Mqttnet内存与性能改进录
Posted dotNET跨平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mqttnet内存与性能改进录相关的知识,希望对你有一定的参考价值。
1 MQTTnet介绍
MQTTnet是一个高性能的 .NET MQTT库,它提供MQTT客户端和MQTT服务器的功能,支持到最新MQTT5协议版本,支持.Net Framework4.5.2版本或以上。
MQTTnet is a high performance .NET library for MQTT based communication. It provides a MQTT client and a MQTT server (broker) and supports the MQTT protocol up to version 5. It is compatible with mostly any supported .NET Framework version and CPU architecture.
2 我与MQTTnet
我有一些小型项目,需要安装在局域网环境下的windows或linux系统,这个安装过程需要小白也能安装,而且每天都有可能有多份新的安装部署的新环境,所以流行的mqtt服务器emqx可能变得不太适合我的选型,因为让小白来大量部署它不是非常方便。
我的这个小项目主体是一个Web项目,浏览器用户对象是管理员,数据的产生者是N多个廉价linux小型设备,设备使用mqtt协议高频提交数据到后台,后台也需要使用mqtt协议来主动控制设备完成一些操作动作。除此之后,Web浏览器也需要使用mqtt over websocket来订阅一些主题,达到监控某台设备的实时数据目的。
经过比较,MQTTnet变成了我意向使用的mqtt库,尤其是MQTTnet.AspNetCore子项目,基于kestrel来使用tcp或websocket做传输层,增加mqtt应用层协议的解析,最后让mqtt与asp.netcore完美地融合在一起。
3 Bug发现
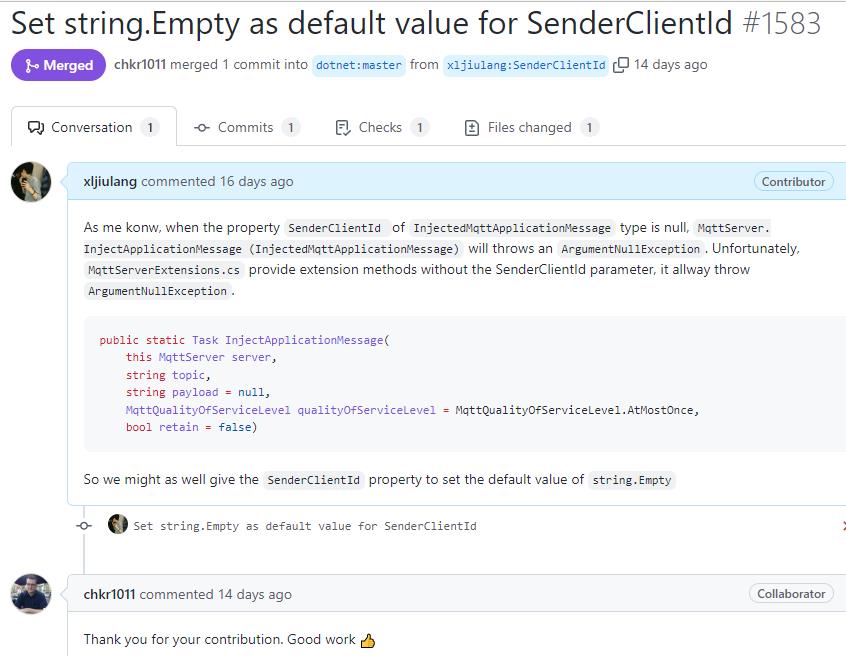
项目有后台主动发送mqtt到设备以控制设备的需求,在mqttnet里有个对应的InjectApplicationMessage()扩展方法可以从server主动发送mqtt到client,但这个方法总是抛出ArgumentNullException。但如果使用InjectApplicationMessage (InjectedMqttApplicationMessage)这个基础方法来注入mqtt消息不有异常。
经过一段时间后,闲时的我决定迁出mqttnet项目的源代码来调试分析。最后发现是因为这个扩展方法没有传递SenderClientId导致的异常,所以我决定尝试修改并推送一个请求到mqttnet项目。
4 改进之路
经过尝试修改一个小小bug之后,我开始认真的阅读MQTTnet.AspNetCore的源代码,陆续发现一些可以减少内存复制和内存分配的优化点:
ReadOnlyMemory<byte>转为ReceivedMqttPacket过程优化;MqttPacketBuffer发送过程的优化;Array.Copy()的改进;Byte[]->ArraySegment<byte>的优化;
4.1 避免不必要的ReadOnlyMemory<byte>转为byte[]
原始代码
var bodySlice = copy.Slice(0, bodyLength);
var buffer = bodySlice.GetMemory().ToArray();
var receivedMqttPacket = new ReceivedMqttPacket(fixedHeader, new ArraySegment<byte>(buffer, 0, buffer.Length), buffer.Length + 2);
static ReadOnlyMemory<byte> GetMemory(this in ReadOnlySequence<byte> input)
if (input.IsSingleSegment)
return input.First;
// Should be rare
return input.ToArray();
原始代码设计了一个GetMemory()方法,目的是在两个地方调用到。但它的一句var buffer = bodySlice.GetMemory().ToArray(),就会无条件的产生一次内存分配和一次内存拷贝。
改进代码
var bodySlice = copy.Slice(0, bodyLength);
var bodySegment = GetArraySegment(ref bodySlice);
var receivedMqttPacket = new ReceivedMqttPacket(fixedHeader, bodySegment, headerLength + bodyLength);
