基于单机最高能效270亿参数GPT模型的文本生成与理解
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于单机最高能效270亿参数GPT模型的文本生成与理解相关的知识,希望对你有一定的参考价值。
概述
GPT模型能较好的处理文本生成领域的各种任务,比如文本补全,自由问答,完形填空,写作文,写摘要,写小说,写诗歌等等。最近火爆全网的人工智能产品ChatGPT也是以GPT文本生成模型为底座。虽然GPT大模型作用在这些应用领域的效果很好,但是训练成本非常高。以OpenAI推出的1750亿的GPT-3为例,在1024张A100GPU上预估需要34天,一万亿参数的GPT-3在3072张A100显卡上也至少需要84天;微软/英伟达联合推出的5300亿的NLG模型,在2048张A100显卡上耗时了3个月的训练时间才能达到比较好的收敛效果。

针对GPT基础模型参数量大,训练&推理硬件资源消耗过高等问题,基于MoE的稀疏化训练是目前最具竞争力的降本增效途径。MoE的全称是Mixture of Experts,其中的Expert对应的是Transfomrer模型的MLP层,在训练的时候从多个MLP中选取一个MLP进行激活(如下图所示)。这意味着模型可以在不增加计算强度(FLOPS/Bytes)的情况下,通过增加MLP模块的数量来增加模型参数量级,进而提升模型在下游任务上的泛化性能。采用MoE后的稀疏Transformer模型和同等质量(验证集loss以及zeroshot nlu下游任务性能)的稠密模型相比有将近1.2倍的训练吞吐性能提升,1.3倍的推理吞吐性能提升。我们在稀疏架构总体设计的时候,选择让MoE跟纯Transformer Decoder架构的GPT进行有机结合。原因是MoE跟Decoder结合效果通常会好于跟Encoder的结合效果。具体来讲,Encoder是通过随机masking的方式学习语言模型,而这种被随机masked的token会让expert的路由选择出现不均衡。另一方面,考虑到Decoder类的GPT模型比Encoder类的Bert模型有更广泛使用场景,因此我们采用GPT+MoE的技术架构路线,探索单机最高能效的绿色低碳GPT大模型训练&推理软硬一体化适配技术在中文文本生成场景的落地可行性。
基于当前比较成熟的分布式MoE专家路由选择技术,采用Switch Transformer[2]中的top-1路由机制。每个Expert根据如下的softmax函数被赋予一个概率值,取概率最高(top-1)的那个Expert当作网络的FFN层。其中W_r是做路由选择时需要学习的参数。

GPT-MoE训练&推理能效分析
基础预训练模型训练&推理性能分析
任何一种稠密(Dense)的GPT模型,都有一种效果与之对应的训练&推理速度更快的稀疏(MoE)GPT模型。我们的目标是在受限硬件比如单机条件下找到这种GPT-MoE模型配置,然后通过对MoE算法进行改进来进一步提升它的训练能效。我们通过对比稠密&稀疏模型的训练&推理性能,来发现与稠密模型等价的高能效稀疏模型。
8种GPT模型的参数量,模型结构,训练超参数如下表所示:
| GPT模型 | 参数量 | Layers | Heads | hidden size | LR | Batch of Tokens |
| 1.3B Dense | 1.3B | 24 | 32 | 2048 | 2e-4 | 1M |
| 2.7B Dense | 2.7B | 32 | 32 | 2560 | 1.6e-4 | 1M |
| 3.6B Dense | 3.6B | 30 | 32 | 3072 | 1.6e-4 | 1M |
| 0.35B+MoE-64 | 6.7B | 24 | 16 | 1024 | 3e-4 | 0.5M |
| 1.3B+MoE-32 | 13B | 24 | 32 | 2048 | 2e-4 | 1M |
| 1.3B+MoE-64 | 27B | 24 | 32 | 2048 | 1.6e-4 | 1M |
| 2.7B+MoE-64 | 56B | 32 | 32 | 2560 | 1.6e-4 | 1M |
| 3.6B+MoE-64 | 75B | 30 | 32 | 3072 | 1.6e-4 | 1M |
如下图所示,1.3B+MoE32/64模型在相同的step下对比1.3B dense表现出更低的验证集loss,其中1.3B+MoE-64模型的loss甚至低于2.7B dense模型

