VMware 虚拟机安装 hadoop 2.6.0 完全分布式集群
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了VMware 虚拟机安装 hadoop 2.6.0 完全分布式集群相关的知识,希望对你有一定的参考价值。
最近连着搭了两次hadoop的集群,搭建的时候也碰到了一些问题,因为之前对linux 不熟悉,经常遇到各种问题和命令忘记写,幸亏有度娘谷哥,这里做一个记录 下次使用的时候用的上
计算机的配置
计算机:
G3440 3.3G 双核
8G内存
虚拟机:
vmware workstation 12 pro
系统:
centos6.5
节点:
192.168.133.33 master.hadoop
192.168.1.151 slave1.hadoop
192.168.1.151 slave2.hadoop
分布式安装的主要的几个步骤就是
1、安装虚拟机
2、安装操作系统
3、配置静态ip(为了避免局域网ip冲突,用nat方式) 修改host hostname 文件
4、安装java
5、ssh 免密码登录
6、安装hadoop
7、启动调试
1、VMware 安装
很简单下载完成以后一路next 就ok 了,最好不要把这个软件和以后的安装系统安装到系统盘
2、linux安装
这里选装的是centos6.5,准备好安装文件以后,文件-》新建虚拟机
这里有个注意点,因为大数据比较耗费空间,每台虚拟机的空间最好大一些,我选的是40G
一路下一步点下去以后就可以等待安装重启了linux 了
3、为虚拟机配置静态ip
需要为每天机器设定固定ip,因为是公司的局域网为了不ip冲突影响其他同事,使用nat 连接方式,采用 192.168.133 网段
选择VMnet8 然后把使用本地dhcp 去掉
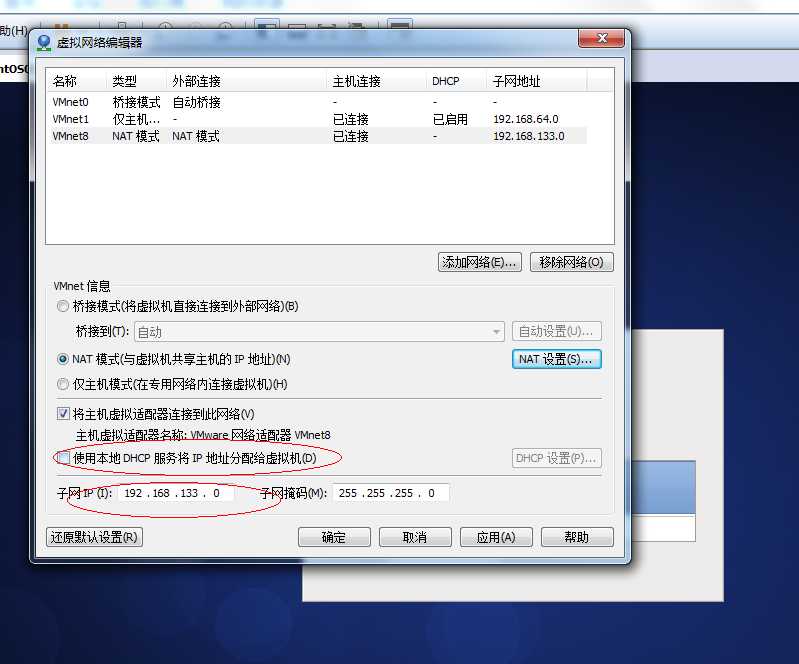
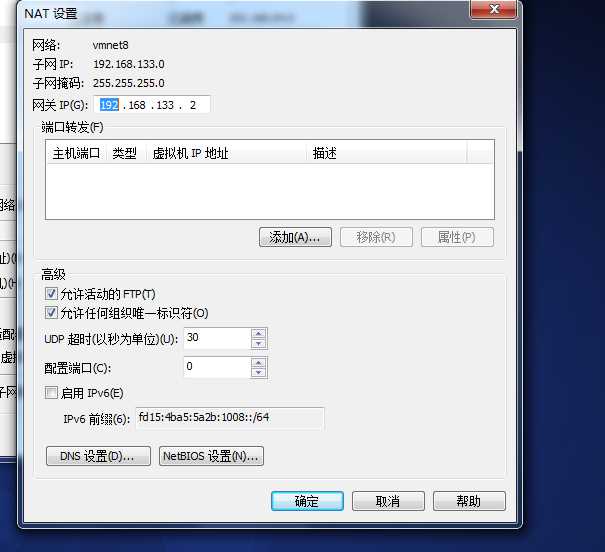
点击 nat设置 修改网关
以上是vmware的设置,设置完成以后,需要进入虚拟机进行设置,进入centos1 虚拟机 进行设置步骤如下(其他机器类似)
1)给yhw 赋予sudo 权限

