云原生灾备产品HyperBDR自动化测试实践
Posted 孙琦Ray
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了云原生灾备产品HyperBDR自动化测试实践相关的知识,希望对你有一定的参考价值。
HyperBDR是一款基于云原生理念的迁移和容灾产品,核心的业务场景是将源端以块级别差量方式同步至云原生存储中,目前已经实现对块存储和对象存储支持,最后再利用Boot-in-Cloud专利技术将业务系统一键式恢复至可用状态,真正做到了对云原生编排能力的充分利用,满足迁移和灾备等业务场景的不同需求。
HyperBDR目前已经支持的源端操作系统大版本就将近10个(Windows/CentOS/Redhat/Ubuntu/SUSE/国产化操作系统),小版本更是超过几百个,而在目标目标云平台也陆续支持了将近40个(公有云、专有云、私有云、超融合、虚拟化等),并且数量还在增加。假设我们将源端的操作系统到全部云平台进行一次覆盖性测试,组合的测试用例可能超过10000个。
这么大规模的情况下想做到测试覆盖,单纯依靠人力显然不现实,必须引入自动化测试手段对核心业务场景进行测试,这样不仅可以满足自动化测试的需要,也可以在日常开发过程中及时让开发人员在新开发功能中对核心流程的影响,进一步提升产品的稳定性和可靠性。
痛点分析
我们先来看一下手工测试情况下,HyperBDR产品测试的几个痛点:
痛点一、测试用例多,人力资源不足
在上述源端和目标端的规模情况下,即使做一些基本冒烟,一次完整的测试的场景用例也依然有一百多种。例如:
-
源端(19种):CentOS(6/7/8)、Redhat(6/7/8)、SUSE(11/12)、Ubuntu(14.04/16.04/18.04/20.04)、Windows(2003/2008/2012/2016/2019)、Oracle Linux、国产化操作系统
-
目标端(9种):OpenStack、AWS、阿里云、腾讯云、华为云、移动云、ZStack、超融合产品、超融合产品
如此计算下来,一次测试的场景是171种。可能有的同学会说,这些用例也不是很多呀,跑一次也用不了多久,所以接下来让我们看一下HyperBDR在测试过程中第二个痛点:测试周期问题。
痛点二、测试周期长
不同于业务测试,HyperBDR单一场景的测试是非常耗时的,我们先忽略前期资源准备时间和各种配置时间,单纯就数据同步和启动过程进行一下分析:
-
数据同步:简单来说数据同步的过程就是将源端操作系统内的有效数据(不是分配容量),以块级别方式读出,写入到目标的云原生存储中。其中,第一次为全量,后续为永久增量。以Windows为例,假设有效数据为500G,如果按照千兆局域网带宽80%利用率计算,传输速度大概在800 Mbps,大约为80 MB/s,耗时约为1小时8分钟。
-
主机启动:根据不同的云原生存储类型,启动时间有很大的差异性,例如华为云的块存储,由于快照机制以及可以支持交换系统盘,所以启动时间与容量基本没有关系,基本可以控制在5分钟之内。但是对于国内的大多数云平台来说,并没有这样的能力,像阿里云在有快照生成卷时,底层限速为40 MB/s,这样一下子就拉长了恢复实践。我们以对象存储为例,假设我们从内网(Internal网络)将对象存储数据恢复至块存储,一个500G有效数据磁盘的恢复时间大约在40分钟左右。
