Elasticsearch:如何在 Elastic Agents 中配置 Beats 来采集定制日志
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:如何在 Elastic Agents 中配置 Beats 来采集定制日志相关的知识,希望对你有一定的参考价值。
在我之前的文章 “Observability:使用 Elastic Agent 来摄入日志及指标 - Elastic Stack 8.0”,我详细地描述了如何安装 Elasticsearch,Stack 及 Elastic Agents 来采集系统日志及指标。很多开发者可能会有疑问,在我们的实际使用中,我们更多的可能是需要采集定制的应用日志,而不是系统日志。那么在这个时候,我们该如何使用 Elastic Agents 来把这些日志摄入呢?在以前的系统中,我们可以使用如下的几种方式来采集日志:
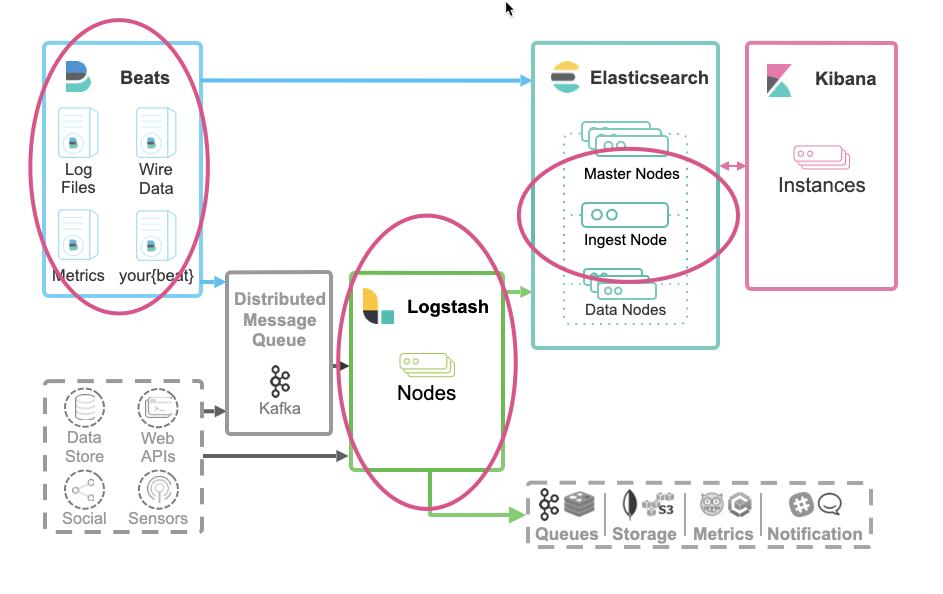
- 我们可以直接使用 Beats 把数据传入到 Elasticsearch 中。对数据的处理,我们可以使用 Beats 的 processors 来处理数据,或者通过 Elasticsearch 集群的 ingest nodes 来处理数据。
- 我们可以通过 Beats => Logstash => Elasticsearch。针对这种情况,我们可以分别在 Beats,Logstash 或者 Elasticsearch 集群的 ingest nodes 来处理数据。
- 我们可以直接使用各种编程语言来直接向 Elasticsearch 集群进行写入。我们可以使用 Elasticsearch 集群的 ingest nodes 来处理数据。
在今天的文章里,我们来详细地描述如何使用 Elastic Agents 把应用中的定制日志摄入到 Elasticsearch 中并进行分析。在今天的演示中,我将使用如下测试环境:
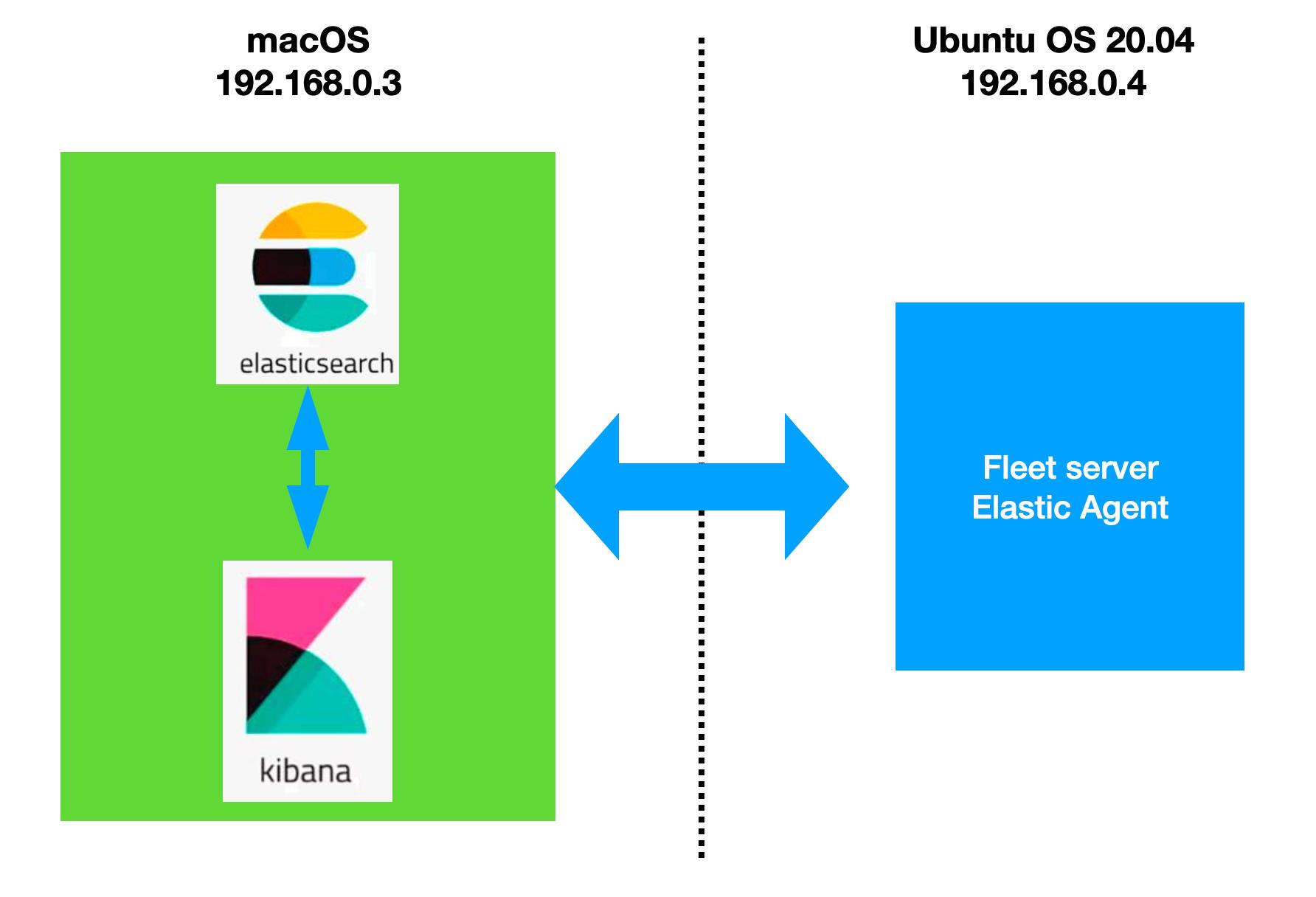
针对 Elastic Agents 采集数据,究其本质,它也是采用相应的 Beats 比如 Filebeat 来采集日志。我们可以采用 Elasticsearch 集群中的 ingest nodes 来处理数据。这个在我之前的文章 “Observability:如何使用 Elastic Agents 把定制的日志摄入到 Elasticsearch 中” 已经讲到了。在今天的文章中,我来讲该如何配置 Beats 的 processors 来及其相关的设置。关于如何配置 Filebeat 来进行数据采集,请阅读我之前的文章 “Beats:使用 Elastic Stack 记录 Python 应用日志”。
Elastic Agents vs Filebeat
- Elastic-Agent 是一种单一、统一的方式,可以为主机添加对日志、指标和其他类型数据的监控。
- Filebeat 是用于转发和集中日志数 据的轻量级采集器。
我应该使用哪一个? Elastic-Agent 提供最好的体验,一切都可以通过 Kibana 配置,你可以在 Kibana 上看到 Elastic-Agent 的日志以及它的健康状态。如果由于某种原因你无法运行 Elastic-Agent,Filebeat 仍然是一个选项。
Structured logging 几乎已经成为行业标准,可以轻松理解和解析日志。 虽然 Elastic-Agent 提供了与许多应用程序的集成,允许轻松摄取和解析日志,但当涉及到我们自己的应用程序时,还需要做一些工作。
我将使用 Elastic Stack 8.5.2 来进行安装并展示。
准备日志
我在上面的 Ubuntu OS 机器上的目录 /tmp 下创建如下的文件 sample.log:
liuxg@liuxgu:/tmp$ pwd
/tmp