vim /etc/sudoers
在root 下面增加一行和root 一样的配置 用户名为yhw(这个以后是我们的hadoop操作账户)
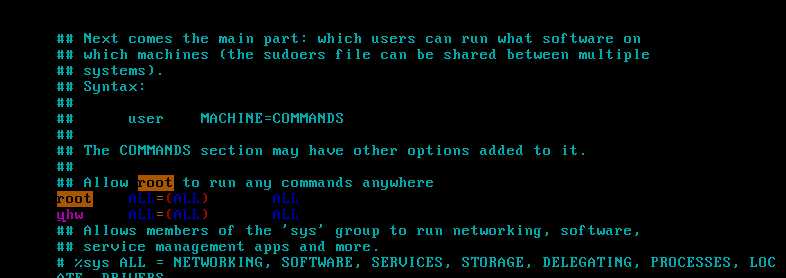
修改成如图所示 ,wq 退出
2)sudo vim /etc/sysconfig/network

将hostname 修改一下。
因为我们的集群设置成1个master 2个slaver 所以 centos1 就用master.hadoop 来表示 其他用 slaver1.hadoop 和 slaver2.hadoop 表示,ip对应关系如下
192.168.133.33 master.hadoop
192.168.133.34 slaver1.hadoop
192.168.133.35 slaver2.hadoop
3)修改网卡配置

