Java花费数十小时,带你体验Java文档搜索引擎的实现过程
Posted 意愿三七
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java花费数十小时,带你体验Java文档搜索引擎的实现过程相关的知识,希望对你有一定的参考价值。
Java文档搜索引擎
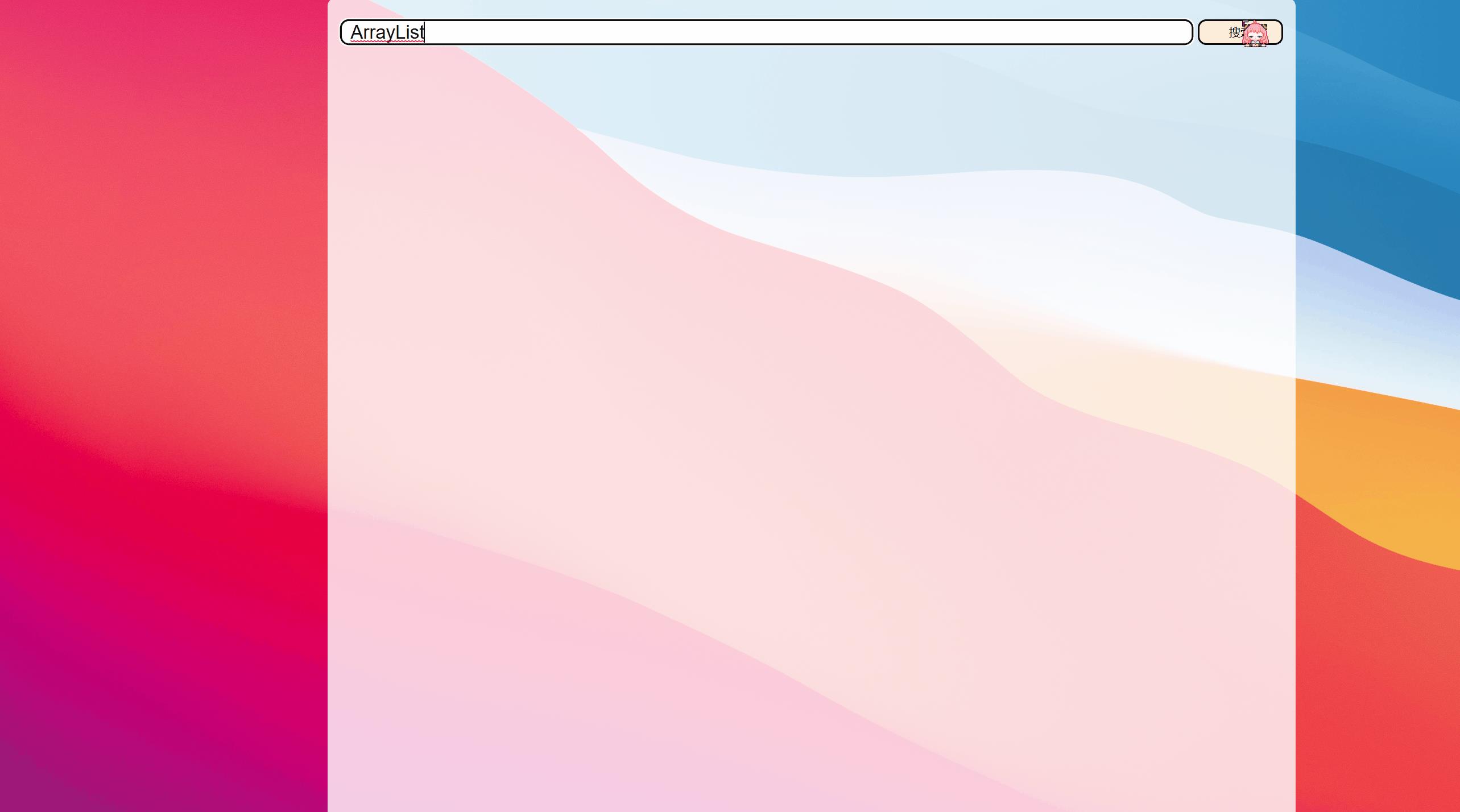
- 项目运行效果
项目运行效果
一、简述搜索引擎概念
我们先来看看搜索引擎是啥?
我们经常使用的百度搜索引擎就是一个这样的,看起来页面很简单,但是里面的代码是十分的复杂的。

我们去搜索其实就发现搜索引擎核心功能就是查找到一组和用户输入的词or一句话
像这个蛋糕两个字,我们称它为查询词,我们搜索到的内容也是要和查询词有相关性。

一般搜索到的内容也差不多是这样的,当然有的显示出来的结果会更加多一点内容。

当我们点击进去会跳转到详细页面(落地页)
二、搜索引擎实现思路
对于搜索引擎来说,首先需要获取很多的网页,然后在根据用户输入的查询词,在这些网页中查找。
但是我们有以下问题:
- 搜索引擎的页面是怎么获取到的?
答:此处主要涉及到“爬虫”这样的程序,其实爬虫也就是Http客户端程序,它也是发送一些请求,响应一些结果,像百度,搜狗每天都有好多这样的程序,去爬互联网的各各网站,把数据收集处理。- 用户输入了查询词之后,如何让查询词和当前这些网页进行匹配呢?
