无标题
Posted chocolate2018
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了无标题相关的知识,希望对你有一定的参考价值。
NXP eIQ 机器学习 — 4
第九章 DeepViewRT
DeepViewRT是一款专为NXP微处理器和微控制器优化的专有神经网络推理引擎,它不仅实现了自己的计算引擎,还能够利用流行的第三方引擎。
特点:
•DeepViewRT 2.4.37
•允许各种计算引擎的插件API:
— DeepViewRT (CPU/Neon)
— DeepViewRT (OpenVX)
— TensorFlow Lite
— Arm NN
— ONNX Runtime
• C and Python API
• 支持逐张量和逐通道量化模型
• 为现有操作定义自定义操作或自定义行为
• 模型部署到所有目标,而不需要显式地对计算图进行编程
9.1 DeepViewRT软件栈
DeepViewRT软件栈包括DeepViewRT库,modelrunner库和modelrunner服务器-见下图:
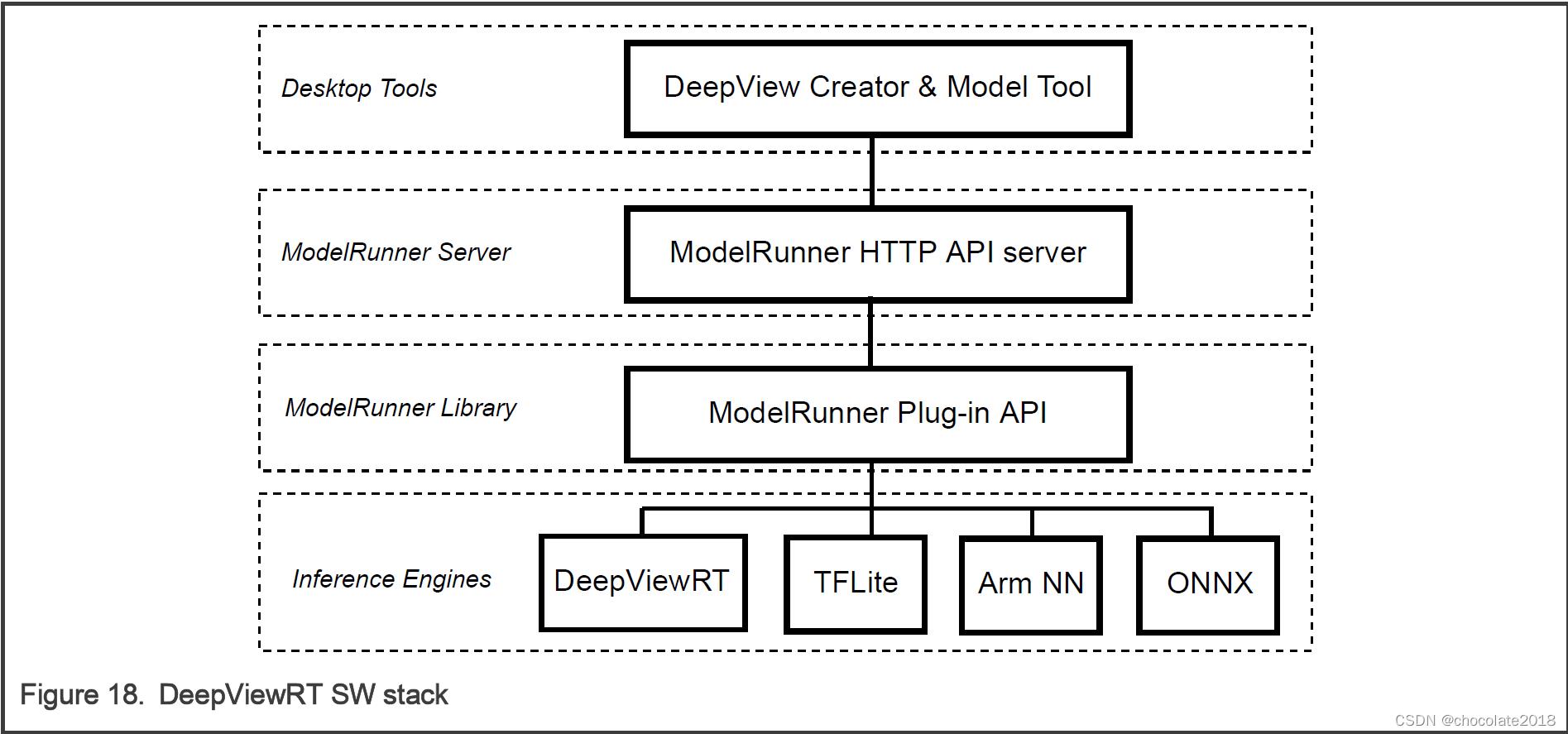
请注意: eIQ门户和模型工具是eIQ工具包的一部分。
DeepViewRT支持以下硬件:
• CPU Arm Cortex-A内核
• GPU/NPU硬件加速器使用VSI NPU后端,它可以运行在GPU和NPU上,具体取决于哪一个可用
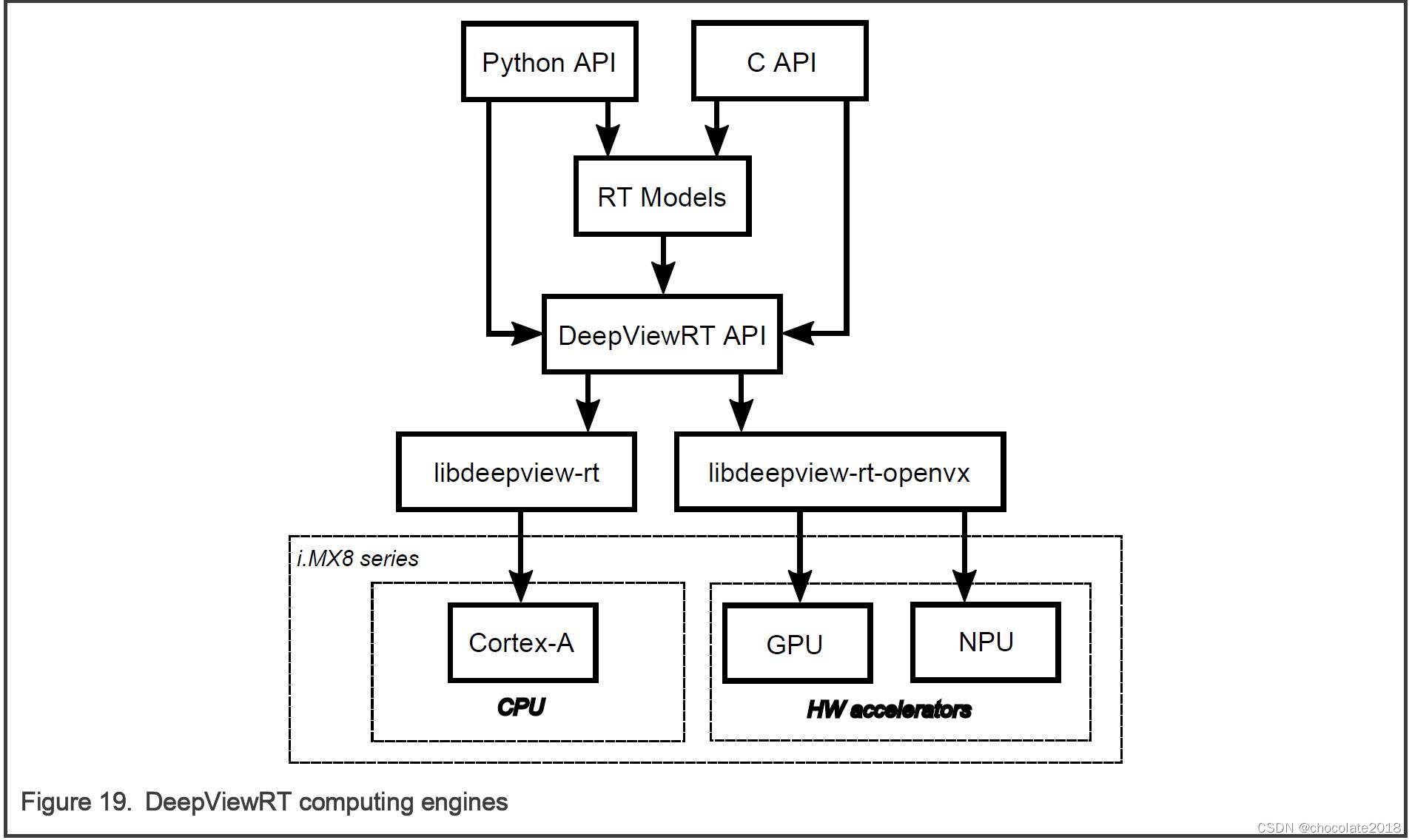
请注意:
请参考DeepViewRT用户手册,包含在eIQ工具包文档文件夹中,以获得更多关于DeepViewRT API的信息。
9.2 交付包
DeepViewRT可以在Yocto recipe中找到,并且可以通过DeepViewRT recipe获得DeepViewRT包。
DeepViewRT包包括Yocto BSP版本的以下组件:
• DeepViewRT共享库(动态库)
• DeepViewRT头文件
• DeepViewRT Python模块
• ModelRunner二进制文件和库
• ModelRunner插件库(OpenVX, TensorFlow Lite, Arm NN, ONNX Runtime)
•DeepViewRT示例(labelimg, detectimg, ssdcam-gst, labelcam-gst)
9.3示例应用程序
所有示例应用程序都集成到Yocto BSP图像中。你可以使用这个Yocto命令来提取源代码并构建所有示例:
Bitbake -c patch deepview-rt-examples
deepview-rt-examples源代码放在tmp/work/cortexa53-crypto-mx8mp-poky-linux/deepview-rt-examples/1.3-r0/deepview-rt-examples-1.3下。
文件夹结构如下:

对于这些示例的交叉编译,请在示例源文件夹下使用Makefile。
9.3.1图像标签应用
有两个示例应用程序演示了如何实现一个图像标签应用程序,目标是直接DeepViewRT C API或使用libCurl库的ModelRunner REST API。
“labelimg”应用程序直接调用DeepViewRT C API:
$ cd /usr/bin/deepview-rt-examples
$ ./labelimg mobilenet_v1_0.25_224_quant.rtm eagle.png
“labelimg_remote”应用程序通过libCurl库使用ModelRunner REST API。运行它需要两个带有以下命令的终端:
# Terminal 1: use -e rt -c 1 (for NPU) or -e rt -c 0 (for CPU)
$ modelrunner -e rt -c 1 -H 10818 -m mobilenet_v1_0.25_224_quant.rtm
# Terminal 2:
$ ./labelimg_remote mobilenet_v1_0.25_224_quant.rtm eagle.png
9.3.2对象检测应用
有两个示例应用程序演示了如何实现一个对象检测应用程序,目标是直接使用libCurl库的DeepViewRT C API或ModelRunner REST API。
“detectimg”应用程序直接调用DeepViewRT C API:
$ cd /usr/bin/deepview-rt-examples $ ./detectv4 DATA_PATH//mobilenet_ssd_v1_1.00_trimmed_new.rtm DATA_PATH/ssd_resized.jpg -T 0.5 -I 0.5 -i 50 -e /usr/lib/deepview-rt-openvx.so
