556) Data Time 3.879 (3.879) Loss 27.7129 (27.7129)
Epoch: [0][100/518] Batch Time 0.185 (0.516) Data Time 0.000 (0.306) Loss 6.1569 (8.4569)
Epoch: [0][200/518] Batch Time 1.251 (0.487) Data Time 1.065 (0.289) Loss 6.3175 (7.3364)
Epoch: [0][300/518] Batch Time 1.207 (0.476) Data Time 1.019 (0.282) Loss 5.6598 (6.9211)
Epoch: [0][400/518] Batch Time 1.174 (0.470) Data Time 0.988 (0.278) Loss 6.2519 (6.6751)
Epoch: [0][500/518] Batch Time 1.303 (0.468) Data Time 1.117 (0.276) Loss 5.4864 (6.4894)
Epoch: [1][0/518] Batch Time 1.061 (1.061) Data Time 0.871 (0.871) Loss 5.7480 (5.7480)
Epoch: [1][100/518] Batch Time 0.189 (0.227) Data Time 0.000 (0.037) Loss 5.8557 (5.6431)
Epoch: [1][200/518] Batch Time 0.188 (0.225) Data Time 0.000 (0.036) Loss 5.2024 (5.5586)
Epoch: [1][300/518] Batch Time 0.190 (0.225) Data Time 0.000 (0.036) Loss 5.5348 (5.4957)
Epoch: [1][400/518] Batch Time 0.188 (0.226) Data Time 0.000 (0.036) Loss 5.2623 (5.4442)
Epoch: [1][500/518] Batch Time 0.190 (0.225) Data Time 0.000 (0.035) Loss 5.3105 (5.3835)
Epoch: [2][0/518] Batch Time 1.156 (1.156) Data Time 0.967 (0.967) Loss 5.3755 (5.3755)
Epoch: [2][100/518] Batch Time 0.206 (0.232) Data Time 0.016 (0.042) Loss 5.6532 (5.1418)
Epoch: [2][200/518] Batch Time 0.197 (0.226) Data Time 0.007 (0.036) Loss 4.6704 (5.0717)
剩下的就是等待了~
3.6.2 后处理
3.6.2.1 目标框信息解码
之前我们的提到过,模型不是直接预测的目标框信息,而是预测的基于anchor的偏移,且经过了编码。因此后处理的第一步,就是对模型的回归头的输出进行解码,拿到真正意义上的目标框的预测结果。
后处理还需要做什么呢?由于我们预设了大量的先验框,因此预测时在目标周围会形成大量高度重合的检测框,而我们目标检测的结果只希望保留一个足够准确的预测框,所以就需要使用某些算法对检测框去重。这个去重算法叫做NMS,下面我们详细来讲一讲。
3.6.2.2 NMS非极大值抑制
NMS的大致算法步骤如下:
-
按照类别分组,依次遍历每个类别。
-
当前类别按分类置信度排序,并且设置一个最低置信度阈值如0.05,低于这个阈值的目标框直接舍弃。
-
当前概率最高的框作为候选框,其它所有与候选框的IOU高于一个阈值(自己设定,如0.5)的框认为需要被抑制,从剩余框数组中删除。
-
然后在剩余的框里寻找概率第二大的框,其它所有与第二大的框的IOU高于设定阈值的框被抑制。
-
依次类推重复这个过程,直至遍历完所有剩余框,所有没被抑制的框即为最终检测框。
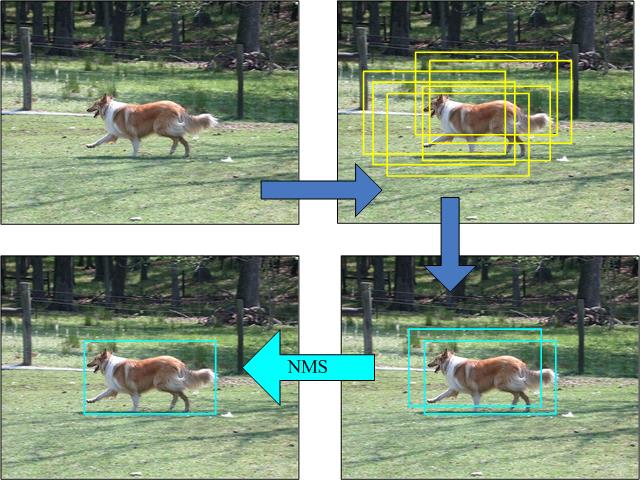
3.6.2.3 代码实现:
整个后处理过程的代码实现位于model.py中tiny_detector类的detect_objects函数中
def detect_objects(self, predicted_locs, predicted_scores, min_score, max_overlap, top_k):
"""
Decipher the 441 locations and class scores (output of the tiny_detector) to detect objects.
