[Nutch]Hadoop单机伪分布模式的配置
Posted kandy_ye
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Nutch]Hadoop单机伪分布模式的配置相关的知识,希望对你有一定的参考价值。
在之前的博文中,我们一直在使用Nutch的local模式,那么Nutch的Deploy模式该怎么使用呢?首先我们来配置hadoop,为使用Nutch的deploy模式做准备。
1. 下载hadoop
在workspace目录使用如下命令下载hadoop 1.2.1:
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz下载之后进行解压:
tar -zxvf hadoop-1.2.1.tar.gz 2. 设置Hadoop运行环境
将hadoop的路径加入到当前用户的配置文件(.bashrc)里面:
用vim打开配置文件
vim ~/.bashrc将doop的路径加入到PATH里面:
export PATH=/home/kandy/workspace/hadoop-1.2.1/bin:$PATH如下:

重新登陆当前账号即可生效:
ssh localhost查看hadoop的路径:
which hadoop结果如下:

3. 配置hadoop运行参数
进入hadoop的根目录:
cd hadoop-1.2.13.1 配置core-site.xml文件
使用vim打开conf目录下的core-site.xml文件:
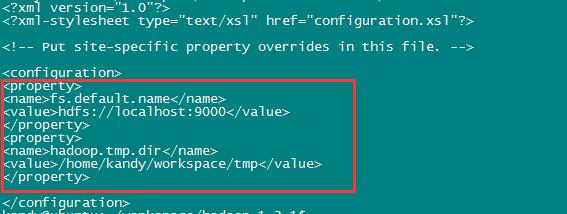
vim conf/core-site.xml在文件里面加入如下内容:
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/kandy/workspace/tmp</value>
</property>如下:
3.2 配置hdfs-site.xml
使用vim打开conf目录下面的hdfs-site.xml文件:
vim conf/hdfs-site.xml在文件里面加入如下内容:
<property>
<name>dfs.name.dir</name>
<value>/home/kandy/workspace/dfs/filesystem/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/kandy/workspace/dfs/filesystem/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>如下:

3.3 配置mapred-site.xml
用vim打开conf目录下面的mapred-site.xml文件:
vim conf/mapred-site.xml在文件里面加入如下内容:
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
<property>
<name>mapred.tasktracker.map.tasks.maximum</name>
<value>2</value>
</property>
<property>
<name>mapred.tasktracker.reduce.tasks.maximum</name>
<value>2</value>
</property>
<property>
<name>mapred.system.dir</name>
<value>/home/kandy/workspace/mapreduce/system</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/home/kandy/workspace/mapreduce/local</value>
</property>
如下:

3.4 配置hadoop-env.sh文件
使用vim打开conf目录下面的hadoop-env.sh文件:
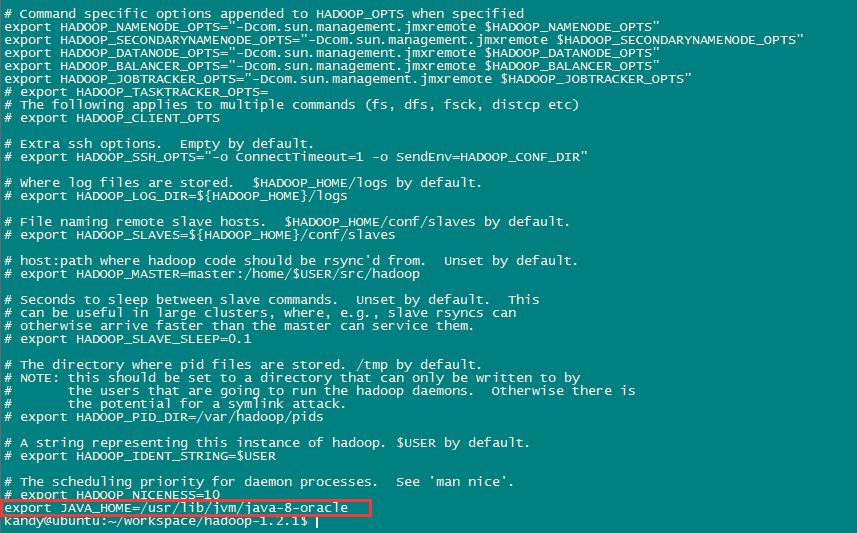
vim conf/hadoop-env.sh在里面配置JAVA_HOME,加入如下内容:
export JAVA_HOME=/usr/lib/jvm/java-8-oracle如图:
4. 格式化名称节点并启动集群
使用如下命令:
hadoop namenode -format如下图:

从上图就可以看到相关信息。
5. 启动集群并查看WEB管理界面
5.1 启动集群
使用如下命令启动集群:
start-all.sh如图:

使用JPS命令就可以看到多了几个进程:

有这样几个进程就表示启动成功。
5.2 查看web管理页面
访问 http://192.168.238.130:50030 可以查看 JobTracker 的运行状态:

访问 http://192.168.238.130:50060 可以查看 TaskTracker 的运行状态:

访问 http://192.168.238.130:50070 可以查看 NameNode 以及整个分布式文件系统的状态,浏览分布式文件系统中的文件以及 log 等:

以上是关于[Nutch]Hadoop单机伪分布模式的配置的主要内容,如果未能解决你的问题,请参考以下文章