机器学习100天:005 数据预处理之划分训练集
Posted 红色石头Will
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习100天:005 数据预处理之划分训练集相关的知识,希望对你有一定的参考价值。
机器学习100天,今天讲的是:数据预处理之划分训练集。
在上一节,我们对类别特征进行了编码,X 和 y 已经变成了机器学习可以理解和处理的数据格式。
下面我们就要对数据集进行划分,划分成训练集和测试集。
在监督式机器学习中,我们一般使用训练集的数据来训练模型,然后把训练好的模型在测试集上进行测试,用测试集上的误差作为最终模型在现实场景中的泛化误差,即真实表现。
那么,对于已有的数据集,该如何划分呢?
一般遵循两个原则:
- 一是通常将数据集的80%作为训练集,20%作为测试集
- 二是采用随机采样的方式划分,避免样本的不均匀性造成模型性能变差
那么如何在程序中划分训练集和测试集呢?
很简单,在 spyder 中,我们直接导入 sklearn.model_selection 模块中的 train_test_split 函数,我们鼠标选中 train_test_split,看一下它的详细文档
可以看到,有几个重要的参数:
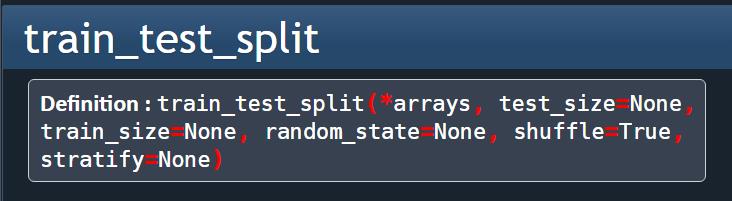
- arrays 表示输入的数组,即待划分的 X 和 y;
- test_size 表示测试集占的比例,一般是 0.2 或 0.3;
- random_state 表示随机数的种子,在需要重复试验的时候,保证得到一组一样的随机数。比如你每次都填 1,其他参数不变的情况下得到的随机数组是一样的。但不填,每次都会不一样。
以上是关于机器学习100天:005 数据预处理之划分训练集的主要内容,如果未能解决你的问题,请参考以下文章