答:假设我们使用暴力搜索的话,如果我们现在有一亿条数据,那么我们需要把查询词,去在一亿里面找,那这样我们的效率是很低的,我们的搜索引擎肯定是希望一敲回车马上出结果。这样肯定是不行的,所以我们需要一种数据结构,使用倒排索引这样的数据结构,这个数据结构在搜索引擎是十分重要的。
2.1倒排索引介绍
我们先来认识一下专业词:
-
文档(document):指的是每个待搜索的网页
-
正排索引:指的是
文档id到文档内容,给你一个文档id可以快速的查到对应的内容- 文档id:当我们爬取了很多信息的时候,需要把每个信息加个id区分,像身份证号码,彼此不重复
-
倒排索引:指的是
词到文档id列表的映射关系,倒排索引正好和正排索引相反,随便给你个词,问你在那个文档里面出现过 ,所以肯定有很多词在内容出现过,所以给的是一个列表。- 词:文档内容并不是完全孤立,内容里面包括很多段落,句子,句子里面呢又有很多词
来个简单的例子:
现在我们有2个文档:
- 正排索引
| 文档ID | 文章 |
|---|---|
| 1 | 雷军发布了小米手机 |
| 2 | 雷军买了两斤小米 |
根据文档ID=1,我们就可以很快找到第一个内容,根据文档ID=2,我们就可以很快找到第二个内容,这样的结构就是正排索引
- 倒排索引
| 词 | 词出现过的文档ID |
|---|---|
| 雷军 | 1,2 |
| 发布 | 1 |
| 买 | 2 |
| 了 | 1, 2 |
| 小米 | 1,2 |
| 手机 | 1 |
上面这样的,根据词出现在哪个文档中,找出它的ID,这样的过程就构成了倒排索引。
当然上面是这样约定,只不过大家效果这样的形式,你也可以反正来 。 QAQ
其实我们平时打游戏的时候也经常遇到倒排索引这样的专业词。
用王者荣耀举例:里面有个叫做妲己的英雄,她有三个技能
1技能:群体伤害
2技能:眩晕技能
3技能:群体伤害
这样的类似于正排索引,根据 英雄名字 到 英雄技能
现在我们这样问,哪一个英雄的2技能有眩晕效果啊?
有这些英雄:1.妲己,2.小鲁班(靠近敌人)…
这样根据英雄的技能到英雄的名字
2.2项目目标
实现一个针对Java文档的搜索引擎
像百度,bing这样的搜索引擎,都是属于“全站搜索”,搜索整个互联网上所有的网站。
还有一类搜索引擎,称为“站内搜索” 只针对某个网站内部的内容进行搜索,像知乎啊,百度贴吧这样的,也就是我们现在的目标。
我们先来看看java文档网站Java文档地址
但是我们发现这个网站没有 搜索框 太不方便了吧!!!所以我们就来做一个!!!
–
2.3获取java文档
刚刚我们说了,想要搜索到内容,就得有网页,才可以制作倒排索引,搜索出来。
我们有两种方式获取:
- 通过爬虫获取文档
- 直接从官方网站上下载压缩包
我们使用第二种,直接下载即可,不需要通过爬虫来实现了。
网站地址:点击跳转下载
下载好了之后打开
打开里面的一个html和官方文档的对比一下,发现是一样的。
官方文档:
本地文档:
其实重点的是我们对比一下它们路径的关系:右击在新窗口打开链接
我们发现还是存在一定的关联关系,从docs后面都是一样的,只是前面不一样,前面是我们自己创建的路径。
针对于这样的关系,我们可以在本地基于离线文档来制做索引,当用户在搜索结果页点击具体的搜索结果的时候,就自动跳转到在线文档的页面。
2.4模块划分
- 索引模块