liuxg@liuxgu:/tmp$ cat sample.log
"level":"info","time":"2022-11-28T12:00:00+01:00","message":"Starting Advent Calendar demo", "status_code": 200
"level":"info","time":"2022-11-28T12:00:32+01:00","message":"First line", "status_code": 300
"level":"debug","time":"2022-11-28T12:08:32+01:00","message":"Second line", "status_code": 400
"level":"error","time":"2022-11-28T12:09:32+01:00","message":"Third line", "status_code": 500
"level":"info","time":"2022-11-28T12:10:32+01:00","message":"Forth line", "status_code": 100
"level":"warn","time":"2022-11-28T12:11:32+01:00","message":"Fith line", "status_code": 200我们在这里有三个字段:
- level:这是日志级别,我们希望将其过滤为 keyworkd(例如:info、error、debug 等)。
- time:是写入日志行的时间,我们需要告诉 Elastic-Agent 使用它作为日志条目的时间而不是摄取时间。
- message:消息本身,我们将其视为自由文本字段。
- status_code:模拟 HTTP 状态代码的数字字段。
安装
在进行下面的练习之前,我们必须安装好 Elasticsearch 及 Kibana。我们可以参考之前的文章:
我们按照上面的要求进行安装 Elasticsearch 及 Kibana。为了能够让 fleet 正常工作,内置的 API service 必须启动。我们必须为 Elasticsearch 的配置文件 config/elasticsearch.yml 文件配置:
xpack.security.authc.api_key.enabled: true配置完后,我们再重新启动 Elasticsearch。针对 Kibana,我们也需要做一个额外的配置。我们需要修改 config/kibana.yml 文件。在这个文件的最后面,添加如下的一行:
xpack.encryptedSavedObjects.encryptionKey: 'fhjskloppd678ehkdfdlliverpoolfcr'如果你不想使用上面的这个设置,你可以使用如下的方式来获得:
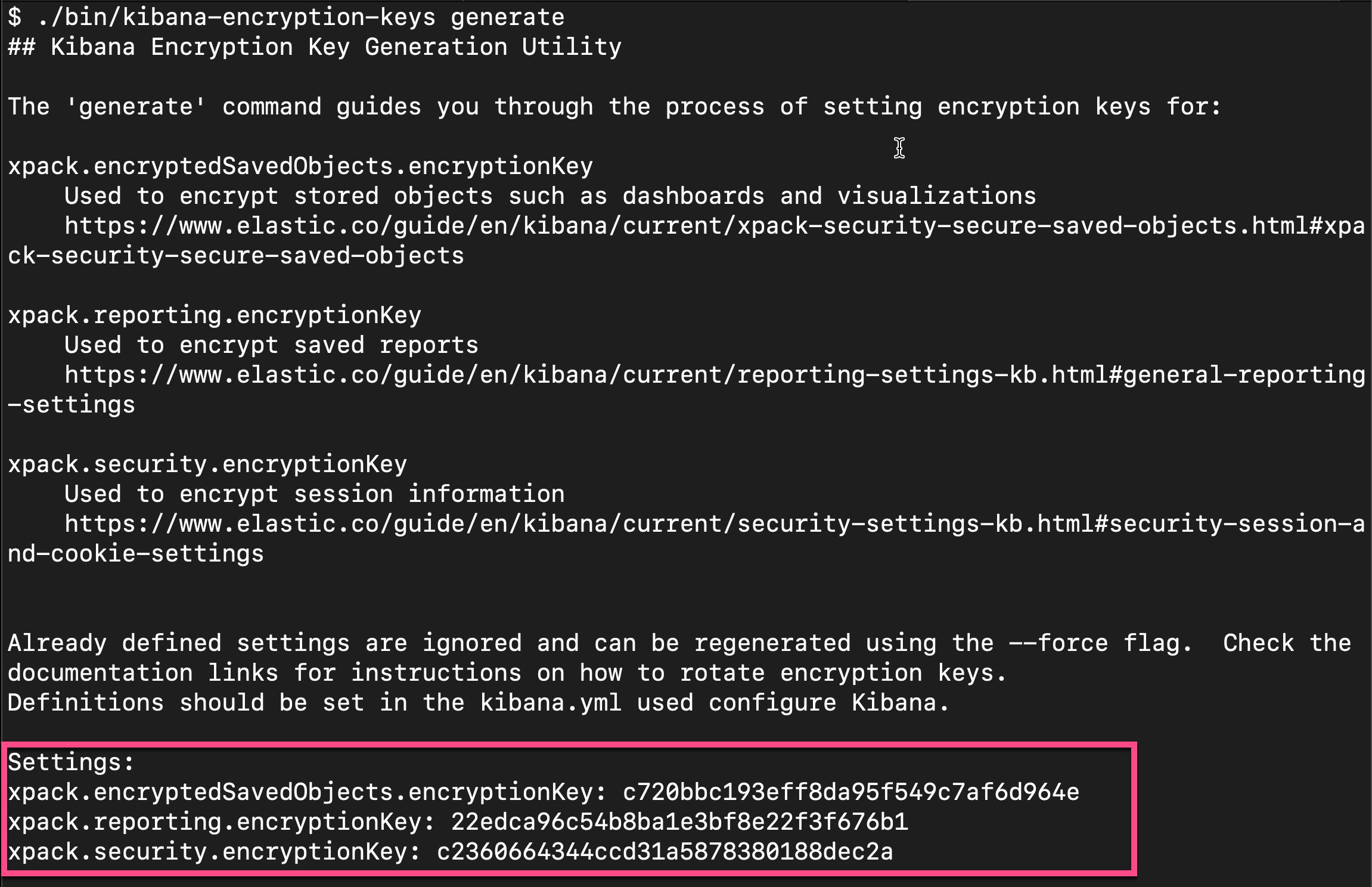
从上面的输出中,我们可以看出来,有三个输出的 key。我们可以把这三个同时拷贝,并添加到 config/kibana.yml 文件的后面。当然,我们也可以只拷贝其中的一个也可。我们再重新启动 Kibana。
这样我们对 Elasticsearch 及 Kibana 的配置就完成。 针对 Elastic Stack 8.0 以前的版本安装,请阅读我之前的文章 “Observability:如何在最新的 Elastic Stack 中使用 Fleet 摄入 system 日志及指标”。
除此之外,Kibana 需要 Internet 连接才能从 Elastic Package Registry 下载集成包。 确保 Kibana 服务器可以连接到https://epr.elastic.co 的端口 443 上 。如果你的环境有网络流量限制,有一些方法可以解决此要求。 有关详细信息,请参阅气隙环境。
目前,Fleet 只能被具有 superuser role 的用户所使用。
