无标题
Posted chocolate2018
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了无标题相关的知识,希望对你有一定的参考价值。
IMX8 图像使用 — 1
第一章 介绍
本文档的目的是提供关于图形api和驱动程序支持的信息。每一章都描述了一组特定的api或驱动集成,以及特定的硬件加速定制。本文的目标读者是编写图形应用程序或视频驱动程序的开发人员。
1.1 i.MX全GPU线
下表列出了所有的gpu。在i.MX 6单板上,只有6Quad和6QuadPlus支持OpenCL。OpenCL的关键性能指标GFLOPS的理论数量也显示在表格中。一些基准(如Clpeak)可以用来验证它。
i.MX 8QuadMax支持OpenVX,这将在下一章中介绍。
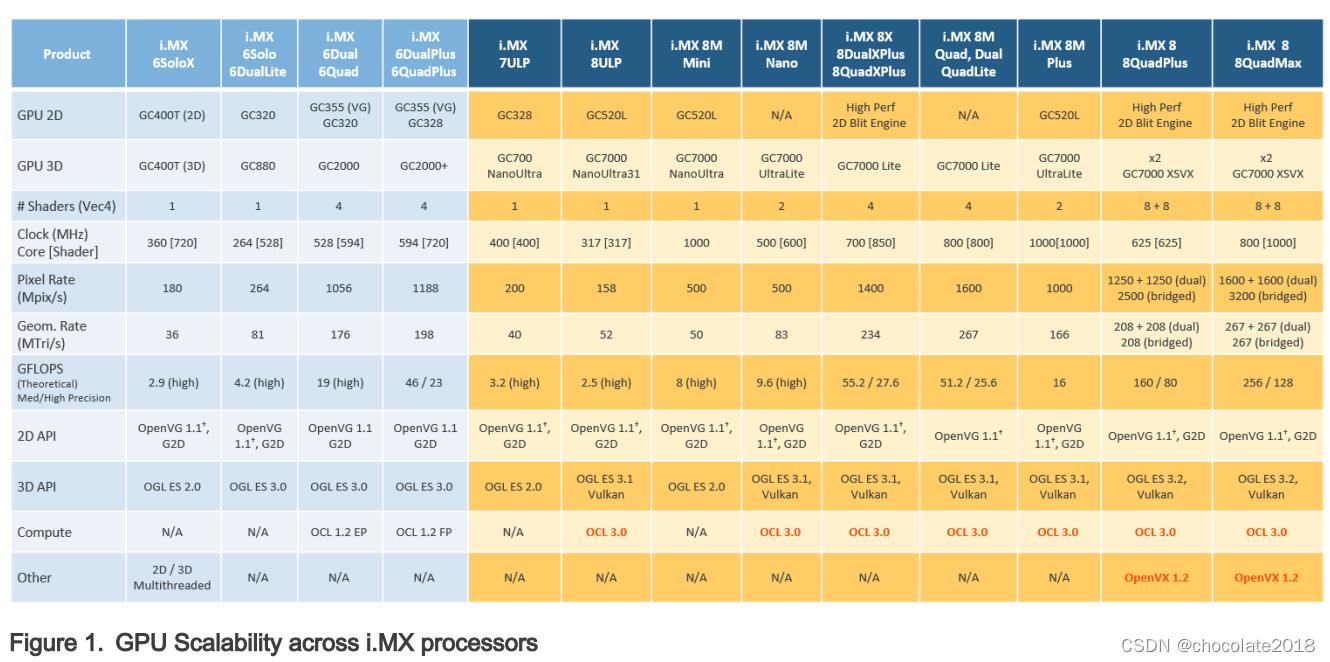
注意:3D GPU上的OpenVG与软件镶嵌
第二章 i.MX G2D API
2.1概述
API (G2D Application Programming Interface)是为便于理解和使用的BLT (2D Bit blit)功能而设计的。它允许用户使用简单的接口实现定制的应用程序。它是独立于硬件和平台的i.MX 2D图形。
G2D API支持以下特性,但不限于这些:
•简单的从源头到目的地的BLT操作
•16/32位RGB(alpha)和YUV颜色格式转换
•使用Porter-Duff规则混合源和目标
•从源到目的的高性能内存拷贝
•从源到目的的上下缩放
•从源到目的90/180/270度旋转
•从源到目的的水平和垂直翻转
•增强视觉质量与像素精度损失抖动()
•为目的地清除高性能内存
•源表面像素级裁剪
•仅对源进行全局alpha混合
•异步模式和同步模式
•连续内存分配器
•支持缓存内存()
•支持VG引擎()
•多源blit ()
注:带有(*)的特性在特定设备上可用。应用可以在G2D中查询可用特性。
G2D API文档包含详细的接口描述和示例代码,供参考。
该API采用C风格编码设计,可用于C和c++应用程序。
2.2枚举和结构
本章描述了G2D中所有的枚举和结构定义。
2.4 G2D支持新操作系统
G2D代码除了缓冲区分配外,与操作系统无关。为缓冲区分配内存的机制由不同的操作系统提供。分配的代码位于[G2D repository copy]/source/os/[os名称]中。
因此,支持新操作系统包括以下步骤:
- 在[G2D repository copy]/source/os/中创建一个新的文件夹,使用新的os名称,并根据新的os分配机制在包含的源代码中更新实现。
- 在为操作系统创建新的makefiles时,请包含新文件夹中的文件。
3.名为overlay_test的测试包含操作系统相关的代码。为了在本次测试中支持新的操作系统,在[G2D repository copy]/test/overlay_test/ OS中创建新的文件夹,并根据新的操作系统机制更新代码,用于显示初始化。还要更新makefiles以包含新文件夹中的代码。
第三章 i.MX EGL和OGL扩展支持
3.1介绍
下表列出了i.MX硬件和软件对EGL和OES扩展的支持级别。支持级别是截止文档日期的当前级别,并且可能会发生变化。
提供了两张表。第一个表列出了EGL接口扩展。第二个表列出了OpenGL ES 1.1、OpenGL ES 2.0和OpenGL ES 3.0的扩展。
关键:
分机名称和号码:每个列出的分机都来自相关的khronos.org网页列表,包括分机号码以及扩展的khronos描述的超链接。
•是:当前支持。
•No:不支持。(缺乏支持的原因可能各不相同:扩展可能是专有的或过时的,或不适用于指定的OES版本。)
•N/A:不提供支持,因为该扩展在本规范和后续版本中不适用。
第四章 i.MX Framebuffer API
4.1概述
该图形软件包括i.MX Framebuffer (FB) API,该API允许用户通过使用Framebuffer设备轻松创建和移植他们的图形应用程序,而不需要花费额外的精力处理平台相关的任务。i.MX Framebuffer API专注于提供控制显示、窗口和像素贴图呈现表面的机制。