所以我们在处理单一主机的一次测试,耗时至少在2个小时之内。按照上面假设的场景,一天测试下来,可能连一朵云的完整测试都无法完成。可能这里又有同学说了,你为什么不并发呀?这又引出了我们第三个痛点问题:成本。
痛点三、测试成本
之所以无法完全采用并发的原因,是受限于网络带宽因素。在内部研发环境中,我们的外网带宽只有40Mbps,在上述测试场景中,500G的数据在带宽充分利用的前提下,全量数据传输的时间在35小时左右。这无疑进一步扩大了一次测试的周期。
另外一点,源端这么多环境,如果再加上不同场景,需要占用的源端的计算和存储资源是海量的。随着产品不停地迭代,资源占用会越来越多。所以为了解决这一问题,我们决定采用部分公有云环境,来解决本地资源不足的问题。根据资源使用的特点,主要采用按量计费方式,实现成本最优。在实际测试过程中,主要产生的云资源包括:计算、块存储、对象存储、网络等。在自动化测试中,尽可能缩短资源周期,避免浪费,及时清理资源。另外,还需要对资源账单情况进行监控,避免资源残留。
需求分析
基本原则:不要重复制造轮子
进行自动化测试开发工作,并没有增加新的开发人员。开发工作主要由研发团队负责,测试团队作为使用方。但是由于开发团队有自身产品研发任务,所以为了避免对产品研发造成影响,制定的第一个原则就是不要重复制造轮子,尽可能复用现有技术积累和第三方组件,灵活的实现自动化测试的目标。
需求一、源端自动化创建与销毁
首先要解决的就是源端资源的灵活创建,而这方面最简单的就是利用Terraform,结合不同的模板实现源端资源创建和销毁能力。这样,我们至少拥有了阿里云、华为云、AWS、OpenStack、VMware五大云作为源端的能力。
第二个要解决的是代理方式自动化注册问题。源端主机需要进行Agent安装和注册后,才能被HyperBDR识别进行后续流程。根据操作系统不同,又分为Linux和Windows系统。Linux系统中,可以使用SSH登录系统后执行安装,而Windows则是利用WinRM方式进行Agent安装。
第三,可扩展性满足更多场景化需求。虽然Terraform本身提供了remote执行方式,但是为了后续的可扩展性,可以结合Ansible实现相关功能。未来的测试场景可能还包含对源端各种应用数据完整性的测试,此时在准备源端时还需要额外的准备应用和数据,使用Terraform结合Ansible,可以实现最大的灵活性。
需求二、测试场景与测试工具解耦,满足扩展性需求
简单来说,自动化测试程度越高,开发成本越高,后期维护的成本会更高。因此在规划自动化测试时,要降低测试场景和测试工具之间的耦合性。这样才能最大程度满足测试场景的可扩展性。换言之,测试场景是由测试工具进行灵活组合实现的,而二者之间的差距是通过各种配置文件进行融会贯通。
具体到HyperBDR的自动化测试规划中,我们将场景定义为:
-
为了验证主线流程的稳定性,我们设计了这样的场景:阿里云的一台CentOS 7操作系统主机,容灾到阿里云对象存储中,利用该数据,主机可以正常启动,系统启动后,可以正常ping通IP地址,可以正常SSH到系统内部,写入一个文件
-
为了验证华为云驱动的稳定性,我们设计的场景如下:将阿里云的N台主机(包含各个版本的操作系统),容灾到华为云的对象存储或块存储中,再将主机在华为云进行启动,启动后,利用ping通IP地址,可以正常登录系统,写入一个文件