For each class, perform Non-Maximum Suppression (NMS) on boxes that are above a minimum threshold.
:param predicted_locs: predicted locations/boxes w.r.t the 441 prior boxes, a tensor of dimensions (N, 441, 4)
:param predicted_scores: class scores for each of the encoded locations/boxes, a tensor of dimensions (N, 441, n_classes)
:param min_score: minimum threshold for a box to be considered a match for a certain class
:param max_overlap: maximum overlap two boxes can have so that the one with the lower score is not suppressed via NMS
:param top_k: if there are a lot of resulting detection across all classes, keep only the top 'k'
:return: detections (boxes, labels, and scores), lists of length batch_size
"""
batch_size = predicted_locs.size(0)
n_priors = self.priors_cxcy.size(0)
predicted_scores = F.softmax(predicted_scores, dim=2) # (N, 441, n_classes)
# Lists to store final predicted boxes, labels, and scores for all images in batch
all_images_boxes = list()
all_images_labels = list()
all_images_scores = list()
assert n_priors == predicted_locs.size(1) == predicted_scores.size(1)
for i in range(batch_size):
# Decode object coordinates from the form we regressed predicted boxes to
decoded_locs = cxcy_to_xy(
gcxgcy_to_cxcy(predicted_locs[i], self.priors_cxcy)) # (441, 4), these are fractional pt. coordinates
# Lists to store boxes and scores for this image
image_boxes = list()
image_labels = list()
image_scores = list()
max_scores, best_label = predicted_scores[i].max(dim=1) # (441)
# Check for each class
for c in range(1, self.n_classes):
# Keep only predicted boxes and scores where scores for this class are above the minimum score
class_scores = predicted_scores[i][:, c] # (441)
score_above_min_score = class_scores > min_score # torch.uint8 (byte) tensor, for indexing
n_above_min_score = score_above_min_score.sum().item()
if n_above_min_score == 0:
continue
class_scores = class_scores[score_above_min_score] # (n_qualified), n_min_score <= 441
class_decoded_locs = decoded_locs[score_above_min_score] # (n_qualified, 4)
# Sort predicted boxes and scores by scores
class_scores, sort_ind = class_scores.sort(dim=0, descending=True) # (n_qualified), (n_min_score)
class_decoded_locs = class_decoded_locs[sort_ind] # (n_min_score, 4)
# Find the overlap between predicted boxes
overlap = find_jaccard_overlap(class_decoded_locs, class_decoded_locs) # (n_qualified, n_min_score)
# Non-Maximum Suppression (NMS)
# A torch.uint8 (byte) tensor to keep track of which predicted boxes to suppress
# 1 implies suppress, 0 implies don't suppress
suppress = torch.zeros((n_above_min_score), dtype=torch.uint8).to(device) # (n_qualified)
# Consider each box in order of decreasing scores
for box in range(class_decoded_locs.size(0)):
# If this box is already marked for suppression
if suppress[box] == 1:
continue
# Suppress boxes whose overlaps (with current box) are greater than maximum overlap
# Find such boxes and update suppress indices
suppress = torch.max(suppress, (overlap[box] > max_overlap).to(torch.uint8))
# The max operation retains previously suppressed boxes, like an 'OR' operation
# Don't suppress this box, even though it has an overlap of 1 with itself
suppress[box] = 0
# Store only unsuppressed boxes for this class
image_boxes.append(class_decoded_locs[1 - suppress])
image_labels.append(torch.LongTensor((1 - suppress).sum().item() * [c]).to(device))