配置 Fleet
使用 Kibana 中的 Fleet 将日志、指标和安全数据导入 Elastic Stack。第一次使用 Fleet 时,你可能需要对其进行设置并添加 Fleet Server。在做配置之前,我们首先来查看一下有没有任何的 integration 被安装:
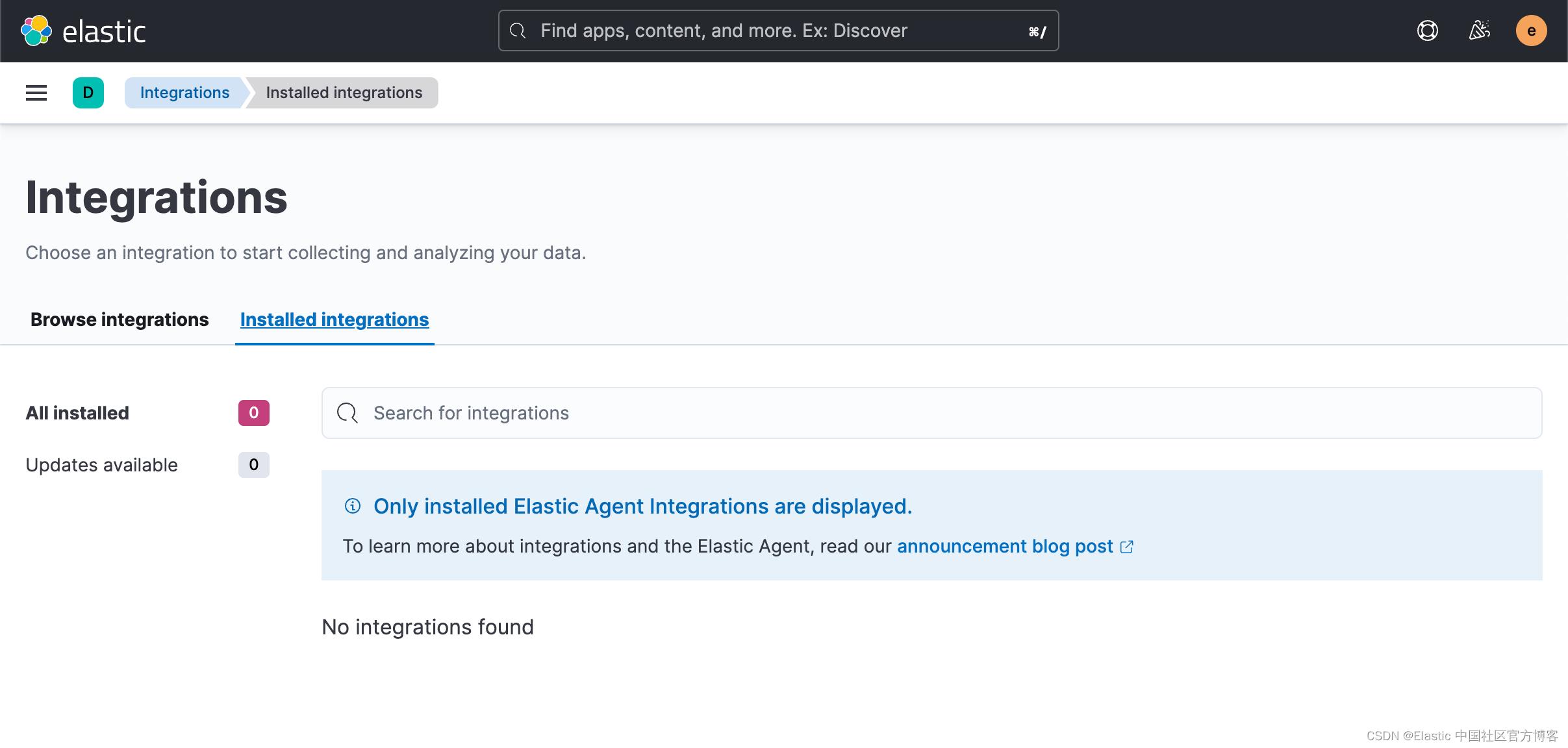 从上面我们可以看出来没有任何安装的 integrations。
从上面我们可以看出来没有任何安装的 integrations。
我们打开 Fleet 页面:
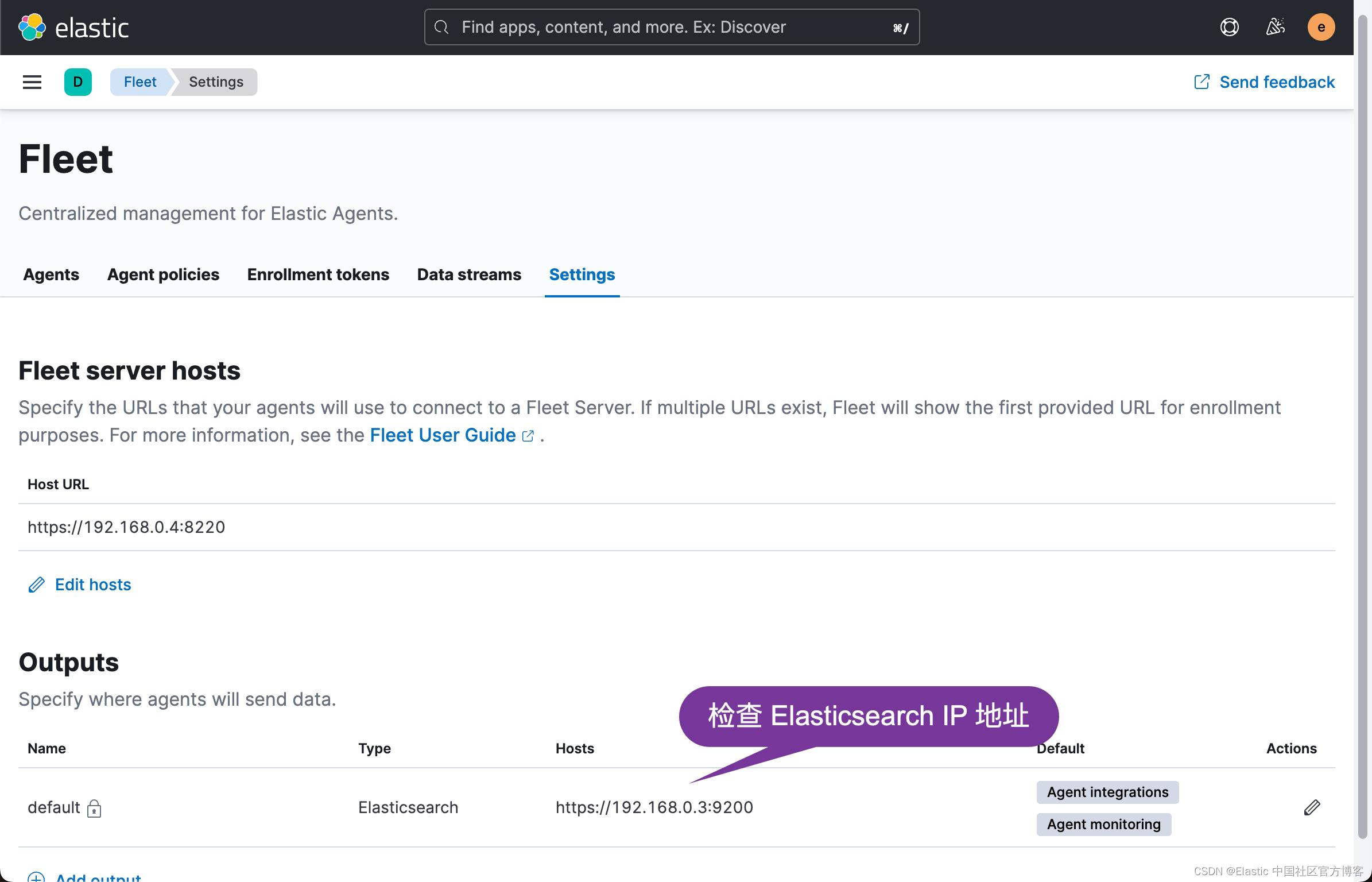
我们接下来添加 Agent:
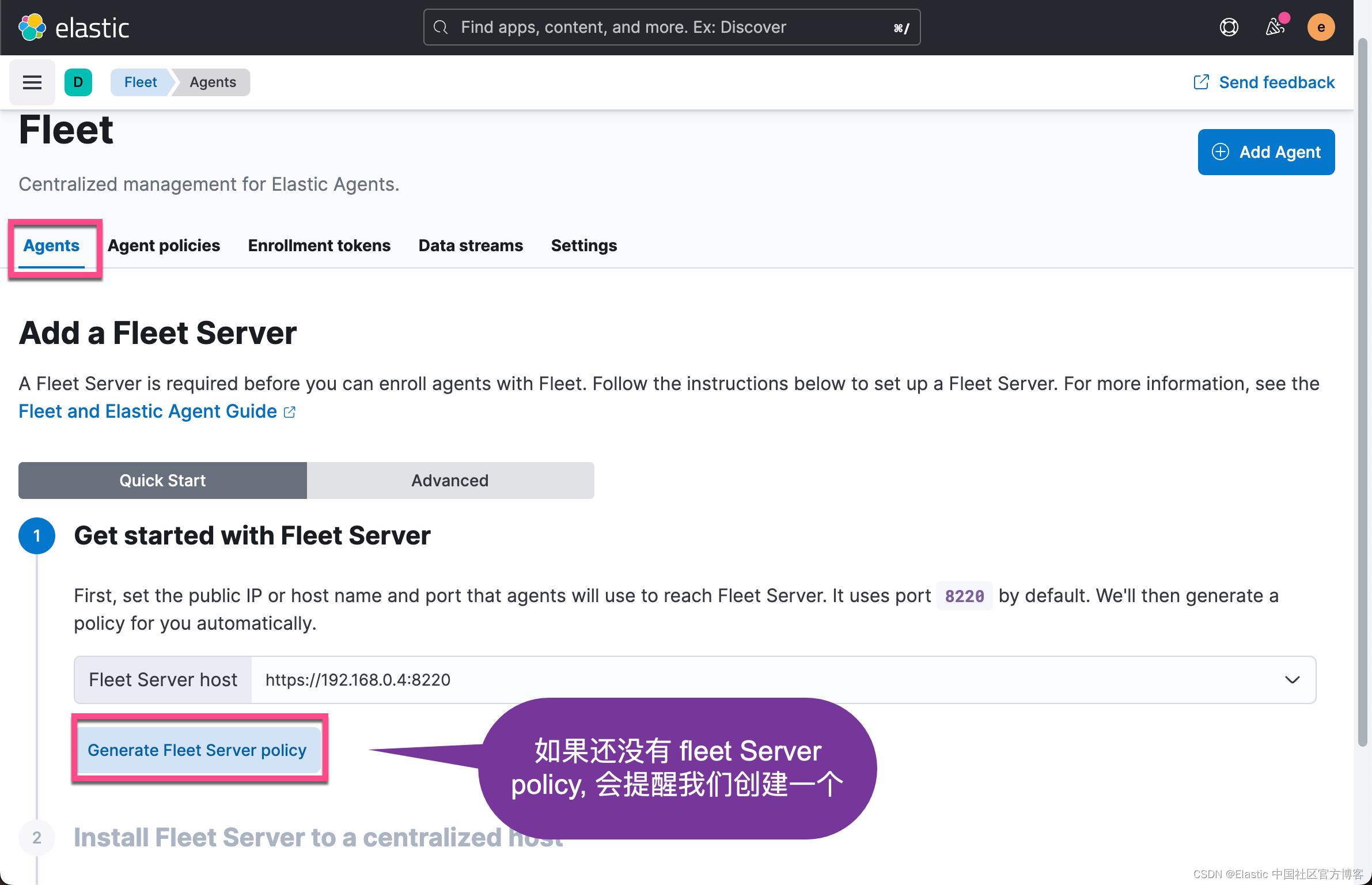
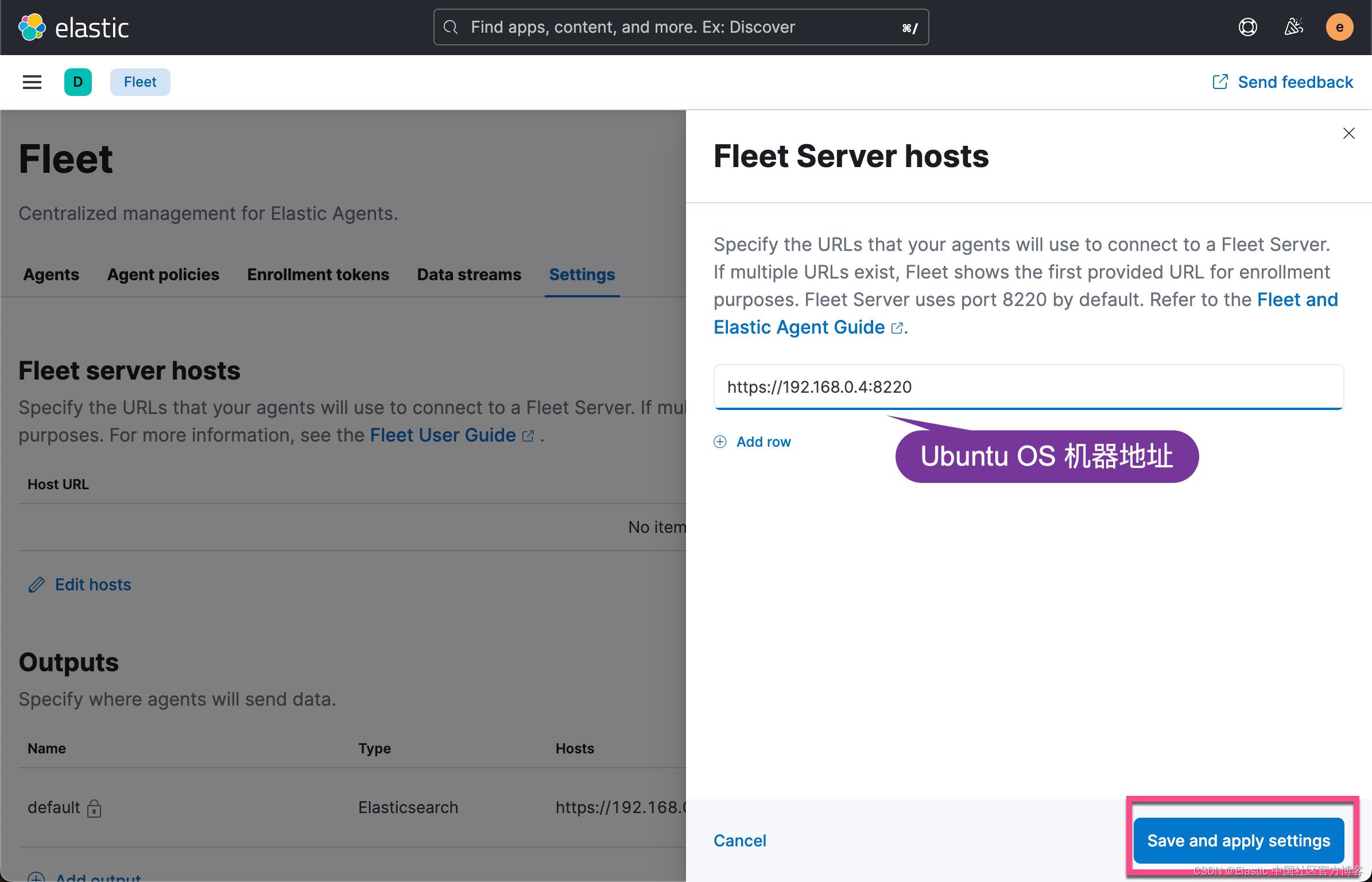
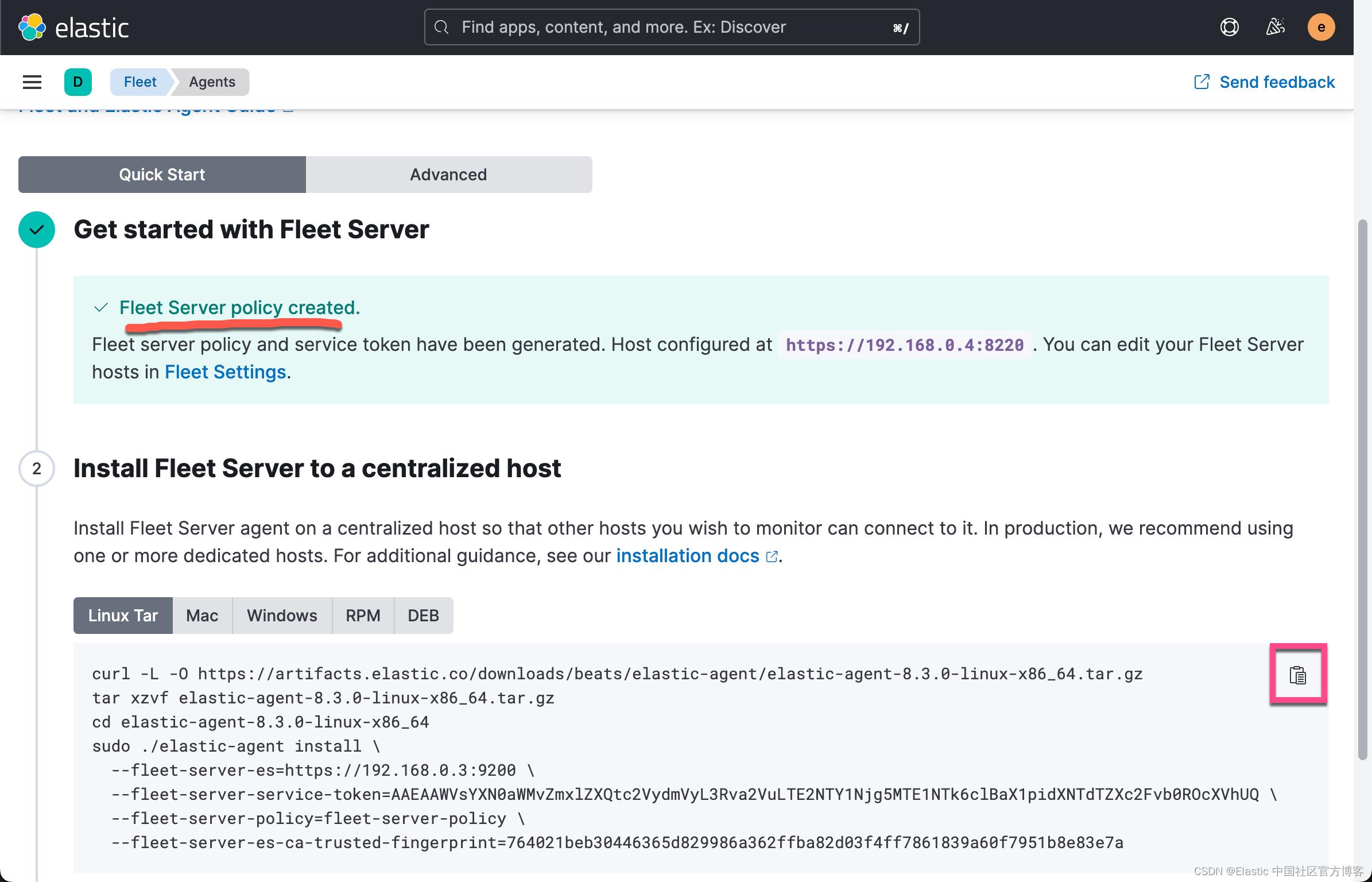 上面显示我们的 Fleet Sever policy 被成功地创建了。我们需要把我们的 Fleet Server 安装到 Ubuntu OS 机器上。
上面显示我们的 Fleet Sever policy 被成功地创建了。我们需要把我们的 Fleet Server 安装到 Ubuntu OS 机器上。
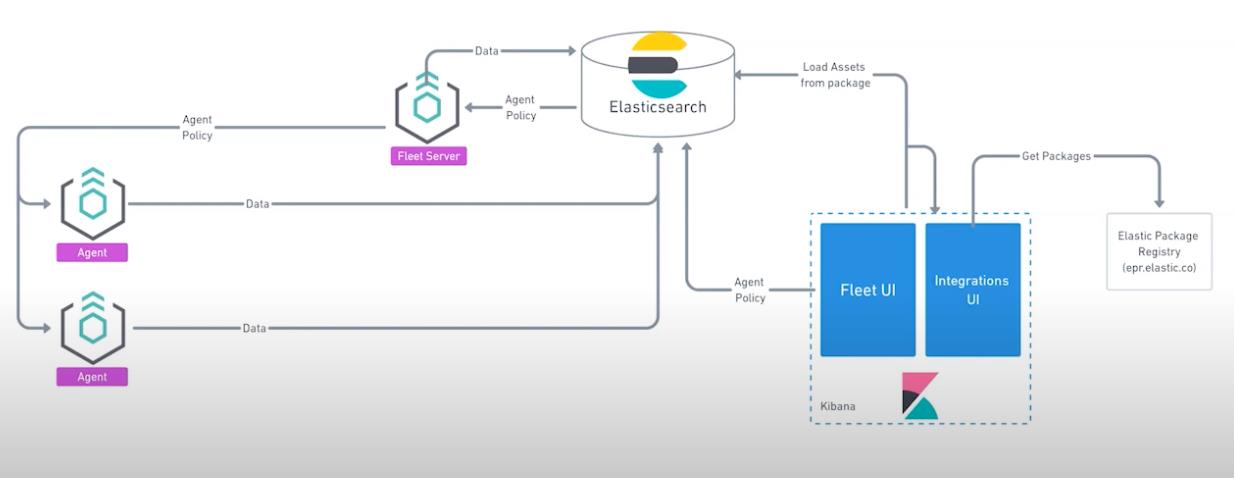
我们的目标机器是 Linux OS。我们点击上面的拷贝按钮,并在 Linux OS 上进行安装:
curl -L -O https://artifacts.elastic.co/downloads/beats/elastic-agent/elastic-agent-8.3.0-linux-x86_64.tar.gz
tar xzvf elastic-agent-8.3.0-linux-x86_64.tar.gz