5个模型中,0.35B+MoE-64的训练吞吐速度最快,是其他模型的2倍左右。其余四个模型中,吞吐速度较高的是1.3B dense和1.3B+MoE-32,1.3B+MoE-64和2.7B dense的速度相近。如下图所示:
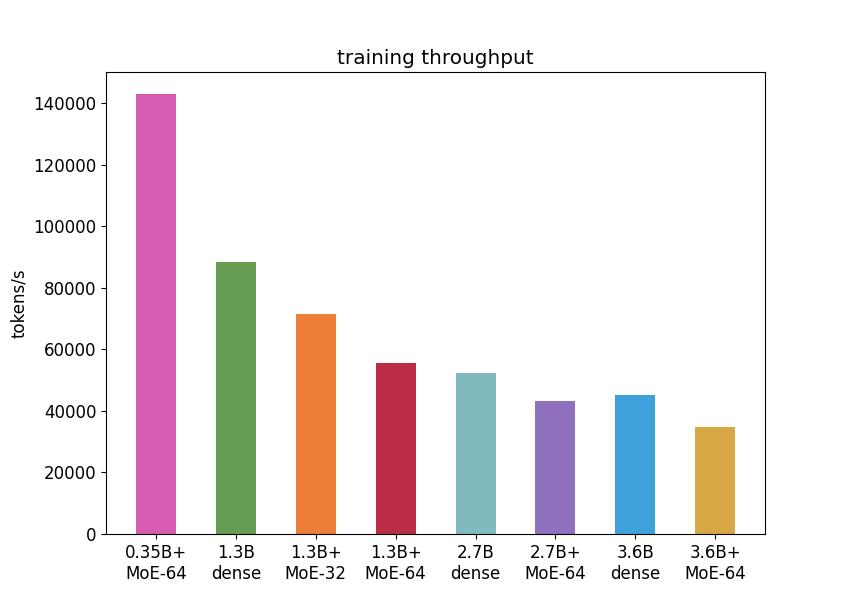
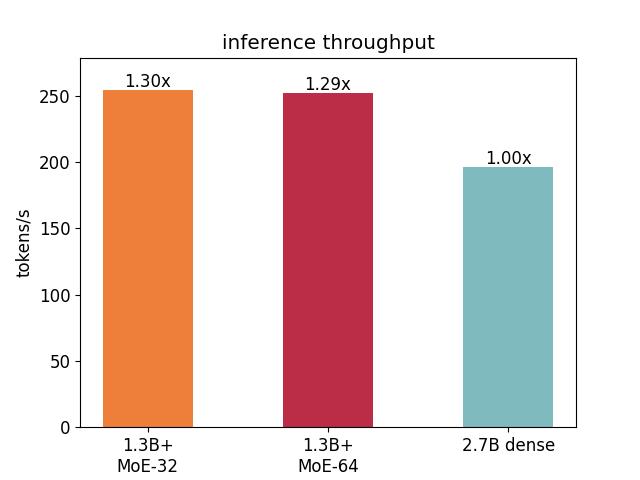
推理吞吐速度方面,1.3B Dense的显存消耗最少,0.35B+MoE64的延迟最低。
input_len = 20
output_len = 128
batch_size = 1
| 模型 | latency (ms) | memory (MB) | num of gpus |
| 1.3B Dense | 399.66 | 9476 | 1 |
| 2.7B Dense | 753.37 | 17340 | 1 |
| 3.6B Dense | 777.54 | 22558 | 1 |
| 0.35B+MoE64 | 356.22 | 15772 | 1 |
| 1.3B+MoE32 | 581.34 | 33294 | 1 |
| 1.3B+MoE64 | 586.18 | 57880 | 1 |
| 2.7B+MoE64 | 742.43 | 61054 | 2 |
| 3.6B+MoE64 | 662.57 | 42724 | 4 |
通过以上的图表分析,我们能大致判断出2.7B-Dense模型对应的高能效的稀疏模型是以1.3B的dense模型为底座,同时配置32或者64个专家的MoE模型。下面我们重点分析下1.3B+MoE-32/64和2.7B dense模型的性价比。在单机A100上预训练200个小时后,借助Tensorboard画出预训练验证集loss曲线。我们发现在验证集loss到达2.16时,1.3B+MoE-64模型的收敛速度是2.7B dense的1.17,1.3B+MoE-32的收敛速度落后于2.7B dense模型15%,如下图所示:

从下图中的基于Faster Transformer的单级单卡推理性能上看。1.3B+MoE-32和1.3B+MoE64的吞吐速度差不多且都高于2.6B dense模型,这是符合预期的,因为他们的底座大小都只有1.3B。
中文ZeroShot-NLU效果评测

中文文本生成效果评测
文本补全

诗歌生成
在线体验地址:https://www.modelscope.cn/models/PAI/nlp_gpt3_text-generation_0.35B_MoE-64/summary

广告文案生成
在线体验地址:https://www.modelscope.cn/models/PAI/nlp_gpt3_text-generation_1.3B_MoE-32/summary

作文生成
在线体验地址:https://www.modelscope.cn/models/PAI/nlp_gpt3_text-generation_1.3B_MoE-64/summary

背景
Top-1 Gating 是目前最主流也最有效的 Routing 算法,但是也有着明显的缺点。例如,在 Top-1 Gating 中,每一个 Token 仅会被交给一个 expert 处理,因此,时常会出现某些 expert 需要处理很多 token,而有些 expert 仅需处理极少数量的 token 的情况,这导致处理极少 token 的 expert 无法获得足够多的信息,无法得到充分的利用。
高能效专家路由选择
因此,我们自研了新的路由算法,如下图所示。我们的算法让 expert 主动选择固定数量(capacity)的 token,同一个 token 可以同时被不同的 expert 处理,从而使每一个 expert 都能得到充分的训练。
最后生成的 token 的表示,则采用 weighted sum 的方式,将来自不同 expert 生成的表示加权求和并经过Expert Residual模块,以获得最终的 token 表示。这样的表示,由于有多个 expert 的共同作用,因此更加鲁棒。

- 计算 expert 对 token 的偏好:

其中

是输入的 tokens 的表示,W_e \\in \\mathbbR^d*e 是 experts 的权重,

表示输入 token 的数量,

表示 expert 的数量,

表示隐藏特征的维度,S \\in \\mathbbR^n*e为每一个 expert 对输入的每一个 token 的偏好程度;
2.L-Softmax 算法训练expert权重
训练过程中利用 L-Softmax loss 优化 experts 的权重W_e ,实现每一个expert对token都具有可区分的的偏好。
3.每个 expert 选取固定数量的 token:

其中,

就是我们预先确定的,每个 expert 可以处理的最多 token 的数量,

记录了每个 expert 需要处理的 tokens 的索引;
- 计算最后的输出:
X_out = a * \\textExpertResidual(\\textExperts(X, I)) + (1-a) * \\textExperts(X, I)
每一个 expert 根据索引计算出对应 tokens 的表示,并将不同 expert 对同一 token 生成的表示加权求和,最后通过 Expert Residual 模块生成最终的输出

