EigenFace的使用 python
Posted 编号1993
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了EigenFace的使用 python相关的知识,希望对你有一定的参考价值。
参考:
人脸识别之特征脸方法(Eigenface):http://blog.csdn.net/zouxy09/article/details/45276053
Eigenface算法,PCA数学理论,协方差:http://blog.csdn.net/gdut2015go/article/details/46271523
人脸识别算法-特征脸方法(Eigenface)及python实现:http://blog.csdn.net/u010006643/article/details/46417127
人脸识别经典算法之一:特征脸方法(Eigenface):http://blog.csdn.net/feirose/article/details/39552887
PCA数学原理:http://blog.csdn.net/u012005313/article/details/50877366
#######################################################################
关于PCA数学方面,可以看上面的PCA数学原理
EigenFace实现步骤:
1.获取M张图片集合。本实验中,使用4个人共20张图片,每张图片大小为256x256。将获取的20张图片按列排序,其中每张图片数据均拉平至一列(即256x256图像拉平为65536x1矩阵)。此时得到图像矩阵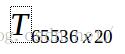
2.计算平均图像。图像矩阵T中每行表示一个字段,累加各个字段并平均得到平均图像M,此时M的大小为65536x1,可以通过操作转换为256x256格式,就是平均图像:

3.计算差值矩阵。将图像矩阵T每一列减去平均图像M就是差值矩阵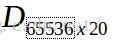
4.求解协方差矩阵。计算差值矩阵D的协方差矩阵C,求得特征向量和特征值。标准的PCA计算公式是: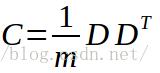 ,不过此时我们的差值矩阵维数是65536x20,所以求得协方差矩阵维数达到65536x65536,计算量过于大,不易于处理,并且存储也很困难。根据上面的博文,有一种简化的方法:
,不过此时我们的差值矩阵维数是65536x20,所以求得协方差矩阵维数达到65536x65536,计算量过于大,不易于处理,并且存储也很困难。根据上面的博文,有一种简化的方法:
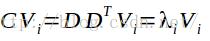 其中V表示特征向量,在等式两边乘以差值矩阵D,求得
其中V表示特征向量,在等式两边乘以差值矩阵D,求得
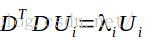 此时,U是
此时,U是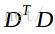 的特征向量,而根据上式可得
的特征向量,而根据上式可得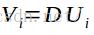
经过上述变换,我们只需求得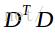 的特征值和特征向量U,然后用差值矩阵D乘以特征向量U就是协方差矩阵C的特征向量V。
的特征值和特征向量U,然后用差值矩阵D乘以特征向量U就是协方差矩阵C的特征向量V。
而计算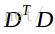 结果矩阵维数为20x20,大大减少了计算量。最后得到的特征向量矩阵V维数为65536x20,其中每一列代表一个特征脸,同样可以转换为图像
结果矩阵维数为20x20,大大减少了计算量。最后得到的特征向量矩阵V维数为65536x20,其中每一列代表一个特征脸,同样可以转换为图像
5.计算得到的特征向量矩阵并不是每一个有用(这里没有太弄懂)。因为一般训练图像的数量小于图像的维数,比如M<N^2,那么起作用的特征向量只有M-1个而不是N^2个(因为其他的特征向量对应的特征值为0)。所以我仅使用最大几个特征值对应的特征向量
6.计算权重。假定我使用3个特征向量构成基向量,即可求得训练图像在新的子空间的表示,称之为权重。计算公式为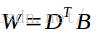 。W为权重向量矩阵,表示训练图像在新子空间的表示,结果维数是20x3;D表示差值图像矩阵,维数为65536x20;B表示基向量矩阵,维数为65536x3
。W为权重向量矩阵,表示训练图像在新子空间的表示,结果维数是20x3;D表示差值图像矩阵,维数为65536x20;B表示基向量矩阵,维数为65536x3
7.此时可以进行图像识别。读取一张新的人脸图像,将图像拉平成一列得到矩阵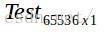 ,使用上面得到的基向量矩阵B计算得到权重
,使用上面得到的基向量矩阵B计算得到权重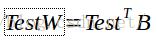
8.利用欧式距离方法用权重计算。当距离小于阈值时说明要判别的脸和训练集内的第k个脸是同一个人。当遍历所有训练集都大于阈值时,根据距离值的大小又可分为是新的人脸或者不是人脸的两种情况。
######################################################
我写的一个算法(python):
#!/usr/bin/env python
#-*- coding: utf-8 -*-
'''
eigenface的python实现
'''
__author__='zj'
import cv2
import os
import sys
import numpy as np
from numpy import *
suffix_list=['.jpg', '.png', '.jpeg', '.JPG', '.PNG', '.JPEG']
'''
提取所有图片以及对应的标签 src_dir格式如下:
.