“detectimg_remote”应用程序通过libCurl库使用ModelRunner REST API。运行它需要两个带有以下命令的终端:
# Terminal 1: use -e rt -c 1 (for NPU) or -e rt -c 0 (for CPU)
$ modelrunner -e rt -c 1 -H 10818 -m mobilenet_ssd_v1_1.00_trimmed_quant_anchors.rtm
# Terminal 2:
$ ./detectv4_remote -p 10818 -m mobilenet_ssd_v1_1.00_trimmed_quant_anchors.rtm -i horse.jpg -A 10.10.40.190 -t 0.6 -n 50 -r 0
请注意:
所有的例子都使用DeepViewRT RTM模型格式。.rtm可以从.tflite转换。对于模型转换,请参阅eIQ Toolkit用户指南(EIQTUG)。
9.3.3 Labelcam-gst示例应用
这个示例演示了一个基于gstreamer的应用程序,它提供了一个摄像头来显示管道和一个用于与DeepViewRT接口的appsink。推断的结果以文本叠加的形式显示在视频显示器上。
这个例子可以通过libCurl库支持DeepViewRT API (CPU)和ModelRunner REST API运行(通过OpenVX插件来利用NPU加速)。这个例子将需要摄像头和显示器;它可以是MIPI-CSI摄像头或USB摄像头。关于MIPI-CSI相机和显示器的使用,请参阅i.MX移植指南(IMXBSPPG)。
假设用户有一个名为mobilenet_v1_0_1.0_224_quant_with_labels.rtm的模型,可以按照以下方式通过DeepViewRT API (CPU)执行演示。使用USB摄像头(/dev/video3)和LCD。
$ ./labelcam-gst -m mobilenet_v1_0_1.0_224_quant_with_labels.rtm -c /dev/video3 IP not set! Streaming to localhost!! video size: 640x480 center roi size: 480x480 model size: 224x224
LCD将显示标签名称与可能性值和运行时值。
演示也可以通过以下方式通过libCurl库通过ModelRunner REST API执行。这将利用NPU来加速:
# Terminal 1: use -e rt -c 1 (for NPU) or -e rt -c 0 (for CPU)
$ modelrunner -e rt -c 1 -H 10818 -m mobilenet_v1_0_1.0_224_quant_with_labels.rtm
# Terminal 2:
$ ./labelcam-gst -m mobilenet_v1_0_1.0_224_quant_with_labels.rtm -c /dev/video3 -r 127.0.0.1 -p 10818 -u 1
POST URL = http://127.0.0.1:10818/v1?run=1&output=MobilenetV1_Predictions_Reshape_1 IP not set! Streaming to localhost!!
video size: 640x480 center roi size: 480x480 model size: 224x224
LCD将显示标签名称与可能性值,往返时间,推断时间。
9.3.4 Ssdcam-gst示例应用
这个项目演示了如何集成DeepViewRT与GStreamer相机管道。在这个例子中,我们从默认相机捕获输入,然后运行单镜头检测来生成帧中每个检测到的物体的边界框、标签和概率。
这个例子可以通过libCurl库支持DeepViewRT API (CPU)和ModelRunner REST API运行(通过OpenVX插件来利用NPU加速)。这个例子将需要摄像头和显示器;它可以是MIPI-CSI摄像头或USB摄像头。关于MIPI-CSI相机和显示器的使用,请参阅i.MX移植指南(IMXBSPPG)。
假设您有一个名为mobilenet_v1_0_1.0_224_quant_with_labels.rtm,mobilenet_ssd_v1_1.00_trimmed_anchors_quant.rtm的模型,使用USB摄像头(/dev/video3)和LCD,可以按照以下方式通过DeepViewRT API(CPU)执行演示。
$ ./ssdcam-gst -m mobilenet_ssd_v1_1.00_trimmed_anchors_quant.rtm -c /dev/video3 -t 0.5 -n 0.5 Score Threshold used = 0.50 video size: 640x480 model size: 300x300 Using display!