1)扫描下载到的文档,分析文档的内容,构建出正排索引+倒排索引,并且把索引内容保存到文件中
2)加载制作好的索引,并提供一些API实现查询正排和查倒排这样的功能
2.搜索模块
调用索引模块,实现一个搜索的完整过程
输入:用户的查询词
输出:完整的搜索结果(包含了很多记录,每个记录就有标题,描述,展示url,并且能够跳转)
3.web模块
需要实现一个web模块程序,能够通过网页的形式来和用户进行交互(包含前端和后端)
2.5创建项目
直接创建Maven项目即可
2.6认识分词
用户在搜索引擎中,输入的查询词不一定就真的是一个词 ,也有可能是一句话。
分词就是把一个完整的句子给切分成多个词
我要买白菜 分成词 我/要/买/白菜/
对于人分词这个操作很简单,对于机器来说,我们要通过代码来分词,会困难很多。
典型的列子:
我一把把车把把住 我也想过过儿过的生活
哈哈哈 这样的是不是很难的。
但是相比之下英文的分词就很简单,因为天然中间有空格。
这样的情况我们使用第三方库来实现。
当然那些百度啥的,别人有团队自己做分词库,比我们开源的要准确不少。
2.7分词的原理
-
基于词库
尝试把所有的“词” 都进行穷举,把这些穷举的结果放到词典文件中
然后就可以依次的取句子中的内容,每隔一个字,在词典查一下,每隔两个字查一下当然还是有些词是不准确的,那些网络流行词就不得行。
-
基于统计
收集到很多很多的“语料库” 相当于人工标准,就知道了那些词在一起的概率比较大。
分词的实现,就是属于“人工智能”典型的应用场景,训练模型。
2.8使用第三方分词库
java第三方的分词库挺多的,我们直接使用 ansj 这个库。
<!-- https://mvnrepository.com/artifact/org.ansj/ansj_seg -->
<dependency>
<groupId>org.ansj</groupId>
<artifactId>ansj_seg</artifactId>
<version>5.1.6</version>
</dependency>
如果是红色的就点刷新,没有报红也点一下:
我们来写个代码:
import org.ansj.domain.Term;
import org.ansj.splitWord.analysis.ToAnalysis;
import java.util.List;
/**
* Created by Lin
* Description:
* User: Administrator
* Date: 2022-12-14
* Time: 19:29
*/
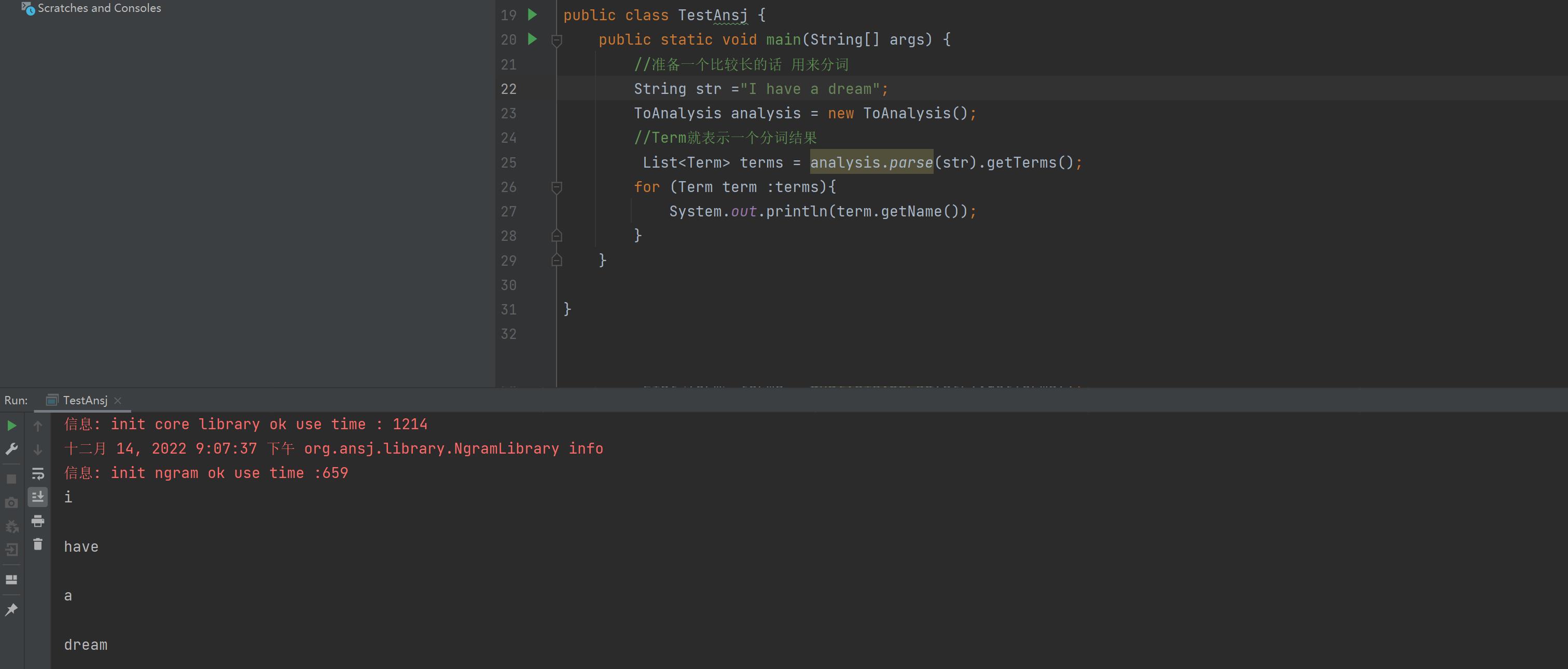
public class TestAnsj
public static void main(String[] args)
//准备一个比较长的话 用来分词
String str ="小明毕业于清华大学,后来又去蓝翔技校和新东方去深照,擅长使用计算机控制挖掘机来炒菜。";
ToAnalysis analysis = new ToAnalysis();
//Term就表示一个分词结果
List<Term> terms = analysis.parse(str).getTerms();
for (Term term :terms)
System.out.println(term.getName());