├── PEOPLE_GRAY_1
│ ├── 10.jpg
│ ├── 12.jpg
│ ├── 3.jpg
│ ├── 5.jpg
│ └── 6.jpg
├── PEOPLE_GRAY_2
│ ├── 12.jpg
│ ├── 14.jpg
│ ├── 21.jpg
│ ├── 6.jpg
│ └── 9.jpg
├── PEOPLE_GRAY_3
│ ├── 38.jpg
│ ├── 46.jpg
│ ├── 49.jpg
│ ├── 54.jpg
│ └── 57.jpg
└── PEOPLE_GRAY_4
├── 14.jpg
├── 18.jpg
├── 20.jpg
├── 7.jpg
└── 9.jpg
'''
def getImgAndLabel(src_dir):
#初始化返回结果
imgs=[] #存放图像
labels=[] #存放类别
#获取子文件夹名
catelist=os.listdir(src_dir)
#遍历子文件夹
for catename in catelist:
#设置子文件夹路径
cate_dir=os.path.join(src_dir, catename)
#获取子文件名
filelist=os.listdir(cate_dir)
#遍历所有文件名
for filename in filelist:
#设置文件路径
file_dir=os.path.join(cate_dir, filename)
#判断文件名是否为图片格式
if not os.path.splitext(filename)[1] in suffix_list:
print file_dir,"is not an image"
continue
#endif
#读取灰度图
imgs.append(cv2.imread(file_dir, cv2.IMREAD_GRAYSCALE))
#读取相应类别
labels.append(catename)
#endfor
#endfor
return imgs,labels
#end of getImgAndLabel
#将图像数据变为一列
def convertImageToArray(img):
img_arr=[]
height,width=img.shape[:2]
#遍历图像
for i in range(height):
img_arr.extend(img[i,:])
#endfor
return img_arr
#end of convertImageToArray
#将每个图像变为一列
def convertImageToArrays(imgs):
#初始化数组
arr=[]
#遍历每个图像
for img in imgs:
arr.append(convertImageToArray(img))
#endfor
return array(arr).T
#end of convertImageToArrays
#计算均值数组
def compute_mean_array(arr):
#获取维数(行数),图像数(列数)
dimens,nums=arr.shape[:2]
#新建列表
mean_arr=[]
#遍历维数
for i in range(dimens):
aver=0
#求和每个图像在该字段的值并平均
aver=int(sum(arr[i,:])/float(nums))
mean_arr.append(aver)
#endfor
return array(mean_arr)
#end of compute_mean_array
#将数组转换为对应图像
def convert_array_to_image(arr, height=256, width=256):
img=[]
for i in range(height):
img.append(arr[i*width:i*width+width])
#endfor
return array(img)
#end of convert_array_to_image
#计算图像和平均图像之间的差值
def compute_diff(arr, mean_arr):
return arr-mean_arr
#end of compute_diff
#计算每张图像和平均图像之间的差值
def compute_diffs(arr, mean_arr):
diffs=[]
dimens,nums=arr.shape[:2]
for i in range(nums):
diffs.append(compute_diff(arr[:,i], mean_arr))
#endfor
return array(diffs).T
#end of compute_diffs
#计算协方差矩阵的特征值和特征向量,按从大到小顺序排列
#arr是预处理图像的矩阵,每一列对应一个减去均值图像之后的图像
def compute_eigenValues_eigenVectors(arr):
arr=array(arr)
#计算arr'T * arr
temp=dot(arr.T, arr)
eigenValues,eigenVectors=linalg.eig(temp)
#将数值从大到小排序
idx=np.argsort(-eigenValues)
eigenValues=eigenValues[idx]
#特征向量按列排
eigenVectors=eigenVectors[:,idx]
return eigenValues,dot(arr,eigenVectors)
#end of compute_eigenValues_eigenVectors