EGL本机平台图形接口提供了创建客户端api可以绘制的渲染表面的机制,为客户端api创建图形上下文,并通过客户端api以及本机平台渲染api同步绘制。这使得使用Khronos api(如OpenGL ES和OpenVG)进行高性能、加速、混合模式的2D和3D渲染成为可能。关于EGL的更多信息,请参见www.khronos.org/registry/egl。本文档中描述的API与规范的EGL 1.4版本兼容。
支持以下平台:
•Linux®OS / X11
•android™平台
•Windows®Embedded Compact OS
•QNX®
注意:Linux操作系统上的i.MX 8支持直接渲染管理器(DRM),其中Linux framebuffer支持有限,推荐图形缓冲区管理器(GBM)。
第五章
OpenCL
5.1概述
5.1.1总则
OpenCL (Open Computing Language)是一种开放的行业标准应用程序编程接口(API),用于对包括gpu、cpu在内的多个设备以及组织为单个计算平台一部分的其他设备进行编程。OpenCL标准针对广泛的设备,从移动电话、平板电脑、pc和消费电子(CE)设备,一直到嵌入式应用程序,如汽车和图像处理功能。该API利用平台中的所有资源,充分利用所有计算能力,并有效地处理来自多个I/O(输入/输出)源的不断增长的复杂性数据流。I/O流可以是相机输入、图像、科学或数学数据,以及任何其他形式的可以利用数据或任务并行的复杂数据。
OpenCL使用gpu中的并行执行SIMD(单指令多数据)引擎,通过跨多个计算引擎对多个数据项执行大规模并行数据处理,从而提高数据的计算密度。每个计算单元都有自己的算术逻辑单元(ALUs),包括流水线浮点(FP)、整数(INT)单元和一个特殊的功能单元(SFU),它可以执行计算和超越操作。并行计算和相关的一系列操作被称为内核,GPU核心可以在任何给定的时间并行地在数千个工作项上执行一个内核。
在高层次上,OpenCL提供了支持并行编程的编程语言和框架。OpenCL包括api、库和一个运行时系统来帮助和支持软件开发。使用OpenCL,可以编写通用程序,可以直接在gpu上执行,而不需要知道图形架构的细节或使用3D图形api,如OpenGL或DirectX。OpenCL还提供了一个底层硬件抽象层(HAL)以及一个框架,该框架公开了底层硬件层的许多细节,从而允许程序员充分利用硬件。
有关OpenCL所有功能的更多详细信息,请参阅以下来自Khronos集团的规范:
•OpenCL 1.2规范
www.khronos.org/registry/cl/specs/opencl-1.2.pdf
•OpenCL 1.2 c++绑定规范
www.khronos.org/registry/cl/specs/opencl-cplusplus-1.2.pdf
5.1.2 OpenCL框架
OpenCL框架有两个主要部分,类似于OpenGL,主机C API和基于设备C的语言运行时。
OpenCL术语中的主机对应于OpenGL中的客户端,设备对应于服务器。设备程序被称为内核。OpenCL程序的执行之前是一系列API调用,用于配置系统和GPGPU执行。
OpenCL使用分层平台模型抽象了当今的异构架构。主机负责协调一个或多个计算设备上的执行和数据传输。计算设备由计算单元组成,每个计算单元包含一组处理元素。
5.1.2.1 OpenCL执行模型:内核和工作元素
OpenCL执行模型是由内核的执行方式定义的。当内核被提交给主机执行时,就定义了一个索引空间。这个索引空间中的每个点都执行一个内核实例。这个内核实例称为工作项。工作项通过它们在索引空间中的位置来标识,索引空间为工作项提供全局ID。每个工作项执行相同的代码,但是通过代码和操作的数据的特定路径因工作项而异。
工作项被组织到工作组中。工作组提供了更广泛的索引空间分解。每个工作组都被分配一个唯一的工作组ID,其维度与工作项使用的索引空间相同。工作项在工作组中被分配一个唯一的本地ID,这样单个工作项可以通过其全局ID或本地ID和工作组ID的组合来唯一地标识。给定工作组中的工作项在同一计算设备上并发执行。