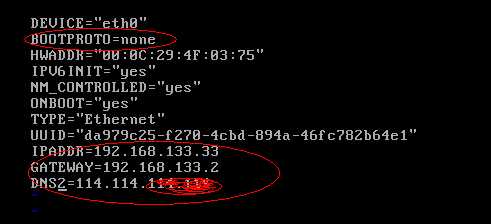
红圈表示处为必须填写项目
设置完毕使用一下命令重启服务
service network restart
然后用ifconfig 查看ip 地址
这样就可以上网并且是静态ip
按照上面的步骤我安装了3个虚拟机 计算机名称为 centos1 centos2 centos3 用户名为 yhw ip地址
192.168.133.33 master.hadoop
192.168.133.34 slaver1.hadoop
192.168.133.35 slaver2.hadoop
设置完以上的步骤,就可以使用shell 来进行管理了
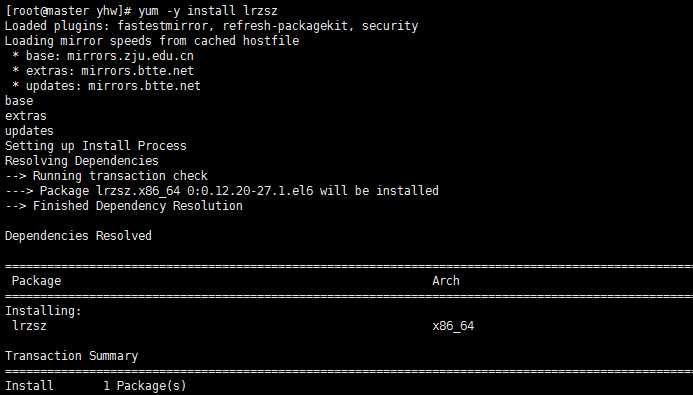
下载lzrz 方便以后上传安装包
yum -y install lrzsz #lrzsz 是一个上传下载软件 rz 是上传 sz 是下载
4、安装java
yum -y install java-1.8.0-openjdk*
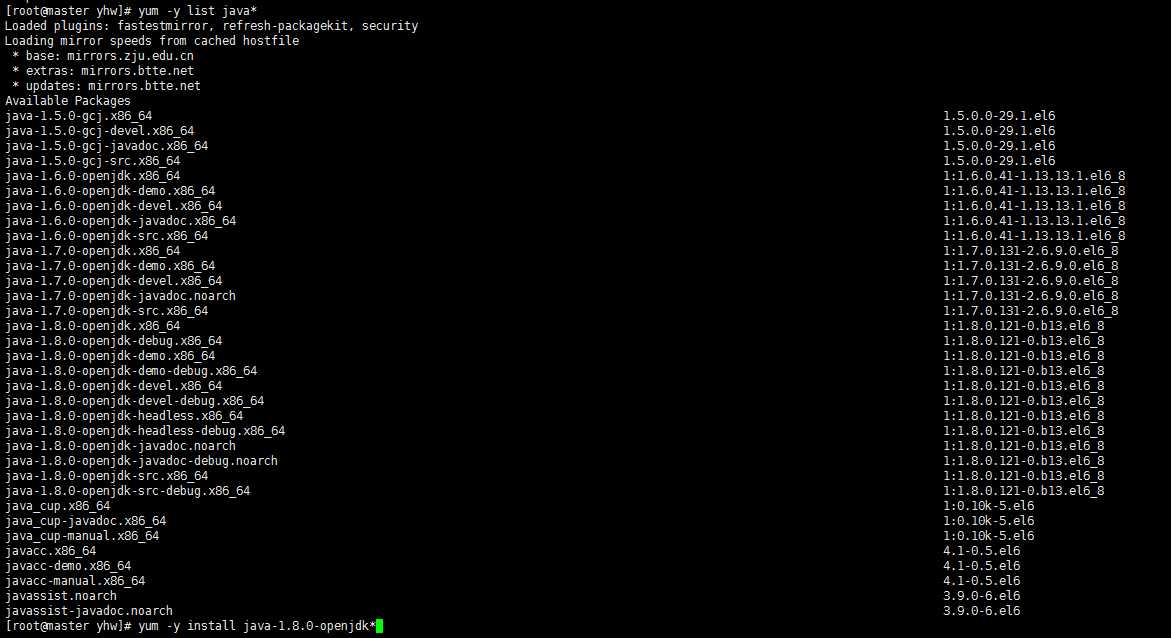
安静的等待安装成功,安装完毕以后用 java -version 查看安装正确与否

为了以后方便还需要在 /etc/profile 里面增加java_home 的配置
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.121-0.b13.el6_8.x86_64
export PATH=$JAVA_HOME/bin:$PATH
这里有个注意点就是 如果不习惯用 yum 安装,可以直接上传下载的安装包进行安装
如何确定yum 安装 的java 的路径是在
/usr/lib/jvm
下面 也可以用 whereis javac 来确定 ,具体可以参考
http://www.tuicool.com/articles/yQn2iy