#计算图像在基变换后的坐标(权重)
def compute_weight(img, vec):
return dot(img, vec)
#end of compute_weight
#计算图像权重
def compute_weights(imgs, vec):
dimens,nums=imgs.shape[:2]
weights=[]
for i in range(nums):
weights.append(compute_weight(imgs[:, i], vec))
return array(weights)
#end of compute_weights
#计算两个权重之间的欧式距离
def compute_euclidean_distance(wei1, wei2):
#判断两个向量的长度是否相等
if not len(wei1) == len(wei2):
print '长度不相等'
os._exit(1)
#endif
sqDiffVector=wei1-wei2
sqDiffVector=sqDiffVector**2
sqDistances=sqDiffVector.sum()
distance=sqDistances**0.5
return distance
#end of compute_euclidean_distance
#计算待测图像与图像库中各图像权重的欧式距离
def compute_euclidean_distances(wei, wei_test):
weightValues=[]
nums=wei.shape
print nums
for i in range(nums[0]):
weightValues.append(compute_euclidean_distance(wei[i], wei_test))
#endfor
return array(weightValues)
#end of compute_euclidean_distances
if __name__ == '__main__':
#获取图片库路径
src_dir=os.path.join(os.getcwd(), "gray")
#获取图片以及对应类别
imgs,labels=getImgAndLabel(src_dir)
'''
for i in range(len(labels)):
print labels[i]
'''
#将图片转换为数组
arr=convertImageToArrays(imgs)
print "arr's shape : ".format(arr.shape)
#计算均值图像
mean_arr=compute_mean_array(arr)
print mean_arr
print "mean_arr's shape: ".format(mean_arr.shape)
#mean_img=convert_array_to_image(mean_arr)
#print mean_img
#print "type(mean_img) : ".format(type(mean_img))
#cv2.imwrite("mean.png", mean_img)
#获取差值图像
arr_diff=compute_diffs(arr, mean_arr)
#计算特征值以及特征向量
eigenValues,eigenVectors=compute_eigenValues_eigenVectors(arr)
print "eigenValues'shape : ".format(eigenValues.shape)
print "eigenVectors'shape : ".format(eigenVectors.shape)
#print eigenValues
#计算权重向量,此处假定使用特征值最大的前3个对应的特征向量作为基
weights=compute_weights(arr_diff, eigenVectors[:,:3])
print "weights.shape : ".format(weights.shape)
#print weights
#读取测试图像,此处使用训练库中的一张
img_test=cv2.imread("gray/PEOPLE_GRAY_1/10.jpg", cv2.IMREAD_GRAYSCALE)
arr_test=convertImageToArray(img_test)
diff_test=compute_diff(arr_test, mean_arr)
wei=compute_weight(diff_test, eigenVectors[:,:3])
print "test's weight : ".format(wei)
#计算欧式距离
weightValues=compute_euclidean_distances(weights, wei)
print "weightValues.shape : ".format(weightValues.shape)
#打印结果
for i in range(len(weightValues)):
print weightValues[i], labels[i]
'''
for i in range(len(eigenValues)):
img=convert_array_to_image(eigenVectors[:,i])
cv2.imwrite(str(i)+".jpg" ,img)
#break
#print eigenValues[i]
#endfor
cv2.waitKey()
print "endl..."'''
