POI读写大数据量EXCEL
Posted tootwo2
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了POI读写大数据量EXCEL相关的知识,希望对你有一定的参考价值。
另一篇文章http://www.cnblogs.com/tootwo2/p/8120053.html里面有xml的一些解释。
大数据量的excel一般都是.xlsx格式的,网上使用POI读写的例子比较多,但是很少提到读写非常大数据量的excel的例子,POI官网上提到XSSF有三种读写excel,POI地址:http://poi.apache.org/spreadsheet/index.html。官网的图片:
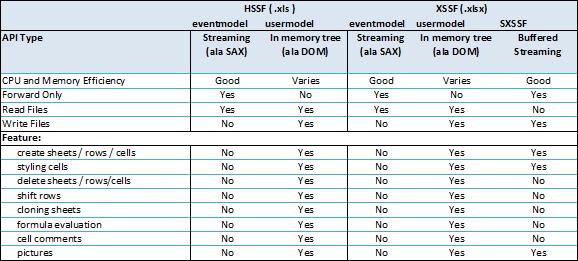
可以看到有三种模式:
1、eventmodel方式,基于事件驱动,SAX的方式解析excel(.xlsx是基于OOXML的),CPU和内存消耗非常低,但是只能读不能写
2、usermodel,就是我们一般使用的方式,这种方式可以读可以写,但是CPU和内存消耗非常大
3、SXSSF,POI3.8以后开始支持,这种方式只能写excel
下面介绍下使用方式(官网地址:http://poi.apache.org/spreadsheet/how-to.html):
第一种方式:
pom文件需要添加依赖:
<dependency> <groupId>org.apache.poi</groupId> <artifactId>poi-ooxml</artifactId> <version>3.15</version> </dependency> <dependency> <groupId>xerces</groupId> <artifactId>xerces</artifactId> <version>2.4.0</version> </dependency>
java官网示例代码:
package excel; import java.io.InputStream; import java.util.Iterator; import org.apache.poi.xssf.eventusermodel.XSSFReader; import org.apache.poi.xssf.model.SharedStringsTable; import org.apache.poi.xssf.usermodel.XSSFRichTextString; import org.apache.poi.openxml4j.opc.OPCPackage; import org.xml.sax.Attributes; import org.xml.sax.ContentHandler; import org.xml.sax.InputSource; import org.xml.sax.SAXException; import org.xml.sax.XMLReader; import org.xml.sax.helpers.DefaultHandler; import org.xml.sax.helpers.XMLReaderFactory; public class ExampleEventUserModel { public void processOneSheet(String filename) throws Exception { OPCPackage pkg = OPCPackage.open(filename); XSSFReader r = new XSSFReader( pkg ); SharedStringsTable sst = r.getSharedStringsTable(); XMLReader parser = fetchSheetParser(sst); // To look up the Sheet Name / Sheet Order / rID, // you need to process the core Workbook stream. // Normally it\'s of the form rId# or rSheet# InputStream sheet2 = r.getSheet("rId2"); InputSource sheetSource = new InputSource(sheet2); parser.parse(sheetSource); sheet2.close(); } public void processAllSheets(String filename) throws Exception { OPCPackage pkg = OPCPackage.open(filename); XSSFReader r = new XSSFReader( pkg ); SharedStringsTable sst = r.getSharedStringsTable(); XMLReader parser = fetchSheetParser(sst); Iterator<InputStream> sheets = r.getSheetsData(); while(sheets.hasNext()) { System.out.println("Processing new sheet:\\n"); InputStream sheet = sheets.next(); InputSource sheetSource = new InputSource(sheet); parser.parse(sheetSource); sheet.close(); System.out.println(""); } } public XMLReader fetchSheetParser(SharedStringsTable sst) throws SAXException { XMLReader parser = XMLReaderFactory.createXMLReader( "com.sun.org.apache.xerces.internal.parsers.SAXParser" ); ContentHandler handler = new SheetHandler(sst); parser.setContentHandler(handler); return parser; } /** * See org.xml.sax.helpers.DefaultHandler javadocs */ private static class SheetHandler extends DefaultHandler { private SharedStringsTable sst; private String lastContents; private boolean nextIsString; private SheetHandler(SharedStringsTable sst) { this.sst = sst; } public void startElement(String uri, String localName, String name, Attributes attributes) throws SAXException { // c => cell if(name.equals("c")) { // Print the cell reference System.out.print(attributes.getValue("r") + " - "); // Figure out if the value is an index in the SST String cellType = attributes.getValue("t"); if(cellType != null && cellType.equals("s")) { nextIsString = true; } else { nextIsString = false; } } // Clear contents cache lastContents = ""; } public void endElement(String uri, String localName, String name) throws SAXException { // Process the last contents as required. // Do now, as characters() may be called more than once if(nextIsString) { int idx = Integer.parseInt(lastContents); lastContents = new XSSFRichTextString(sst.getEntryAt(idx)).toString(); nextIsString = false; } // v => contents of a cell // Output after we\'ve seen the string contents if(name.equals("v")) { System.out.println(lastContents); } } public void characters(char[] ch, int start, int length) throws SAXException { lastContents += new String(ch, start, length); } } public static void main(String[] args) throws Exception { ExampleEventUserModel example = new ExampleEventUserModel(); System.out.println("11"); example.processOneSheet(args[0]); example.processAllSheets(args[0]); } }
运行的时候使用本地的文件地址替代main函数里面的参数就可以运行(亲测可以)。
第三种方式:
其核心是减少存储在内存当中的数据,达到一定行数就存储到硬盘的临时文件中。
pom文件需要增加依赖:
<dependency> <groupId>xerces</groupId> <artifactId>xercesImpl</artifactId> <version>2.11.0</version> </dependency>
java代码如下:
package excel; //import junit.framework.Assert; import java.io.FileOutputStream; import org.apache.poi.ss.usermodel.Cell; import org.apache.poi.ss.usermodel.Row; import org.apache.poi.ss.usermodel.Sheet; import org.apache.poi.ss.usermodel.Workbook; import org.apache.poi.ss.util.CellReference; import org.apache.poi.xssf.streaming.SXSSFWorkbook; public class SXSSFDemo { public static void main(String[] args) throws Throwable { SXSSFWorkbook wb = new SXSSFWorkbook(100); // 在内存当中保持 100 行 , 超过的数据放到硬盘中 Sheet sh = wb.createSheet(); for(int rownum = 0; rownum < 10000; rownum++){ Row row = sh.createRow(rownum); for(int cellnum = 0; cellnum < 10; cellnum++){ Cell cell = row.createCell(cellnum); String address = new CellReference(cell).formatAsString(); cell.setCellValue(address); } } FileOutputStream out = new FileOutputStream("/Users/tootwo2/Documents/sxssf.xlsx"); wb.write(out); out.close(); // dispose of temporary files backing this workbook on disk wb.dispose(); } }
以上是关于POI读写大数据量EXCEL的主要内容,如果未能解决你的问题,请参考以下文章