static ArraySegment<byte> GetArraySegment(ref ReadOnlySequence<byte> input)
if (input.IsSingleSegment && MemoryMarshal.TryGetArray(input.First, out var segment))
return segment;
// Should be rare
var array = input.ToArray();
return new ArraySegment<byte>(array);
因为有其它地方的优化,GetMemory()不再需要复用,所以我们直接改为GetArraySegment(),里面使用MemoryMarshal.TryGetArray()方法尝试从ReadOnlyMemory<byte>获取ArraySegment<byte>对象。而mqttnet的ReceivedMqttPacket对象是支持ArraySegment<byte>类型参数的。
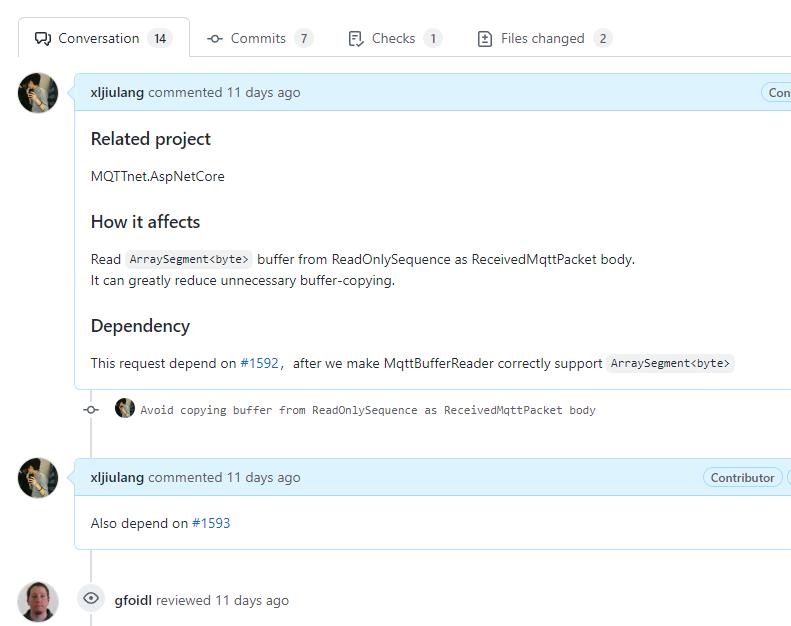
在我提交请求之后,@gfoidl给了很多其它特别好的性能方面的建议,有兴趣的同学可以点此查看。
戏剧性的是,在我尝试改进这个问题的时候,我发现了mqttnet的另外一个BUG:当bodySegment的Offset不是0开始的时候,mqttnet会产生异常。这足以说明,mqttnet项目从未使用Offset大于0的ArraySegment<byte>,所以这个bug才一直没有发现。本为不是MQTTnet.AspNetCore子项目的代码我就不改的原则,我向mqttnet提了问题:https://github.com/dotnet/MQTTnet/issues/1592 作者也很认真看待这个问题,于是自己加班解决:https://github.com/dotnet/MQTTnet/pull/1593
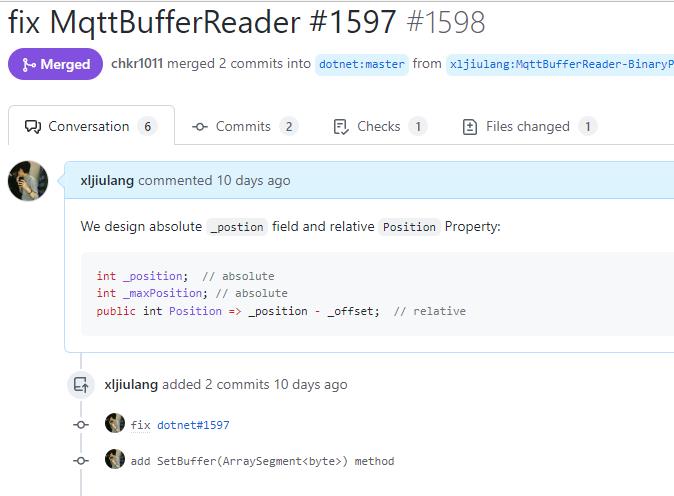
更戏剧性的是,我开心地合并main代码过来验证之后,发现作者改的BUG里又带入了BUG!现在Offset大于0还是有问题。于是我心急啊,我决定为这个BUG中BUG提交一个修改的请求:https://github.com/dotnet/MQTTnet/pull/1598
最后,这个MemoryMarshal.TryGetArray()的优化终于提到合并,改进后CPU时间时间也减少了,内存分配更是减少了50%。
4.2 MqttPacketBuffer发送过程的优化
MqttPacketBuffer有两个数据段:Pacaket段和Payload段,我看到它原始发送代码如下:
var buffer = formatter.Encode(packet);
var msg = buffer.Join().AsMemory();
var output = _output;
var result = await output.WriteAsync(msg, cancellationToken).ConfigureAwait(false);我也没有经过认证思考,觉得这里可以将Pacaket段和Payload直接两次发送即可。
var buffer = PacketFormatterAdapter.Encode(packet);
await _output.WriteAsync(buffer.Packet, cancellationToken).ConfigureAwait(false);
if (buffer.Payload.Count > 0)
await _output.WriteAsync(buffer.Payload, cancellationToken).ConfigureAwait(false);
后来作者说,当mqtt over websocket时,有些客户端在实现上没能兼容一个mqtt包分多个websocket帧传输的处理,所以需要合并发送。那我就想,如果我检测传输层是websocket的话再Join合并就行了,于是改为如下:
if (_isOverWebSocket == false)
await _output.WriteAsync(buffer.Packet, cancellationToken).ConfigureAwait(false);
if (buffer.Payload.Count > 0)
await _output.WriteAsync(buffer.Payload, cancellationToken).ConfigureAwait(false);
else
var bufferSegment = buffer.Join();
await _output.WriteAsync(bufferSegment, cancellationToken).ConfigureAwait(false);
虽然觉得这个方案比之前要好了一些,但感觉Jion里的 new byte[]的分配让我耿耿于怀。再经过几将进改,最后的代码如下,虽然也有拷贝,但至少已经没有分配:
if (buffer.Payload.Count == 0)