。
实验分析
下图是采用自研算法与 Top-1 Gating、s-BASE 算法的验证集 loss 随训练 step 变化的曲线图,我们可以发现,采用自研算法的验证集 loss 始终低于 top-1 gating 和 s-BASE 算法的验证集 loss,证明了我们自研算法的有效性。
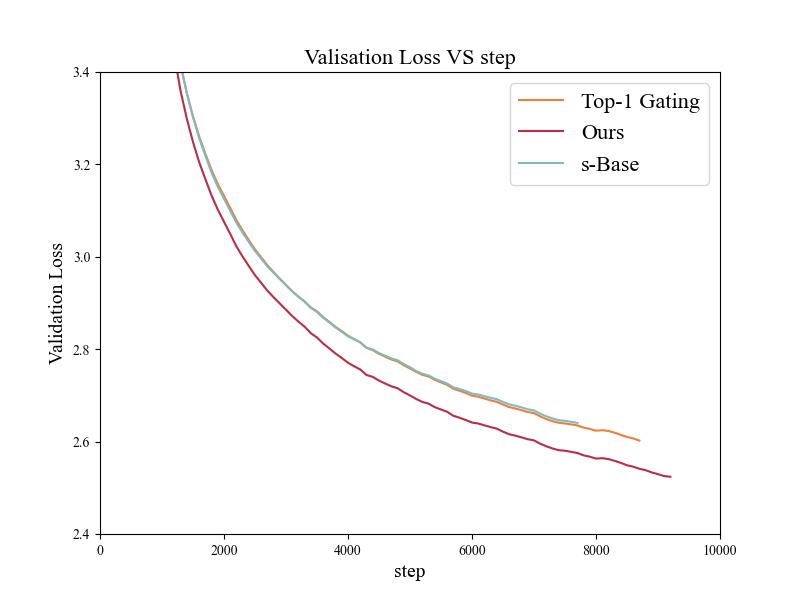
同时,我们观察到,验证集 loss 首次低于 2.7 的时间,自研算法的速度是 s-BASE 的 1.48 倍,极大的减少了模型训练的开销。
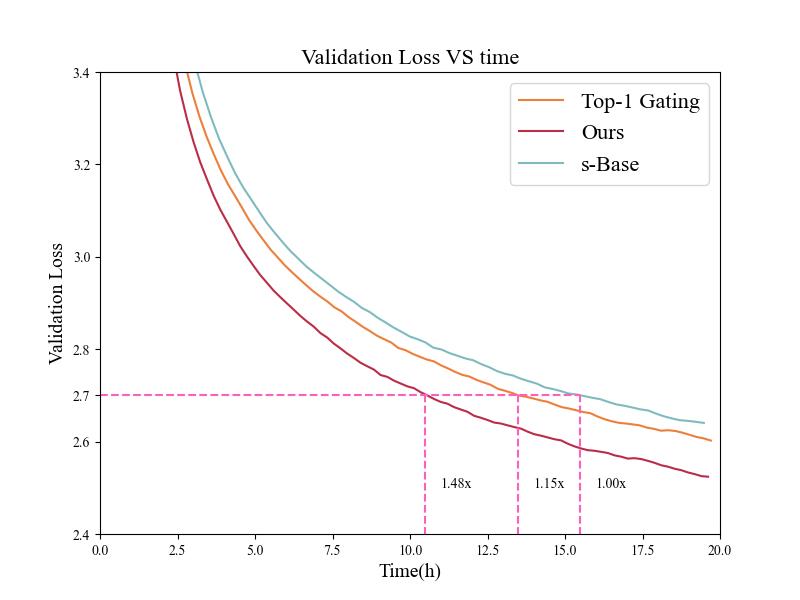
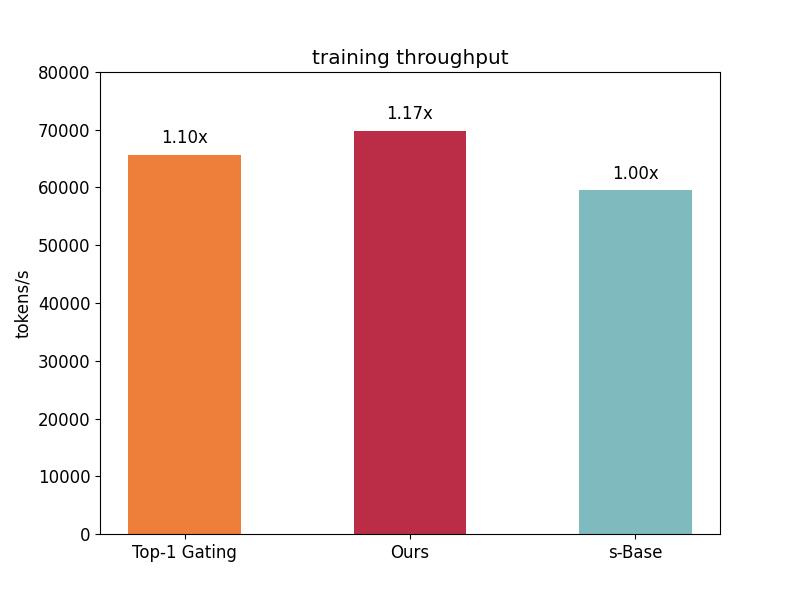
此外,我们也分析了自研算法和 Top-1 Gating、s-BASE 的训练吞吐,如下图所示,采用自研算法相比于 s-BASE 的训练吞吐提升了 1.17 倍。
基于PAI DLC的GPT-MoE预训练
Rapidformer为EasyNLP中各种Transformer模型提供训练加速能力,这是通过有机整合微软的DeepSpeed,英伟达的Megatron来做到的,如下图所示:

在GPT-MoE大模型的预训练中,我们用到的主要训练加速核心技术包括:
混合精度训练(Mixed Precision Training)采用混合精度训练的好处主要有以下两点:1. 减少显存占用,由于FP16的内存占用只有FP32的一半,自然地就可以帮助训练过程节省一半的显存空间。2. 加快训练和推断的计算,FP16除了能节约内存,还能同时节省模型的训练时间。具体原理如下图所示,核心是在反向传播参数更新的时候需要维护一个FP32的备份来避免舍入误差,另外会通过Loss Scaling来缓解溢出错误。
选择性激活重算(Selective Activation Recomputation)在神经网络中间设置若干个检查点(checkpoint),检查点以外的中间结果全部舍弃,反向传播求导数的时间,需要某个中间结果就从最近的检查点开始计算,这样既节省了显存,又避免了从头计算的繁琐过程。实际使用时,有些layers产生的激活值大但是计算量小,需要选择性的过滤掉这一部分的激活值,保留重要的激活值,以节省重计算量。
Zero优化器状态切分 (The Zero Redundancy Optimizer)是一种用于大规模分布式深度学习的新型内存优化技术。ZeRO具有三个主要的优化阶段分别对应于优化器状态,梯度和参数的划分。我们这里使用的是Zero-1优化器状态分区。
序列并行 (Sequence Parallelism)是一种对长序列进行切分从而加速训练的技术,在Tensor Parallelism的基础上,将Transformer核的LayerNorm以及Dropout层的输入按Sequence Length维度进行了切分,使得各个设备上面只需要做一部分的Dropout和LayerNorm即可。这样做的好处有两个:1. LayerNorm和Dropout的计算被平摊到了各个设备上,减少了计算资源的浪费;2. LayerNorm和Dropout所产生的激活值也被平摊到了各个设备上,进一步降低了显存开销。
接下来我们通过PAI-DLC产品来演示如何执行GPT-MoE的基础预训练。
环境准备
首先通过阿里云产品机器学习平台PAI页进入容器训练DLC创建新的训练任务,如下图所示。
有三个关键的地方需要配置,分别是专属镜像,数据集以及执行命令。节点镜像地址配置为:http://pai-image-manage-registry.cn-shanghai.cr.aliyuncs.com/pai/pai-rf-image-poc-moe:0.2。执行命令配置为:
cd /workspace/RapidformerPro/examples/megatron &&
bash dlc_run_pretrain_megatron_gpt.sh run 1 jiebabpe 0.125B 8 0 1 1 sel none 10000其中dlc_run_pretrain_megatron_gpt.sh可以从EasyNLP的github中获取:https://github.com/alibaba/EasyNLP/blob/master/examples/rapidformer/gpt_moe/run_pretrain_megatron_gpt.sh 传递给dlc_run_pretrain_megatron_gpt.sh的主要有以下11个参数,分别是:
MODE=$1 #run or debug
GPUS_PER_NODE=$2 #申请的卡数
TOKENIZER=$3 #中文jiebabpe,英文gpt2bpe
MODEL_SIZE=$4 #0.125B, 0.35B, 1.3B, 3.6B 等等
MOE=$5 #专家数量
RT=$6 #路由类型
BATCH_SIZE=$7 #batch size
TP=$8 #模型并行度
AC=$9 #激活检查点类型
ZERO=$10 #是否打开zero-1
SAVE_INTERVAL=$11 #报错ckpt的step数
资源&数据准备
由于预训练数据集体积比较大,采用下载的方式不是很方便。借助于DLC提供的OSS路径的挂载功能,可以很方便的直接使用存储在OSS上的大规模预训练数据集。

