Tensorflow BP神经网络多输出模型在生产管理中应用实践
Posted 肖永威
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Tensorflow BP神经网络多输出模型在生产管理中应用实践相关的知识,希望对你有一定的参考价值。
本文以某企业组织建设为研究对象,采用大数据神经网络算法中的BP算法, 基于该算法建立了企业组织建设评价模型,最后基于Tensorflow的神经网络开发包实现模型并训练。根据评价结果可评价企业组织建设状况,从而采取相应的预防措施,对今后企业管理有着积极的作用。
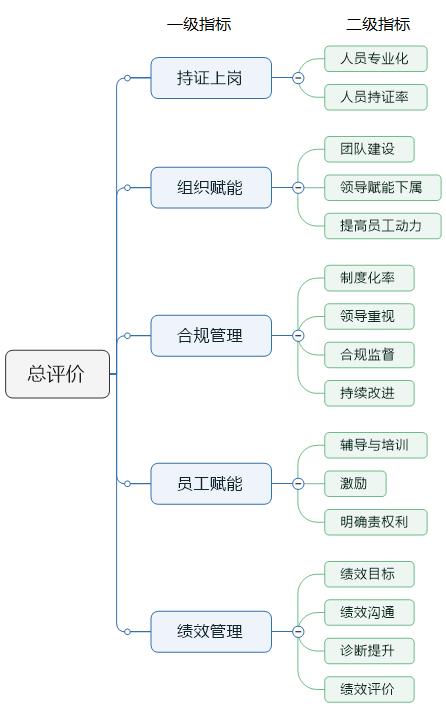
举例如下图所示“企业组织建设”评价指标体系为两级指标,其中,二级指标是人工量化打分或者实际取值,得出一级指标得分,最后给出总评价量化得分。模型设计为:二级指标得分为输入数据,一级指标和总评分是预测输出,而且输出为回归问题数值型(与分类问题区别)。
数据集处理
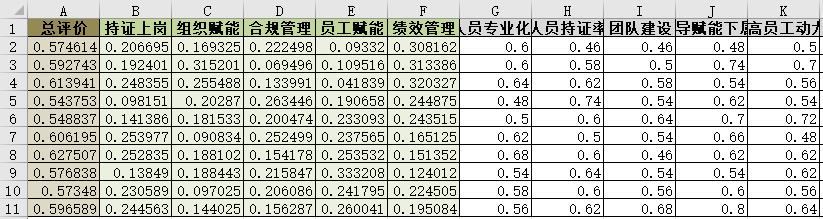
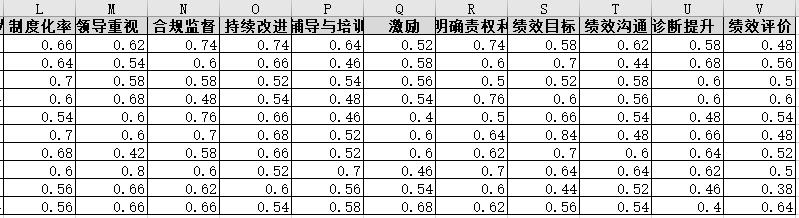
对于神经网络训练数据集,使用Excel表存储,如下图所示二维表。
del_name = ['总评价','持证上岗','组织赋能','合规管理','员工赋能','绩效管理']
#拆分特征与标签
labels = pd.DataFrame(data,columns = del_name)
labels = labels.values
#labels = labels.reshape(labels.shape[0],-1) #单列处理方式,转换为多行
inputs = data.drop(del_name,axis = 1).values
- 输入数据:
表中G到V,16列数据。 - 输出数据:
表中A到F,6列数据[‘总评价’,‘持证上岗’,‘组织赋能’,‘合规管理’,‘员工赋能’,‘绩效管理’]。
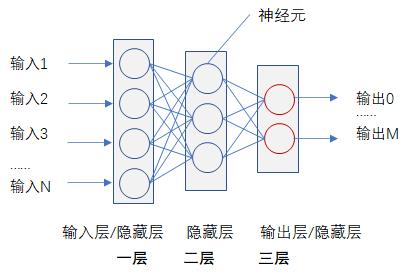
神经网络模型
反向传播算法(即BP神经网络)适合于多层神经元网络的一种学习算法,它建立在梯度下降法的基础上。BP网络的输入输出关系实质上是一种映射关系:一个n输入m输出的BP神经网络所完成的功能是从n维欧氏空间向m维欧氏空间中一有限域的连续映射,这一映射具有高度非线性。它的信息处理能力来源于简单非线性函数的多次复合,因此具有很强的函数复现能力。
关于激活函数
常见问题类型的最后一层激活和损失函数,下表可以帮我们你进行选择正确的最后一层激活和损失函数。详见[4]
| 问题类型 | 最后一层激活 | 损失函数 |
|---|---|---|
| 二分类问题 | sigmoid | binary_crossentropy |
| 多分类、单标签问题 | softmax | categorical_crossentropy |
| 多分类、多标签问题 | sigmoid | binary_crossentropy |
| 回归到任意值 | 无 | mse |
| 回归到0~1、范围内的值 | sigmoid | mse或binary_crossentropy |
- tanh
g ( x ) = e x − e − x e x + e − x g(x)=\\frace^x-e^-xe^x + e^-x g(x)=ex+e−xex−e−x ,如下图所示。

- sigmoid
g ( x ) = 1 1 + e − x g(x)=\\frac11+e^-x g(x)=1+e−x1 ,如下图所示。
Tensorflow实现说明
搭建N×K×M三层BP神经网络
(1)定义神经元参数
神经元基本定义是
y
=
w
x
+
b
y=wx+b
y=wx+b,这里主要是定义参数
w
w
w和
b
b
b。
#定义神经元
def NN(h_in,h_out,layer='1'):
w = tf.Variable(tf.truncated_normal([h_in,h_out],stddev=0.1),name='weights' +layer )
b = tf.Variable(tf.zeros([h_out],dtype=tf.float32),name='biases' + layer)
return w,b
(2)定义隐藏层神经元
y
=
t
a
n
h
(
w
1
x
+
b
1
)
y=tanh(w_1x + b_1)
y=tanh(w1x+b1),Tensorflow实现如下所示,这里的
x
x
x、
y
y
y是张量。
#定义网络参数
w1,b1 = NN(in_units,layers[0],'1') #定义第一层参数
#定义网络隐藏层
#定义前向传播过程
