二数据仓库模型设计
Posted 长不大的大灰狼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了二数据仓库模型设计相关的知识,希望对你有一定的参考价值。
数据仓库模型设计
一、数据模型
数据模型(DATA MODEL, DM): 用于提供数据表示和操作手段的形式架构。
概念模型(Concept Data Model, CDM):
- 定义了重要的业务概念和彼此的关系
- 由核心实体或其集合,及实体间的业务关系组成
逻辑模型(Logical Data Model, LDM):
- 对概念数据模型进一步分解和细化
- 描述实体、属性、以及实体与实体之间的关系
物理模型(Physical Data Mode, PDM):
-
描述模型实体的细节,对数据冗余与性能进行平衡
-
关注数据库的物理实现,解决细节技术问题
-
需要考虑数据类型、长度、索引等因素
-
需确定数据平台和架构
二、关系模型
关系模型:通过实体关系(E-R)描述企业业务和业务规则。
- 实体:客观存在并且可以相互区别的事物
- 关系:描述实体间的关联性
- 属性:用来描述一个事物的最基本元素
3NF:
- 每个属性值唯一,不具有多义性(字段不可分)
- 每个非主属性必须完全依赖整个主键,而非部分主键(表不可分)
- 每个非主属性不能依赖其它关系中的属性,即不存在间接依赖(表不可分)
三、维度模型
维度模型:一种趋于支持最终用户,从分析决策的需求出发的数据模型
维度模型分为:维度表、事实表
1、事实表
事实表(Fact):是维度建模中最基本的表,存放业务度量数据,例如数量、金额、汇总等流水和快照数据。
- 数仓维度建模的核心,围绕业务过程进行设计
- 通过获取表述业务过程的度量来表达业务过程
- 包含了应用的维度和业务过程有关的度量

事实表的基本结构:
- 一个或多个数值型的度量字段