我们使用的是ToAnalysis 如果idea爆红自己手动导入一下包。
我们使用的是parse()这个方法,但是这个方法返回的是一个第三方词库自己的Result类型,我们想获取一个类似于List的集合,所以我们使用getTerms()这个方法,返回的是List类型。

然后运行结果就是:

词已经分好了,但是我们看见这个有红色的玩意是啥**,其实是在分词的时候,其实会加载一些词典文件,通过这些词典文件能够加快分词速度,提高准确率,但是没有这些词典文件,ansj也可以快速准确分出词**,
注意英文 大小会变成小写。
三、实现索引模块-parser类
接下来我们实现索引模块
我们期望这个类,去读取我们之前下载好的文档,并完成索引的制作。
我们首先创建一个Parser类里面实现制作索引数据结构
这个类具体要做的事情就这几点:
1.根据指定的路径去枚举出该路径中所有的文件(所有子目录的html文件),这个过程需要把全部子目录的文件全部获取到
2.针对上面罗列出的路径,打开文件,读取文件内容,并进行解析.并构建索引
3.把内存中构造好的索引数据结构,保存到指定的文件中
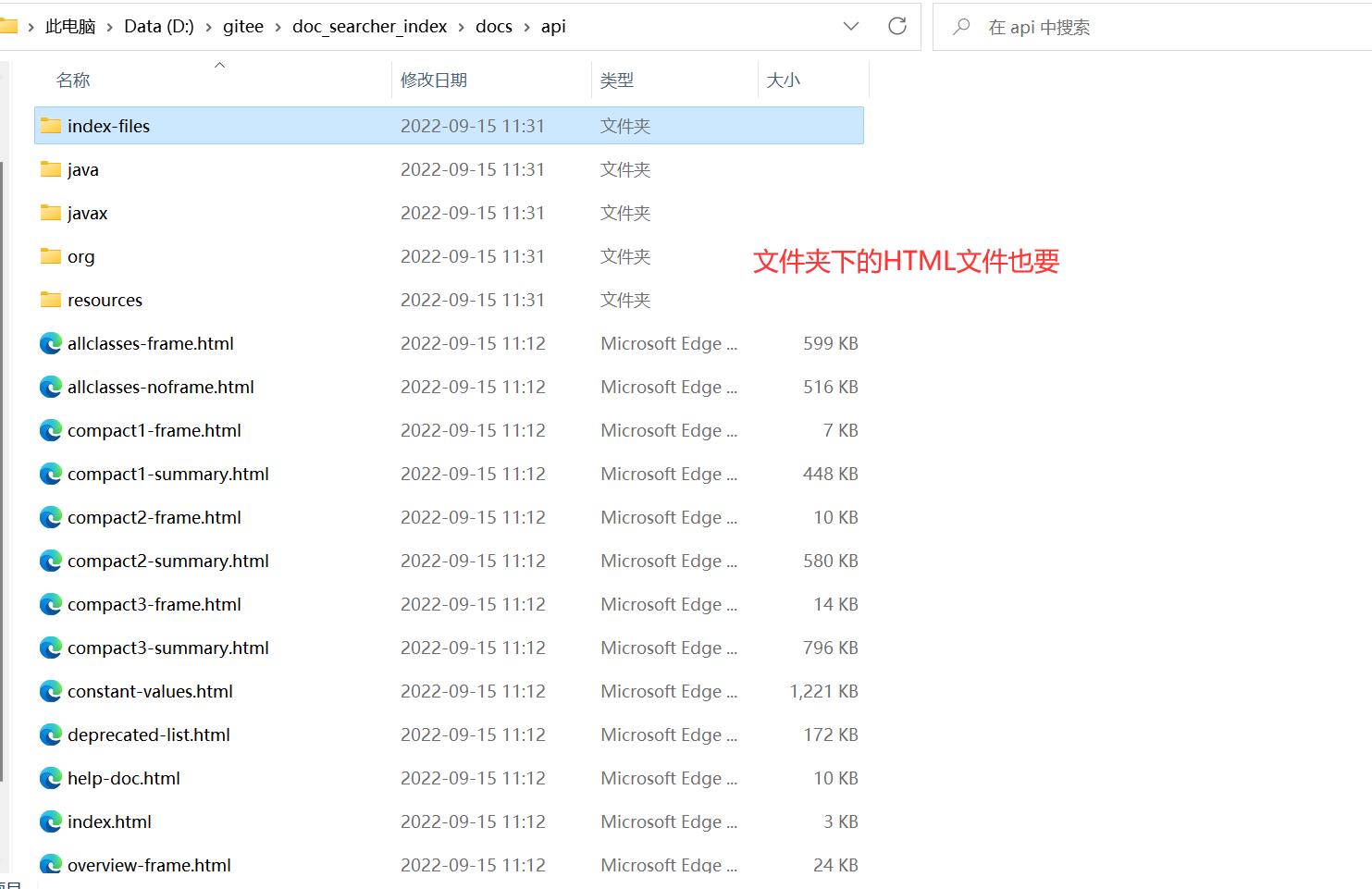
我们来看看第一点是啥意思:
因为官方的文档都是放在api那个文件夹下,所以我们要那个文件夹下的全部内容:
第二点的意思就是:就是那个文件夹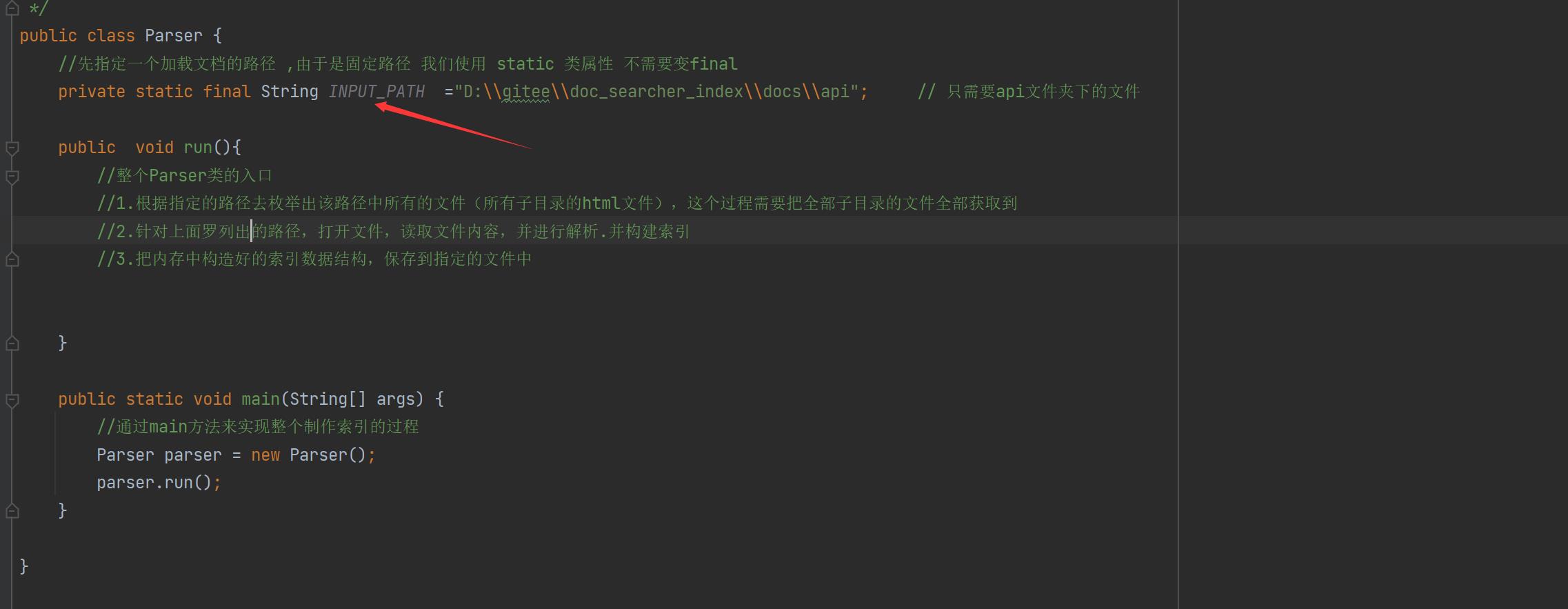
第三点的意思是:把做好的索引放到一个文件中,以后让程序读取索引。
当前阶段代码块:
public class Parser
//先指定一个加载文档的路径 ,由于是固定路径 我们使用 static 类属性 不需要变final
private static final String INPUT_PATH ="D:\\\\gitee\\\\doc_searcher_index\\\\docs\\\\api"; // 只需要api文件夹下的文件
public void run()
//整个Parser类的入口
//1.根据指定的路径去枚举出该路径中所有的文件(所有子目录的html文件),这个过程需要把全部子目录的文件全部获取到
//2.针对上面罗列出的路径,打开文件,读取文件内容,并进行解析.并构建索引
//3.把内存中构造好的索引数据结构,保存到指定的文件中
public static void main(String[] args)
//通过main方法来实现整个制作索引的过程
Parser parser = new Parser();
parser.run();
3.1 实现索引模块-递归枚举文件
枚举全部文件然后放到集合里,先上代码:
import java.io.File;
import java.util.ArrayList;
/**
* Created by Lin
* Description:
* User: Administrator
* Date: 2022-12-15
* Time: 19:15
*/
public class Parser
//先指定一个加载文档的路径 ,由于是固定路径 我们使用 static 类属性 不需要变final
private static final String INPUT_PATH ="D:\\\\gitee\\\\doc_searcher_index\\\\docs\\\\api"; // 只需要api文件夹下的文件