OpenCL中支持的索引空间称为NDRange。NDRange是一个N维索引空间,其中N为1(1)、2(2)或3(3)。NDRange由长度为N的整数数组定义,指定从偏移索引F(默认为0)开始的每个维度的索引空间范围。每个工作项的全局ID和本地ID都是n维元组。全局ID组件的值范围从F到F加上该维度中的元素数减1。
使用与工作项全局id类似的方法为工作组分配id。长度为N的数组定义了每个维度中工作组的数量。将工作项分配给一个工作组,并给出一个本地ID,其中的组件范围从0到该维度中工作组的大小减去1。因此,工作组ID和工作组中的local-ID唯一地定义了一个工作项。每个工作项可以通过两种方式进行标识;就全局索引而言,它在整个内核索引空间中都是唯一的,就本地索引而言,它在工作组中也是唯一的。
5.1.2.2 OpenCL命令队列
OpenCL同时提供任务并行和数据并行。数据移动是通过命令队列来协调的,命令队列提供了一种通用的方法来指定遵守计算中的依赖性的任务间关系和任务执行顺序。OpenCL可以并行执行多个任务,如果它们不依赖于顺序的话。任务是由数据并行内核组成的,类似于着色器,将单个函数并行应用于一系列元素。在内核执行期间,只允许有限制的同步和通信。
OpenCL内核在1、2或3维索引空间上执行。所有工作项执行相同的程序(内核),但是它们的执行可能会发生分歧,分支依赖于数据或它们的索引。关于索引空间中允许多少个工作组的详细信息,请参阅“Using clEnqueueNDRangeKernel”。
内核或内存操作首先进入命令队列。内核是异步执行的,主机应用程序可以在队列操作之后继续执行。应用程序可能选择等待一个操作完成,并且一个操作(内核或内存)可能被标记为在执行之前必须发生的事件列表。
事件是内核完成和内存操作。OpenCL遍历一个队列中内核和内存传输之间的依赖关系图,确保正确的执行顺序。可以构造多个命令队列,进一步增强了跨平台和多计算设备的并行控制。
•命令队列屏障用于控制命令队列中的命令。命令队列屏障指示在继续之前必须完成哪些命令。这允许无序的命令处理。命令队列屏障确保所有先前进入队列的命令在以下任何命令开始执行之前完成执行。
第六章 OpenVX介绍
6.1概述
OpenVX是一个底层编程框架领域,使软件开发人员能够高效地访问计算机视觉硬件加速,同时具有功能和性能的可移植性。OpenVX被设计为支持现代硬件架构,如移动和嵌入式soc以及桌面系统。这些系统中有许多是并行和异构的:包含多种处理器类型,包括多核cpu、DSP子系统、gpu、专用视觉计算结构以及硬连线功能。此外,视觉系统内存层次结构通常是复杂的、分布式的,并且不是完全一致的。OpenVX旨在最大化这些不同硬件平台的功能和性能可移植性,提供一个计算机视觉框架,有效地解决当前和未来的硬件架构,对应用程序的影响最小。
OpenVX定义了一个C应用程序编程接口(API),用于构建、验证和协调图的执行,以及访问内存对象。图抽象使OpenVX实现者能够针对底层的加速架构优化图的执行。
OpenVX还定义了vxu实用程序库,它将OpenVX预定义的每个函数公开为一个可直接调用的C函数,而不需要首先创建一个图。使用vxu库构建的应用程序不能从图的优化中受益;然而,vxu库可以作为使用OpenVX的最简单方式,以及移植现有的视觉应用程序的第一步。
有关使用OpenVX编程的更多详细信息,请参阅以下来自Khronos Group的规范,OpenVX规范(https://www.khronos.org/registry/vx)。
6.2 OpenVX扩展实现
VeriSilicon的视觉成像VX扩展为视觉图像处理提供了通过Khronos集团OpenVX API提供的功能之外的额外功能。这些增强利用了VeriSilicon的可视化硬件中提供的增强的可视化功能。VeriSilicon软件提供了一组扩展,该扩展与OpenCL 1.2接口,并支持VeriSilicon自定义EVIS(增强视觉指令集)的更高级别C语言编程。
VeriSilicon VX扩展和增强包括三个主要组件:
•一个API级接口到EVIS(增强视觉指令集)
•视觉处理的扩展C语言特性
•支持一个与vision兼容的OpenCL内置函数子集
6.2.1硬件需求
视觉成像硬件能力需要支持完整的OpenVX。支持以下配置:
•GC7000XSVX (i.MX 8QuadMax)
•VIP8000NanoSI (i.m x8m Plus)
6.2.2 EVIS指令接口
Vivante的视觉成像能力IP具有增强视觉指令集(EVIS),增强GPU或视觉图像处理器(Vision Image Processor)处理复杂视觉操作的能力。一条EVIS指令可以完成可能需要几十条甚至数百条正常ISA指令才能完成的任务。
下表显示了作为Intrinsic调用支持的指令。
第七章 Vulkan
7.1概述
Vulkan是新一代图形和计算API,提供高效、跨平台的现代gpu访问,用于从pc、控制台到移动电话和嵌入式平台的各种设备。
Vulkan定义为图形和计算硬件的API(应用程序编程接口)。该API包含许多命令,允许程序员指定着色程序、计算内核、对象和生成高质量图形图像(特别是三维对象的彩色图像)所涉及的操作。
对于程序员来说,Vulkan是一组命令,它允许对着色程序或着色器、内核、内核或着色器使用的数据,以及在着色器范围之外的Vulkan状态控制方面的规范。通常,数据代表二维或三维的几何图形和纹理图像,而着色器和内核控制数据的处理、几何图形的栅格化,以及栅格化生成的碎片的光照和着色,从而将几何图形渲染到framebuffer中。
一个典型的Vulkan程序开始于特定于平台的调用,以打开窗口或准备一个显示设备,程序将在其上绘制。然后,调用打开提交命令缓冲区的队列。命令缓冲区包含底层硬件将要执行的命令列表。应用程序还可以分配设备内存,将资源与内存关联,并从命令缓冲区中引用这些资源。绘制命令导致应用程序定义的着色程序被调用,然后可以使用资源中的数据并使用它们产生图形图像。
要显示生成的图像,需要执行进一步的平台特定命令,将生成的图像传输到显示设备或窗口。
有关使用Vulkan编程的更多细节,请参阅以下来自Khronos Group的规范。
https://www.khronos.org/registry/vulkan/
7.2 vvante扩展支持Vulkan
下表列出了当前所有的Vulkan扩展,并指出了它们在Vivante软件中的支持级别。
(名单来自https://www.khronos.org/registry/vulkan/,截止2020年6月1日)
7.3 Vulkan验证层
Vulkan是一个显式API,可以直接控制gpu的工作方式。根据设计,最小的错误检查是在Vulkan驱动器内完成的。应用程序有充分的控制和责任,正确的操作。使用Vulkan的任何错误都可能导致坠机。Vulkan验证层可以帮助开发人员验证他们的应用程序正确使用Vulkan API。
7.4与windows系统集成
Vulkan依靠一种新的机制与本机窗口系统进行交互,并将呈现的结果呈现给用户。
这种机制被称为窗口系统集成(Window System Integration),是通过核心API之外的扩展提供的。
在启用Vulkan的i.MX BSPs中,默认的窗口管理器是Weston,一个Wayland合成引用实现。
在为Wayland编译Vulkan应用程序时,请确保定义了VK_USE_PLATFORM_WAYLAND_KHR符号,以便启用所有正确的包含和代码路径。
GLFW和SDL可以管理表面的创建和适当的扩展初始化,但当一个应用程序是新开发的,不使用任何框架,需要启用以下实例扩展:
VK_KHR_SURFACE_EXTENSION_NAME
VK_KHR_WAYLAND_SURFACE_EXTENSION_NAME
一旦有了到Wayland服务器的显示连接并创建了一个曲面,然后开始使用wl_display和wl_surface指针来填充vkCreateWaylandSurfaceKHR所需的信息结构。
在创建交换链之前,当使用vkGetPhysicalDeviceSurfaceCapabilitiesKHR查询物理设备表面能力时,当前的区段宽度和高度将返回0xFFFFFFFF的值,确保在代码中添加对此的检查,当发生这种情况时,将交换链区段设置为要渲染的表面的实际大小,或者设置回退区段大小。