#endif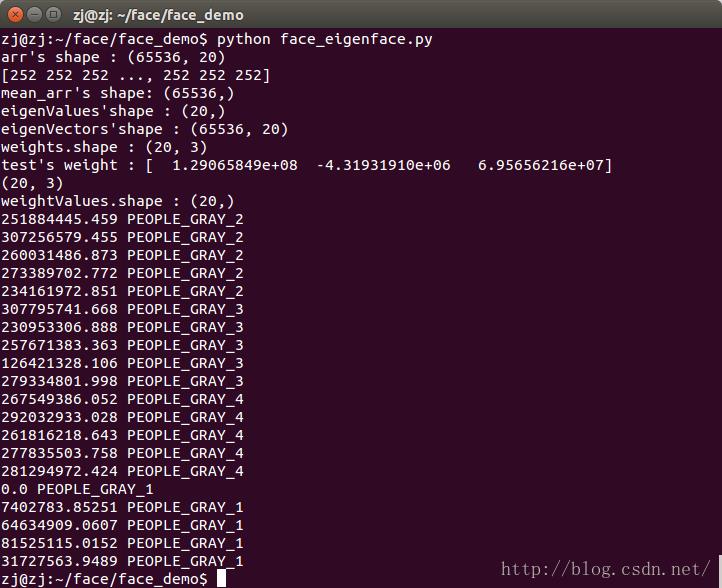
结果由图可知,由于使用的是训练集中的一张图片,所以得到的结果存在欧式距离刚好为0的情况
######################################################################################################
其中的一篇博文里记载的python代码,修改了一些,没办法运行,不过其中一些python函数值得学习以下:
#coding:utf-8
from numpy import *
from numpy import linalg as la
import cv2
import os
def loadImageSet(add):
FaceMat=mat(zeros(20, 256*256))
j=0
#获取子文件夹名
catelist=os.listdir(src_dir)
#遍历子文件夹
for catename in catelist:
#设置子文件夹路径
cate_dir=os.path.join(src_dir, catename)
#获取子文件名
filelist=os.listdir(cate_dir)
#遍历所有文件名
for filename in filelist:
#设置文件路径
file_dir=os.path.join(cate_dir, filename)
#判断文件名是否为图片格式
if not os.path.splitext(filename)[1] in suffix_list:
print file_dir,"is not an image"
continue
#endif
#读取灰度图
img=cv2.imread(file_dir, cv2.IMREAD_GRAYSCALE)
FaceMat[j,:]=mat(img).flatten()
j+=1
#读取相应类别
labels.append(catename)
#endfor
#endfor
return FaceMat
'''
FaceMat = mat(zeros((15,98*116)))
j =0
for i in os.listdir(add):
if i.split('.')[1] == 'normal':
try:
img = cv2.imread(add+i,0)
except:
print 'load %s failed'%i
FaceMat[j,:] = mat(img).flatten()
j += 1
return FaceMat
'''
def ReconginitionVector(selecthr = 0.8):
# step1: load the face image data ,get the matrix consists of all image
FaceMat = loadImageSet(os.path.join(os.getcwd(), "gray")).T