-
为了验证增量数据,我们设计的场景如下:将阿里云的N台主机安装数据库,并且构建一定量数据进行记录,容灾到华为云对象存储中,再将主机在华为云进行启动,启动后,除了常规验证外,还要对数据库是否可以访问以及数据记录条数进行比对
而测试工具提供的能力上,我们进行了这样的定义:
-
源端创建/删除资源:完全由Terraform实现,但是为了后续程序更好的衔接,在产生主机后,自动产生一个conf文件,作为后续命令的输入,而主机内不同的应用则通过编写Ansible模板实现
-
目标平台配置/数据同步/启动主机/清理资源:这几部分主要通过调用HyperBDR SDK实现,而具体的配置则在配置文件中进行修改,如果是不同场景时,只需要不同的配置文件即可实现
以上全部的步骤,均是可以单独执行的,而每一步完成后,写入统一的CSV文件,这样步骤在连接时可以通过该文件形成统一性。后续可以将该CSV文件直接推送到数据可视化工具中,形成趋势展现的效果。
需求三、实现场景自动化,测试失败及时通知
在实际应用中,几乎从研发到交付的整个过程中都需要使用该工具。比如研发同学在提交代码前,至少需要对基本流程进行一次测试;交付同事在搭建一些演示环境时,也可以利用该脚本提高效率;而测试同事更是对这个工具有强烈的需求。
那么真正的不同场景自动化工作,则是由Jenkins任务完成串联,并且在测试失败后,可以及时通知大家,尽快进行修改。例如:每个小时,做一次小的冒烟测试,确保主线流程是否稳定;每天凌晨,做一次基本冒烟,确保已经支持云平台的稳定性;每周做一次大冒烟,确保主要的操作系统版本的稳定性。这样不仅节约了人力资源,也能第一时间发现版本中的不稳定因素。
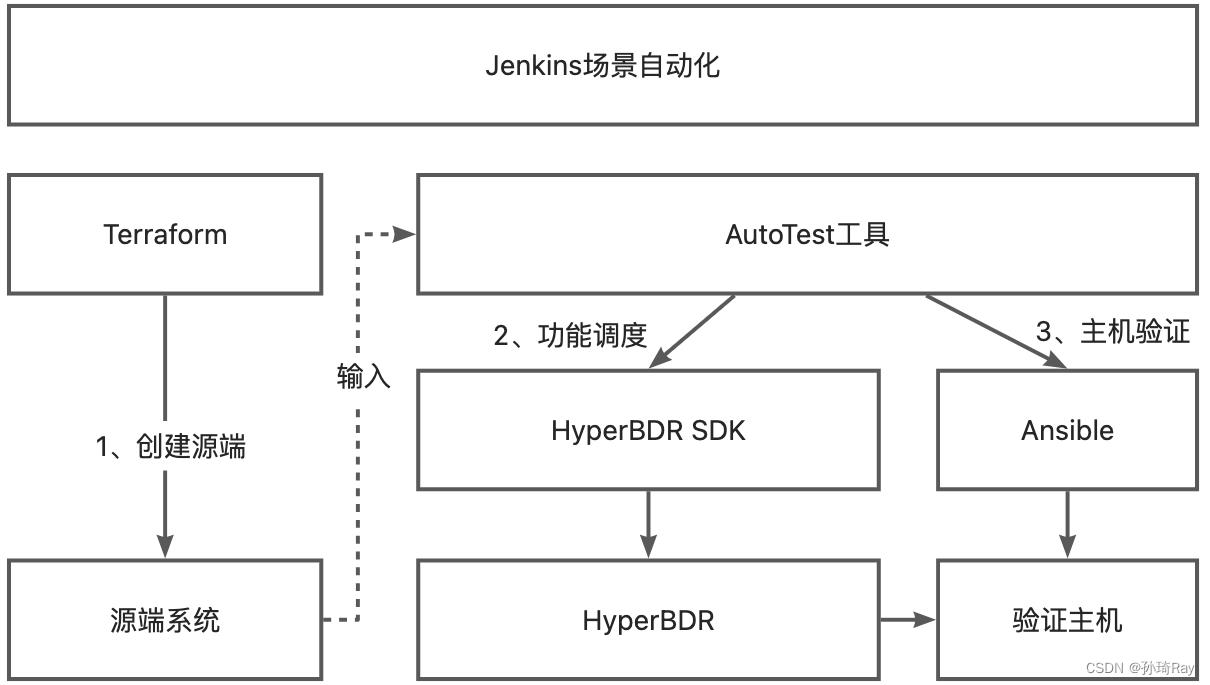
实现方式
整体架构
根据上面的需求,完整的工具包含两部分:
-
Terraform:主要包含了源端创建使用的模板以及ansible playbooks,Terraform在每次执行后,会自动产生源端主机列表,用于AutoTest工具的命令行输入参数
-
AutoTest工具:使用Python语言开发,主要通过对HyperBDR SDK调用控制HyperBDR实现自动化流程调度,各个阶段都是通过独立命令行进行控制,所有的可变部分在配置文件进行修改
-
AutoTest配置文件包含以下三部分配置:
-
基本配置:HyperBDR SDK鉴权信息,以及平台整体配置
-
目标云平台配置:目标云平台鉴权信息,配置参数等,根据不同的存储类型分为块存储和对象存储
-
容灾/迁移配置:用于定义主机在目标端的启动参数
-
Terraform创建资源并远程执行指令
Terraform的使用方面,有很多教程,这里不再赘述。这里主要说明一些Terraform使用的一些细节功能,满足Terraform于AutoTest之间的脚本串联。
内置方法remote-exec
Terraform创建资源后,会自动安装Agent注册到HyperBDR中,为了减少远程主机操作复杂度,这里将Agent上传至新创建的主机,再进行安装实现自动注册。
Terraform本身通过provisioner提供远程连接、上传并执行的方式,基本结构如下:
resource "null_resource" "ins_centos7_run_remote_command"
# 定义了SSH连接方式,可以通过密码或者密钥方式
connection
timeout = "5m"
type = "ssh"
user = "root"
password = "$random_password.password.result"
host = "$openstack_compute_instance_v2.ins_centos7.network[0].fixed_ip_v4"
# 将本地文件上传至远程资源的某个目录中
provisioner "file"
source = "../downloads/linux_agent.sh"
destination = "/tmp/script.sh"
# 通过remote-exec远程执行脚本
provisioner "remote-exec"
inline = [
"chmod +x /tmp/script.sh",
"sudo bash /tmp/script.sh",
]
depends_on = [openstack_compute_instance_v2.ins_centos7]
如果是Windows,则连接方式为winrm方式,这里要注意的一点是,启动的资源必须已经开启了WinRM,否则无法使用该方式进行连接。一种开启WinRM方式是利用user-data方式。这里看一下具体的示例
resource "null_resource" "run_windows_remote_command"
# 注意此处的类型为winrm
connection
timeout = "5m"
type = "winrm"
user = "Administrator"
password = "$random_password.password.result"
host = "$openstack_compute_instance_v2.ins_windows.network[0].fixed_ip_v4"
https = true
insecure = true
# 如果给定的是一个目录,则会上传整个目录,但是要注意Windows目录的斜线方向,盘符需要转移C:\\\\
provisioner "file"
source = "../downloads/Windows_server_64bit_beta"
destination = "C:\\\\Windows_server_64bit_beta"
# 远程执行方式与Linux相同
provisioner "remote-exec"
inline = [
"C:\\\\Windows_server_64bit_beta\\\\install-cli.bat",
"net start DiskSyncAgent",
]
depends_on = [openstack_compute_instance_v2.ins_windows]
与Ansible结合
直接利用Terraform的远程执行方式很简便,但是对于更多的复杂场景在支持上,并不够灵活,所以我们引入Ansible来加强我们对资源的控制。与remote-exec相对应的指令是local-exec,即通过执行本地的Ansible指令实现对远程资源的控制。目录结构如下:
.