public void run()
//整个Parser类的入口
//1.根据指定的路径去枚举出该路径中所有的文件(所有子目录的html文件),这个过程需要把全部子目录的文件全部获取到
ArrayList<File> fileList = new ArrayList<>();
enumFile(INPUT_PATH,fileList);
//2.针对上面罗列出的路径,打开文件,读取文件内容,并进行解析.并构建索引
//3.把内存中构造好的索引数据结构,保存到指定的文件中
System.out.println(fileList);
//看看文件个数
System.out.println(fileList.size());
//第一个参数表示从那个目录开始进行遍历,第二个目录表示递归得到的结果
private void enumFile(String inputPath, ArrayList<File> fileList)
//我们需要把String类型的路径变成文件类 好操作点
File rootPath = new File(inputPath);
//listFiles()类似于Linux的ls把当前目录中包含的文件名获取到
//使用listFiles只可以看见一级目录,想看到子目录需要递归操作
File[] files = rootPath.listFiles();
for (File file : files)
//根据当前的file的类型,觉得是否递归
//如果file是普通文件就把file加入到listFile里面
//如果file是一个目录 就递归调用enumFile这个方法,来进一步获取子目录的内容
if (file.isDirectory())
//根路径要变
enumFile(file.getAbsolutePath(),fileList);
else
//普通文件
fileList.add(file);
public static void main(String[] args)
//通过main方法来实现整个制作索引的过程
Parser parser = new Parser();
parser.run();
这里我们是创建了一个enumFile()方法,使用listFile()这个函数可以获取目标路径下的当前目录
获取所有的文件的思路就是:判断是否是目录还是文件,是文件的话就把文件加入到 ArrayList fileList = new ArrayList<>()这个里面; 是目录就继续进函数里面递归,具体看代码注释。
最后看结果:
发现不止只有HTML文件还要其他的文件,我们应该去除它,只有HTML文件
3.2 排除非HTML文件
排除非HTML文件其实思路很简单,只需要判断文件的后缀是什么就可以了,可以使用endWith()这个函数进行识别,
import java.io.File;
import java.util.ArrayList;
/**
* Created by Lin
* Description:
* User: Administrator
* Date: 2022-12-15
* Time: 19:15
*/
public class Parser