# step2: average the FaceMat
avgImg = mean(FaceMat,1)
# step3: calculate the difference of avgimg and all image data(FaceMat)
diffTrain = FaceMat-avgImg
#step4: calculate eigenvector of covariance matrix (because covariance matrix will cause memory error)
eigvals,eigVects = linalg.eig(mat(diffTrain.T*diffTrain))
#从大到小排序
eigSortIndex = argsort(-eigvals)
#此处利用阈值设置新空间的基向量个数,特征值按从大到小排列,从头相加,其值刚刚大于阈值则其对应特征向量为基向量
for i in xrange(shape(FaceMat)[1]):
if (eigvals[eigSortIndex[:i]]/eigvals.sum()).sum() >= selecthr:
eigSortIndex = eigSortIndex[:i]
break
covVects = diffTrain * eigVects[:,eigSortIndex] # covVects is the eigenvector of covariance matrix
# avgImg 是均值图像,covVects是协方差矩阵的特征向量,diffTrain是偏差矩阵
return avgImg,covVects,diffTrain
#judgeImg - 待处理图像
#FaceVector - 特征向量矩阵
#avgImg - 平均图像矩阵
#diffTrain - 差值图像矩阵
def judgeFace(judgeImg,FaceVector,avgImg,diffTrain):
#待处理图像减去平均图像
diff = judgeImg.T - avgImg
#计算权重向量
weiVec = FaceVector.T* diff
res = 0
resVal = inf
for i in range(15):
TrainVec = FaceVector.T*diffTrain[:,i]
if (array(weiVec-TrainVec)**2).sum() < resVal:
res = i
resVal = (array(weiVec-TrainVec)**2).sum()
return res+1
if __name__ == '__main__':