按照上面的步骤把其他两台也安装好(因为之前是做windows 平台开发的, 不太熟悉linux 有没有同步安装的方法,安装完一台其他的只要复制就ok了)
5、ssh 免密登陆
因为集群是要互相访问的,所以要设置免密ssh 登陆,防止被拒绝,导致服务起不来
原理就是 做一个 公钥 存入到相互访问的机器里面authorized_keys 里面
我们以后将 yhw 用户作为hadoop的专用用户,我们要把身份切换到 yhw :su yhw
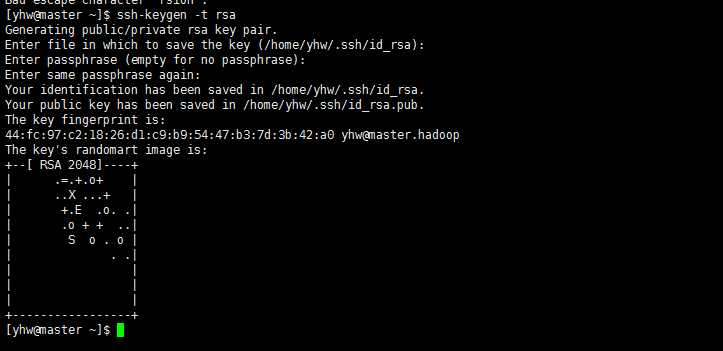
因为centos6.5 已经预装了 ssh 了(如果没有安装的可以系在安装一下) 所以我们直接生成秘钥就可以了,输入
ssh-keygen -t rsa
然后陆续回车就可以了 如下图所示
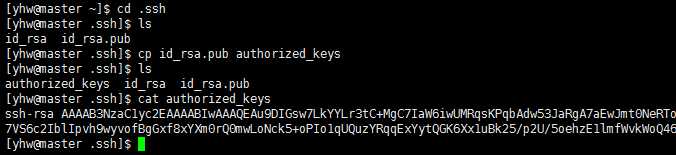
导航到 /home/yhw/.ssh 目录下面 可以看到文件,用
cp id_rsa.pub authorized_keys
复制到authorized_keys 中
测试一下效果 在测试之前还需要 修改一下硬解
sudo /etc/hosts
增加每天机器的硬解配置
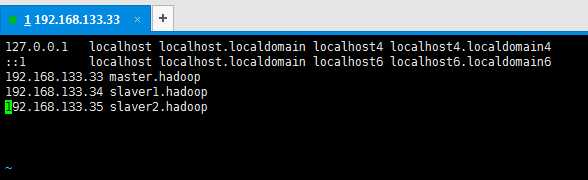
这里有一点是要注意 不要写成127.0.0.1 master.hadoop
这样hadoop 集群的时候 容易出问题
完成以后使用
ssh master.hadoop
测试登陆效果

可以看到登陆成功了
同样要在其他机器上按照上述步骤生成秘钥
使用
scp authorized_keys master.hadoop:/home/yhw/.ssh/slaver1 #slaver1 的命令
scp authorized_keys master.hadoop:/home/yhw/.ssh/slaver2 #slaver2 的命令
命令把slaver1和slaver2上的文件复制到 master 上
在用
cat slaver1 >> authorized_keys
cat slaver2 >> authorized_keys
将slaver1和 salver2的公钥 都放到authorized_keys 里面
最后authorized_keys文件里面的内容效果如下

把这个文件用 copy 到 slaver1 和 slaver2机器上
scp authorized_keys slaver1.hadoop:/home/yhw/.ssh/authorized_keys
scp authorized_keys slaver2.hadoop:/home/yhw/.ssh/authorized_keys
另外还要注意的是权限的问题 .ssh目录的权限为700 authorized_keys文件的权限是600 因为登陆后会有known_hosts 文件生成
按照以上步骤生成完以后,三台机器就能互相登录了
6、安装单机版的hadoop (由于公司的版本是2.6.0,安装3.0 和这个有一点区别但是区别不大)
从以下地址下载安装文件
http://archive.apache.org/dist/hadoop/core/hadoop-2.6.0/
利用之前的rzsz 工具上传,因为程序包里面有特殊字符另外比较大 建议使用
sudo rz -be
上传文件
上传完毕以后 ,将其安装到 /usr/haddop
sudo tar -zxvf hadoop-2.6.0.tar.gz