LCD会显示推断时间,并有可能绘制出对象和对象类名的边界框。
这个演示也可以通过ModelRunner REST API和libCurl库来执行,这将利用NPU来加速:
# Terminal 1: use -e rt -c 1 (for NPU) or -e rt -c 0 (for CPU) $ modelrunner -e rt -c 1 -H 10818 -m mobilenet_v1_0_1.0_224_quant_with_labels.rtm # Terminal 2: $ ./ssdcam-gst -m mobilenet_ssd_v1_1.00_trimmed_anchors_quant.rtm -c /dev/video3 -t 0.5 -n 0.5 -r 127.0.0.1 -p 10818 Score Threshold used = 0.50 video size: 640x480 model size: 300x300 Using display!
LCD会显示推断时间、往返时间,并有可能绘制出对象和对象类名的边界框。
9.4 ModelRunner
ModelRunner应用程序提供了一个HTTP服务,用于托管DeepViewRT模型、TensorFlow Lite模型、ONNX Runtime模型和远程评估。该服务还提供用于低延迟视频处理的低级UNIX套接字服务。它通过DeepViewRT Yocto配方集成到BSP中。
对于ModelRunner HTTP REST API,请参考DeepViewRT用户手册,它包含在eIQ工具包文档文件夹中。
要使用Modelrunner进行基准评估,请参考以下命令(章节)来度量性能。
9.4.1 DeepViewRT
使用DeepViewRT后端运行modelrunner并测量其性能:
$ modelrunner -e rt -c 0 -m mobilenet_v1_1.0_224_quant.rtm -b 50 -t 4 Plugin: libmodelrunner-rt.so; Average model run time: 129.0078 ms (layer sum: 0.0000 ms)
请注意:
线程数(-t参数)应该与设备计算核数相关,以获得最佳性能。例如,对于i.MX 8QM设备使用-t 6等。
9.4.2 OpenVX
使用OpenVX通过加速NPU运行modelrunner并测量其性能:
$ modelrunner -e rt -c 1 -m mobilenet_v1_1.0_224_quant.rtm -b 50 Plugin: libmodelrunner-ovx.so; RTMx Output indices = [87 ] Created empty VX graph, inputs = 1, outputs = 1 RTMx Layer count = 88 … Average model run time: 2.2397 ms
9.4.3 TensorFlow Lite
使用TensorFlow Lite和NNAPI委托运行modelrunner并测量其性能:
$ modelrunner -e tflite -c 1 -m mobilenet_v1_1.0_224_quant.tflite -b 50 Plugin: libmodelrunner-tflite.so; Loaded model resolved reporter INFO: Created TensorFlow Lite delegate for NNAPI. Applied NPU delegate. interpreter invoked average time: 2.51356 ms Average layer sum: 2.5105 ms
请注意:
可以通过“-c 0”替换“-c 1”来使用CPU。XNNPACK使用" - 2 “,VX Delegate使用” - 3 "。
9.4.4 Arm NN
使用Arm NN和Vsi_Npu后台运行modelrunner并测量其性能:
$ modelrunner -e armnn -c 3 -m mobilenet_v1_1.0_224_quant.tflite -b 50 -t 4 Plugin: libmodelrunner-armnn.so; NPU backend preference Model loaded and validated, size = 150528 … Inference Time in ms = 2.56184
请注意:可以通过将“-c 3”替换为“-c 0”来更改为使用CpuAcc。
9.4.5 ONNX运行时
使用ONNX Runtime和Vsi_Npu执行提供商运行modelrunner并测量其性能:
$ modelrunner -e onnx -c 3 -m mobilenet_v1_1.0_224_quant.onnx -b 50 Plugin: libmodelrunner-onnx.so; WARNING: Since openmp is enabled in this build, this API cannot be used to configure intra op num threads. Please use the openmp environment variables to control the number of threads. Prefer Vsi_Npu execution provider Input name=input, type=1, num_dims=4, shape=[ 1 3 224 224 ] Number of outputs = 1 Output 0 : name=TFLITE2ONNX_Quant_MobilenetV1/Predictions/Reshape_1_dequantized
Loaded ONNX model.
Average model run time: 434.220155 ms
使用ONNX Runtime和Arm NN执行提供商运行modelrunner并测量其性能:
$ modelrunner -e onnx -c 2 -m mobilenet_v1_1.0_224_quant.onnx -b 50 -t 4 Plugin: libmodelrunner-onnx.so; WARNING: Since openmp is enabled in this build, this API cannot be used to configure intra op num threads. Please use the openmp environment variables to control the number of threads. Prefer ArmNN execution provider Input name=input, type=1, num_dims=4, shape=[ 1 3 224 224 ] Number of outputs = 1 Output 0 : name=TFLITE2ONNX_Quant_MobilenetV1/Predictions/Reshape_1_dequantized Loaded ONNX model. Average model run time: 233.127588 ms