avgImg,FaceVector,diffTrain = ReconginitionVector(selecthr = 0.9)
nameList = ['01','02','03','04','05','06','07','08','09','10','11','12','13','14','15']
characteristic = ['centerlight','glasses','happy','leftlight','noglasses','rightlight','sad','sleepy','surprised','wink']
for c in characteristic:
count = 0
for i in range(len(nameList)):
# 这里的loadname就是我们要识别的未知人脸图,我们通过15张未知人脸找出的对应训练人脸进行对比来求出正确率
loadname = 'gray/PEOPLE_GRAY_1/10.jpg'#+nameList[i]+'.'+c+'.pgm'
judgeImg = cv2.imread(loadname,0)
if judgeFace(mat(judgeImg).flatten(),FaceVector,avgImg,diffTrain) == int(nameList[i]):
count += 1
print 'accuracy of %s is %f'%(c, float(count)/len(nameList)) # 求出正确率
mean函数:
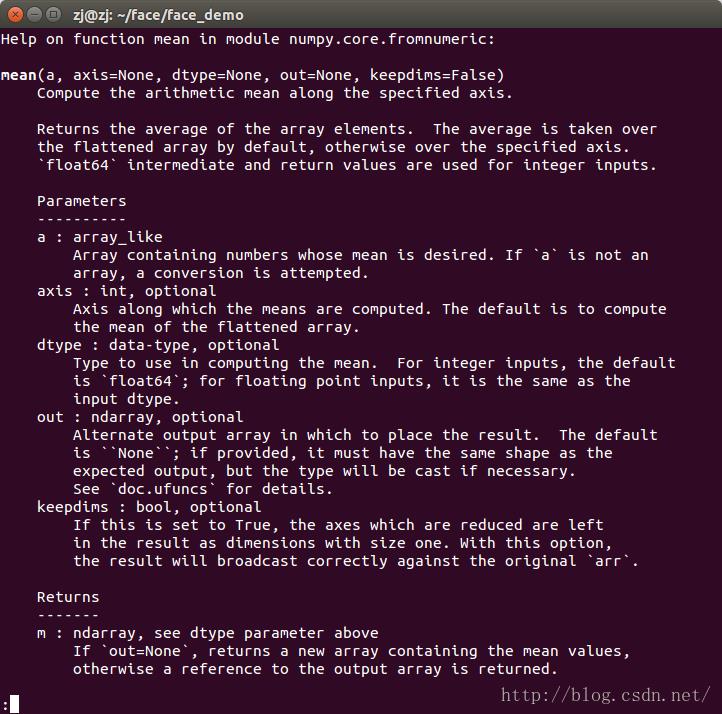
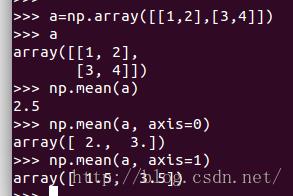
功能:沿着指定的轴计算算术平均值。默认求和数组中每个元素并按元素数求和。可以指定某个轴进行计算,axis=0表示沿着x轴计算,axis=1表示沿着y轴计算。在计算过程中使用数据类型"float64"进行计算,不过返回时会自动转换为integer格式
参数 a:数组或矩阵,不为空
参数axis:int类型,默认为空,表示整个数组进行计算,axis=0时求和每列并求平均值;axis=1时求和每行并求平均值
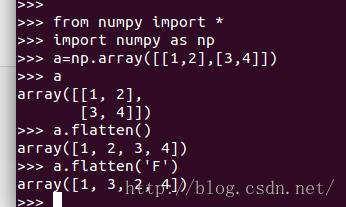
flatten
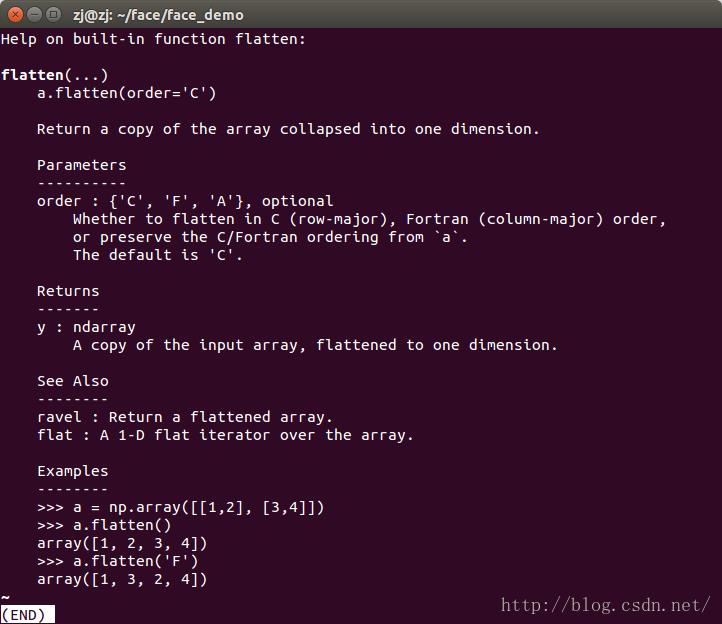
功能:将数组折叠成一个维度
参数order:可选,默认为'c',表示按行排列;如果设为'F',表示按列排列
numpy.linalg.eig:
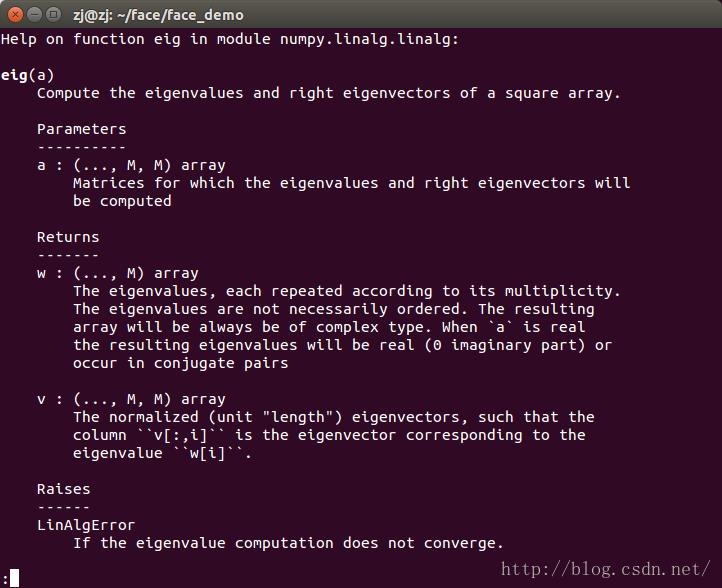
功能:计算正方形数组或矩阵的特征值以及对应的特征向量
返回的特征值和特征向量都是数组类型,并且特征向量是按行排列的
以上是关于EigenFace的使用 python的主要内容,如果未能解决你的问题,请参考以下文章