//先指定一个加载文档的路径 ,由于是固定路径 我们使用 static 类属性 不需要变final
private static final String INPUT_PATH ="D:\\\\gitee\\\\doc_searcher_index\\\\docs\\\\api"; // 只需要api文件夹下的文件
public void run()
//整个Parser类的入口
//1.根据指定的路径去枚举出该路径中所有的文件(所有子目录的html文件),这个过程需要把全部子目录的文件全部获取到
ArrayList<File> fileList = new ArrayList<>();
enumFile(INPUT_PATH,fileList);
//2.针对上面罗列出的路径,打开文件,读取文件内容,并进行解析.并构建索引
//3.把内存中构造好的索引数据结构,保存到指定的文件中
System.out.println(fileList);
System.out.println(fileList.size());
//第一个参数表示从那个目录开始进行遍历,第二个目录表示递归得到的结果
private void enumFile(String inputPath, ArrayList<File> fileList)
//我们需要把String类型的路径变成文件类 好操作点
File rootPath = new File(inputPath);
//listFiles()类似于Linux的ls把当前目录中包含的文件名获取到
//使用listFiles只可以看见一级目录,想看到子目录需要递归操作
File[] files = rootPath.listFiles();
for (File file : files)
//根据当前的file的类型,觉得是否递归
//如果file是普通文件就把file加入到listFile里面
//如果file是一个目录 就递归调用enumFile这个方法,来进一步获取子目录的内容
if (file.isDirectory())
//根路径要变
enumFile(file.getAbsolutePath(),fileList);
else
//只针对HTML文件
if(file.getAbsolutePath().endsWith(".html"))
//普通HTML文件
fileList.add(file);
public static void main(String[] args)
//通过main方法来实现整个制作索引的过程
Parser parser = new Parser();
parser.run();
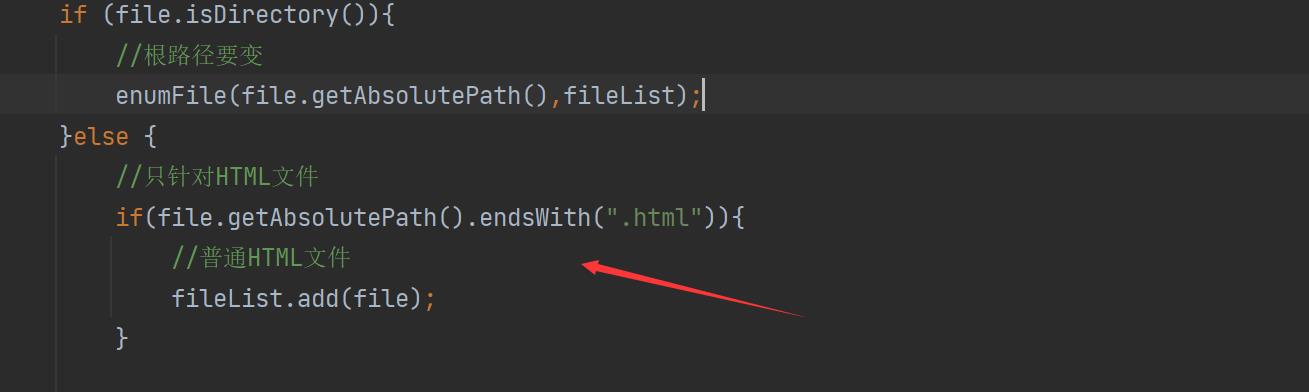
只加了这个的一个判断即可。
3.3 实现索引模块-解析HTML
解析HTML的意思就是:我们一条搜索结果包含了标题,描述,展示URL,这些信息就是来着于要解析的HTML
因此当前的解析HTML操作,就是要把整个HTML文件的标题,描述,URL获取到,其实我们重点要理解这个描述是个啥东西呢?
描述:我们可以视为是正文的一段摘要
因此要想得到描述,就先得到整个正文,所以我们先不管描述,先想办法得到正文。
所以我们的当前任务就是:
- 解析出HTML标题
- 解析出HTML对应的文章
- 解析出HTML对应的正文(有正文才有后续的描述)
import java.io.File;