这里要注意的一点就是权限的问题,如果为了方便 可以对 usr 增加写权限
修改javahome配置
vim etc/hadoop/hadoop-env.sh

如果是单机版的基本上搞定了 ,现在可以做个试验了
mkdir ./input #建立设定一个输入文件夹
cp ./etc/hadoop/*.xml ./input #将要被查询的数据一股脑的放到input 中
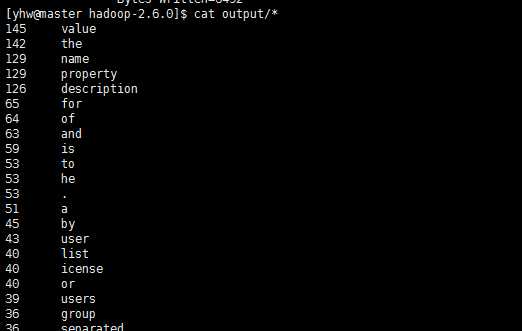
sudo bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar grep ./input ./output ‘[a-z.]+‘ #运行任务
cat output/* #输出数据
不出意外的话应该能出结果了
如果是 3.0.0 版本的 有的机器可能会出现 java 加载native 方面的错误,这个我认为最好的办法是用源码编译一下
Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [master.hadoop]
具体的编译步骤可以参考
http://www.cnblogs.com/yjmyzz/p/compile-hadoop-2_6_0-source-code-in-centos_x64.html
分布式部署:
需要修改etc 下面的 6个文件,分别是
$HADOOP_HOME/etc/hadoop/yarn-env.sh
$HADOOP_HOME/etc/hadoop/core-site.xml
$HADOOP_HOME/etc/hadoop/hdfs-site.xml
$HADOOP_HOME/etc/hadoop/mapred-site.xml
$HADOOP_HOME/etc/hadoop/yarn-site.xml
$HADOOP_HOME/etc/hadoop/slaves(在3.0里面叫workers)
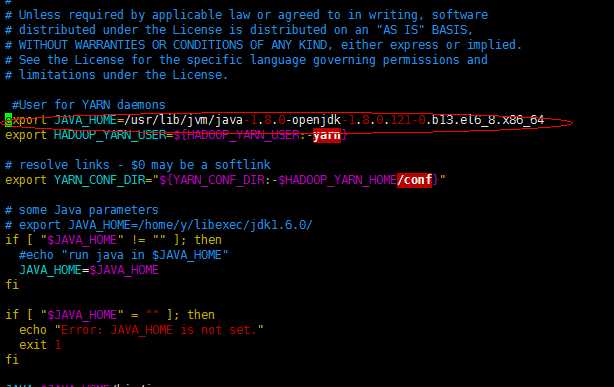
修改yarn-env.sh
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.121-0.b13.el6_8.x86_64
修改core-site.xml
<!-- fs.default.name - 这是一个描述集群中NameNode结点的URI(包括协议、主机名称、端口号),集群里面的每一台机器都需要知道NameNode的地址。
DataNode结点会先在NameNode上注册,这样它们的数据才可以被使用。独立的客户端程序通过这个URI跟DataNode交互,以取得文件的块列表。-->
<!—hadoop.tmp.dir 是hadoop文件系统依赖的基础配置,很多路径都依赖它。
如果hdfs-site.xml中不配置namenode和datanode的存放位置,默认就放在这个路径中-->
<configuration> <property><name>fs.defaultFS </name><value>hdfs://master.hadoop:9000</value></property> <property><name>hadoop.tmp.dir</name><value>/usr/hadoop-2.6.0/tmp</value></property> </configuration>