第八章 多gpu和虚拟化
8.1概述
Vivante多gpu实现提供了多种功能,可以通过硬件和软件控制来管理。本章旨在总结用于Vivante多gpu IP实现的软件控件。
在i.m x8quadmax和衍生设备上可以使用双GC7000XSVX来启用多gpu特性。
8.2 Multi-GPU配置
Vivante Multi-GPU IP可以通过软件配置为以下行为模型之一:
•组合模式,在多GPU设计中两个(或更多)GPU核心协同工作。驱动程序将多GPU作为单个逻辑GPU呈现给SW应用程序。多个gpu工作在同一个虚拟地址空间,共享同一个MMU页表。多个gpu获取并执行一个共享的命令缓冲区。
•独立模式,在多GPU设计中,每个GPU独立运行。多个gpu工作在不同的虚拟地址空间,但共享相同的MMU页表。每个GPU核心获取并执行自己的命令缓冲区。这使得不同的SW应用程序可以同时运行在不同的GPU核心上。
•OpenCL API允许应用程序直接处理多GPU独立模式,因为在多GPU设计中每个GPU核心代表一个独立的OpenCL计算设备。
8.3 GPU亲和性配置
在多GPU独立模式下,应用程序可以通过环境变量VIV_MGPU_AFFINITY指定运行在多个GPU中的特定GPU上。一旦指定了应用程序的GPU亲和性,该应用程序将只在指定的GPU上运行,并且不会迁移到其他GPU上,即使这些GPU处于空闲状态。
VIV_MGPU_AFFINITY环境变量,用于在多GPU平台上控制应用的GPU亲和性。不管这个变量是如何设置的,客户端驱动程序都会假设他们通过一个gcoHARDWARE对象使用一个独立的GPU。环境变量VIV_MGPU_AFFINITY的可能值包括:
•未定义或
•定义为“0”gcoHARDWARE对象工作在gcvMULTI_GPU_COMBINED模式(默认)
-“1:0”gcoHARDWARE对象工作在gcvMULTI_GPU_INDEPENDENT模式下,使用GPU0
—“1:1”gcoHARDWARE对象工作在gcvMULTI_GPU_INDEPENDENT模式下,使用GPU1
在单个GPU设备上,将VIV_MGPU_AFFINITY设置为0或1不会产生任何影响,因为所有应用进程/线程都绑定到GPU0。但是如果VIV_MGPU_AFFINITY设置为“1:1”(驱动报告错误),应用程序将无法进行GPU上下文初始化。
8.4多gpu设备上的OpenCL
OpenCL驱动工作在桥接模式下,作为单个逻辑计算设备。在这种配置中,设备中的多个gpu作为单独的OpenCL计算设备运行。OpenCL应用程序负责分配和调度计算任务到每个GPU(计算设备)。
下面的OpenCL api返回平台上可用的计算设备列表,以及设备信息。
cl_int clgetdeviceid (cl_platform_id platform, cl_device_type device_type, cl_uint num_entries,
cl_device_id *devices, cl_uint *num_devices)
cl_int clGetDeviceInfo (cl_device_id device, cl_device_info param_name, size_t param_value_size,
void *param_value, size_t *param_value_size_ret)
8.5 GPU虚拟化配置
Multi-GPU也可以在不同的操作系统上作为独立模式单独使用,这可以通过覆盖不同操作系统实现的irq可用性n DTS条目来配置,在arch/arm64/boot/ DTS /freescale/fsl-imx8qmxxx.dts中。
Guest OS 1(仅限GPU0)
&gpu_3d1
status = "disable";
;
Guest OS 2(仅限GPU1)
&gpu_3d0
status = "disable";
;
以上是关于无标题的主要内容,如果未能解决你的问题,请参考以下文章