深入理解XGBoost,优缺点分析,原理推导及工程实现
Posted Datawhale
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入理解XGBoost,优缺点分析,原理推导及工程实现相关的知识,希望对你有一定的参考价值。
本文的主要内容概览:
1. XGBoost简介
XGBoost的全称是eXtreme Gradient Boosting,它是经过优化的分布式梯度提升库,旨在高效、灵活且可移植。XGBoost是大规模并行boosting tree的工具,它是目前最快最好的开源 boosting tree工具包,比常见的工具包快10倍以上。在数据科学方面,有大量的Kaggle选手选用XGBoost进行数据挖掘比赛,是各大数据科学比赛的必杀武器;在工业界大规模数据方面,XGBoost的分布式版本有广泛的可移植性,支持在Kubernetes、Hadoop、SGE、MPI、 Dask等各个分布式环境上运行,使得它可以很好地解决工业界大规模数据的问题。本文将从XGBoost的数学原理和工程实现上进行介绍,然后介绍XGBoost的优缺点,并在最后给出面试中经常遇到的关于XGBoost的问题。
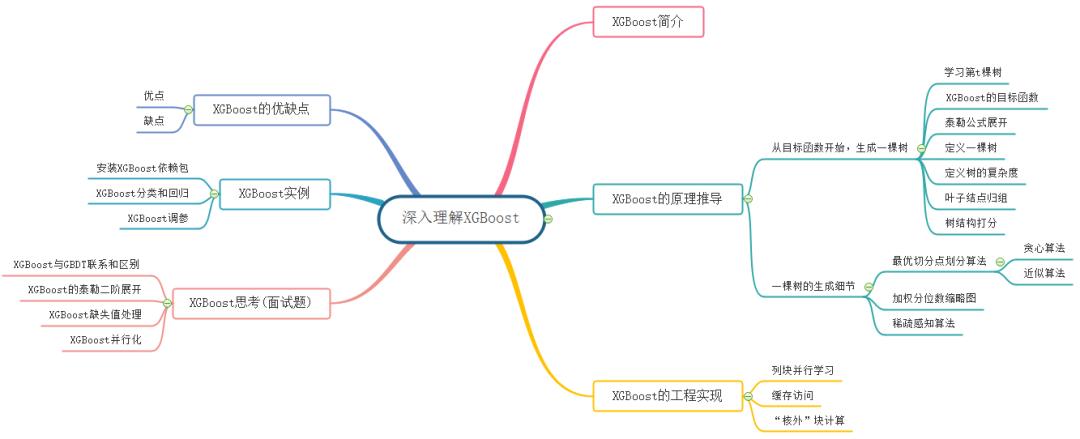
2. XGBoost的原理推导
2.1 从目标函数开始,生成一棵树
XGBoost和GBDT两者都是boosting方法,除了工程实现、解决问题上的一些差异外,最大的不同就是目标函数的定义。因此,本文我们从目标函数开始探究XGBoost的基本原理。
2.1.1 学习第 t 棵树
XGBoost是由 个基模型组成的一个加法模型,假设我们第 次迭代要训练的树模型是 ,则有:

2.1.2 XGBoost的目标函数
损失函数可由预测值 与真实值 进行表示:
其中, 为样本的数量。
我们知道模型的预测精度由模型的偏差和方差共同决定,损失函数代表了模型的偏差,想要方差小则需要在目标函数中添加正则项,用于防止过拟合。所以目标函数由模型的损失函数 与抑制模型复杂度的正则项 组成,目标函数的定义如下:
其中, 是将全部 棵树的复杂度进行求和,添加到目标函数中作为正则化项,用于防止模型过度拟合。
由于XGBoost是boosting族中的算法,所以遵从前向分步加法,以第 步的模型为例,模型对第 个样本 的预测值为:
其中, 是由第 步的模型给出的预测值,是已知常数, 是这次需要加入的新模型的预测值。此时,目标函数就可以写成:
注意上式中,只有一个变量,那就是第 棵树 ,其余都是已知量或可通过已知量可以计算出来的。细心的同学可能会问,上式中的第二行到第三行是如何得到的呢?这里我们将正则化项进行拆分,由于前 棵树的结构已经确定,因此前 棵树的复杂度之和可以用一个常量表示,如下所示:
2.1.3 泰勒公式展开
泰勒公式是将一个在 处具有 阶导数的函数 利用关于 的 次多项式来逼近函数的方法。若函数 在包含 的某个闭区间 上具有 阶导数,且在开区间