深入浅出SpringCloud原理及实战「Netflix系列之Hystrix」针对于限流熔断组件Hystrix的缓存请求执行运作原理
Posted 洛神灬殇
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入浅出SpringCloud原理及实战「Netflix系列之Hystrix」针对于限流熔断组件Hystrix的缓存请求执行运作原理相关的知识,希望对你有一定的参考价值。
♣ 请求缓存
请求缓存
在HystrixCommand和HystrixObservableCommand的实现中,你可以定义一个缓存的 Key,这个Key用于在同一个请求上下文(全局或者用户级)中标识缓存的请求结果,当然,该缓存是线程安全的。
下例展示了在一个完整 HTTP 请求周期内,两个线程执行命令的流程:
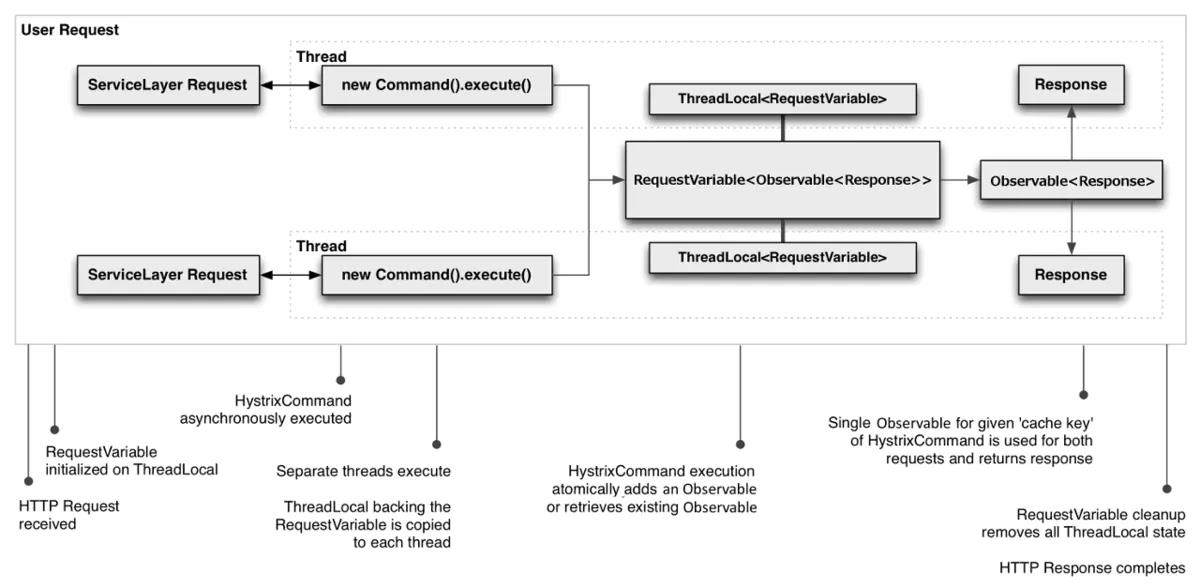
请求缓存例子
请求缓存有如下好处:
-
不同请求路径上针对同一个依赖服务进行的重复请求(有同一个缓存 Key),不会真实请求多次
-
这个特性在企业级系统中非常有用,在这些系统中,开发者往往开发的只是系统功能的一部分。(注:这样,开发者彼此隔离,不太可能使用同样的方法或者策略去请求同一个依赖服务提供的资源)
例如,请求一个用户的Account的逻辑如下所示,这个逻辑往往在系统不同地方被用到:
Account account = new UserGetAccount(accountId).execute();
//or
Observable<Account> accountObservable = new UserGetAccount(accountId).observe();
Hystrix的RequestCache只会在内部执行run()方法一次,上面两个线程在执行HystrixCommand命令时,会得到相同的结果,即使这两个命令是两个不同的实例。
数据获取具有一致性
因为缓存的存在,除了第一次请求需要真正访问依赖服务以外,后续请求全部从缓存中获取,可以保证在同一个用户请求内,不会出现依赖服务返回不同的回应的情况。
避免不必要的线程执行
在construct()或run()方法执行之前,会先从请求缓存中获取数据,因此,Hystrix 能利用这个特性避免不必要的线程执行,减小系统开销。
若Hystrix没有实现请求缓存,那么HystrixCommand和HystrixObservableCommand的实现者需要自己在construct()或run()方法中实现缓存,这种方式无法避免不必要的线程执行开销。
请求缓存是对一次请求的数据进行缓存,当有新的请求进来的时候,将会进行初始化操作,保证读取到的数据是最新的而不是上次缓存的数据,hystrix就是去缓存一次请求中相同cachekey的查询结果
请求缓存实现
对于请求缓存可以通过实现类和注解的方式进行实现,这里我并没有去研究创建实现类的方式,比较复杂,我这里是使用了注解的方式进行请求缓存的实现
相关注解释义
-
@CacheResult:标记这是一个执行缓存的方法,其结果将会被缓存,需要注意的是,该注解需要配合HystrixCommand注解使用
-
@CacheKey:这个注解会对请求参数进行标记,相同参数将会获取缓存得到的结果
具体实现逻辑
首先创建一个服务提供者的实现类,用于返回调用值,这里采用随机数的方式,保证每次生成的数值不重复,以便于验证我们的缓存是否起作用