// zero copy
// https://github.com/dotnet/runtime/blob/main/src/libraries/System.IO.Pipelines/src/System/IO/Pipelines/StreamPipeWriter.cs#L279
await _output.WriteAsync(buffer.Packet, cancellationToken).ConfigureAwait(false);
else
WritePacketBuffer(_output, buffer);
await _output.FlushAsync(cancellationToken).ConfigureAwait(false);
static void WritePacketBuffer(PipeWriter output, MqttPacketBuffer buffer)
// copy MqttPacketBuffer's Packet and Payload to the same buffer block of PipeWriter
// MqttPacket will be transmitted within the bounds of a WebSocket frame after PipeWriter.FlushAsync
var span = output.GetSpan(buffer.Length);
buffer.Packet.AsSpan().CopyTo(span);
buffer.Payload.AsSpan().CopyTo(span.Slice(buffer.Packet.Count));
output.Advance(buffer.Length);
4.3 Array.Copy()的改进
mqttnet由于要兼容很多.net框架和版本,所以往往能使用的api不多,比如在内存拷贝了,还保留了最初的Array.Copy(),我们可以较新的框架下使用更好的api来复制,最高可达25%的复制性能提升,这个改进的工作量非常小,但产出是相当的可喜啊。
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public static void Copy(byte[] source, int sourceIndex, byte[] destination, int destinationIndex, int length)
#if NETCOREAPP3_1_OR_GREATER || NETSTANDARD2_1
source.AsSpan(sourceIndex, length).CopyTo(destination.AsSpan(destinationIndex, length));
#elif NET461_OR_GREATER || NETSTANDARD1_3_OR_GREATER
unsafe
fixed (byte* pSoure = &source[sourceIndex])
fixed (byte* pDestination = &destination[destinationIndex])
System.Buffer.MemoryCopy(pSoure, pDestination, length, length);
#else
Array.Copy(source, sourceIndex, destination, destinationIndex, length);
#endif
4.4 Byte[] -> ArraySegment<byte>的优化
当前的mqttnet,由于历史设计的局限原因,现在还不能创建ArraySegment<byte>或Memory<byte>作为payload的mqtt消息包。如果我们从ArrayPool申请1000字节的buffer,实际我们会得到一个到1024字节的buffer,想拿租赁的buffer的前1000字节做mqtt消息的payload,我们现在不得不再创建一个1000字节的byte[1000] newpayload,然后拷贝buffer到newpayload。
这种局限对服务端来说弊端是很大的,我现在尝试如何不破坏原始的byte[]支持的设计提前下,让mqttnet也支持ArraySegment<byte>的数据发送。当然,保持兼容性的新Api加入对项目来说是一种大的变化,自然有一定的风险性。
如果你也关注这个mqttnet项目,你可以查看 https://github.com/dotnet/MQTTnet/pull/1585 这个提议,也许未来它会变成现实。
5 最后
开源项目让大众受益,尤其是核心作者真的不容易,为其呕心沥血。我们在受益的同时,如果有能力的话可以反抚开源项目,在参与过程中,自身也会学到一些知识的,就当作被学习的过程吧。
以上是关于Mqttnet内存与性能改进录的主要内容,如果未能解决你的问题,请参考以下文章
为 MQTTnet 客户端消息的 TLS/SSL 加密导入的 PFX 证书适用于服务,但适用于 Xamarin UWP 应用程序失败