完整参考目录
http://hadoop.apache.org/docs/r2.6.0/hadoop-project-dist/hadoop-common/core-default.xml
修改hdfs-site.xml
<!-- dfs.replication -它决定着 系统里面的文件块的数据备份个数。对于一个实际的应用,它 应该被设为3(这个 数字并没有上限,但更多的备份可能并没有作用,而且会占用更多的空间)。
少于三个的备份,可能会影响到数据的可靠性(系统故障时,也许会造成数据丢失)--> <configuration> <property> <name>dfs.replication</name> <value>2</value> </property> </configuration>

http://hadoop.apache.org/docs/r2.6.0/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
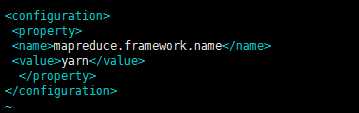
修改mapred-site.xml
将mapred-site.xml.template 复制为 mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
mapred-site.xml的完整参数请参考
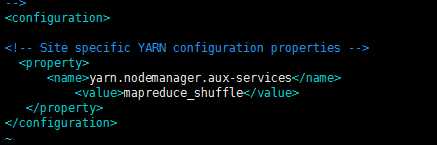
修改 yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
yarn-site.xml的完整参数请参考
http://hadoop.apache.org/docs/r2.6.0/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
修改 slavers (3.0 版本叫workers)
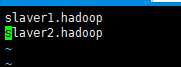
slaver1.hadoop
slaver2.hadoop
将master.hadoop 上的hadoop复制到slaver1 和slaver2
scp -r /usr/hadoop-2.6.0 slaver1.hadoop:/usr/
scp -r /usr/hadoop-2.6.0 slaver2.hadoop:/usr/

需要注意的就是 如果使用默认的配置 需要在各个主机上hadoop根目录新建 tmp 目录 ,dfs 目录 dfs 下简历 name 和 data目录
7 验证
master节点上,重新启动
在hadoop根目录
bin/hadoop namenode -format

出现如下图所示

则表示成功
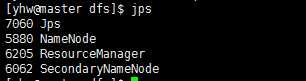
sbin/start-all.sh

如果顺利的话 在 master 节点会看到以下进程
使用 jps命令查看
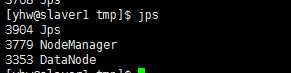
在slaver1上查看
同时 在 master.hadoop:50070 可以访问到节点情况
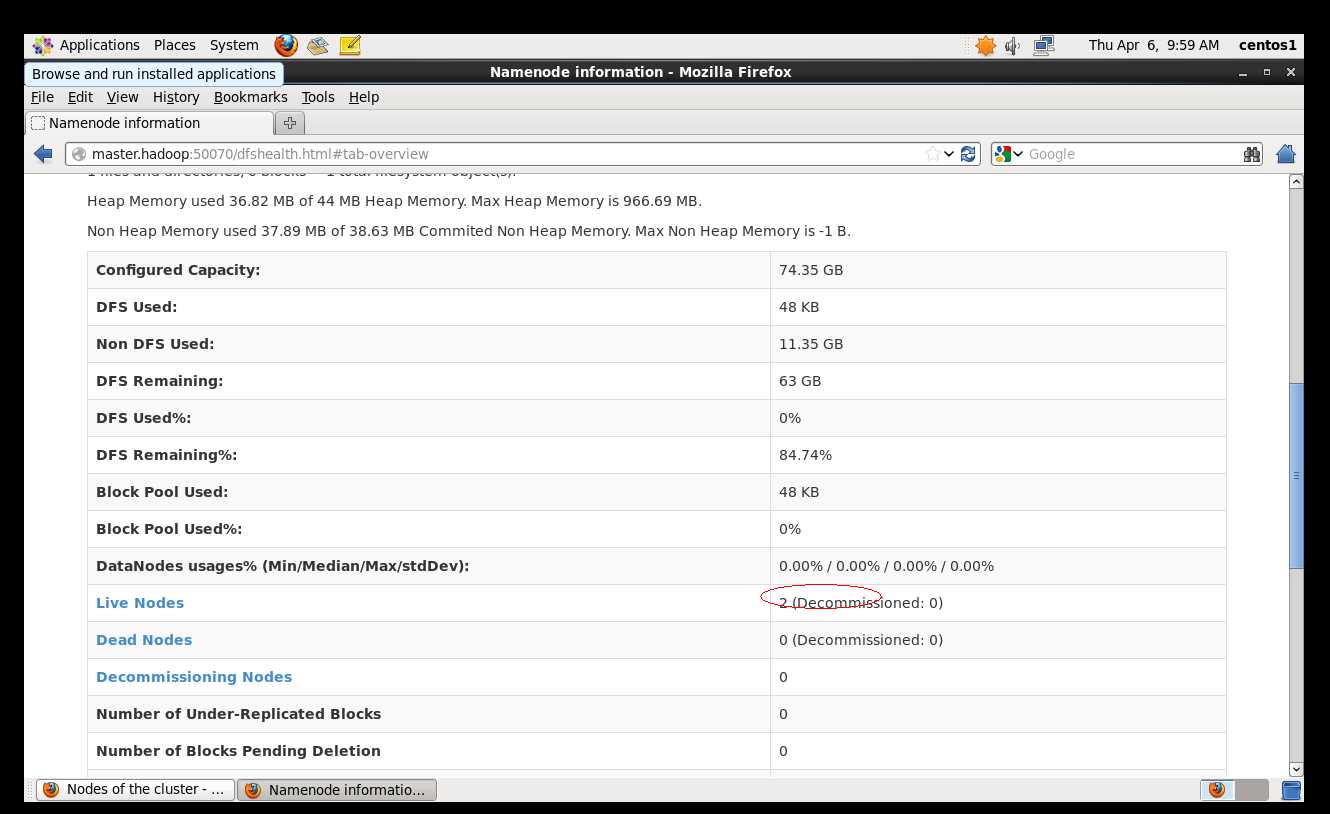
在配置过程中,遇到了几个问题
1、 nodes 节点和主机连接不上,在master的nodes 节点上线上不出来