请注意:
通过将“-c 3”替换为“-c 2”,可以将其更改为使用“ArmNN”作为执行提供者。
第十章 TVM
Apache TVM是一个开放源码的机器学习编译器框架,用于cpu、gpu和机器学习加速器。 它的目标是让机器学习工程师在任何硬件后端优化和高效运行计算。
特点:
• 0.7.0 TVM
• 将深度学习模型编译为最小可部署模块
• 在更多的后端自动生成和优化模型的基础设施,具有更好的性能
• GPU/NPU支持i.MX8 (i.MX8MM和i.MX8MN除外)平台和OpenVX库
• TVM builder支持Ubuntu 18.04, x86_64平台
请注意:更多详细信息请参考TVM文档。
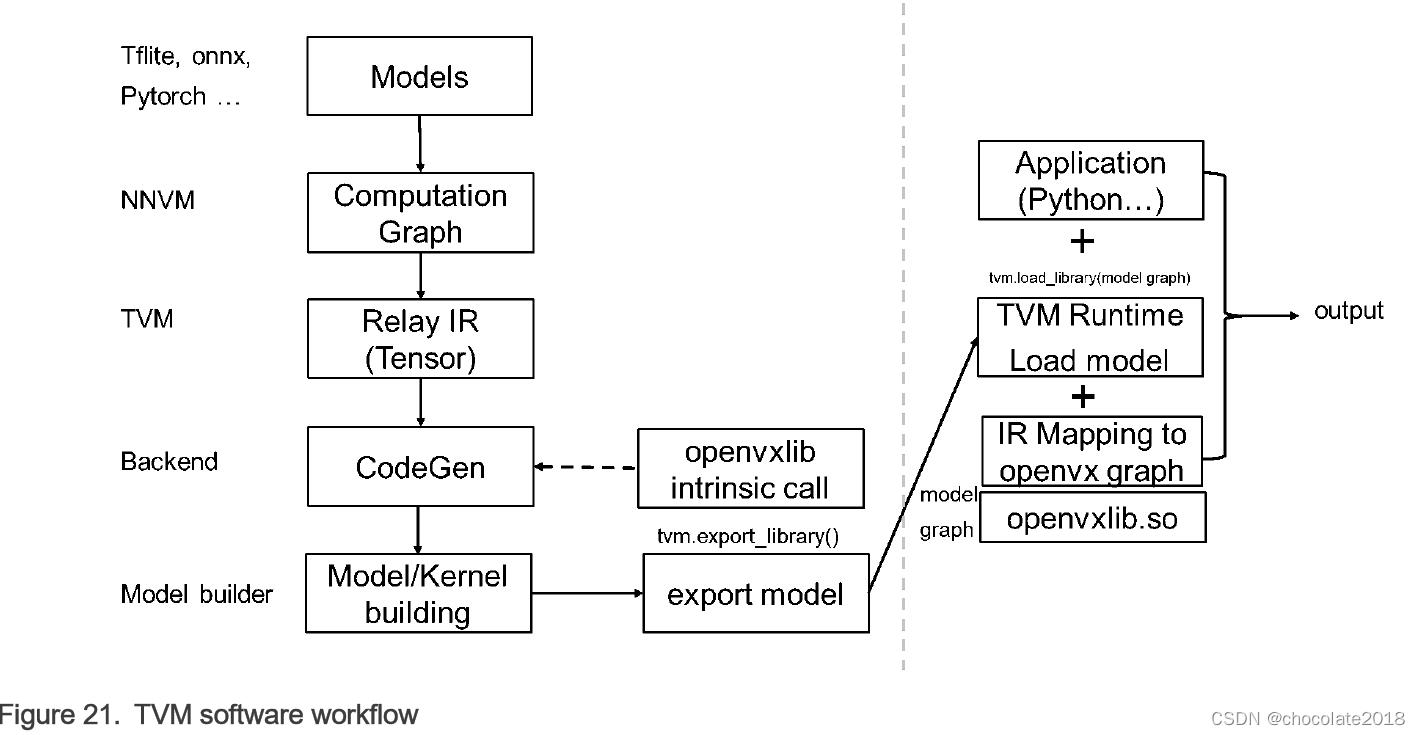
10.1 TVM软件工作流程
预训练的模型将转换为Relay IR,并通过TVM模型优化,如常量折叠、内存规划,最后传递到代码生成阶段。 在此阶段,目标设备支持的操作被转化为内在调用,进入连接GPU/NPU等模型加速器设备的卸载库。
10.2开始
10.2.1运行示例,使用RPC验证
TVM提供了远程过程调用(Remote Procedure Call, RPC)功能,可以在远程设备上运行模型。
用户可以通过RPC验证在tests/python/contrib/test_vsi_npu运行示例。 模型在设备上的运行结果将与相同输入的主机上的结果进行验证。
• 在设备上启动RPC服务器
$ python3 -m tvm.exec.rpc_server --host 0.0.0.0 --port=9090
• 导出系统变量:
$ export TVM_HOME=/path/to/tvm
$ export PYTHONPATH=$TVM_HOME/python
• 在主机PC上运行指定型号:
$ python3 tests/python/contrib/test_vsi_npu/test_tflite_models.py -i device_ip - m mobilenet_v2_1.0_224_quant
• 在主机PC上运行所有支持的TensorFlow Lite模型:
$ python3 tests/python/contrib/test_vsi_npu/test_tflite_models.py -i device_ip
请注意: 本次测试将自动下载模型,请确保网络能够连接到公共互联网。 示例脚本可以导入额外的Python库。 请检查脚本并确保它们正确安装。
要测试pytorch/onnx/keras模型,需要在主机PC上安装额外的python包:
$ python3 -m PIP install torch==1.7.0 torchvision==0.8.1
$ python3 -m PIP install onnx=1.8.1 onnxruntime==1.8.1
$ python3 -m PIP install tensorflow==2.5.0
10.2.2在设备上单独运行示例
在这种模式下,模型脱机在主机上编译,并保存为model.so。 请参考tests/python/contrib/test_vsi_npu/compile_tflite_models.py在主机上编译TensorFlow Lite模型。
下面的脚本片段展示了如何在设备上加载和运行一个编译好的模型:
ctx = tvm.cpu(0)
# load the compiled model
lib = tvm.runtime.load_module(args.model)
m = graph_runtime.GraphModule(lib["default"](ctx))
# set inputs data = get_img_data(args.image, (args.input_size, args.input_size), args.data_type) m.set_input(args.input_tensor, data)
# execute the model
m.run()
# get outputs
tvm_output = m.get_output(0)
请参考tests/python/contrib/test_vsi_npu/label_image.py来获得一个完整的标签图像示例,其中包括图像解码的预处理和生成标签的后处理。
10.3如何在主机上构建TVM栈
从概念上讲,TVM可以分为两部分:
TVM构建栈:在主机上编译深度学习模型
TVM运行时:在设备上加载和解释模型
此构建堆栈使用LLVM交叉编译生成的源文件,将其作为可部署的动态库用于设备。 请参考LLVM文档在主机上安装LLVM。 如果安装成功,llvm-config应该在/usr/bin下找到。
要构建tvm,请确保主机上安装了以下依赖包:
• cmake
• python3-dev
• build-essential
• llvm-dev
• g++-aarch64-linux-gnu
• libedit-dev
• libxml2-dev
• python3-numpy
• python3-attrs
• python3-tflite
对于Ubuntu 18.04,用户可以使用以下命令来安装所有依赖:
$ sudo apt-get update
$ sudo apt-get install -y python3 python3-dev python3-setuptools
$ sudo apt-get install -y cmake llvm llvm-dev g++-aarch64-linux-gnu gcc-aarch64-linux-gnu
$ sudo apt-get install -y libtinfo-dev zlib1g-dev build-essential libedit-dev libxml2-dev
$ python3 -m pip install numpy decorator scipy attrs six tflite
按照以下指令在主机上构建TVM堆栈:
$ export TOP_DIR=`pwd`
$ git clone --recursive https://source.codeaurora.org/external/imx/eiq-tvm-imx/ tvm-host
$ cd tvm-host
$ mkdir build
$ cp cmake/config.cmake build
$ cd build $ sed -i 's/USE_LLVM\\ OFF/USE_LLVM\\ \\/usr\\/bin\\/llvm-config/' config.cmake
$ cmake ..
