LevelDB 源码剖析WAL模块:LOG 结构读写流程崩溃恢复
Posted 凌桓丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LevelDB 源码剖析WAL模块:LOG 结构读写流程崩溃恢复相关的知识,希望对你有一定的参考价值。
文章目录
当向 LevelDB 写入数据时,只需要将数据写入内存中的 MemTable,而由于内存是易失性存储,因此 LevelDB 需要一个额外的持久化文件:预写日志(Write-Ahead Log,WAL),又称重做日志。这是一个追加修改、顺序写入磁盘的文件。当宕机或者程序崩溃时 WAL 能够保证写入成功的数据不会丢失。将 MemTable 成功写入 SSTable 后,相应的预写日志就可以删除了。
日志结构
Log 文件以块为基本单位,一条记录可能全部写到一个块上,也可能跨几个块。记录的格式如下图所示:
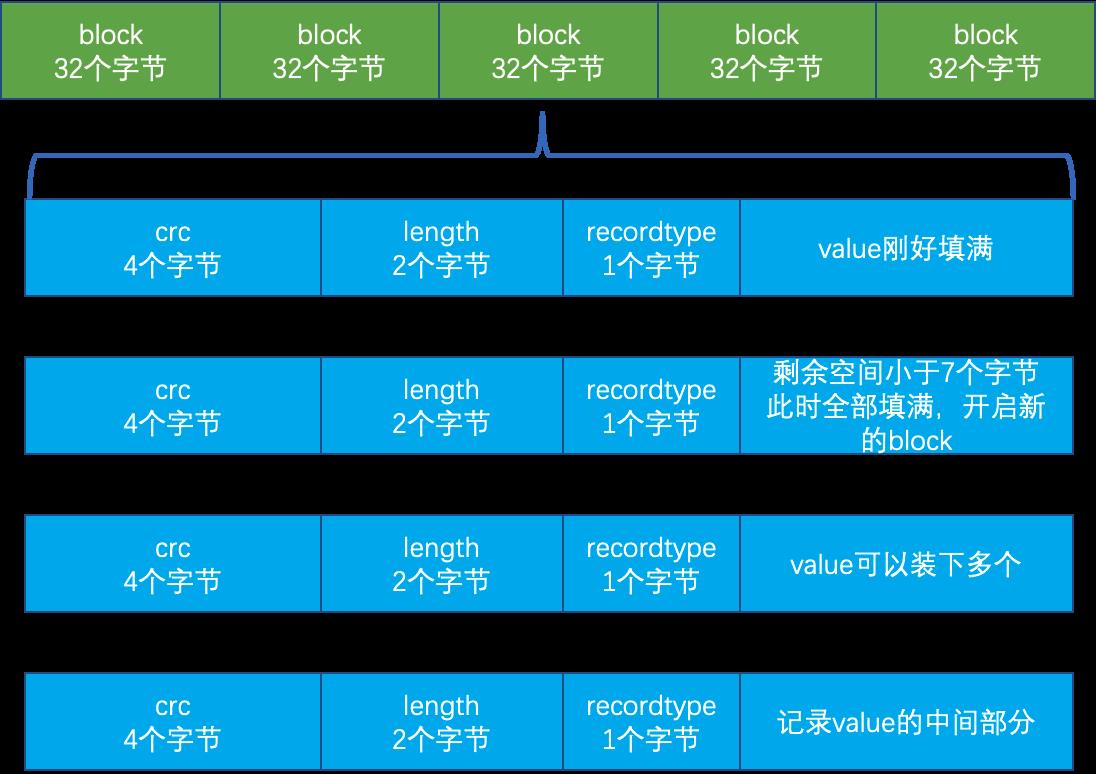
首先我们来看看 Log 中的数据格式,代码如下:
// https://github.com/google/leveldb/blob/master/db/log_format.h
namespace log
enum RecordType
// Zero is reserved for preallocated files
kZeroType = 0,
kFullType = 1,
// For fragments
kFirstType = 2,
kMiddleType = 3,
kLastType = 4
;
static const int kMaxRecordType = kLastType;
static const int kBlockSize = 32768;
// Header is checksum (4 bytes), length (2 bytes), type (1 byte).