h1 = tf.nn.tanh(tf.add(tf.matmul(x,w1),b1))
训练并持久化(保存)模型
saver = tf.train.Saver() #定义saver
#随机梯度下降算法训练参数
with tf.Session() as sess:
......
saver.save(sess, 'save_m/BP_model.ckpt') #模型储存位置
使用(加载)持久化模型
# 根据输入预测结果
def BPNN_Pprediction(input_x):
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
saver = tf.train.import_meta_graph('save_m/BP_model.ckpt.meta')
saver.restore(sess,tf.train.latest_checkpoint('save/'))
graph = tf.get_default_graph()
# 获取保存到模型中所定义变量名称
x = graph.get_tensor_by_name("x:0")
y_ = graph.get_tensor_by_name("y_:0")
# 输出预测结果
y_conv = graph.get_tensor_by_name('y_conv:0')
keep_prob = graph.get_tensor_by_name("keep_prob:0")
ret = sess.run(y_conv, feed_dict=x:input_x,keep_prob:1.0)
#y = sess.run(tf.argmax(ret,1)) # 用于分类问题,取最大概率
print("预测结果:".format(ret))
注意:此处加载方法是加载模型定义和模型参数,有别于只加载模型参数的方法。解释说明详见参加文档[2]。
代码
import numpy as np
import tensorflow as tf
import pandas as pd
#数据源:以专家投票频次与评分标准向量积算出指标评分,与PCE保持一致。
def get_DataFromExcel():
df = pd.read_excel('BP_random.xlsx')
return df
# 生成样例数据集
def generate_data():
data = get_DataFromExcel()
del_name = ['总评价','持证上岗','组织赋能','合规管理','员工赋能','绩效管理']
#拆分特征与标签
labels = pd.DataFrame(data,columns = del_name)
labels = labels.values
#labels = labels.reshape(labels.shape[0],-1) #单列处理方式,转换为多行
inputs = data.drop(del_name,axis = 1).values
return inputs, labels
#定义神经元
def NN(h_in,h_out,layer='1'):
w = tf.Variable(tf.truncated_normal([h_in,h_out],stddev=0.1),name='weights' +layer )
b = tf.Variable(tf.zeros([h_out],dtype=tf.float32),name='biases' + layer)
return w,b
#定义BP神经网络
def BP_NN(in_units,layers=[10,5,6],dropout=True):
#定义输入变量
x = tf.placeholder(dtype=tf.float32,shape=[None,in_units],name='x')
num = len(layers) # 网络层数
#定义网络参数
w1,b1 = NN(in_units,layers[0],'1') #定义第一层参数
w2,b2 = NN(layers[0],layers[1],'2') #定义第二层参数
#定义网络隐藏层
#定义前向传播过程
h1 = tf.nn.tanh(tf.add(tf.matmul(x,w1),b1))
#定义dropout保留的节点数量
keep_prob = tf.placeholder(dtype=tf.float32,name='keep_prob')
if dropout:
#使用dropout
h1_drop = tf.nn.dropout(h1,rate = 1 - keep_prob) #Please use `rate` instead of `keep_prob`. Rate should be set to `rate = 1 - keep_prob`.