import java.util.ArrayList;
/**
* Created by Lin
* Description:
* User: Administrator
* Date: 2022-12-15
* Time: 19:15
*/
public class Parser
//先指定一个加载文档的路径 ,由于是固定路径 我们使用 static 类属性 不需要变final
private static final String INPUT_PATH ="D:\\\\gitee\\\\doc_searcher_index\\\\docs\\\\api"; // 只需要api文件夹下的文件
public void run()
//整个Parser类的入口
//1.根据指定的路径去枚举出该路径中所有的文件(所有子目录的html文件),这个过程需要把全部子目录的文件全部获取到
ArrayList<File> fileList = new ArrayList<>();
enumFile(INPUT_PATH,fileList);
//2.针对上面罗列出的路径,打开文件,读取文件内容,并进行解析.并构建索引
for (File f :fileList)
//通过这个方法解析单个HTML文件
System.out.println("开始解析:" + f.getAbsolutePath());
parseHTML(f);
//3.把内存中构造好的索引数据结构,保存到指定的文件中
// System.out.println(fileList);
// System.out.println(fileList.size());
//通过这个方法解析单个HTML文件
private void parseHTML(File f)
// 1. 解析出HTML标题
String title = parseTitle(f);
// 2. 解析出HTML对应的文章
String url = parseUrl(f);
// 3. 解析出HTML对应的正文(有正文才有后续的描述)
String content = parseContent(f);
private String parseContent(File f)
private String parseUrl(File f)
private String parseTitle(File f)
//第一个参数表示从那个目录开始进行遍历,第二个目录表示递归得到的结果
private void enumFile(String inputPath, ArrayList<File> fileList)
//我们需要把String类型的路径变成文件类 好操作点
File rootPath = new File(inputPath);
//listFiles()类似于Linux的ls把当前目录中包含的文件名获取到
//使用listFiles只可以看见一级目录,想看到子目录需要递归操作
File[] files = rootPath.listFiles();
for (File file : files)
//根据当前的file的类型,觉得是否递归
//如果file是普通文件就把file加入到listFile里面
//如果file是一个目录 就递归调用enumFile这个方法,来进一步获取子目录的内容