- 一组关联到维表的外键,而这些维表提供了事实表度量的上下文
- 一个或者多个退化维度(Degennerate Dimensions))——存在于事实表,但不是外键,不关联任何维表,可能是事实表的主键。
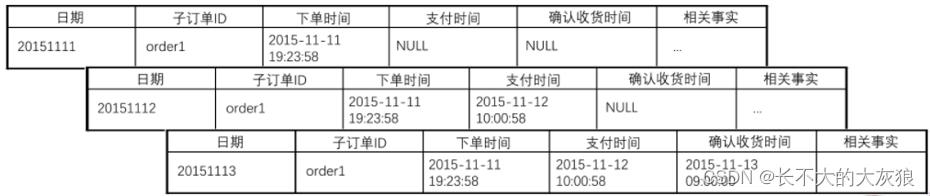
(1)事务事实表
- 用来描述业务过程,跟踪空间或时间上某点的度量事件;
- 保存的是最原子的数据,也称为“原子事实表”、“交易事实表”
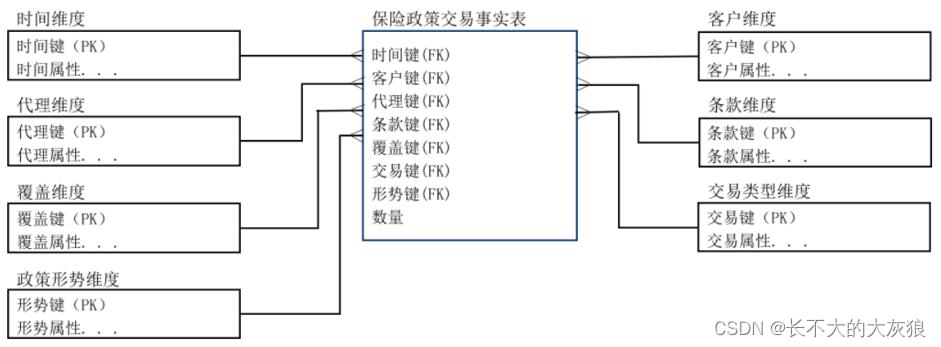
(2)周期快照事实表
周期快照事实表表现得是一个时间段,或者规律性得重复。适合跟踪长期的过程。
周期快照表特点:
- 事务事实表只记录当天发生的业务过程。
- 快照事实表无论当天是否有业务发生都会记录一条。
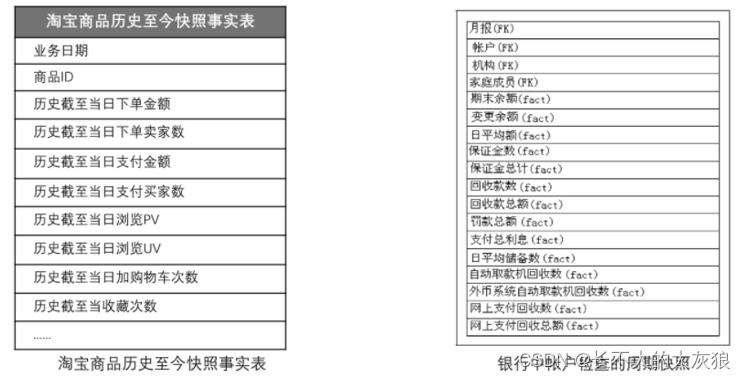
(3)累计快照事实表
- 用于描述有明确开始和结束的过程,如合同履行,保单受理等。
- 累计快照表不适合长期连续处理,如跟踪银行账户。
- 累计快照事实表的粒度是一个实体从创建到当前状态的完整历史。
- 适合研究事件之间的时间间隔
特点:
- 事务事实表仅记录事务发生时的状态,对于实体的某一实例不再更新,累积快照事实表则对某一实例 定期更新。
- 适合于具有明确起止时间的短生命周期的实体。对于较长生命周期的实体,一般采用周期快照事实表比较合适。
(4)无事实的事实表
事件类:没有具体测量值,如用事实表记录交通事故事件。
条件、范围、资格类:客户和销售人员的分配情况,产品的促销范围等。

2、维度表
维度表(Dimension):对数据进行分类的表,用于从特定的角度观察数据。维度是事实表的入口点,维度通常是反范式的,通常占总数据的10%左右。
基础结构:
- 代理键:一个无意义的,唯一标识的字段;维表的主键,事实表的外键;