$ make tvm -j4 # make tvm build stack
10.4支持模型
以下型号已通过TVM验证。
表3 TVM模型ZOO


第十一章 硬件加速器上的NN执行
11.1硬件加速说明
i.MX8类设备部署了两种NN加速器(见图1):
神经处理单元(NPU)
图形处理单元(GPU)
神经处理单元优化了定点算法,在8位和16位宽度。 为了在NPU上获得最佳性能,量化模型应使用。
对图形处理单元进行了优化设计,实现了定点算法和半精度浮点算法。 为了在GPU上获得最佳性能,量化模型或半精度应使用浮点模型。
请注意:TensorFlow Lite框架可以直接用16位半精度算法计算浮点模型。
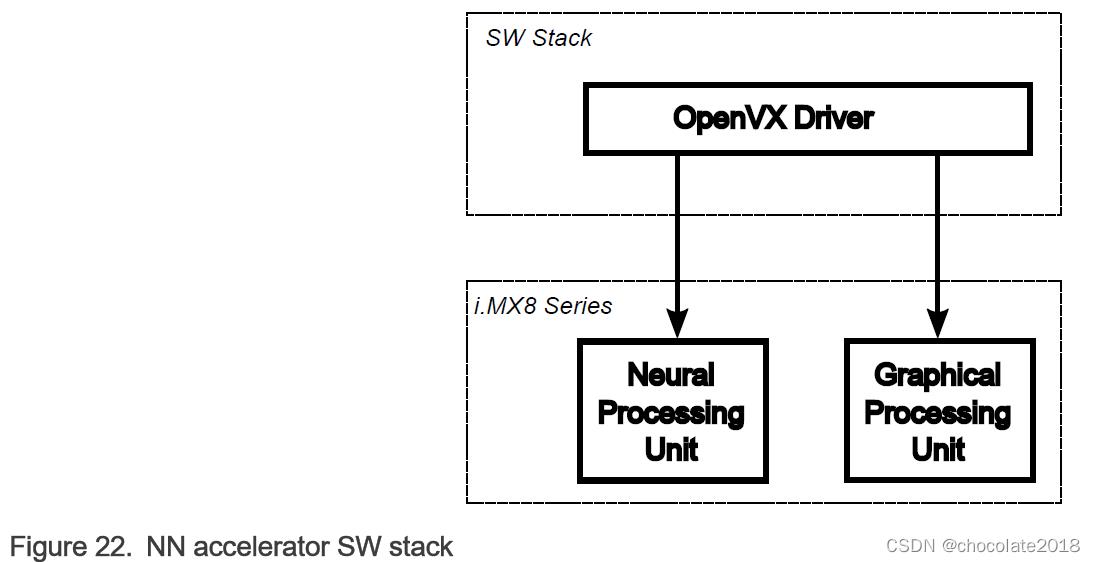
NPU/GPU硬件加速器的接口是通过OpenVX v1.2提供的NN扩展。 OpenVX是一个开放的,免版税的标准,用于计算机视觉应用的跨平台加速。 它提供了[3](OpenVX 1.2规范; https://www.khronos.org/registry/OpenVX/specs/1.2/html/index.html):
• 一个预定义和可定制的视觉函数库
• 基于图的执行模型,可以组合支持任务和数据独立执行的功能
• 抽象物理内存的一组内存对象
Open VX定义了一个c应用程序编程接口,用于构建、验证和协调图形执行以及访问内存对象。 关于OpenVX的更多信息可以在OpenVX主页上找到。
请注意:在当前的OpenVX驱动实现中,OpenVX图中支持的最大节点数是2048。
11.2硬件加速器上的分析
介绍如何在GPU/NPU上开启profiler,以及如何抓取日志。
- 按EVK单板“Enter”键停止U-Boot。
- 通过添加galcore.showArgs=1 和 galcore.gpuProfiler=1来更新mmcargs。
u-boot=> editenv mmcargs
edit: setenv bootargs $jh_clk console=$console root=$mmcroot
galcore.showArgs=1 galcore.gpuProfiler=1
u-boot=> boot
- 启动单板,等待Linux操作系统提示。
- 在执行应用程序之前,应该启用以下环境标志。 在分析过程中,VIV_VX_DEBUG_LEVEL和VIV_VX_PROFILE标记应该始终为1。 CNN_PERF标志使驱动程序能够生成每层概要日志。 NN_EXT_SHOW_PERF显示了编译器如何评估性能并基于性能确定平铺的细节。
export CNN_PERF=1 NN_EXT_SHOW_PERF=1 VIV_VX_DEBUG_LEVEL=1 VIV_VX_PROFILE=1
- 捕获剖析器日志。 我们使用标准NXP Linux发行版的ML示例部分来解释下面的部分。
• TensorFlow Lite剖析
运行后台为GPU/NPU的TensorFlow Lite应用,步骤如下:
$ cd /usr/bin/tensorflow-lite-2.6.0/examples $ ./label_image -m mobilenet_v1_1.0_224_quant.tflite -t 1 -i grace_hopper.bmp -l labels.txt --external_delegate_path=/usr/lib/libvx_delegate.so -v 0 > viv_test_app_profile.log 2>&1
• Arm NN分析
运行Arm NN应用程序(此处以TfMobilNet为例),后端为GPU/NPU,如下所示:
$ cd /usr/bin/armnn-21.08/ $ ./TfMobileNet-Armnn --data-dir=data --model-dir=models --compute=VsiNpu > viv_test_app_profile.log 2>&1
请注意:Armnn概要分析示例假设模型文件和输入数据都位于各自的子文件夹中。 请参见运行Arm NN测试。
日志记录了各层执行时钟周期和DDR数据传输的详细信息。
请注意: 随着分析器开销的增加,推断的平均时间可能会比平常更长。
11.3硬件加速器的预热时间
对于Arm NN和TensorFlow Lite,由于GPU/NPU硬件加速器需要初始化模型图,因此初始执行模型推断需要更长的时间。 初始化阶段称为预热阶段。 通过将初始OpenVX图处理产生的信息存储在磁盘上,可以减少后续应用程序运行的时间。 以下环境变量应用于此目的:
VIV_VX_ENABLE_CACHE_GRAPH_BINARY:开启/关闭OpenVX图形缓存的标志
VIV_VX_CACHE_BINARY_GRAPH_DIR:设置缓存信息在磁盘上的位置
例如,在控制台上这样设置这些变量:
export VIV_VX_ENABLE_CACHE_GRAPH_BINARY="1"
export VIV_VX_CACHE_BINARY_GRAPH_DIR=`pwd`
通过设置这些变量,OpenVX图形编译的结果以网络二进制图形文件(.nb)的形式存储在磁盘上。 运行时在网络上执行快速哈希检查,如果匹配。 nb文件哈希,它直接加载到NPU内存。 这些环境变量需要持久地设置,例如,重新启动后可用。 否则,即使*。 存在Nb文件。
图初始化之后的迭代执行速度要快很多倍。 当评估运行在GPU/NPU上的应用程序的性能时,应该分别测量预热时间和推断时间。 预热时间通常只影响第一次推断运行。 然而,根据机器学习模型类型的不同,在最初的几次推理运行中,这可能是显而易见的。 必须做一些初步的测试,以决定考虑什么预热时间。 当这个阶段被很好地划分时,后续的推理运行可以被认为是纯推理,并用于计算推理阶段的平均值。
11.4切换GPU和NPU
一些平台同时部署了3D GPU和NPU硬件加速器。 两者都可以用于OpenVX图的执行(即ML推断)。 为了区分GPU和NPU,有一个环境变量USE_GPU_INFERENCE。 该变量由硬件加速驱动程序直接读取。