static const int kHeaderSize = 4 + 2 + 1;
// namespace log
结合上面的代码和图片,我们可以看到每一个块大小为 32768 字节,并且每一个块由头部和正文组成。头部由 4 字节校验,2 字节的长度与 1 字节的类型构成,即每一个块的开始 7 字节属于头部。头部中的类型字段有如下 4 种:
- kZeroType:为预分配的文件保留。
- kFullType:表示一条记录完整地写到了一个块上。
- kFirstType:表示该条记录的第一部分。
- kMiddleType:表示该条记录的中间部分。
- kLastType:表示该条记录的最后一部分。
通过记录结构可以推测出 Log 文件的读取流程,即首先根据头部的长度字段确定需要读取多少字节,然后根据头部类型字段确定该条记录是否已经完整读取,如果没有完整读取,继续按该流程进行,直到读取到记录的最后一部分,其头部类型为 kLastType。
读写流程
写入
Log 的读取主要由 Writer 中的 AddRecord 实现,代码如下:
// https://github.com/google/leveldb/blob/master/db/log_writer.h
class Writer
public:
explicit Writer(WritableFile* dest);
Writer(WritableFile* dest, uint64_t dest_length);
Writer(const Writer&) = delete;
Writer& operator=(const Writer&) = delete;
~Writer();
Status AddRecord(const Slice& slice);
private:
Status EmitPhysicalRecord(RecordType type, const char* ptr, size_t length);
WritableFile* dest_;
int block_offset_; // Current offset in block
uint32_t type_crc_[kMaxRecordType + 1];
;
// https://github.com/google/leveldb/blob/master/db/log_writer.cc
Status Writer::AddRecord(const Slice& slice)
const char* ptr = slice.data();
size_t left = slice.size();
Status s;
//begin表明本条记录是第一次写入,即当前块中第一条记录
bool begin = true;
do
//当前块剩余空间,用于判断头部能否完整写入
const int leftover = kBlockSize - block_offset_;
assert(leftover >= 0);
if (leftover < kHeaderSize)
//如果块剩余空间小于七个字节且不等于0,说明当前无法完整写入数据,此时填充\\x00,从下一个块写入
if (leftover > 0)
static_assert(kHeaderSize == 7, "");
dest_->Append(Slice("\\x00\\x00\\x00\\x00\\x00\\x00", leftover));
//此时块正好写满,将block_offset_置为0,表明开始写入新的块
block_offset_ = 0;
assert(kBlockSize - block_offset_ - kHeaderSize >= 0);
//计算块剩余空间
const size_t avail = kBlockSize - block_offset_ - kHeaderSize;
//计算当前块能够写入的数据大小(块剩余空间和记录剩余内容中最小的)
const size_t fragment_length = (left < avail) ? left : avail;
RecordType type;
//end表明该记录是否已经完整写入,即最后一条记录
const bool end = (left == fragment_length);
//根据begin与end来确定记录类型
if (begin && end)
//记录为第一条且同时又是最后一条,说明当前是完整的记录,状态为kFullType
type = kFullType;
else if (begin)
//记录为第一条,状态为kFirstType
type = kFirstType;
else if (end)
//记录为最后一条,标记状态为kLastType
type = kLastType;
else
//记录不为第一条,也并非最后一条,则说明是中间状态,标记为kMiddleType
type = kMiddleType;
//将数据按照格式写入,并刷新到磁盘文件中
s = EmitPhysicalRecord(type, ptr, fragment_length);
ptr += fragment_length;
left -= fragment_length;
begin = false;
while (s.ok() && left > 0);
//循环至数据完全写入或者写入失败时才停止
return s;
写入流程如下:
- 判断头部能否完整写入,如果不能则将剩余空间用
\\x00填充,接着从新的块开始写入。 - 根据 begin 和 end 判断记录类型。
- 将数据按照格式写入,并刷新到磁盘文件中。
- 循环至数据完全写入或者写入失败后停止,将结果返回。
读取
Log 的读取主要由 Reader 中的 ReadRecord 实现,代码如下:
// https://github.com/google/leveldb/blob/master/db/log_reader.h
class Reader
public:
// Interface for reporting errors.