if (file.isDirectory())
//根路径要变
enumFile(file.getAbsolutePath(),fileList);
else
//只针对HTML文件
if(file.getAbsolutePath().endsWith(".html"))
//普通HTML文件
fileList.add(file);
public static void main(String[] args)
//通过main方法来实现整个制作索引的过程
Parser parser = new Parser();
parser.run();
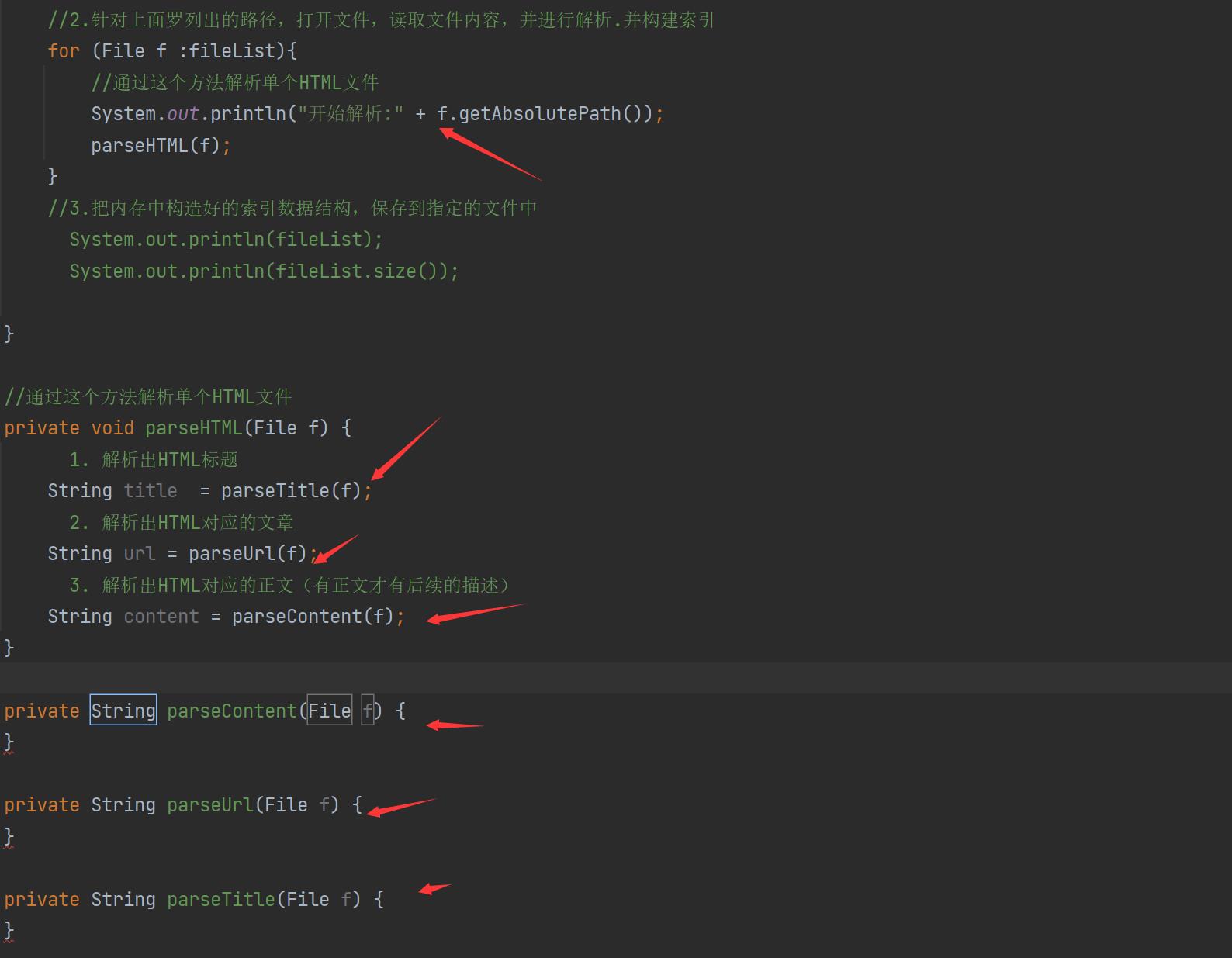
本小节我们增加了解析HTML类,和解析我们需要用到的内容,标题,URL类。
3.4 实现索引模块-解析标题
接下来我们就开始进行解析HTML标题
思路有其二:
- 找到HTML文件的title标签中的内容就标题
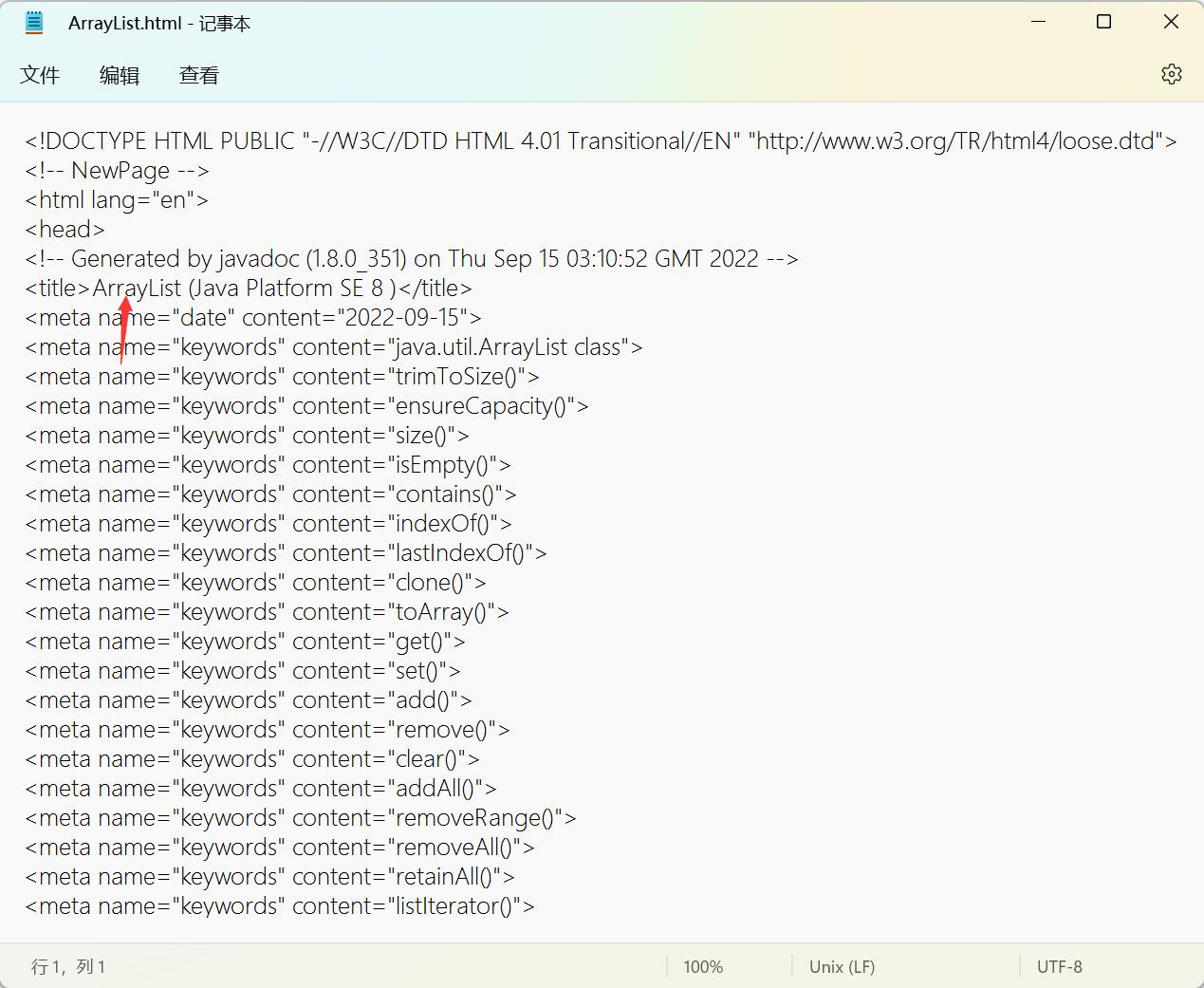
- 获取文件名获取具体的HTML标题,每个文件名好像和HTML的标题是差不多的。
所以我们直接选择获取文件名,来获取标题。
这里我们使用的是getName()函数:

输出结果就获取到了HTML文件名

我们需要的搜索结果是标题,不需要带后缀,要去掉
去掉后缀实现思路:使用substring()来实现
这里有个小问题,我们要如何刚刚好把 .html给去掉,这个substring()有个版本是前闭后开,我们只需要找出总长度减去.html的长度即可得到.html的前面部分:
public static void main(String[] args)
File f = new File("D:\\\\gitee\\\\doc_searcher_index\\\\docs\\\\api\\\\java\\\\util\\\\ArrayList.html");
System.out.println(f.getAbsolutePath());
System.out.println(f.getName().substring(0,f.getName().length()-".html".length()));
.html也是字符串可以使用length();
parseTitle()的实现:
private String parseTitle(File f)
//获取文件名
String name = f.getName();
return name.substring(0,name.length()-".html".length());
–
3.5 实现索引模块-解析url的思路
其实真正的搜索引擎的展示url和跳转的url是不一样的:有的要先经过搜索引擎的服务器然后在到页面

但是我们这里就不要考虑那么多辣,直接都使用一个url就可以了,既可以展示,也可以跳转。
有人在想为什么要跳到搜索引擎的服务器,因为有如下原因:
- 如果是广告结果 ,需要根据点击计费
- 自然搜索结果的话,需要根据点击来优化用户体验
我们实现url的思路:
因为我们最终期望的效果是:用户点击搜索结果,就能够跳转到对应的线上文档的页面
- 然后我们发现
以上是关于Java花费数十小时,带你体验Java文档搜索引擎的实现过程的主要内容,如果未能解决你的问题,请参考以下文章