行为如下:
USE_GPU_INFERENCE=1表示图形在GPU上执行
否则,图形将在NPU上执行(如果可用的话)
默认情况下,NPU用于OpenVX图形的执行。
使用TensorFlow Lite的示例:
$ USE_GPU_INFERENCE=1 ./label_image -m mobilenet_v1_1.0_224_quant. / Tflite -i grace_hopper.bmp -l labels.txt——external_delegate_path=/usr/lib/libvx_delegate.so
第十二章 使用NNStreamer的Vision Pipeline
NNStreamer是一个用于复杂神经网络应用的高效、灵活的流管道框架。最初由三星电子开发,后来转给了LF AI基金会作为孵化项目。
它是一组GStreamer插件,允许GStreamer开发人员轻松高效地采用神经网络模型,并允许神经网络开发人员轻松高效地管理神经网络管道及其过滤器。
该项目在其专用的github文档网站上有很好的文档记录,但为了方便起见,下面将介绍主要的要点。
除了标准的GStreamer数据类型外,NNStreamer还添加了新的数据类型“other/tensor”和“other/tensor”,这要归功于一个专用的转换器元素。该数据类型分别表示多维数组流和多维数组的多个实例容器流。
NNStreamer提供了一组对张量应用多种操作的流过滤器:
• Tensor_converter将音频、视频、文本或任意二进制流转换为其他/张量流。
• Tensor_decoder使用指定的子插件将其他/张量转换为视频或文本流。
• Tensor_filter使用给定的模型路径和神经网络框架名称调用神经网络模型。
• Tensor_transform对张量应用各种运算符,包括类型转换、加、多、转置和归一化。为了更快的处理,它支持SIMD指令和在一个过滤器中多个操作符。
• Tensor_crop表示传入张量的区域。
• Tensor_rate控制张量流的帧速率。
• Tensor_mux、tensor_demux、tensor_merge、tensor_split、tensor_if和tensor_aggregator支持张量流路径控件。
• Tensor_sink是一个接收器插件,用于使应用程序获得其他/张量的缓冲区。
• tensor_source允许非GStreamer标准输入源,例如传感器,来提供其他/张量流。
• tensor_reposink和tensor_reposrc实现了递归路径助手,得益于专用的共享存储库,减少了GStreamer管道周期。tensor_reposink将数据推送到存储库,后者通过tensor_reposrc元素向上游重新注入数据。
下图显示了NNStreamer管道的一般架构。

有两个元素允许在运行时添加用户创建的特性:tensor_filter和tensor_decoder:
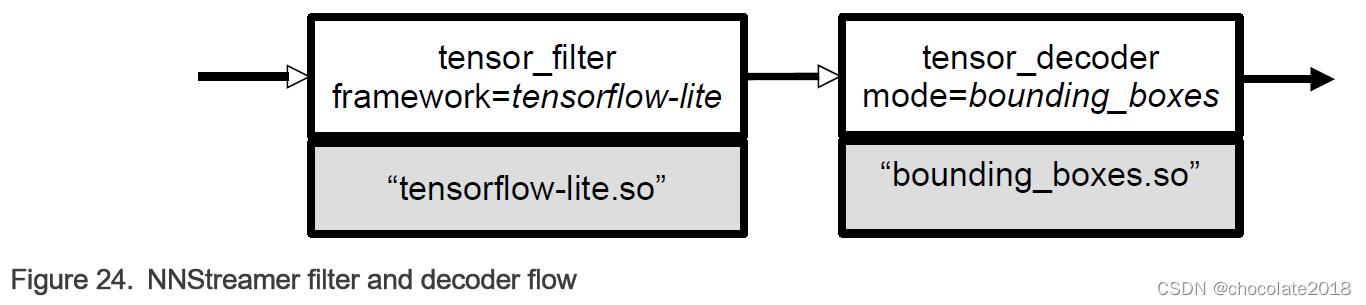
在实例化tensor_filter和tensor_decoder时,由于在运行时加载了专用的共享库,框架和模式选项分别指定了目标实现。NNStreamer提供了一组过滤器和解码器(如下所述),以及实现自定义用户子插件的api。因此,可以使用专有的推理引擎子插件作为张量滤波器,或专门的NN解码器。
NNStreamer支持最流行的推断引擎(不管是否是开源的)。这个版本支持TensorFlow Lite引擎。不支持Arm NN引擎。
表4. NNStreamer支持功能

在多个硬件后端可能支持推理引擎的情况下,可以指定映射到神经网络的设备。
尽管张量解码器元素可能不是适合构建应用程序通常不使用神经网络输出仅用于显示目的,它特别适合实现一个原型在开发阶段可能集中在神经网络模型或优化数据路径。事实上,大多数神经网络拓扑都支持经典的计算机视觉用例:分类、目标检测、姿态估计或分割。
NNStreamer张量过滤器元素必须配置使用特定的引擎和硬件加速器。下表列出了可用的选项。
表5所示.TensorFlow Lite引擎

Table 6. Arm NN engine (deprecated)

12.1 对象检测管道示例
在本例中,将利用i.MX 8M Plus上大多数可用的计算后端来实现以下管道,以构建一个对象检测场景。

在target上,从google coral github站点下载经过训练的神经网络,并将文件名导出到bash环境变量:
root:~# wget https://github.com/google-coral/test_data/raw/master/ssd_mobilenet_v2_coco_quant_postprocess.tflite
root:~# wget https://github.com/google-coral/test_data/raw/master/coco_labels.txt
root:~# export MODEL=$(pwd)/ssd_mobilenet_v2_coco_quant_postprocess.tflite
root:~# export LABELS=$(pwd)/coco_labels.txt
Then builds and executes the GStreamer pipeline:
然后构建并执行GStreamer管道:
root:~# gst-launch-1.0 --no-position v4l2src device=/dev/video3 ! \\
video/x-raw,width=640,height=480,framerate=30/1 ! \\
tee name=t t. ! queue max-size-buffers=2 leaky=2 ! \\
imxvideoconvert_g2d ! \\ video/x-raw,width=300,height=300,format=RGBA ! \\
videoconvert ! video/x-raw,format=RGB ! \\ tensor_converter ! \\