任务资源配置建议使用单机八卡A100来训练1.3B以上的GPT-MoE模型。

任务创建
任务创建完成后,进入任务监控页面观察任务执行状态,如下所示:

点击日志查看运行状态,如下所示:

基于PAI DSW的GPT-MoE微调诗歌生成
使用DLC完成GPT-MoE的基础预训练后,还需要对模型进行微调才能在下游任务生成领域比如诗歌,小说,文等领域获得比较好的生成效果。接下来我们通过PAI-DSW产品来演示如何执行GPT-MoE的下游任务微调。我们以0.35B+MoE64的GPT大模型为例,尝试对诗歌生成任务进行微调来获得比较好的生成效果。
环境准备
首先创建DSW任务,资源类型选择单机八卡V100-32G,如下所示:

由于预训练checkpoint体积比较大,采用下载的方式不是很方便。借助于DSW提供的OSS路径的挂载功能,可以很方便的直接使用存储在OSS上的预训练模型来进行下游任务微调,配置方法如下图所示。

接着配置镜像,采用和DLC中同样的镜像地址:http://pai-image-manage-registry.cn-shanghai.cr.aliyuncs.com/pai/pai-rf-image-poc-moe:0.2

创建好后,点击打开进入到DSW交互式开发环境

数据准备
首先,您需要下载用于本示例的训练和测试集,并创建保存模型的文件夹,命令如下:
!wget https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/text_generation_datasets/poetry/train.tsv
!wget https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/text_generation_datasets/poetry/dev.tsv--2023-01-05 06:45:39-- https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/text_generation_datasets/poetry/train.tsv
Resolving atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com (atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com)... 47.101.88.27
Connecting to atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com (atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com)|47.101.88.27|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 43411824 (41M) [text/tab-separated-values]
Saving to: ‘train.tsv’
train.tsv 100%[===================>] 41.40M 33.2MB/s in 1.2s
2023-01-05 06:45:40 (33.2 MB/s) - ‘train.tsv’ saved [43411824/43411824]
--2023-01-05 06:45:41-- https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/text_generation_datasets/poetry/dev.tsv
Resolving atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com (atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com)... 47.101.88.27
Connecting to atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com (atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com)|47.101.88.27|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 208167 (203K) [text/tab-separated-values]
Saving to: ‘dev.tsv’
dev.tsv 100%[===================>] 203.29K --.-KB/s in 0.1s
2023-01-05 06:45:41 (1.69 MB/s) - ‘dev.tsv’ saved [208167/208167]数据下载完成后,可以通过以下代码查看第一条数据。在训练集验证集中,每一行为一条诗歌数据。
print('Training data sample:')
! head -n 1 train.tsv
print('Development set data sample:')
! head -n 1 dev.tsvTraining data sample:
半生长以客为家,罢直初来瀚海槎。始信人间行不尽,天涯更复有天涯。
Development set data sample:
云髻高梳鬓不分,扫除虚室事元君。新糊白纸屏风上,尽画蓬莱五色云。初始化
在EasyNLP专属镜像环境下,我们首先引入模型运行需要的各种库,并做一些初始化。在本教程中,我们使用gpt-moe-0.35B+MoE64作为预训练模型底座。
from functools import partial
import torch
from megatron import get_args
from megatron.model import ModelType
from megatron.utils import (average_losses_across_data_parallel_group,
get_ltor_masks_and_position_ids)
from rapidformer.application.zeroshot_nlu.zeroshot_gpt_finetuner import \\
GPTFinetuner
from rapidformer.dataset.gpt_dataset import GPTDataset
from rapidformer.engine.engine import RapidformerEngine
from rapidformer.engine.initialize import get_tokenizer
from rapidformer.model.transformer.gpt_model import GPTModel模型训练&评估
finetuner = MegatronGPTMoEFinetuner(engine=engine)
finetuner.train()一步执行
值得一提的是,上述所有训练/评估,都已经被集成到EasyNLP/examples/rapidformer/gpt_moe/finetune_megatron_gpt.py中,可采用直接执行脚本文件EasyNLP/examples/rapidformer/gpt_moe/run_finetune_text_generation_gpt.sh的方式,一步执行上述所有训练/评估。根据脚本run_finetune_text_generation_gpt.sh,需要设置的具体参数如下:
TASK_NAME=$1 #任务名称,这里是poetry
TRAIN_DATASET_PATH=$2 #训练集路径
VALID_DATASET_PATH=$3 #验证集路径
PRETRAIN_CHECKPOINT_PATH=$4 #预训练模型路径
MODEL_SIZE=$5 #预训练模型大小
MOE=$6 #专家数量
RT=$7 #路由类型
BATCH_SIZE=$8 #batch size
EPOCH=$9 #训练轮次
TP=$10 #模型并行度
AC=$11 #激活检查点类型
ZERO=$12 #降显存类型
SEQ_LEN=$13 #序列长度sh run_finetune_text_generation_gpt.sh
poetry
/mnt/workspace/train.tsv
/mnt/workspace/train.tsv
/workspace/checkpoints/wudao-megatron-gpt-moe-64-0.35B-lr-3e-4-bs-4-gbs-256-tp-1-ac-sel-zero-none
0.35B
64
0
16
2
1
sel
none
128分析Tensorboard
分析Tensorboard,对比不同实验参数设置,比如我们选择调试训练轮次分别是2和5,观察收敛曲线的变化,如下所示:


从上图可以看出,训练轮次越大,验证集loss越低,收敛效果越好。于是我们选择训练5个epoch后的ckpt来做诗歌生成的预测
模型预测
文本生成效果预测已经被集成到EasyNLP/examples/rapidformer/gpt_moe/generate_text_gpt.py中,可采用直接执行脚本文件EasyNLP/examples/rapidformer/gpt_moe/run_text_generation_gpt.sh的方式,一步执行诗歌生成和预测。首先按照如何格式准备预测用的数据集。
[
"id": 0,
"txt": "大漠孤烟直"
,
"id": 1,
"txt": "江上归帆天际开"
]然后根据脚本run_finetune_text_generation_gpt.sh里面的参数设置,运行命令:sh run_text_generation_gpt.sh
CHECKPOINT_PATH=$1 #微调后的模型路径
MODEL_SIZE=$2 #模型大小
MOE=$3 #专家数量
SEQ_LEN=$4 #序列长度
TOP_K=$5 #topk
INPUT_SEQ_LEN=$6 #输入最大长度
OUTPUT_SEQ_LEN=$7 #输出最大长度
INPUT_FILE=$8 #输入文件路径
OUTPUT_FILE=$9 #输出文件路径sh run_text_generation_gpt.sh
/workspace/checkpoints/finetune-poetry-ckpts
0.35B
64
128
5
20
128
input_poetry
output_poetry生成结果如下:
"id": 0,
"prompt": "大漠孤烟直",
"output_poetry": "大漠孤烟直,雄哉太山岑。万古长松树,青青如碧玉。"
"id": 1,
"prompt": "江上归帆天际开",
"output_poetry": "江上归帆天际开,一帆秋色望中来。何当一洗三千丈,万里风风尽下来。"
基于PAI EAS的在线推理部署
使用DSW完成GPT-MoE在下游任务上的微调后,就可以在线部署下游文本生成任务的服务了。接下来我们通过PAI-EAS产品来演示如何执行GPT-MoE的下游任务服务的在线部署。
开发基于FasterTransformer的Processor
首先使用Faster Transformer Converter将微调后的诗歌模型进行格式转换
cd ~/RapidformerPro/examples/fastertransformer
sh run_convert.sh
model_type=$1 #模型类型:dense or moe
tokenizer=$2 #分词器类型:gpt2bpe or jiebabpe
infer_gpu_num=$3 #推理用的卡数
INPUT_DIR=$4 #微调后的模型路径名
SAVED_DIR=$5 #转换后的模型路径名然后基于EAS提供的开发参考https://help.aliyun.com/document_detail/130248.html,开发文本生成processor。核心process方法参考如下
def process(self, data):
""" process the request data
"""
data_str = data.decode('utf-8')
data_json = json.loads(data_str)
data = self.pre_proccess(data)
contexts = [data_json['inputs'][0]]
user_parameters = data_json['parameters']
max_length = int(user_parameters['max_length'])
seed = 42
top_k = int(user_parameters['top_k'])
self.top_k = top_k
self.output_len = max_length
start_ids = [
torch.IntTensor(
self.tokenzer.tokenize(
c.replace('\\\\n', '\\n').replace('\\\\"', '\\"')))
for c in contexts
]
start_lengths = [len(ids) for ids in start_ids]
start_ids = pad_sequence(start_ids,
batch_first=True,
padding_value=self.end_id)
start_lengths = torch.IntTensor(start_lengths)
torch.manual_seed(seed)
random_seed_tensor = torch.zeros([1], dtype=torch.int64)
with torch.no_grad():
tokens_batch = self.gpt(
start_ids, start_lengths, self.output_len, self.beam_width,
self.top_k *
torch.ones(size=[self.max_batch_size], dtype=torch.int32),
self.top_p *
torch.ones(size=[self.max_batch_size], dtype=torch.float32),
self.beam_search_diversity_rate *
torch.ones(size=[self.max_batch_size], dtype=torch.float32),
self.temperature *
torch.ones(size=[self.max_batch_size], dtype=torch.float32),
self.len_penalty *
torch.ones(size=[self.max_batch_size], dtype=torch.float32),
self.repetition_penalty *
torch.ones(size=[self.max_batch_size], dtype=torch.float32),
random_seed_tensor, self.return_output_length,
self.return_cum_log_probs)
if self.return_cum_log_probs > 0:
tokens_batch, _, cum_log_probs = tokens_batch
print('[INFO] Log probs of sentences:', cum_log_probs)
outputs = []
batch_size = min(len(contexts), self.max_batch_size)
outputs_token = np.ones([batch_size, self.output_len], dtype=int)
tokens_batch = tokens_batch.cpu().numpy()
for i, (context, tokens) in enumerate(zip(contexts, tokens_batch)):
for beam_id in range(self.beam_width):
token = tokens[beam_id][:start_lengths[i] +
self.output_len]
token = token[~np.isin(token, torch.tensor([7]))]
output = self.tokenzer.detokenize(token)
outputs.append(output)
print(f'[INFO] batch i, beam'
f' beam_id:'
f' \\n[Context]\\ncontext\\n\\n[Output]\\noutput\\n')
output_token = tokens[beam_id][
start_lengths[i]:start_lengths[i] + self.output_len]
outputs_token[i] = output_token
outputs = [o.replace('\\n', '\\\\n') for o in outputs]
result_dict = 'text': outputs[0]
return get_result_str(result_dict=result_dict)搭建在线服务