├── main.tf
├── playbooks
│ └── apache-install.yml
我们将Ansible Playbooks存放在单独的目录中,Terraform中实现方式如下:
resource "null_resource" "run_ansible"
connection
timeout = "5m"
type = "ssh"
user = "root"
password = "$random_password.password.result"
host = "$huaweicloud_vpc_eip.myeip.address"
# 这里调用了local-exec本地执行Ansible命令
provisioner "local-exec"
command = "ANSIBLE_HOST_KEY_CHECKING=False ansible-playbook -u root -i '$huaweicloud_vpc_eip.myeip.address,' --extra-vars 'ansible_ssh_pass=$random_password.password.result' --ssh-common-args '-o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null' playbooks/apache-install.yml"
depends_on = [huaweicloud_compute_eip_associate.associated]
输出
为了串接Terraform和AutoTest,我们需要Terraform每次执行后,输出一个主机列表,包含了一些基本信息,当然这也可以作为Ansible Inventory文件使用。利用local_file resource,直接将我们想要写入的内容定向输出到文件中。具体实现如下:
resource "local_file" "inventory"
filename = "./sources.conf"
content = <<-EOF
[$openstack_compute_instance_v2.ins_centos7.network[0].fixed_ip_v4]
username = centos
password = $nonsensitive(random_password.password.result)
ipv4 = $openstack_compute_instance_v2.ins_centos7.network[0].fixed_ip_v4
mac = $openstack_compute_instance_v2.ins_centos7.network[0].mac
private_key = "$abspath(path.module)/../keys/openstack_linux.pem"
os = CentOS7
EOF
Terraform本地缓存
由于众所周知的原因,Terraform在执行init命令的时候,会访问github,这就造成安装过程中有一定的失败概率,为了减少失败的风险,需要采用本地缓存的方式,避免访问网络造成的风险。先来看一下目录结构:
.
├── install.sh
├── plugins-cache
│ └── registry.terraform.io
│ ├── hashicorp
│ │ ├── local
│ │ ├── null
│ │ ├── random
│ │ ├── template
│ │ └── tls
│ ├── huaweicloud
│ │ └── huaweicloud
│ └── terraform-provider-openstack
│ └── openstack
├── README.md
├── terraform_1.3.7_linux_amd64.zip
└── update_plugins_cache.sh
install.sh用于将下载好的terraform二进制包进行解压缩安装,同时会将plugins-cache拷贝至$HOME/.terraform.d目录,最后生成.terraformrc文件。
plugin_cache_dir = "$HOME/.terraform.d/plugins-cache"
在实际执行时,通过指定参数实现从本地执行安装,这种方式网上大部分文档都没有提及到:
terraform init -ignore-remote-version
在构建plugins-cache时,我们主要使用terraform providers mirror命令,例如:
terrform providers mirror /path/to/your/plugins-cache
为此我们在项目中增加了一个脚本,来自动化更新我们的缓存:
#!/bin/bash
#
# This script is used to install Terraform from local
#
set -e
CURRENT_PATH=$(cd `dirname $0`; pwd)
TERRAFORM_CLI="$HOME/bin/terraform"
PLUGINS_CACHE_PATH="$CURRENT_PATH/plugins-cache"
SRC_ROOT_PATH="$CURRENT_PATH/.."
# NOTE(Ray): Find all terraform directories and cache providers
for dir in $(find $SRC_ROOT_PATH -type d); do
for file in "$dir"/*tf; do
if [ -f "$file" ]; then
echo "Run terraform cache in $dir..."