image_scores.append(class_scores[1 - suppress])
# If no object in any class is found, store a placeholder for 'background'
if len(image_boxes) == 0:
image_boxes.append(torch.FloatTensor([[0., 0., 1., 1.]]).to(device))
image_labels.append(torch.LongTensor([0]).to(device))
image_scores.append(torch.FloatTensor([0.]).to(device))
# Concatenate into single tensors
image_boxes = torch.cat(image_boxes, dim=0) # (n_objects, 4)
image_labels = torch.cat(image_labels, dim=0) # (n_objects)
image_scores = torch.cat(image_scores, dim=0) # (n_objects)
n_objects = image_scores.size(0)
# Keep only the top k objects
if n_objects > top_k:
image_scores, sort_ind = image_scores.sort(dim=0, descending=True)
image_scores = image_scores[:top_k] # (top_k)
image_boxes = image_boxes[sort_ind][:top_k] # (top_k, 4)
image_labels = image_labels[sort_ind][:top_k] # (top_k)
# Append to lists that store predicted boxes and scores for all images
all_images_boxes.append(image_boxes)
all_images_labels.append(image_labels)
all_images_scores.append(image_scores)
return all_images_boxes, all_images_labels, all_images_scores # lists of length batch_size
我们的后处理代码中NMS的部分着实有些绕,大家可以参考下Fast R-CNN中的NMS实现,更简洁清晰一些
# --------------------------------------------------------
# Fast R-CNN
# Copyright (c) 2015 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Written by Ross Girshick
# --------------------------------------------------------
import numpy as np
# dets: 检测的 boxes 及对应的 scores;
# thresh: 设定的阈值
def nms(dets,thresh):
# boxes 位置
x1 = dets[:,0]
y1 = dets[:,1]
x2 = dets[:,2]
y2 = dets[:,3]
# boxes scores
scores = dets[:,4]
areas = (x2-x1+1)*(y2-y1+1) # 各box的面积
order = scores.argsort()[::-1] # 分类置信度排序
keep = [] # 记录保留下的 boxes
while order.size > 0:
i = order[0] # score最大的box对应的 index
keep.append(i) # 将本轮score最大的box的index保留
\\# 计算剩余 boxes 与当前 box 的重叠程度 IoU
xx1 = np.maximum(x1[i],x1[order[1:]])
yy1 = np.maximum(y1[i],y1[order[1:]])
xx2 = np.minimum(x2[i],x2[order[1:]])
yy2 = np.minimum(y2[i],y2[order[1:]])
w = np.maximum(0.0,xx2-xx1+1) # IoU
h = np.maximum(0.0,yy2-yy1+1)
inter = w*h
ovr = inter/(areas[i]+areas[order[1:]]-inter)
\\# 保留 IoU 小于设定阈值的 boxes
inds = np.where(ovr<=thresh)[0]
order = order[inds+1]
return keep
3.6.3 单图预测推理
当模型已经训练完成后,下面我们来看下如何对单张图片进行推理,得到目标检测结果。
首先我们需要导入必要的python包,然后加载训练好的模型权重。
随后我们需要定义预处理函数。为了达到最好的预测效果,测试环节的预处理方案需要和训练时保持一致,仅去除掉数据增强相关的变换即可。
因此,这里我们需要进行的预处理为:
- 将图片缩放为 224 * 224 的大小
- 转换为 Tensor 并除 255
- 进行减均值除方差的归一化
# Set detect transforms (It's important to be consistent with training)
resize = transforms.Resize((224, 224))
to_tensor = transforms.ToTensor()
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
接着我们就来进行推理,过程很简单,核心流程可以概括为:
- 读取一张图片
- 预处理
- 模型预测
- 对模型预测进行后处理
核心代码如下:
# Transform the image
image = normalize(to_tensor(resize(original_image)))
# Move to default device
image = image.to(device)
# Forward prop.
predicted_locs, predicted_scores = model(image.unsqueeze(0))
# Post process, get the final detect objects from our tiny detector output
det_boxes, det_labels, det_scores = model.detect_objects(predicted_locs, predicted_scores, min_score=min_score, max_overlap=max_overlap, top_k=top_k)
这里的detect_objects 函数完成模型预测结果的后处理,主要工作有两个,首先对模型的输出进行解码,得到代表具体位置信息的预测框,随后对所有预测框按类别进行NMS,来过滤掉一些多余的检测框,也就是我们上一小节介绍的内容。
最后,我们将最终得到的检测框结果进行绘制,得到类似如下图的检测结果:

完整代码见 detect.py 脚本,下面是更多的一些VOC测试集中图片的预测结果展示:





可以看到,我们的 tiny_detector 模型对于一些简单的测试图片检测效果还是不错的。一些更难的图片的预测效果如下:
以上是关于动手学CV-目标检测入门教程6:训练与测试的主要内容,如果未能解决你的问题,请参考以下文章