/**
* hystrix请求缓存
*
* @param
* @return
*/
@RequestMapping("/hystrix/cache")
public Integer getRandomInteger()
Random random = new Random();
int randomInt = random.nextInt(99999);
return randomInt;
// 请求缓存具体注解实现类
@Override
@CacheResult
@HystrixCommand(commandKey = "commandKey2")
public Integer getRandomInteger(@CacheKey int id)
Integer a1=storeClient.getRandomInteger();
return a1;
/**
* 请求缓存测试
* 请求方式处设置缓存相关设置
*/
@GetMapping("/getCache1")
public String getCache1()
//初始化Hystrix请求上下文
HystrixRequestContext context =HystrixRequestContext.initializeContext();
// 初始化请求上下文
Integer a=cacheService.getRandomInteger(1);
System.out.println("第一次获取缓存值为"+a);
Integer a1=cacheService.getRandomInteger(1);
System.out.println("第二次获取缓存值为"+a1);
Integer a2=cacheService.getRandomInteger(1);
System.out.println("第三次获取缓存值为"+a2);
String show="第一次请求值:"+a+",第二次请求值为:"+a1+",第三次请求值为:"+a2;
//上下文环境用完需要进行关闭
context.close();
return show;
查看结果

以上是关于深入浅出SpringCloud原理及实战「Netflix系列之Hystrix」针对于限流熔断组件Hystrix的缓存请求执行运作原理的主要内容,如果未能解决你的问题,请参考以下文章
深入浅出SpringCloud原理及实战「Netflix系列之Fegin」打开Fegin之RPC技术的开端,你会使用原生态的Fegin吗?(下)
深入浅出SpringCloud原理及实战「Netflix系列之Hystrix」针对于限流熔断组件Hystrix的超时机制的原理和实现分析
深入浅出SpringCloud原理及实战「Netflix系列之Hystrix」针对于限流熔断组件Hystrix的基本参数和实现原理介绍分析
深入浅出Dubbo3原理及实战「SpringCloud-Alibaba系列」基于Nacos作为注册中心进行发布SpringCloud-alibaba生态的RPC接口实战
深入浅出SpringCloud原理及实战「Netflix系列之Ribbon」针对于负载均衡组件Ribbon的基本参数和实现原理介绍分析
深入浅出SpringCloud原理及实战「SpringCloud-Gateway系列」微服务API网关服务的Gateway全流程开发实践指南(入门篇)