class Reporter
public:
virtual ~Reporter();
virtual void Corruption(size_t bytes, const Status& status) = 0;
;
Reader(SequentialFile* file, Reporter* reporter, bool checksum,
uint64_t initial_offset);
Reader(const Reader&) = delete;
Reader& operator=(const Reader&) = delete;
~Reader();
bool ReadRecord(Slice* record, std::string* scratch);
uint64_t LastRecordOffset();
private:
enum
kEof = kMaxRecordType + 1,
kBadRecord = kMaxRecordType + 2
;
;
// https://github.com/google/leveldb/blob/master/db/log_reader.cc
bool Reader::ReadRecord(Slice* record, std::string* scratch)
if (last_record_offset_ < initial_offset_)
if (!SkipToInitialBlock())
return false;
scratch->clear();
record->clear();
bool in_fragmented_record = false;
uint64_t prospective_record_offset = 0;
Slice fragment;
while (true)
//ReadPhysicalRecord读取log文件并将记录保存到fragment,同时返回记录的类型
const unsigned int record_type = ReadPhysicalRecord(&fragment);
uint64_t physical_record_offset =
end_of_buffer_offset_ - buffer_.size() - kHeaderSize - fragment.size();
if (resyncing_)
if (record_type == kMiddleType)
continue;
else if (record_type == kLastType)
resyncing_ = false;
continue;
else
resyncing_ = false;
//根据记录的类型来判断是否需要将当前记录附加到scratch后并继续读取
switch (record_type)
//类型为kFullType则说明当前是完整的记录,直接赋值给record后返回
case kFullType:
if (in_fragmented_record)
if (!scratch->empty())
ReportCorruption(scratch->size(), "partial record without end(1)");
prospective_record_offset = physical_record_offset;
scratch->clear();
*record = fragment;
last_record_offset_ = prospective_record_offset;
return true;
//类型为kFirstType则说明当前是第一部分,先将记录复制到scratch后继续读取
case kFirstType:
if (in_fragmented_record)
if (!scratch->empty())
ReportCorruption(scratch->size(), "partial record without end(2)");
prospective_record_offset = physical_record_offset;
scratch->assign(fragment.data(), fragment.size());
in_fragmented_record = true;
break;
//类型为kMiddleType则说明当前是中间部分,先将记录追加到scratch后继续读取
case kMiddleType:
//初始读取到的类型为kMiddleType或者kLastType,则需要忽略并且继续偏移
if (!in_fragmented_record)
ReportCorruption(fragment.size(),
"missing start of fragmented record(1)");
else
scratch->append(fragment.data(), fragment.size());
break;
//类型为kLastType则说明当前为最后,继续追加到scratch,并将scratch赋值给record并返回
case kLastType:
if (!in_fragmented_record)
ReportCorruption(fragment.size(),
"missing start of fragmented record(2)");
else
scratch->append(fragment.data(), fragment.size());
*record = Slice(*scratch);
last_record_offset_ = prospective_record_offset;
return true;
break;
//如果状态为kEof、kBadRecord时说明日志损坏,此时清空scratch并返回false
case kEof:
if (in_fragmented_record)
scratch->clear();
return false;
case kBadRecord:
if (in_fragmented_record)
ReportCorruption(scratch->size(), "error in middle of record");
in_fragmented_record = false;
scratch->clear();
break;
//未定义的类型,输出日志,剩余同上处理
default:
char buf[40];
std::snprintf(buf, sizeof(buf), "unknown record type %u", record_type);
ReportCorruption(
(fragment.size() + (in_fragmented_record ? scratch->size() : 0)),
buf);
in_fragmented_record = false;
scratch->clear();
break;
return false;
执行流程如下:
- ReadRecord 读取一条记录到 fragment 变量中,并且返回该条记录的类型。
