4. 非监督学习与强化学习简介
Posted starrow
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了4. 非监督学习与强化学习简介相关的知识,希望对你有一定的参考价值。
1.2 非监督学习
机器学习的第二种范式是非监督学习(Unsupervised learning),目标是从数据中找出模式。监督学习接收的是有标记的数据,非监督学习处理的则是没有标记的数据。换句话说,非监督学习没有已知的输出作为标准,而是试图发现数据中存在的模式。根据模式的性质,非监督学习可分为两个领域。
一个领域是聚类分析,根据数据实例的相似性将它们划分进不同的集群。聚类分析有许多应用,例如,对像素聚类能够分割图像,对词语聚类可以找出同义词,对文章聚类能够将它们按主题归档。
另一领域是关联规则分析,找出数据中经常一同出现的项集,然后建立它们之间的关联规则:对于项集A和B,如果它们的并集出现的概率与A出现的概率之比超过一定的阈值,我们就认为“A蕴含B”为一条规则,意为当A出现时,很可能会出现B。例如,一家超市的老板发现顾客同时购买牛腩和白萝卜的次数很多,并且每当一位顾客购买牛腩时,他也买白萝卜的可能性很大,老板就建立起一条“牛腩蕴含白萝卜”的关联规则。关联规则分析的应用广泛,除了最常见的购物篮分析,还可以分析时间序列数据,从中找出某些事件的触发器;用于故障分析,在众多因素中找出故障的原因等。
1.3 强化学习
让我们来思考人是怎样学骑自行车的。会骑自行车的读者可以回忆,不会骑的也可以凭经验和想象思考。假如学骑自行车是监督学习,就应该有人告诉你,这个状态下左腿应该用多大力踩踏板,下个场景里身体应该往哪边倾斜多少度。而实际上,虽然你的父亲或朋友会给一些指导意见,但远不是监督学习中训练数据那样具体的输入到输出的映射。学骑自行车也不是非监督学习,因为你不是看了3小时别人骑车的录像,总结出其中的运动模式,然后就神奇地迈上一辆自行车开始骑了。你是通过尝试和练习,或者说试错(Trial and error),学会骑车的,所有的经验(相当于数据)都来自于人与自行车和道路等构成的环境的互动:人对身体各部位的肌肉发出指令,感受下一刻人和车的姿态和运动,并接收相应的“奖励”或“惩罚”——身体保持平衡、成功向右拐、在红灯前停住车等是奖励,失衡、摔倒、撞到栏杆、刮到行人等是惩罚——再调整姿势和力量,感受人和车的状态,接收奖励或惩罚……
强化学习(Reinforcement learning)[[1]]就是研究上述过程所代表的学习类型——主体通过与环境互动来学会控制自己的行为,以最大化某种累积的奖励[[2]]。如图1.10所示,主体从环境获得反馈,将其解释为状态和奖励,据此做出动作,导致环境发生改变,重新反馈给主体,从而构成了主体与环境之间交互作用的循环。
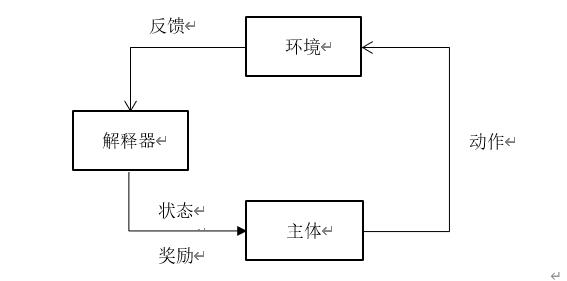
图1.10 强化学习的过程
在此过程中主体注重长期的而非即时的奖励,意味着大的奖励未必是一个动作的直接后果,而是由一系列动作导致的。例如,在开始下坡时缓缓刹车,并不会产生即时的奖励,但能够避免车速越来越快以致最终失控。此外,强化学习的环境通常带有随机性(Stochastic),即在同样的状态下采取同样的动作,可能导致不同的状态、获得不同的奖励。例如,在骑车时,风、路况、行人和车辆等因素都具有随机性。
相较于监督和非监督学习,强化学习最接近人们日常理解的学习,所以其取得的进展也最引人注目:在作为智力竞技代表项目的国际象棋和围棋上,计算机程序从被人类棋手轻视,发展到职业选手承认无法战胜。波士顿动力公司制造的机器狗远比木牛流马聪明。斯坦福大学开发的无人驾驶直升机可以做出人类无法企及的炫目动作。
监督和非监督学习在任务和理论上有共通之处,将是本书正文分析的重点。强化学习与监督和非监督学习迥异,难以在同一本书的篇幅内深入讨论,下面将仅简单介绍其基本理论和解决思路。
[[1]] 强化学习的术语和理论源自行为心理学的操作性条件反射(Operant conditioning),强化指的是通过奖励促进主体的某种行为。例如在实验中老鼠按下某个杠杆会得到食物,它按下该杠杆的频率就会增加。
[[2]] 将奖励视为一个标量,惩罚就是一个负值的奖励。
以上是关于4. 非监督学习与强化学习简介的主要内容,如果未能解决你的问题,请参考以下文章