$TERRAFORM_CLI providers mirror $PLUGINS_CACHE_PATH
break
fi
done
done
Taskflow串联执行流程,实现扩展性
在AutoTest工具开发过程中,我们主要复用了OpenStack部分Python模块简化开发,主要使用的模块为stevedore和taskflow,另外为了简化CSV文件操作,使用了pandas库来进行操作。
利用驱动方式扩展命令行
在setup.cfg中,我们定义了下面的驱动,每一个指令对应一个Taskflow的执行流程。
tasks =
cloud_config_oss = autotest.tasks.cloud_config:CloudConfigOss
cloud_config_block = autotest.tasks.cloud_config:CloudConfigBlock
cloud_config_clean = autotest.tasks.cloud_config:CloudConfigClean
data_sync_oss = autotest.tasks.data_sync:DataSyncOss
data_sync_block = autotest.tasks.data_sync:DataSyncBlock
host_boot = autotest.tasks.host_boot:HostBoot
host_clean = autotest.tasks.host_clean:HostClean
report = autotest.tasks.report:Report
在代码加载时,通过输入而不同参数,动态加载相应的流水线:
def run_tasks(args, hosts_conf, hyperbdr_conf):
"""Load each tasks as a driver"""
# We use a csv as a data table
data_table = DataTable(hosts_conf, args.work_path)
data_table.init()
status_file = StatusFile(args.work_path)
status_file.init()
driver_name = args.which.replace("-", "_")
logging.info("Loading task driver for %s..." % driver_name)
# 根据不同的命令行名称,加载相关的驱动
driver_manager = driver.DriverManager(
namespace="tasks",
name=driver_name,
invoke_on_load=False)
task_driver = driver_manager.driver(hyperbdr_conf, data_table, status_file)
task_driver.run()
利用Taskflow串接流程
Taskflow是OpenStack中非常优秀的库,对Task执行过程进行了抽象后,方便上层上时序业务场景使用。所以在应用中为了简化开发过程,在Taskflow之上做了适当的抽象,将执行过程和执行内容进行分离,即基类中进行执行,而子类中只需要定义相关具体的任务即可。
基类代码示例如下:
import taskflow.engines
from taskflow.patterns import linear_flow as lf
class BaseTask(object):
# 此处有代码省略
def run(self, tasks=[], *args, **kwargs):
# 子类只需要在继承类中定义好自己的tasks即可
if not tasks:
raise NotImplementedError("run() method "
"is not implemented")
# .......
flow_name = self.__class__.__name__
flow_api = lf.Flow(flow_name)
for task in tasks:
flow_api.add(task)
try:
taskflow.engines.run(flow_api,
engine_conf="engine": "serial",
store=
# 参数传递
)
except Exception as e:
raise e
finally:
# 任务失败后的处理,比如记录数据
一个具体的子类实现如下:
from taskflow import task
from autotest.tasks.base import BaseTask
class CloudConfigOss(BaseTask):
def run(self, *args, **kwargs):
steps = [
AddCloudAccount(),
WaitCloudAccount(),
AddOss(),
]
super().run(steps)
class AddCloudAccount(task.Task):
# TODO
class WaitCloudAccount(task.Task):
# TODO
class AddOss(task.Task):
# TODO
通过上述抽象,可以很快速的利用HyperBDR SDK实现各种应用场景,最大程度满足后续可扩展性的需求。
Jenkins串联自动化测试流程
工具实现后,不仅可以满足手工分步执行的需要,也可以利用Jenkins串接流程,满足场景自动化测试的需求。
场景自动化
我们在git中新建一个项目,名称为autotest-cases,用于自动化场景测试。示例结构如下:
.
├── Jenkinsfile
├── openstack_oss_qa_tiny_smoke
│ ├── hyperbdr.conf
│ └── terraform_templates
