小5聊Python3 使用selenium模块实现简单爬虫系列一
Posted 小5聊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小5聊Python3 使用selenium模块实现简单爬虫系列一相关的知识,希望对你有一定的参考价值。
第一次听说Python还是在工作的时候,还是一位女生在用,当时她说可以用来处理excel文档,特别是一些统计分析。第二次让我真正进入python世界,还是在一次C站举办的大赛上。聊聊你是因为什么机缘巧合进入到python圈的呢?不妨留言说说
本期主要是聊聊,我接触到的selenium模块实现简单的爬虫效果
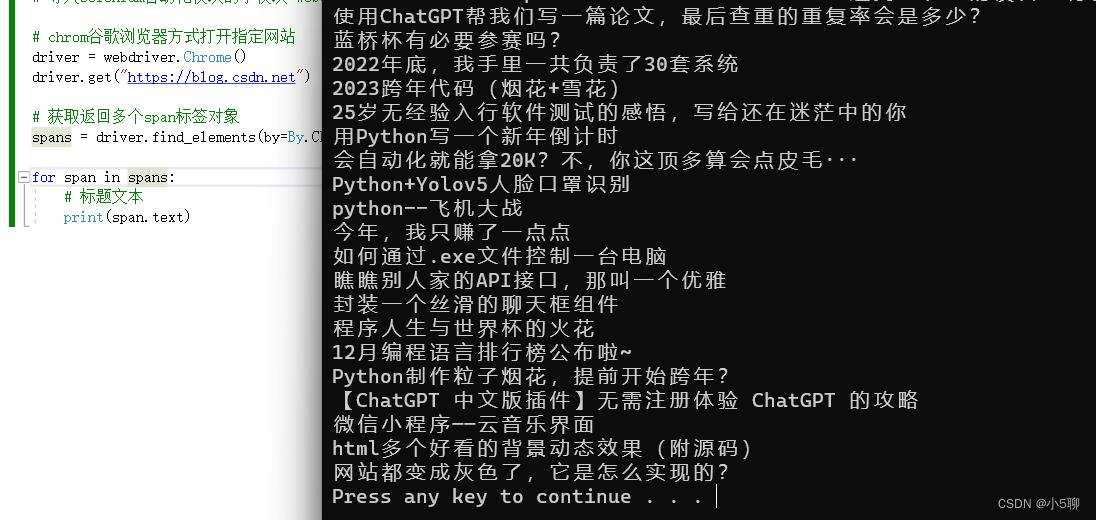
爬虫输出标题效果
1、开发环境
1)windows 11 家庭中文版
说实在的,win11真心不够稳定和好用,特别是改了那个鼠标右键出菜单那个,非常不习惯
2)Visual Studio 2022 社区版
3)Python 3.9

2、爬虫场景
1)什么是爬虫
一般指网络爬虫,自动获取网页内容的程序
2)先简单设置一个爬虫场景
当程序运行后,能够爬取C站首页推荐区域的前10条资讯标题
3、小知识点
1)函数和模块
python本身内置了一些常用函数,以及一些内置的模块,模块下又有很多函数方法
比如:math和random模块分别包含了数学运算相关的函数以及随机数相关的函数
2)引入模块必不可少
3)import和from import的区别
两者都可以为导入目标重新命名
import 具体到模块,不能具体到函数和类等
from import可以具体到类、函数
4、爬虫编码分析
1)Selenium
主要用于Web应用程序的自动化测试工具包
2)Webdriver
调用浏览器的API(程序接口),并返回响应结果的工具,这个工具包在Selenium包里面
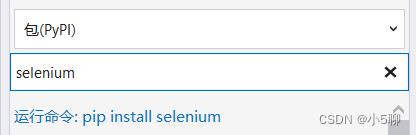
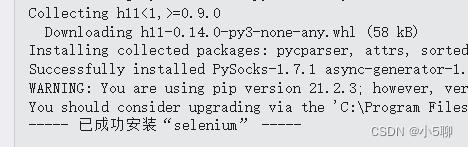
3)安装模块
4)对目标内容进行分析
爬虫目标的标题为span标签,且class为blog-text

5)下载chromedriver.exe
点击下载-chromedriver.exe,尽量放到英文目录
6)常见问题 - 编码无法识别
在脚本开头写上:# coding=gb2312 或者 # coding=utf-8

7)'WebDriver' object has no attribute
可能已经使用了新的写法
5、完整代码
# coding=gb2312
from selenium import webdriver
from selenium.webdriver.common.by import By
# 导入selenium自动化模块的子模块-webdriver-浏览器驱动模块
# chrom谷歌浏览器方式打开指定网站
driver = webdriver.Chrome()
driver.get("https://blog.csdn.net")
# 获取返回多个span标签对象
spans = driver.find_elements(by=By.CLASS_NAME,value='blog-text')
for span in spans:
# 标题文本
print(span.text)以上是关于小5聊Python3 使用selenium模块实现简单爬虫系列一的主要内容,如果未能解决你的问题,请参考以下文章