基于ModelScope的在线文本生成演示
我们已经搭建了诗歌,广告文案,作文三个文本生成服务,具体的在线体验地址是:https://www.modelscope.cn/organization/PAI

我们可以修改modelscope页面上的README.md信息来设计应用样式
tasks:
- text-generation
widgets:
- examples:
- name: 1
title: 诗歌生成
inputs:
- name: text
data: 大漠孤烟直
parameters:
- name: max_length
type: int
value: 128
- name: top_k
type: int
value: 5在modelscope上呈现出来的效果如下所示:

参考文献
[1] . Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
[2]. GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
[3]. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
[4]. BASE Layers: Simplifying Training of Large, Sparse Models
[5]. Hash Layers For Large Sparse Models
[6]. TAMING SPARSELY ACTIVATED TRANSFORMER WITH STOCHASTIC EXPERTS
[7]. GLaM: Efficient Scaling of Language Models with Mixture-of-Experts
[8]. Unified Scaling Laws for Routed Language Models
[9]. Designing Effective Sparse Expert Models
[10]. Large Margin Deep Networks for Classification
作者:李鹏,王玮,陈嘉乐,黄松芳,黄俊
单位:阿里云智能机器学习平台PAI & 达摩院自然语言基础技术
本文为阿里云原创内容,未经允许不得转载。
以上是关于基于单机最高能效270亿参数GPT模型的文本生成与理解的主要内容,如果未能解决你的问题,请参考以下文章
千亿参数大模型首次被撬开!Meta复刻GPT-3“背刺”OpenAI,完整模型权重及训练代码全公布...
千亿参数大模型首次被撬开:Meta复刻GPT-3“背刺”OpenAI,完整模型权重及训练代码全公布