tensor_filter framework=tensorflow-lite model=$MODEL custom=Delegate:External,ExtDelegateLib:libvx_delegate.so ! \\
tensor_decoder mode=bounding_boxes option1=tf-ssd option2=$LABELS \\
option3=0:1:2:3,50 option4=640:480 option5=300:300 ! \\
mix. t. ! queue max-size-buffers=2 ! \\
imxcompositor_g2d name=mix sink_0::zorder=2 sink_1::zorder=1 ! waylandsink
注意事项:如有必要,按CTRL+C键停止执行。
12.2 管道分析
NNStreamer团队开发了NNShark,这是一种基于GstShark的评测工具,用于监控多个用于评估SoC硬件使用情况的管道度量。
NNShark只能用于i.MX8M Plus,其中添加了特定指标:
• 2D GPU(GC520L)利用率负载
• 3D GPU(GC7000UL)利用率负载
• NPU(GC8000)利用率负荷
• Linux内核性能工具报告的SoC主带宽
• 此外,如果用户可以使用功率测量评估工具包,则功率测量工具(PMT)会报告功率域消耗。
考虑到涉及并行阶段的复杂GPU/NPU架构,其报告的利用率负载应视为一个数量级,可能无法准确反映每个阶段的状态。
注意事项:有关源代码演示位置,请参阅nnshark存储库。
12.2.1启用NNShark分析
建议通过SSH连接到目标,因为NNShark UI刷新率可能无法在串行控制台上很好地呈现。
通过环境变量启用NNShark评测:
root:~# export GST_DEBUG="GST_TRACER:7"
root:~# export GST_TRACERS="live"
为了获得GPU使用率测量值,您必须禁用GPU驱动程序(galcore)中的节能功能,这要归功于命令行内核参数。可以在执行boot命令之前手动编辑bootargs uboot变量,添加以下参数:
galcore.gpuProfiler=1 galcore.powerManagement=0
然后运行上一个gst启动命令行,现在应在终端屏幕上显示以下屏幕。可以使用上/下方向键滚动所有管道元素,以选择所需的元素并显示其与其他管道元素的连接。
可以使用左/右方向键选择元素焊盘,以高亮显示其与其他元素焊盘的连接。
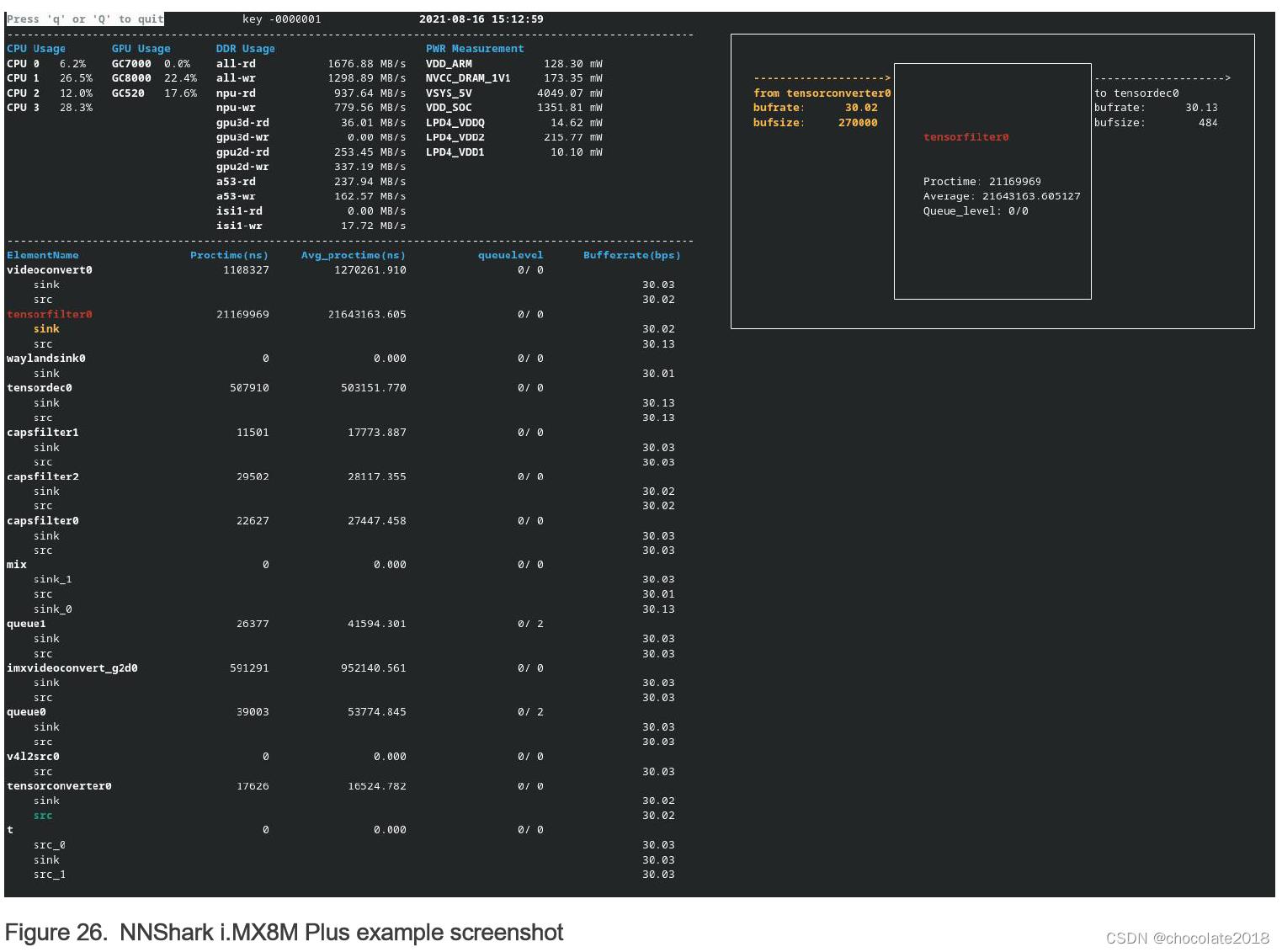
在本例中,张量过滤器的平均处理时间为21.64 ms,其橙色接收器突出显示的焊盘连接到tensorconverter0元素的源焊盘(绿色突出显示)。
按“q”或“q”退出分析工具并返回外壳终端。如前所述,您可以通过CTRL+C退出应用程序。
12.2.2向NNShark添加功率测量功能
在连接到功率测量评估套件的桌面PC上,在服务器模式下执行功率测量工具(PMT),如功率测量采集,在65432 TCP/IP端口上可用。
user@localhost:pmt# python3 main.py server -b imx8mpevkpwra0 -p 65432
在目标器中,导出桌面PC的ip地址(本例中为192.168.1.99):
root:~# export GST_TRACERS_PWR_SERVER_IP=192.168.1.99
请注意:用户无需功耗测量套件即可运行NNShark。
12.2.3已知问题和限制
如果perf报告不一致的高数值,这意味着perf进程仍然在前一次运行的后台运行。如果是,则必须手动终止它们的执行。
为了您的方便,可以使用以下命令:
root:~# kill -9 $(ps -ef | grep nnshark-perf-ddr.sh | grep -v grep | tr -s ' ' | cut -d ' ' -f 2)
第十三章 eIQ演示
13.1 AWS端到端的SageMaker演示
AWS SageMaker演示了如何使用i.MX BSP中预构建的AWS IoT Greengrass和SageMaker Edge Manager包,通过云服务构建、部署和管理机器学习模型和设备软件。
AWS IoT Greengrass是一款将云功能扩展到本地设备的软件。它支持通过MQTT协议进行本地设备消息传递,建立到云的安全连接。AWS SageMaker Edge Manager提供了一个运行在边缘设备上的软件代理,用于模型推断,以及一个单独的SageMaker Neo云服务,用于管理边缘设备上的模型。
特点:
• AWS IoT Greengrass v2
• AWS Sagemaker边缘管理代理
• AWS命令行接口(AWS CLI) v1.21.12
• 基于AWS CLI的自动脚本示例,实现云服务和设备的发放、操作
• 视频推断演示,执行这些任务:
—从云计算模型部署
—USB摄像头捕捉图像帧
—推理结果返回到云端
13.1.1 AWS Greengrass/SageMaker演示工作流
这个端到端流程(也见下图)使用预先训练的mobilenetv2图像分类模型对从USB摄像头捕获的图像在边缘进行图像分类。推断是在i.MX 8M Plus的NPU上执行的,与只在CPU上运行相比,它允许高达50倍的性能提高。结果被上传至AWS IoT,输入和输出张量被上传至Amazon S3。
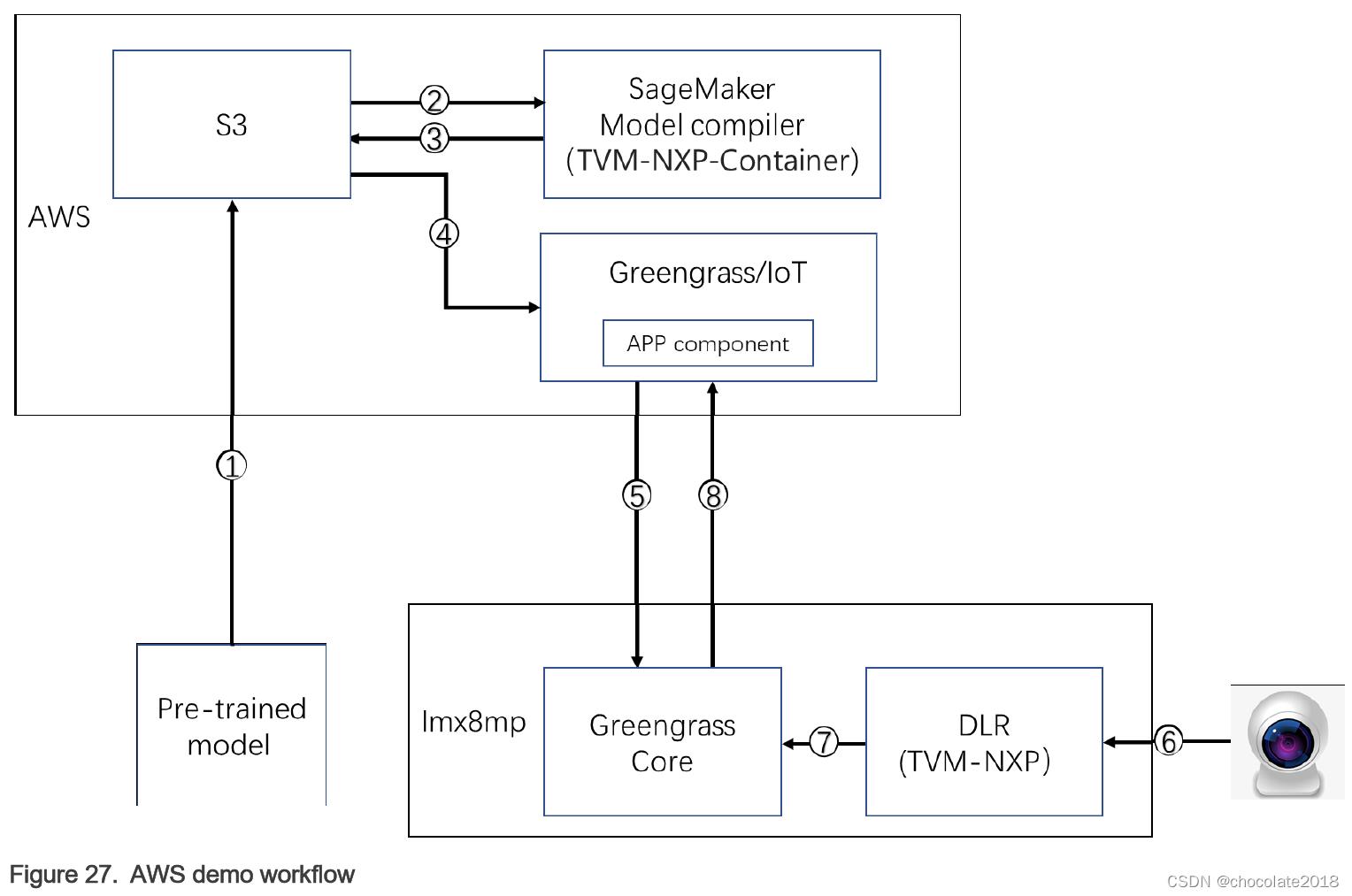
演示流程如下:
- 用户将预训练的模型上传到AWS S3。
- SageMaker模型编译器(NXP提供给AWS的容器)获取模型并为i.MX 8M Plus NPU编译二进制文件。
3.容器将二进制文件上传回S3。 - Greengrass/IoT将模型二进制和用户代码打包到APP组件中。