cd elastic-agent-8.3.0-linux-x86_64
sudo ./elastic-agent install \\
--fleet-server-es=https://192.168.0.3:9200 \\
--fleet-server-service-token=AAEAAWVsYXN0aWMvZmxlZXQtc2VydmVyL3Rva2VuLTE2NTY1Njg5MTE1NTk6clBaX1pidXNTdTZXc2Fvb0ROcXVhUQ \\
--fleet-server-policy=fleet-server-policy \\
--fleet-server-es-ca-trusted-fingerprint=764021beb30446365d829986a362ffba82d03f4ff7861839a60f7951b8e83e7a我们按照 Kibana 中的提示来安装:
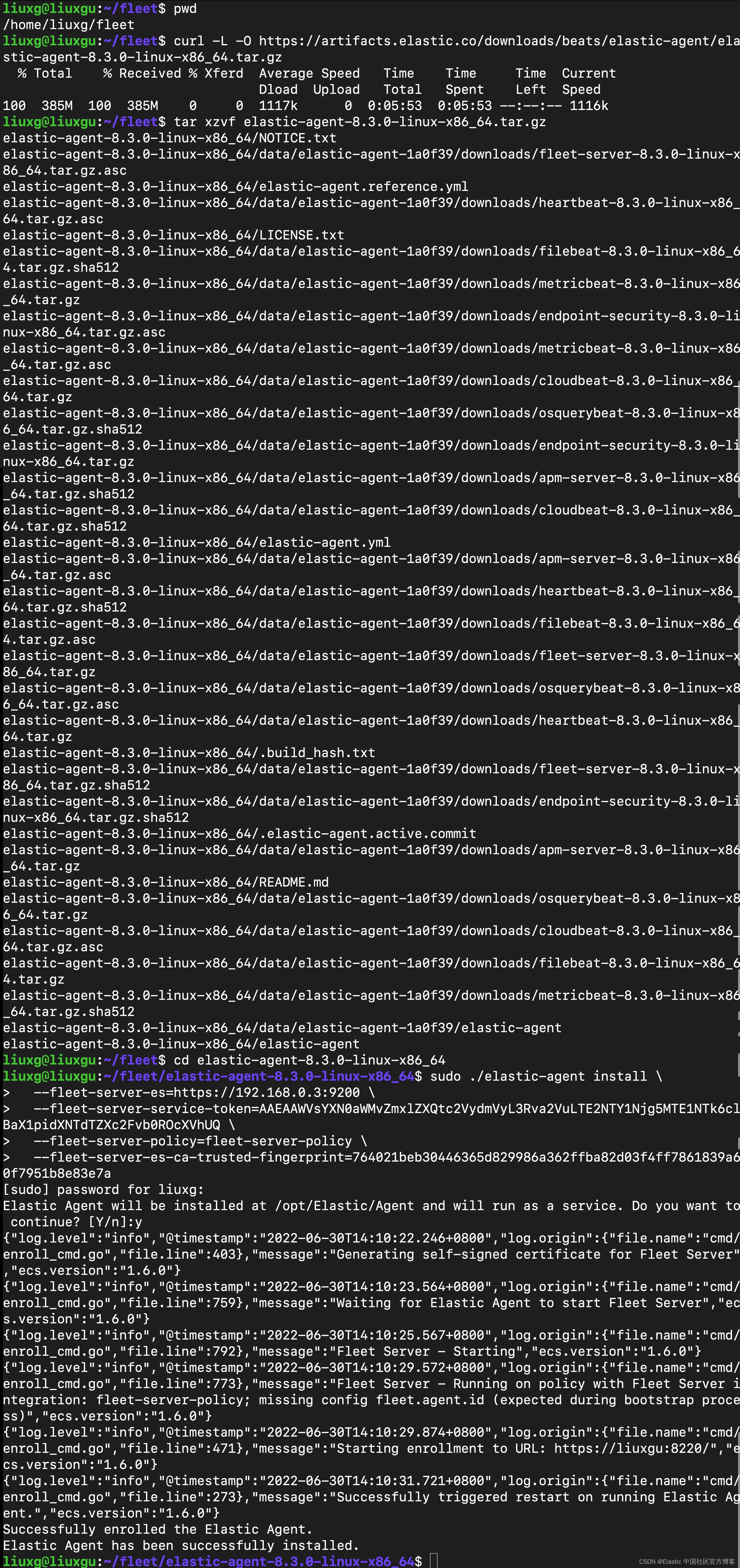
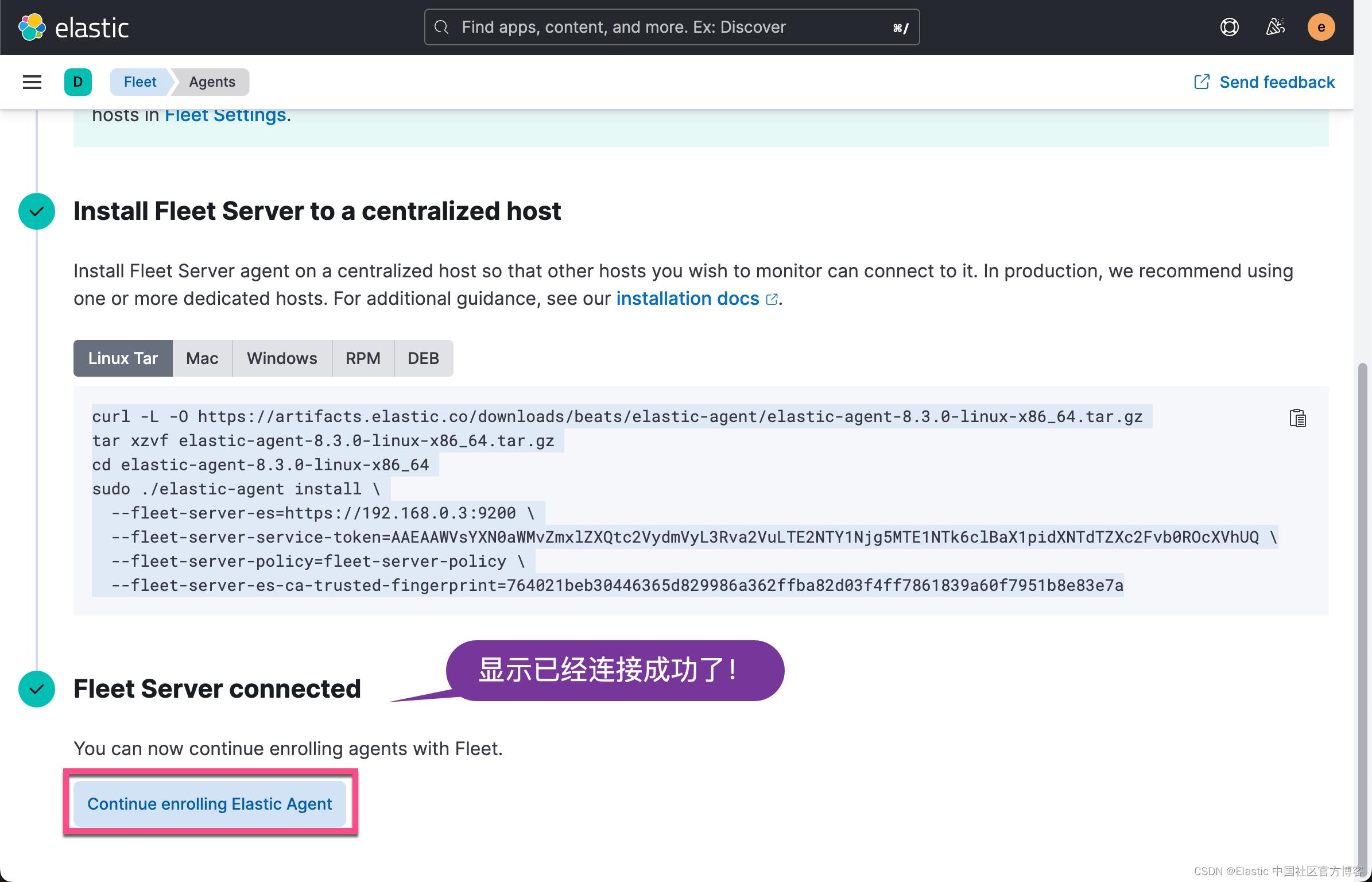
等过一段时间,我们可以看到这个运用于 192.168.0.4 机器上的 Agents 的状态也变为 healthy:
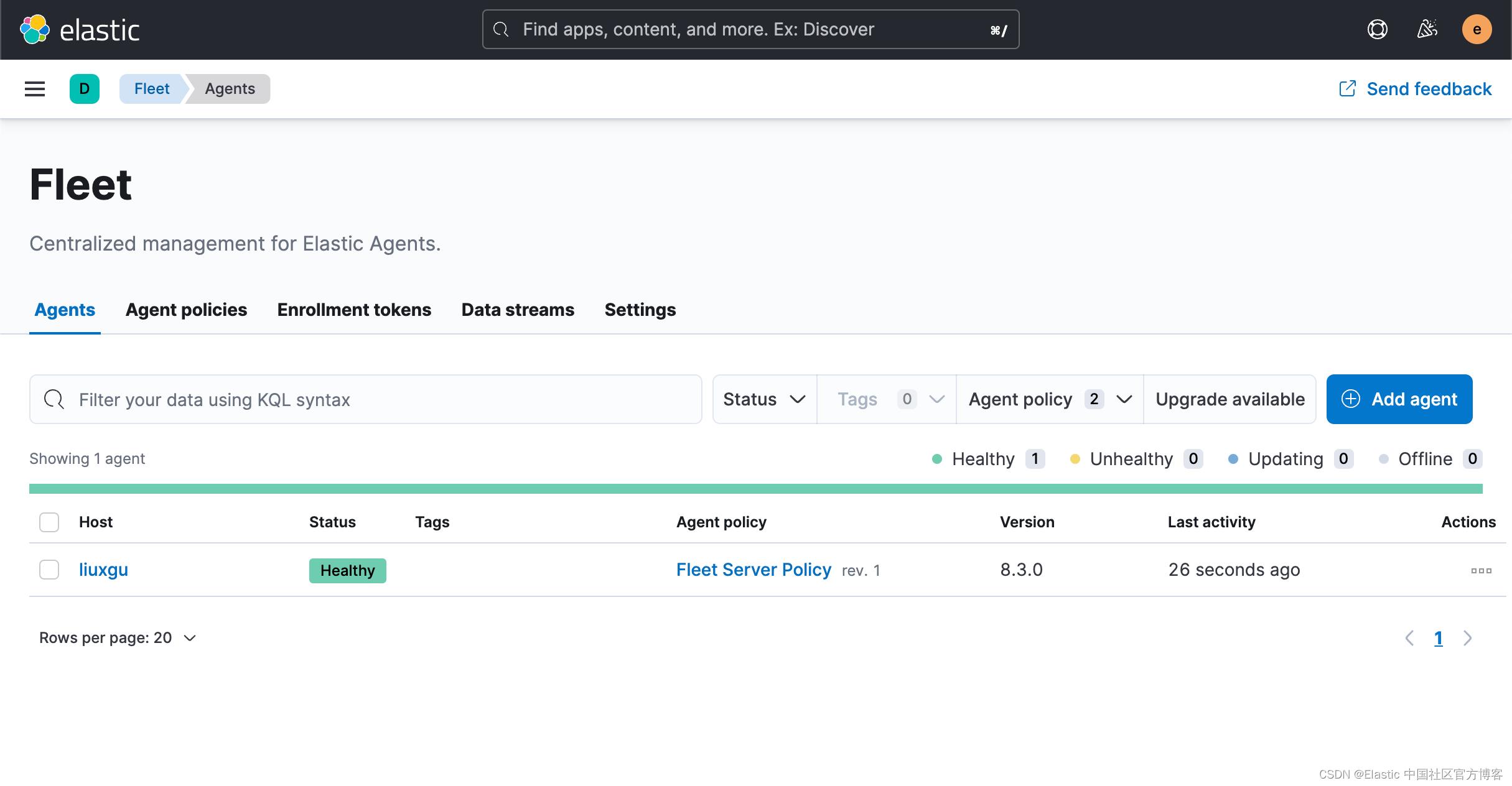
由于我们的 Elastic Agent 和 Fleet Server 是在一个服务器上运行的,所以,我们直接在 Fleet Server Policy 里添加我们想要的 integration。如果你的 Elastic Agent 可以运行于另外的一个机器上,而不和 Fleet Server 在同一个机器上,你可以创建一个新的 policy,比如 logs。然后让 agent 赋予给这个 新创建的 policy。
我们直接在这个 Fleet Server Policy 里添加一个叫做 custom log 的集成:
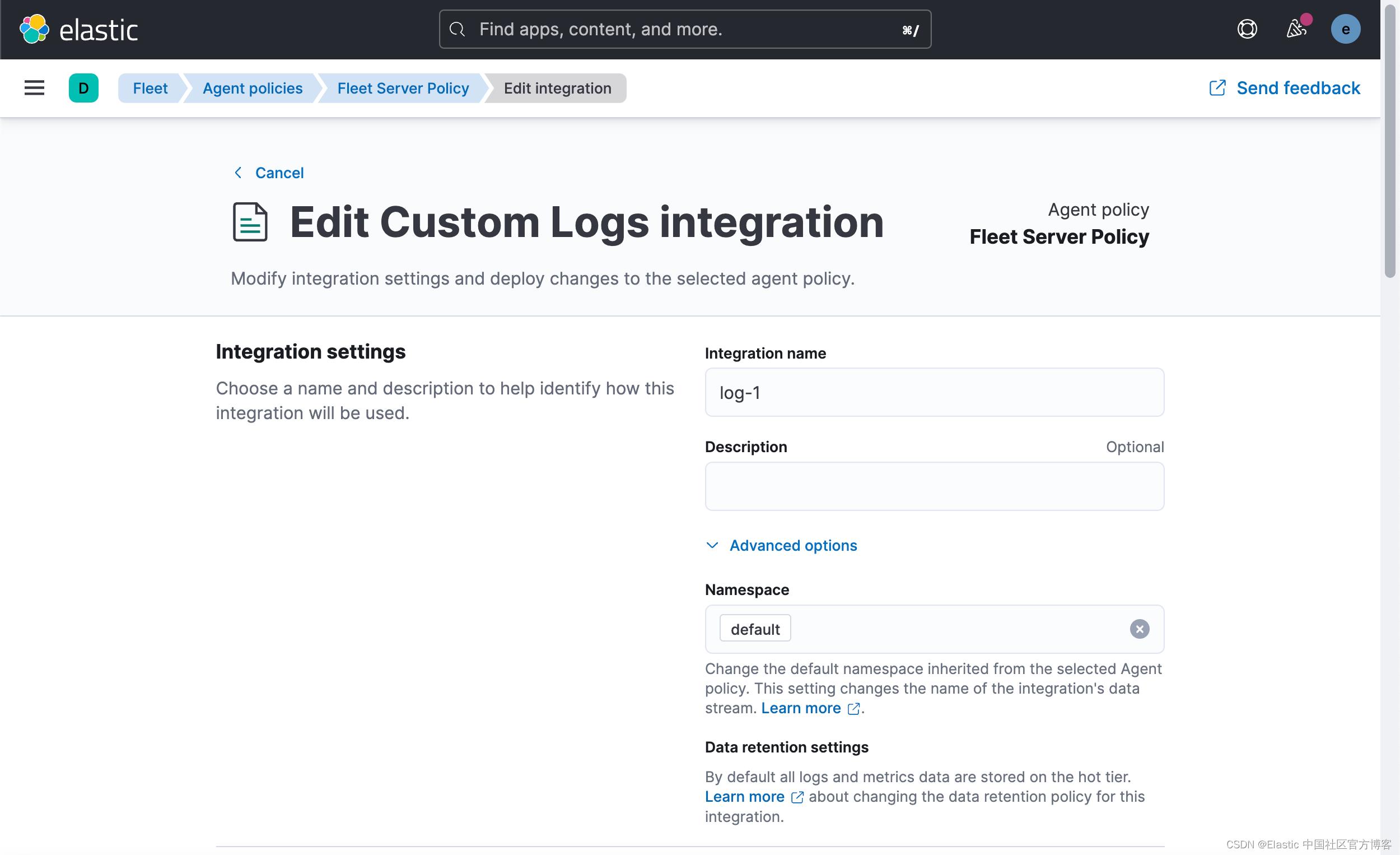
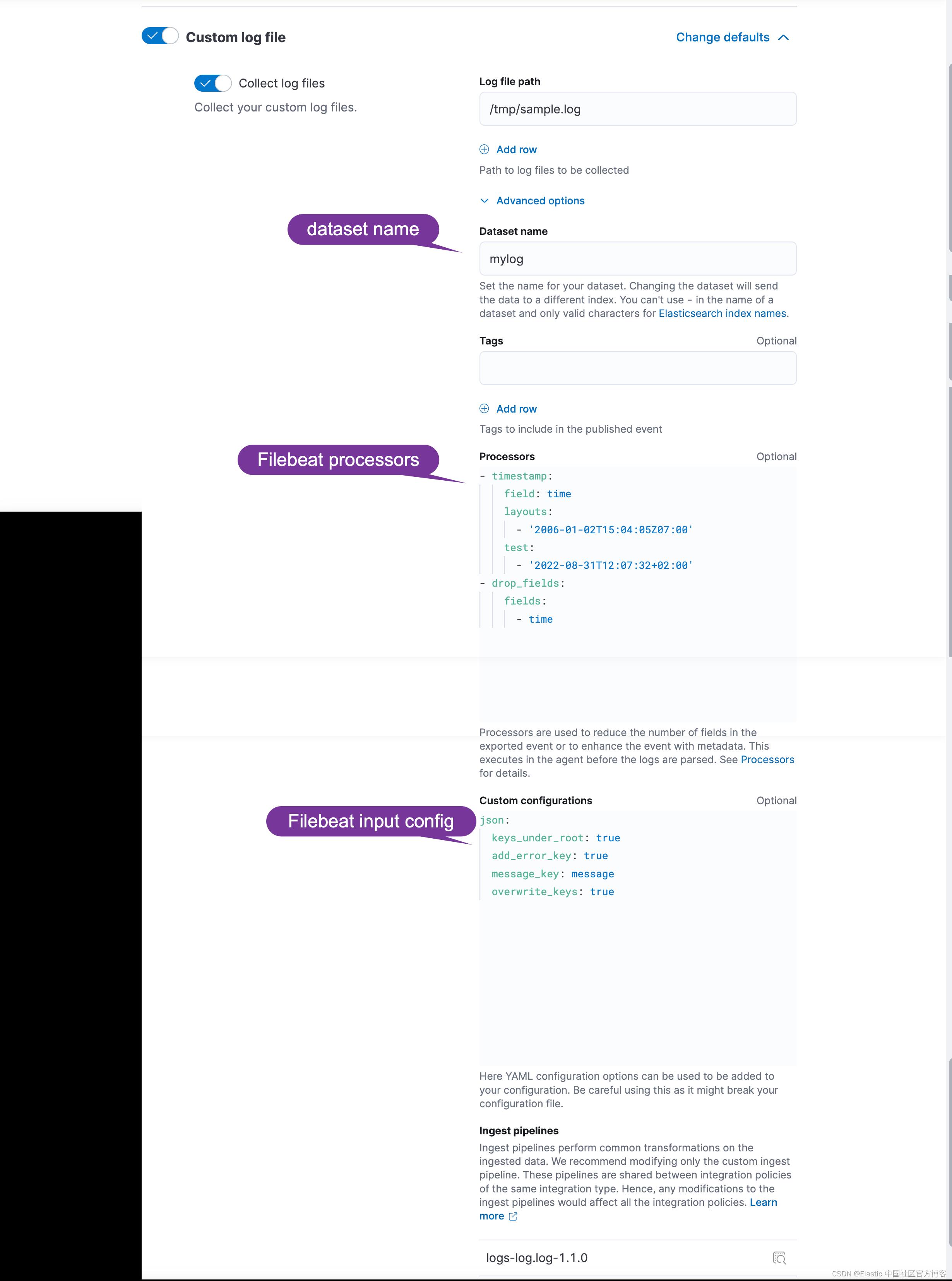
在幕后(在撰写本文时)Elastic-Agent 将运行一个 Filebeat 实例,因此这些可选配置的所有文档都是 Filebeat 的文档。 Custom Log 集成在后台使用 Log input,因此我们感兴趣的文档是:
- Processors:顾名思义,它们可以丰富、修改我们的事件。
- Custom configurations:好吧,它们是我们输入的自定义配置。
在上面,我们需要了解如下两个链接的文档:
Procsessors
我们将需要两个处理器:
- timestamp:它将解析我们的时间戳并在最终事件上正确设置它
- drop_fields:这个是可选的,但如果我们已经在事件中正确设置了@timestamp,就不需要保留时间字段。
- timestamp:
field: time
layouts:
- '2006-01-02T15:04:05Z07:00'
test:
- '2022-08-31T12:07:32+02:00'
- drop_fields:
fields:
- time这里唯一需要注意的是,时间戳处理器仍处于测试阶段,但它足够稳定,可以使用。 无论如何,在使用它时请记住这一点。
Custom configuration
自定义配置是关于告诉日志输入我们希望它将数据解析为 JSON,覆盖事件中已经存在的任何键,如果有错误,向最终事件添加一个错误键,这样我们就可以知道发生了什么。
json:
keys_under_root: true
add_error_key: true
message_key: message
overwrite_keys: true在上面,我们使用 Filebeat 的 processors 来对数据进行加工。如果你对这个不是很熟的话,请参考我之前的文章 “Beats:Beats processors”。
