[Nutch]指定LUKE的分词器
Posted kandy_ye
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Nutch]指定LUKE的分词器相关的知识,希望对你有一定的参考价值。
在上一篇博文我们有介绍给Solr配置中文分词器mmseg4j,那么我们在LUKE工具中如何配置对应的中文分词器进行查看呢?本篇博文将详细进行解释。
1. 下载中文分词器
由于我们使用的luke是4.0版本的,只能使用mmseg4j的1.9.1版本,因为1.8.5的mmseg4j版本与4.0版本的luke有冲突,请点击下载1.9.1版本的mmseg4j-1.9.1.
2. luke设置mmseg4j
2.1 加压mmseg4j-1.9.1
解压后会有一个dist目录:
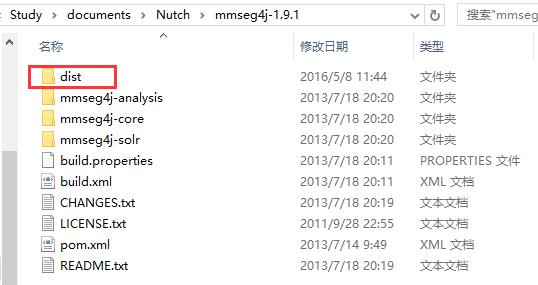
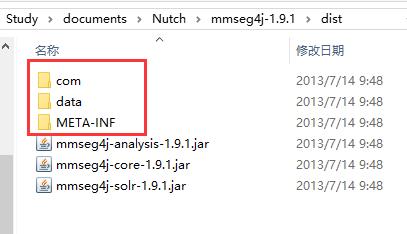
在dist目录下面会有3个jar包:

对这3个目录进行解压,会生成3个文件夹:
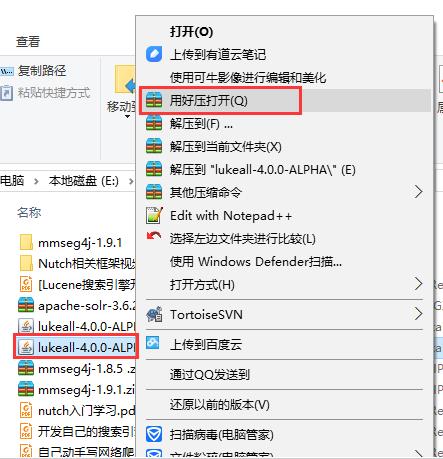
2.2 用压缩工具打开luke
我使用的是好压,如下:
打开后内容如下:

2.3 设置分词
将mmseg4j中的3个jar文件解压后得到的两个目录:data和com拖入用压缩工具打开的luke中:

3. 在luke中选择mmseg4j分词器
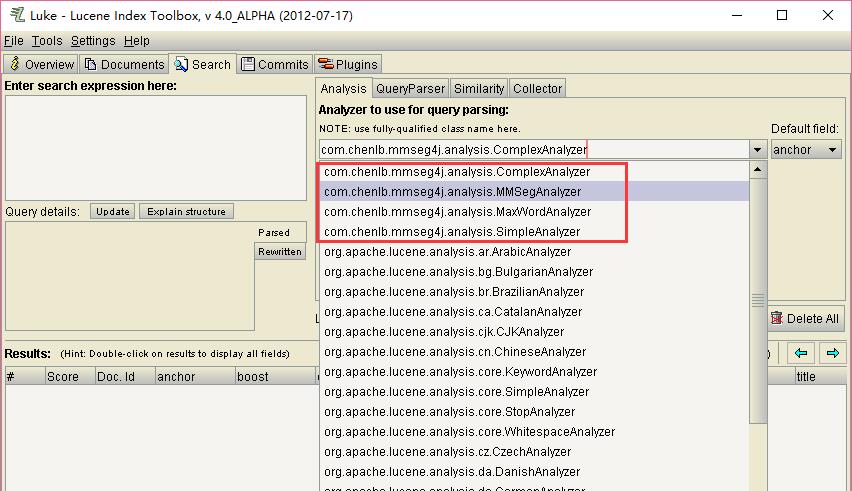
使用命令行打开设置mmseg4j的luke:
java -jar lukeall-4.0.0-ALPHA.jar在Search栏位右上角的Analysis里面就可以看到mmseg4j的4个分词器:
4. luke运用mmseg4j分词器
4.1 设置分词器和域
由于之前在设置Solr的分词器的时候,我们有选择Complex模式:
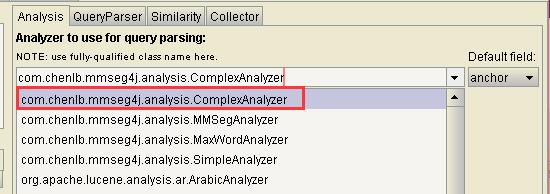
所以我们选择使用ComplexAnalyzer:
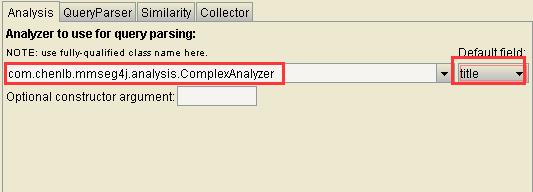
缺省的域选择title:
4.2 使用分词器
在“Enter search expression here”输入:”title:电子商务”,如下:
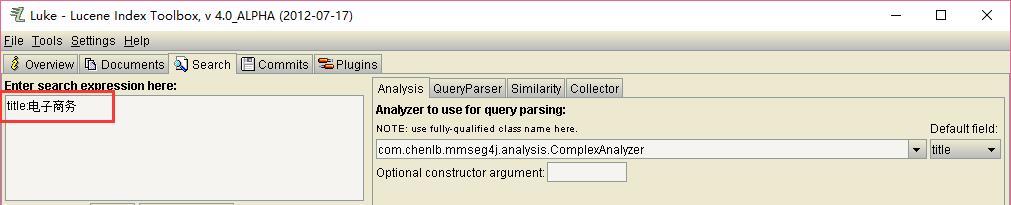
点击“Search”按钮,可以看到:
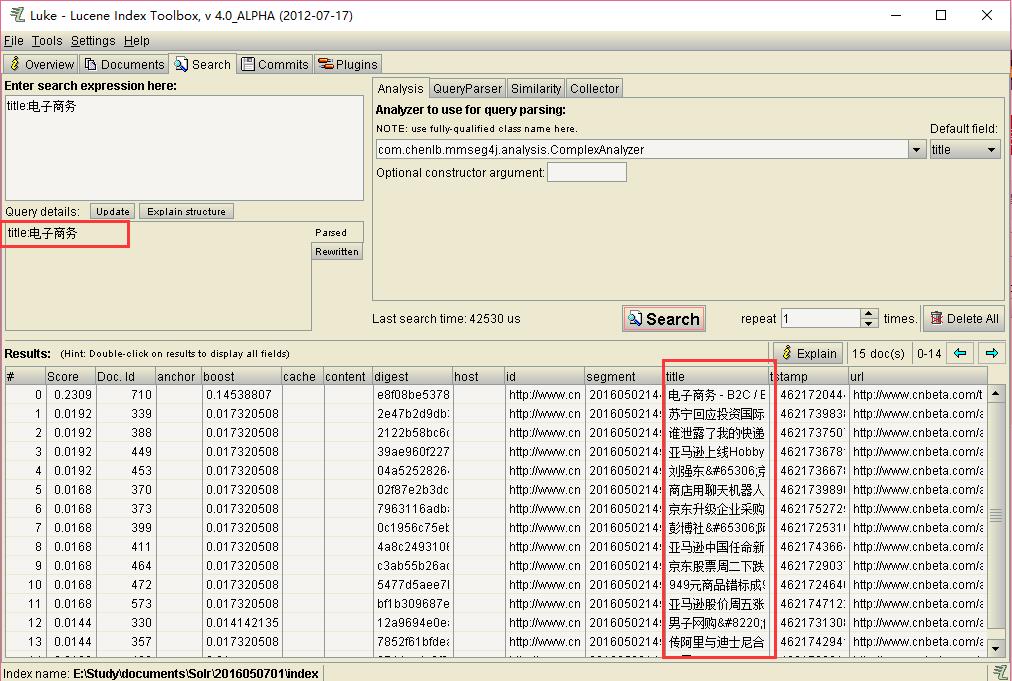
在“Query Details”里面显示的就是一个分词“title:电子商务”。
以上是关于[Nutch]指定LUKE的分词器的主要内容,如果未能解决你的问题,请参考以下文章