- Greengrass/IoT将APP组件部署到边缘设备(i.MX 8M Plus)。
- APP组件从摄像头获取图像。
- APP组件在DLR (NXP提供的TVM运行时)上运行模型。
- Greengrass Core将推断结果发送给AWS。
要求:
• NXP i.MX8MP-EVK BSP,内置AWS设备包
• 一个AWS帐户
• AWS帐户的证书和私钥
• 连接NXP i.MX8MP-EVK的USB摄像头
13.1.2开始
13.1.2.1构建BSP镜像
该构建基于AWS包和演示脚本:
• 按照i.MX Yocto项目用户指南(IMXLXYOCTOUG)设置项目
• 库初始化:
repo init -u https://source.codeaurora.org/external/imx/imx-manifest -b imx-linux-hardknott - m imx-5.10.72-2.2.0_aws.xml
repo sync
• 构建图像:
$ DISTRO=fsl-imx-wayland MACHINE=imx8mpevk source imx-aws-setup-release.sh -b build-imx8mp
$ bitbake imx-image-full
• 将镜像Flash到SD卡
$ sudo dd if=imx-image-full-imx8mpevk.wic of=/dev/xxxx
• 用这个SD卡启动主板
13.1.2.2 在设备上运行demo脚本
启动电路板后,可以在/usr/bin/dlr-demo-scripts文件夹下找到演示脚本。这些脚本可以操作云资源,并可以设置演示环境:
root@imx8mpevk:/usr/bin/dlr-demo-scripts# ls -l *.sh
00_setup_cloud_services.sh
01_create_greengrass_core.sh
02_create_greengrass_role.sh
03_upload_component_version.sh
04_create_device_fleet_register_device.sh
05_compile_and_package_neo_model.sh
06_create_greengrass_deployment.sh
07_setup_device_greengrass.sh
10_clean_up.sh setup_cloud_service_and_device.sh
在运行这些脚本之前,需要指定以下环境变量:
• 设置AWS密钥环境:
$ export AWS_ACCESS_KEY_ID="YOUR AWS ACCESS KEY ID"
$ export AWS_SECRET_ACCESS_KEY="YOUR AWS SECRET ACCESS KEY"
$ export AWS_SESSION_TOKEN="YOUR AWS SESSION TOKEN"
$ export AWS_REGION="us-west-2" #replace with your aws region
• 如果需要,可以设置ARN权限边界。您可以在AWS管理控制台->IAM->策略中找到它:
$ export PERMISSIONS_BOUNDARY="YOUR PERMISSIONS BOUNDARY ARN"
• 也可根据需要设置摄像头设备ID。默认值为3。
$ export CAMERA_DEVICE=3
• 设置PROJECT_NAME为一个唯一的字符串,只有小写字母:
$ export PROJECT_NAME=project_name
运行演示脚本:
$ cd /usr/bin/dlr-demo-scripts
$ ./setup_cloud_service_and_device.sh
13.1.2.3 检查推断结果
你可以用两种方式检查推断结果:
- 从设备的Greengrass日志文件中:
$ cd /greengrass/v2/logs $ tail -f aws.sagemaker.$project_name_edgeManagerClientCamera Integration.log stdout. 'index': '750', 'confidence': '0.4980392156862745', 'performance': '9.131669998168945', 'model_name': 'mobilenetv2-224-10-quant'. stdout. 'index': '831', 'confidence': '0.49411764705882355', 'performance': '15.126943588256836', 'model_name': 'mobilenetv2-224-10-quant'.
- 从云服务控制台:
导航到AWS IoT控制台->测试-> MQTT测试客户端(见下图)。在“订阅”菜单下,选择“em/inference”。每一秒,“em/inference”主题的推断结果都应该得到,并且包含结果和置信度。

13.1.2.4清理云环境
测试完成后,释放云资源,节省成本:
$ /usr/bin/dlr-demo-scripts/10_clean_up.sh
13.1.3额外的资源
有关AWS IoT Greengrass的详细信息,请参考以下链接:
• AWS IoT Greengrass: What is AWS IoT Greengrass? - AWS IoT Greengrass (amazon.com)
• SageMaker Edge Manager: SageMaker Edge Manager - Amazon SageMaker
• Greengrass sagemaker example: Greengrass-v2-sagemaker-edge-manager-python
• IAM & Permission boundary: Permission boundary
以上是关于无标题的主要内容,如果未能解决你的问题,请参考以下文章