- 根据记录的类型来判断是否需要将当前记录附加到 scratch 后并继续读取:
- kFullType:当前是完整的记录,直接赋值给 record 后返回。
- kFirstType:当前是第一部分,先将记录覆盖到 scratch 后继续读取。
- kMiddleType:当前是中间部分,先将记录追加到 scratch 后继续读取。
- kLastType:当前为最后部分,继续追加到 scratch,并将完整的 scratch 赋值给 record 后返回。
- 其它/异常:清空 scratch 并返回 false,如果是未定义类型需要输出日志。
这里还有一个需要注意的细节,由于读取 Log 文件时可以从指定偏移量开始,所以如果初始读取到的类型为 kMiddleType 或者 kLastType,则需要忽略并且继续偏移,直到碰见第一个 kFirstType。
崩溃恢复
当打开一个 LevelDB 的数据文件时,需先检验是否进行崩溃恢复,如果需要,则会从 Log 文件生成一个MemTable,其实现代码如下:
// https://github.com/google/leveldb/blob/master/db/db_impl.cc
Status DBImpl::RecoverLogFile(uint64_t log_number, bool last_log,
bool* save_manifest, VersionEdit* edit,
SequenceNumber* max_sequence)
struct LogReporter : public log::Reader::Reporter
Env* env;
Logger* info_log;
const char* fname;
Status* status; // null if options_.paranoid_checks==false
void Corruption(size_t bytes, const Status& s) override
Log(info_log, "%s%s: dropping %d bytes; %s",
(this->status == nullptr ? "(ignoring error) " : ""), fname,
static_cast<int>(bytes), s.ToString().c_str());
if (this->status != nullptr && this->status->ok()) *this->status = s;
;
mutex_.AssertHeld();
//打开log文件
std::string fname = LogFileName(dbname_, log_number);
SequentialFile* file;
Status status = env_->NewSequentialFile(fname, &file);
if (!status.ok())
MaybeIgnoreError(&status);
return status;
//创建log reader.
LogReporter reporter;
reporter.env = env_;
reporter.info_log = options_.info_log;
reporter.fname = fname.c_str();
reporter.status = (options_.paranoid_checks ? &status : nullptr);
log::Reader reader(file, &reporter, true /*checksum*/, 0 /*initial_offset*/);
Log(options_.info_log, "Recovering log #%llu",
(unsigned long long)log_number);
//读取所有的records并写入一个memtable
std::string scratch;
Slice record;
WriteBatch batch;
int compactions = 0;
MemTable* mem = nullptr;
//循环读取日志文件
while (reader.ReadRecord(&record, &scratch) && status.ok())
if (record.size() < 12)
reporter.Corruption(record.size(),
Status::Corruption("log record too small"));
continue;
WriteBatchInternal::SetContents(&batch, record);
if (mem == nullptr)
mem = new MemTable(internal_comparator_);
mem->Ref();
//将records写入memtable
status = WriteBatchInternal::InsertInto(&batch, mem);
MaybeIgnoreError(&status);
if (!status.ok())
break;
const SequenceNumber last_seq = WriteBatchInternal::Sequence(&batch) +
WriteBatchInternal::Count(&batch) - 1;
if (last_seq > *max_sequence)
*max_sequence = last_seq;
//如果memtable大于阈值,则将其转换成sstable(默认4MB)
if (mem->ApproximateMemoryUsage() > options_.write_buffer_size)
compactions++;
*save_manifest = true;
status = WriteLevel0Table(mem, edit, nullptr);
mem->Unref();
mem = nullptr;
if (!status.ok())
break;
delete file;
//判断是否应该继续重复使用最后一个日志文件
if (status.ok() && options_.reuse_logs && last_log && compactions == 0)
assert(logfile_ == nullptr);
assert(log_ == nullptr);
assert(mem_ == nullptr);
uint64_t lfile_size;
if (env_->GetFileSize(fname, &lfile_size).ok() &&
env_->NewAppendableFile(fname, &logfile_).ok())
Log(options_.info_log, "Reusing old log %s \\n", fname.c_str());
log_ = new log::Writer(logfile_, lfile_size);
logfile_number_ = log_number;
if (mem