这个一般清一下防火墙就行

2、clusterid 不对
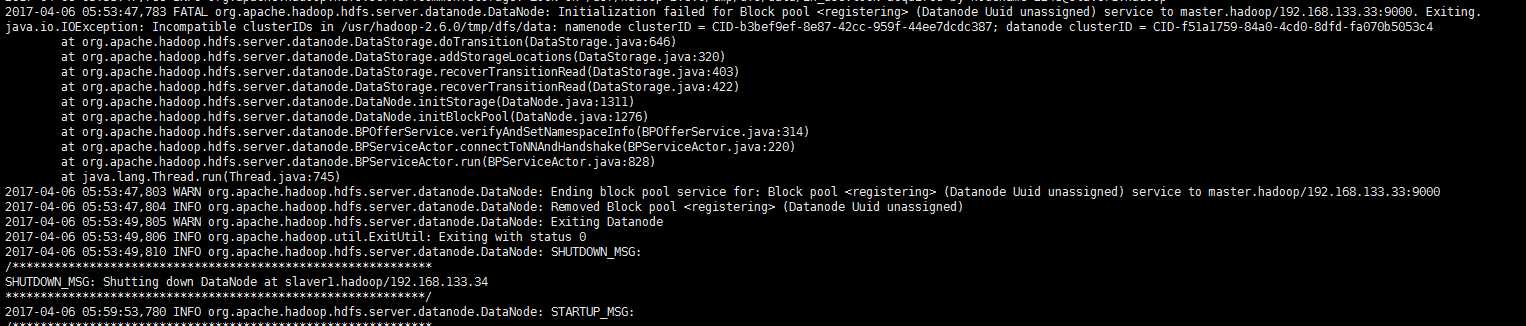
这个是由于重新格式化造成的 若要重新格式化,请先清空各datanode上的data目录(最好连tmp目录也一起清空),否则格式化完成后,启动dfs时,datanode会启动失败
以上是关于VMware 虚拟机安装 hadoop 2.6.0 完全分布式集群的主要内容,如果未能解决你的问题,请参考以下文章