else:
h1_drop = h1
# 针对三层网络
if num > 2:
w3,b3 = NN(layers[1],layers[2],'3') #定义第三一层参数
# 定义第二层隐藏层
h2 = tf.nn.tanh(tf.add(tf.matmul(h1_drop,w2),b2))
#h2 = tf.add(tf.matmul(h1_drop,w2),b2)
# 定义输出层
y_conv = tf.nn.sigmoid(tf.add(tf.matmul(h2,w3),b3),name='y_conv')
else:
y_conv = tf.nn.sigmoid(tf.add(tf.matmul(h1_drop,w2),b2),name='y_conv')
#y_conv = tf.add(tf.matmul(h1_drop,w2),b2)
#定义输出变量
y_ = tf.placeholder(dtype=tf.float32,shape=[None,layers[num - 1]],name='y_')
#定义损失函数及反向传播方法。
loss_mse = tf.reduce_mean(tf.square(y_conv-y_))
#均方误差MSE损失函数
train_step = tf.train.GradientDescentOptimizer(0.002).minimize(loss_mse)
correct_pred = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))
return x,y_,loss_mse,train_step,correct_pred,keep_prob
def BPNN_train():
inputs, labels = generate_data()
# 定义周期、批次、数据总数、遍历一次所有数据需的迭代次数
n_epochs = 3
batch_size = 6
# 使用from_tensor_slices将数据放入队列,使用batch和repeat划分数据批次,且让数据序列无限延续
dataset = tf.data.Dataset.from_tensor_slices((inputs, labels))
dataset = dataset.batch(batch_size).repeat()
# 使用生成器make_one_shot_iterator和get_next取数据
iterator = dataset.make_one_shot_iterator()
next_iterator = iterator.get_next()
#定义神经网络的参数
in_units = 16 #输入16个指标,返回一个评分
# 定义三层BP神经网络,层数及神经元个数通过layers参数确定,两层[5,3],只支持2或3层,其他无意义
x,y_,loss_mse,train_step,correct_pred,keep_prob = BP_NN(in_units,layers=[8,8,6],dropout=False)
saver = tf.train.Saver() #定义saver
#随机梯度下降算法训练参数
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(10000):
batch_x,batch_y = sess.run(next_iterator)
_,total_loss = sess.run([train_step,loss_mse], feed_dict=x:batch_x,y_:batch_y,keep_prob:0.8)
if i%100 == 0:
#train_accuracy = accuracy.eval(session = sess,feed_dict=x:batch_x, y_: batch_y, keep_prob: 1.0) # 用于分类识别,判断准确率
#print ("step , training accuracy ".format(i, train_accuracy))
print ("step , total_loss ".format(i, total_loss)) # 用于趋势回归,预测值
saver.save(sess, 'save_m/BP_model.ckpt') #模型储存位置
# 根据输入预测结果
def BPNN_Pprediction(input_x):
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
saver = tf.train.import_meta_graph('save_m/BP_model.ckpt.meta')
saver.restore(sess,tf.train.latest_checkpoint('save/'))
graph = tf.get_default_graph()
x = graph.get_tensor_by_name("x:0")
y_ = graph.get_tensor_by_name("y_:0")
# 输出预测结果
y_conv = graph.get_tensor_by_name('y_conv:0')
keep_prob = graph.get_tensor_by_name("keep_prob:0")
ret = sess.run(y_conv, feed_dict=x:input_x,keep_prob:1.0)
#y = sess.run(tf.argmax(ret,1)) # 用于分类问题,取最大概率
print("预测结果:".format(ret))
def main():
train = True
#train = False
if train:
BPNN_train()
input_x = [[0.54,0.56,0.78,0.44,0.48,0.72,0.72,0.54,0.44,0.68,0.68,0.8,0.84,0.84,0.74,0.8]]
BPNN_Pprediction(input_x)
return
if __name__ == '__main__':
main()
注:对于隐藏层一般使用relu激活函数,对于输出层如果用于分类则采用sigmoid激活函数,用于回归则采用线性激活函数。
关于数据来源问题
本文训练集来源于《模糊层次综合分析法Python实践及相关优缺点分析》所获得的数据(文中的样例是模拟随机产生的数据),在实际工作中,可以通过这两种算法来验证评价结果。BP神经网络有较好的成长性,适应工作需要,便于调整指标,如果能通过大量模糊样本的学习,将使模型有较好的泛化能力。
由于作者水平有限,欢迎反馈讨论。
参考:
[1]《BP神经网络学习与实践》 CSDN博客 ,肖永威 2019年11月
[2]《如何使用训练好的Tensorflow模型的案例及分析》 CSDN博客 ,肖永威 2019年5月
[3]《TensorFlow CNN卷积神经网络实现工况图分类识别(一)》 CSDN博客 , 肖永威 ,2019年3月
[4]《《python深度学习》笔记》 CSDN博客 ,lxiao428 , 2019年3月
以上是关于Tensorflow BP神经网络多输出模型在生产管理中应用实践的主要内容,如果未能解决你的问题,请参考以下文章