- 自然键:一个或多个字段,从源系统抽取来的有意义的字段;
- 描述属性:静态或者变化比较慢的字段;会有多个

缓慢变化维:
维度的属性并不是静态的,它会随着时间的流逝发生缓慢的变化;
与数据增长较为快速的事实表相比,维度的变化相对缓慢;
在Kimball理论中,有三种处理缓慢变化维的方式:
- 重写维度值
- 插入新的维度行
- 添加唯独列
重写维度值:不保留历史数据,始终取最新数据。
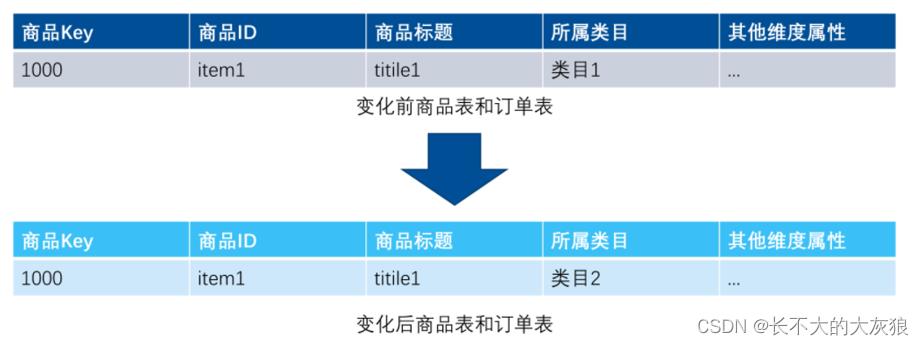
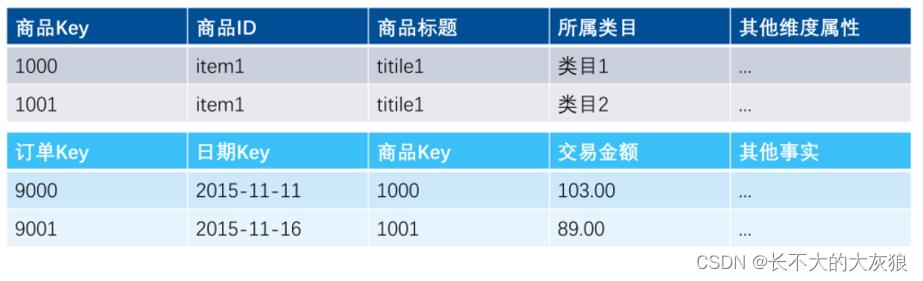
插入新的维度行:保留历史数据,如商品item1的所属类目变化后,插入一条新事务代理键为1001的维度数据,则订单9001使用新的代理键。
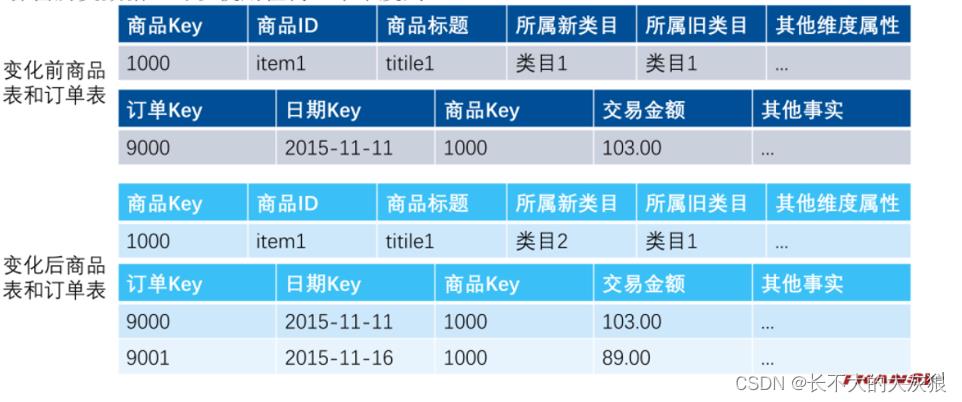
添加维度列: 生成新的一列而不是新的一行。保留历史数据,可以使用任何一个维度列。
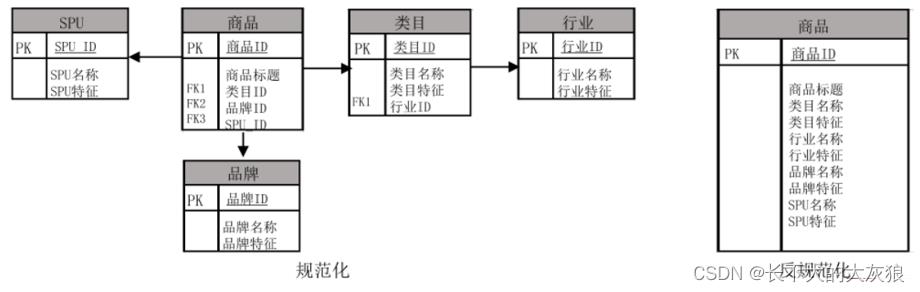
维度表的规范化与反规范化:
- 规范化可以有效避免数据冗余导致的不一致问题;
- 反规范化没有丢失信息,且复杂性降低了;
- 规范化的雪花模式,可以节约部分存储,但会损耗一定的查询性能
- 实际应用中总是使用维表的空间来换取简明性和查询性能
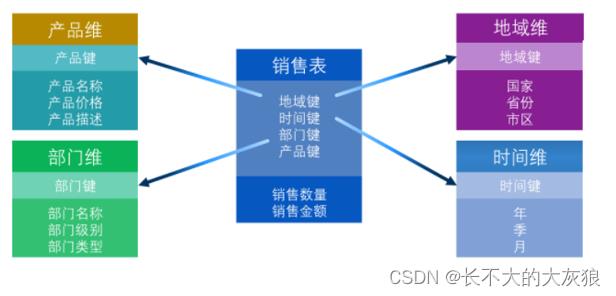
3、维度模型类型
(1)星型类型
- 表达维度和事实之间单层关系的模型
- 事实和每个维度之间都是直连关系
- 不同维度之间没有任何联系
优点:
- 简化查询
- 简化业务报表逻辑
- 提升查询性能
- 快速聚合
(2)雪花模型
- 基于星型模型的拓展
- 对星型模型的维度表进行了范式化处理,一个维度被规范成多个关联的表
- 表达了维度和事实之间的多层关系
优点:节省存储空间