我们以场景名称命名目录,每一个目录下均有单独一套的terraform模板和hyperbdr配置文件。这样定义Jenkins任务时,就可以把测试场景作为一个目录,灵活的进行加载。
其中Jenkinsifle的基本结构为:
pipeline
// 省略部分代码
parameters
string(
name: 'TEST_CASE',
defaultValue: 'openstack_oss_qa_tiny_smoke',
description: '测试任务执行的目录,对应autotest-cases的目录'
)
string(
name: 'HYPERBDR_URL',
defaultValue: 'https://xxxx',
description: 'HyperBDR地址,需要配合鉴权信息使用'
)
// 省略部分代码
stages
stage('Clone Repository')
// 省略部分代码
// end stage
stage('更新HyperBDR环境')
// 省略部分代码
// end stage
stage('下载Agent代理')
// 省略部分代码
// end stage
// 鉴权信息固定写在Terraform tfvars文件时,使用时通过Jenkins中的Credentials进行替换
stage('创建源端')
steps
// 对每个目录下auth文件进行替换后,source声明环境变量
withCredentials([usernamePassword(credentialsId: "$CLOUD_CREDENTIALS_ID", usernameVariable: 'USERNAME', passwordVariable: 'PASSWORD')])
sh """
sed -i "s/JENKINS_CLOUD_USERNAME/$USERNAME/g" "$terraformVars"
sed -i "s/JENKINS_CLOUD_PASSWORD/$PASSWORD/g" "$terraformVars"
"""
dir("$terraformTemplatePath")
sh """
$terraformPath init -ignore-remote-version -plugin-dir ~/.terraform.d/plugins-cache
$terraformPath apply -auto-approve -var-file="$terraformVars"
"""
// end steps
// end stage
stage('目标平台配置')
// 省略部分代码
// end stage
stage('数据同步')
// 省略部分代码
// end stage
stage('启动主机')
// 省略部分代码
// end stage
stage('清理资源')
// 省略部分代码
// end stage
stage('清理环境')
steps
dir("$terraformTemplatePath")
sh """
$terraformPath destroy -auto-approve -var-file="$terraformVars"
"""
// end steps
// end stage
stage('发送报告')
// 将Markdown格式报告发送至钉钉,包含执行结果和执行时间
// end stage
// end stages
// end pipeline
通过对每一阶段的定义,能够清晰的了解每一阶段执行的结果以及失败的原因,最终将结果发送至钉钉中,及时了解当前代码的稳定性。
异常处理
在整个自动化测试流程中,如果在中间任何一个步骤失败,都需要对资源进行及时清理,避免对下一次测试的影响。所以定义一个全局的失败,进行强制资源清理。
post
failure
// TODO(Ray): 目前暂未加入清理目标端资源的逻辑
// 全局异常处理,保证源端和目标端不残留资源
dir("$terraformTemplatePath")
sh """
$terraformPath destroy -auto-approve -var-file="$terraformVars"
"""
// end failure
// end post
总结
目前,在HyperBDR的日常开发中,我们还在不断完善自动化测试的场景,但是经过这一轮的实现,让我对自动化测试有了全新的认知。
自动化测试能否实现全面覆盖呢?至少在HyperBDR中不行,因为HyperBDR的源端和目标端造成了测试场景的不可预期性,很难完全通过自动化脚本来模拟出复杂场景,特别是异常场景。例如:对源端主机内部的破坏性测试,对数据传输链路的一些攻击场景,需要配合监控才能发现是否满足预期。这些场景,利用自动化测试模拟开发代价太大,而且可能发生的场景还在不断变化,根本无法满足版本快速迭代的需求。当然你如果有一个几百人的研发团队,专门做这件事情,那另当别论,不过这样的投入产出比是否合理,值得探讨。
自动化测试中,哪些该”自动“,哪些该”手动“?在实现自动化测试过程中,不要盲目的追求”自动“。自动程度越高,开发成本越高,灵活性大打折扣,导致可利用的场景较少,这反而与预期相违背。以HyperBDR场景为例,倒不如将每个流程进行切分,实现局部自动化,实现多个工具形成工具集,再用流程串联方式构建场景化。
后续的计划有哪些?随着产品不停的迭代,自动化测试还将不断的扩展,除了支持代理方式,还会增加对无代理方式、块存储方式自动化的支持,但是这些的开发模式全部以上述框架为前提。上述测试主要还是针对接口的测试,对于前端的测试还将引入Selenium实现,实现的范围仍然以主线流程为主。最后,逐步丰富数据测试场景,增加对数据完整性的测试。
随着DevOps理念逐步改变传统研发流程,自动化测试作为其中的一环也是必不可少的,也是未来开发人员必备的技能之一。但是自动化测试不同于产品研发,要学会”断“的思想,理解测试的需求和场景,才能做出适配性最好的自动化测试工具。
以上是关于云原生灾备产品HyperBDR自动化测试实践的主要内容,如果未能解决你的问题,请参考以下文章