同时,针对 Filebeat 的 input 的配置,请参考文章 “Beats:使用 Elastic Stack 记录 Python 应用日志”。
Mappings
让我们确保 Elasticsearch 正确理解我们的数据,因为我们需要为我们的数据设置映射。
前往 Fleet > Agent Policies,单击 policy 名称,然后单击 integration 名称。 在下一个屏幕上,转到 Change defaults > Advanced options,在最底部有 Mappings 部分。
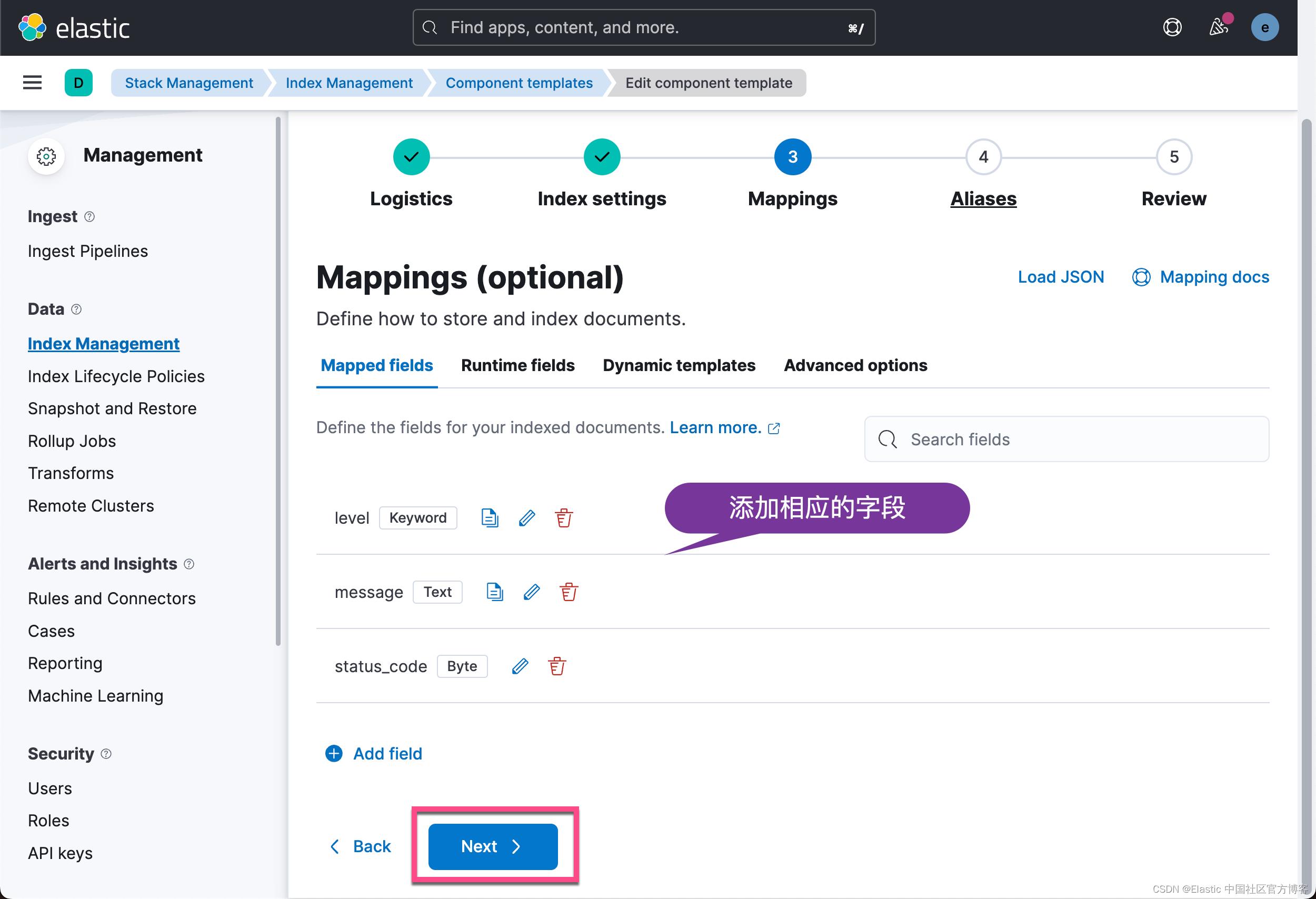
然后点击 Next,直到 Review 这一步,再点击 Save component template。
在 Kibana 中查看数据
前往 Discover,搜索一些数据,展开其中一个文档,你将看到正确映射的字段。
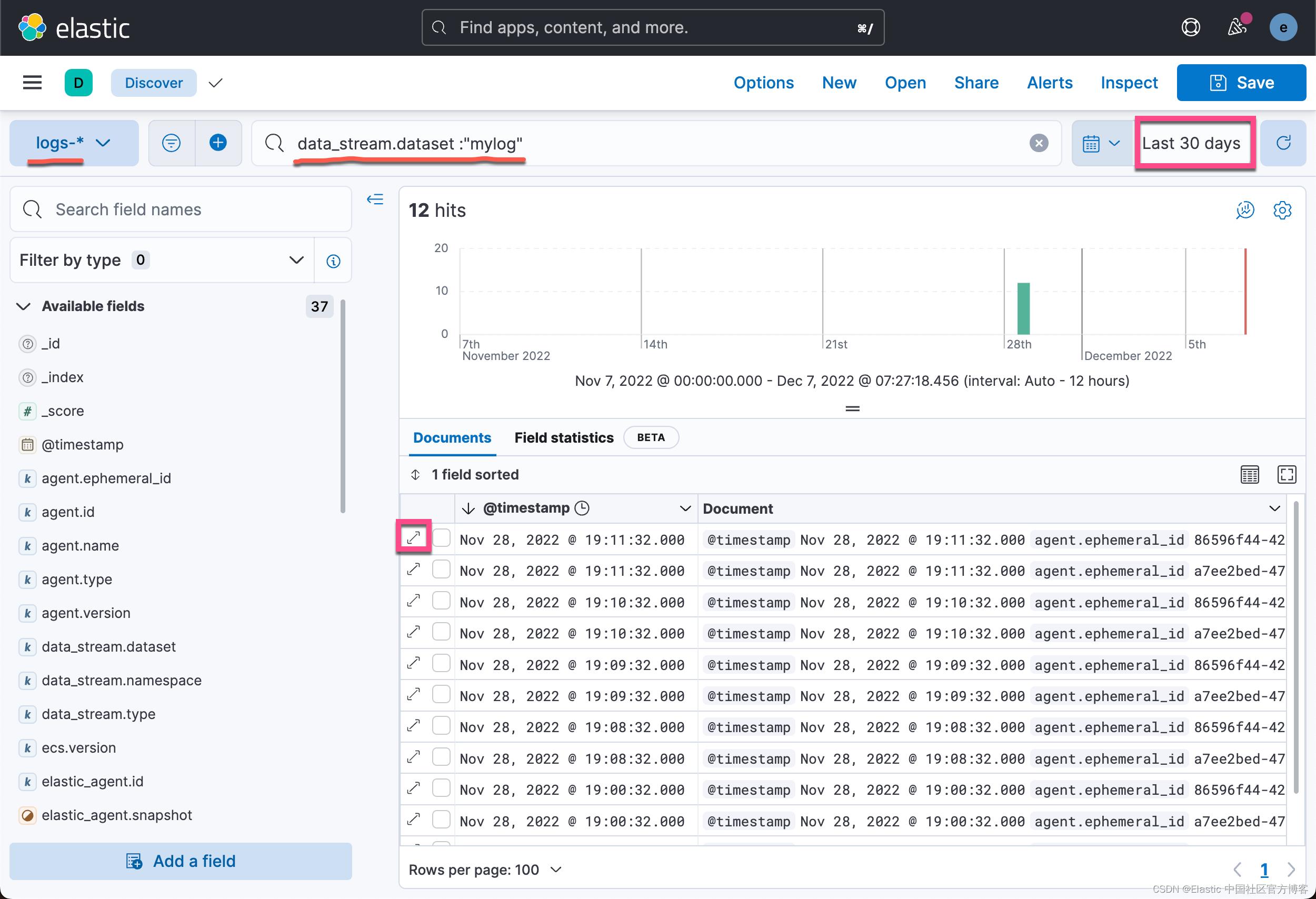
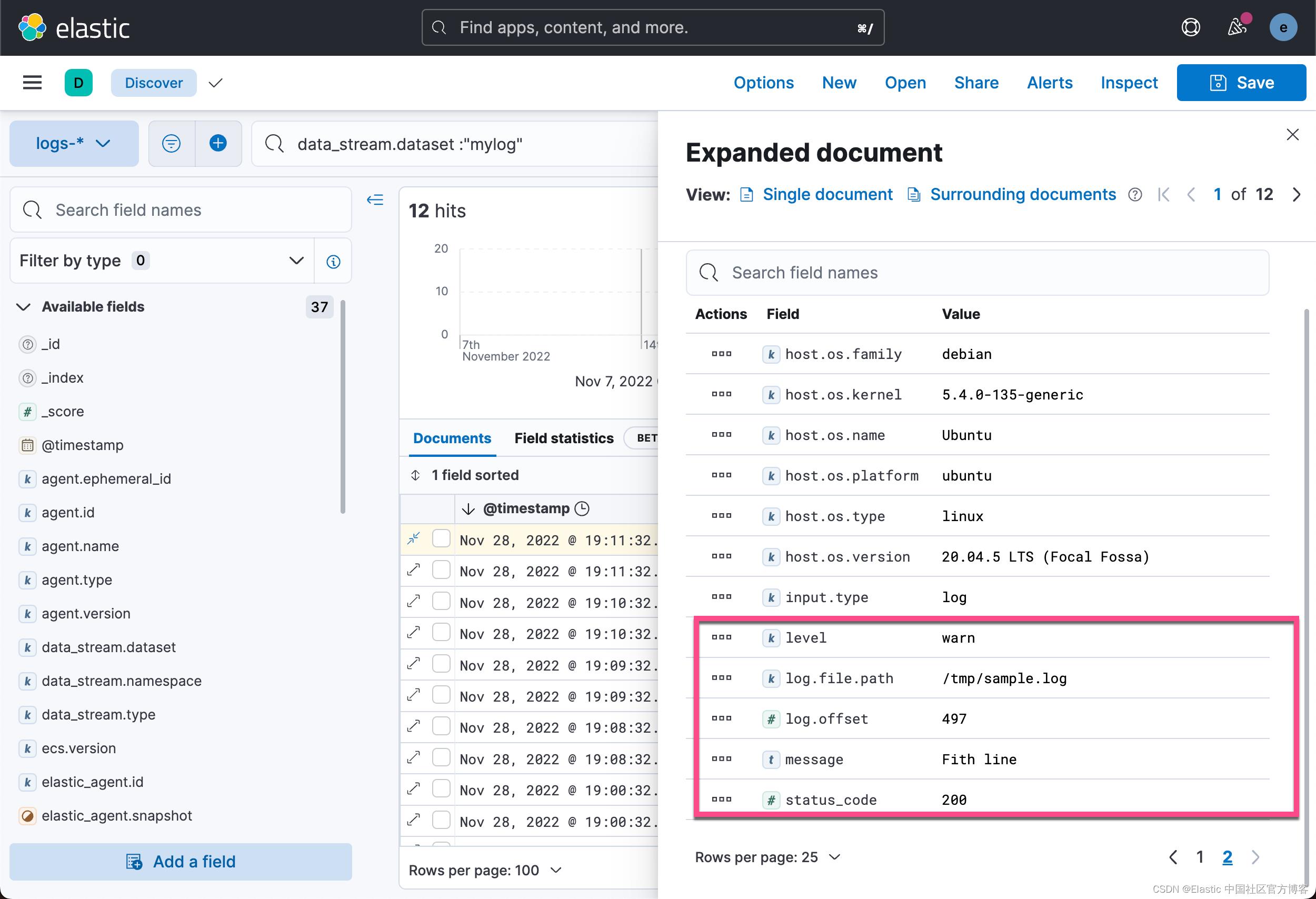
我们甚至可以针对 status_code 进行一个搜索:
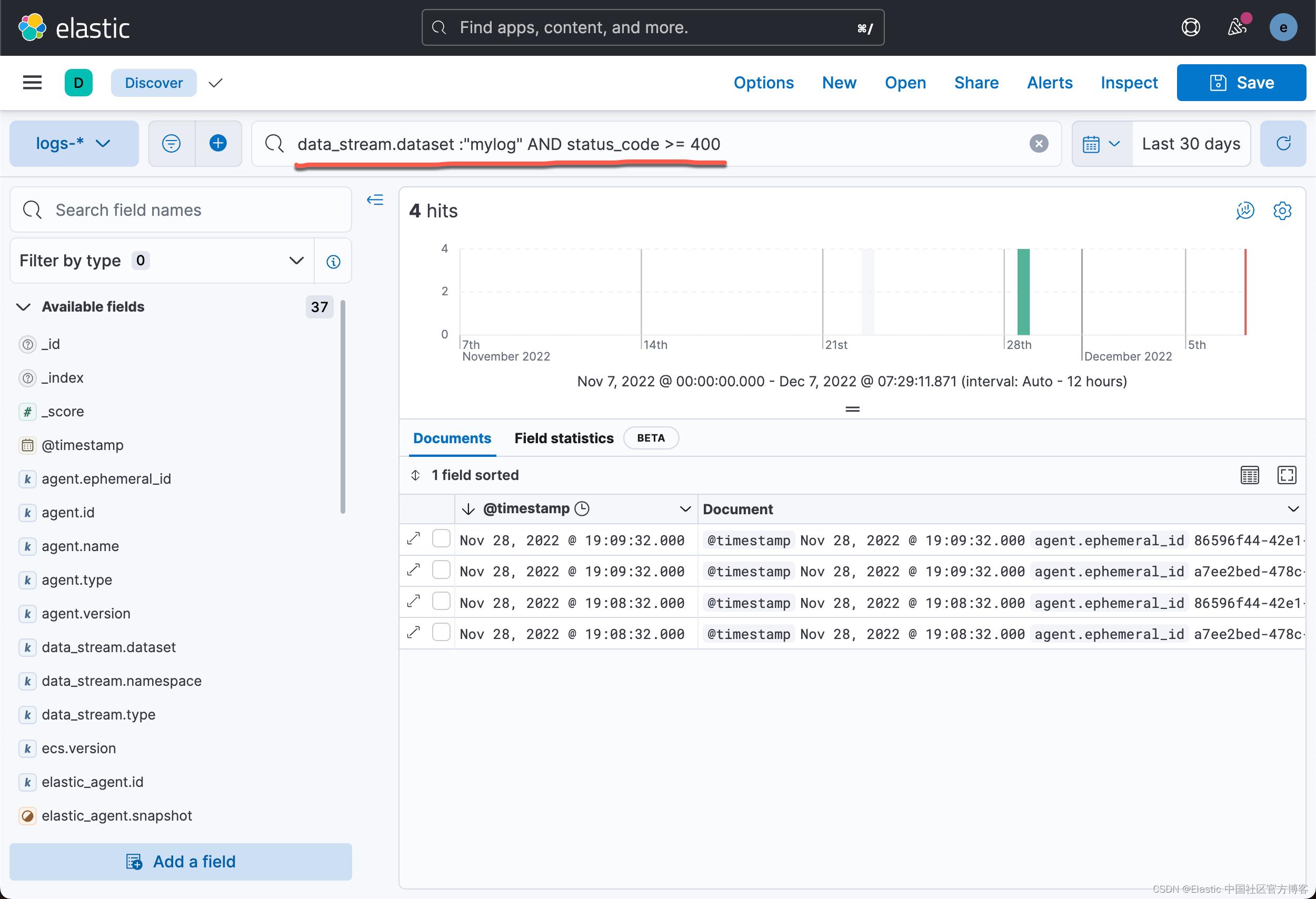
好了,我今天的分享就到这里。希望大家对 Elastic Agents 的使用会更加熟练。在实际的操作中,根据自己的情况进行相应的配置。
以上是关于Elasticsearch:如何在 Elastic Agents 中配置 Beats 来采集定制日志的主要内容,如果未能解决你的问题,请参考以下文章
Observability:如何在使用 Elastic Agents 把多行的日志摄入到 Elasticsearch 中
Elasticsearch:如何分析和优化 Elastic 部署的存储空间
Elasticsearch:如何在 Elastic 中实现图片相似度搜索