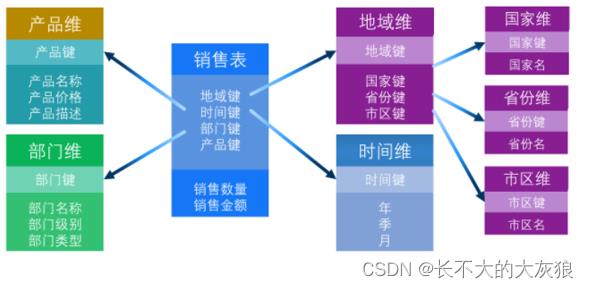
(3)星座模型
星型模型延申,多张事实表,且共享维度表。
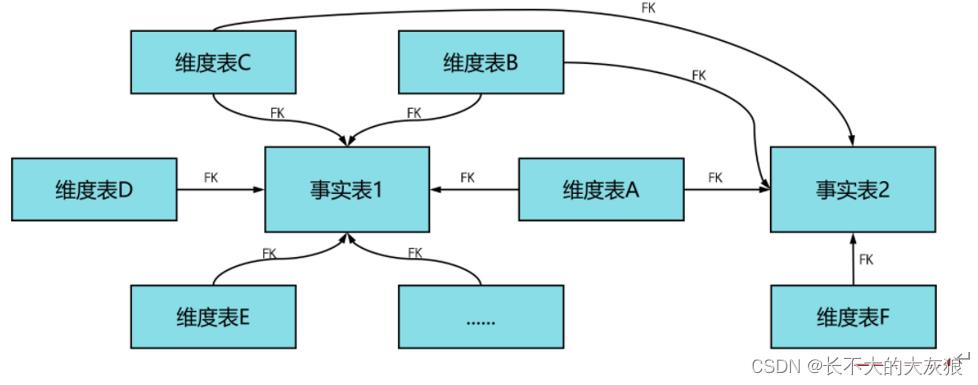
4、维度模型 VS 关系模型
关系模型:
优点:稳定,低冗余;
缺点:性能弱;
场景:传统金融业
维度模型
优点:性能好,易理解
缺点:稳定性弱、高冗余
场景:互联网行业
四、模型设计方法
1、泛化
由具体的、个别的到一般的过程;
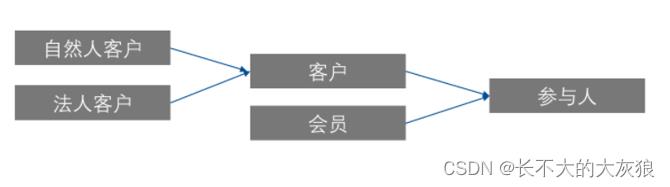
优点:
- 实体能够保罗万象,提高模型的稳定性、泛化能力。如新增存储一种具体对象,无需新增实体;
- 泛化后的数据模型可以减少实体的个数,无需为每个具体的业务对象分别建立相关历史实体;
缺点
- 业务可理解性变弱;
- 计算性能影响
2、子类
- 对于具有泛化层次关系的实体,实体的上一级称为父类实体,实体的下一级称为子类实体; 父子层级可能存在多个层级
- 一般将公共属性放在父类实体,个性化属性放在子类实体;
- 排他性父子类关系:即一条父类数据只能有一种子类;
- 非排他性父子类关系:即一条父类可能有多种子类;
优点:
- 清晰展现业务主题之间的关系;
- 减少子类的附属实体个数;
- 数据模型的稳定性和可扩展性
缺点:
- 计算性能影响;
3、抽象
为确保模型结构(对字段的抽象)能够适应于各种场景,以一种特定的方式移除细节但仍能保留属性的设计模式。
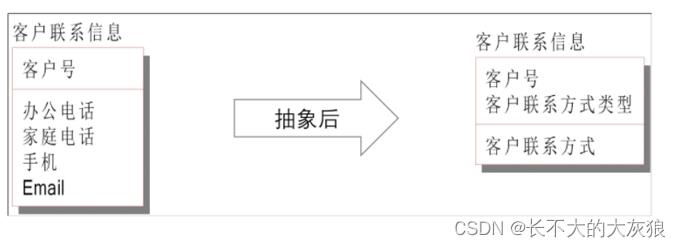
优点:
- 提升数据模型机构的稳定性和可扩展性,当新增一种客户联系方式,如微信号,模型结构无需变化,只需在现有的数据模型实体里增加内容
缺点:
- 业务可理解性变弱
- 计算性能影响
以上是关于二数据仓库模型设计的主要内容,如果未能解决你的问题,请参考以下文章