adreno源码系列全局内存申请
Posted bubbleben
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了adreno源码系列全局内存申请相关的知识,希望对你有一定的参考价值。
1. kgsl_allocate_global
struct kgsl_memdesc *kgsl_allocate_global(struct kgsl_device *device,
u64 size, u32 padding, u64 flags, u32 priv, const char *name)
int ret;
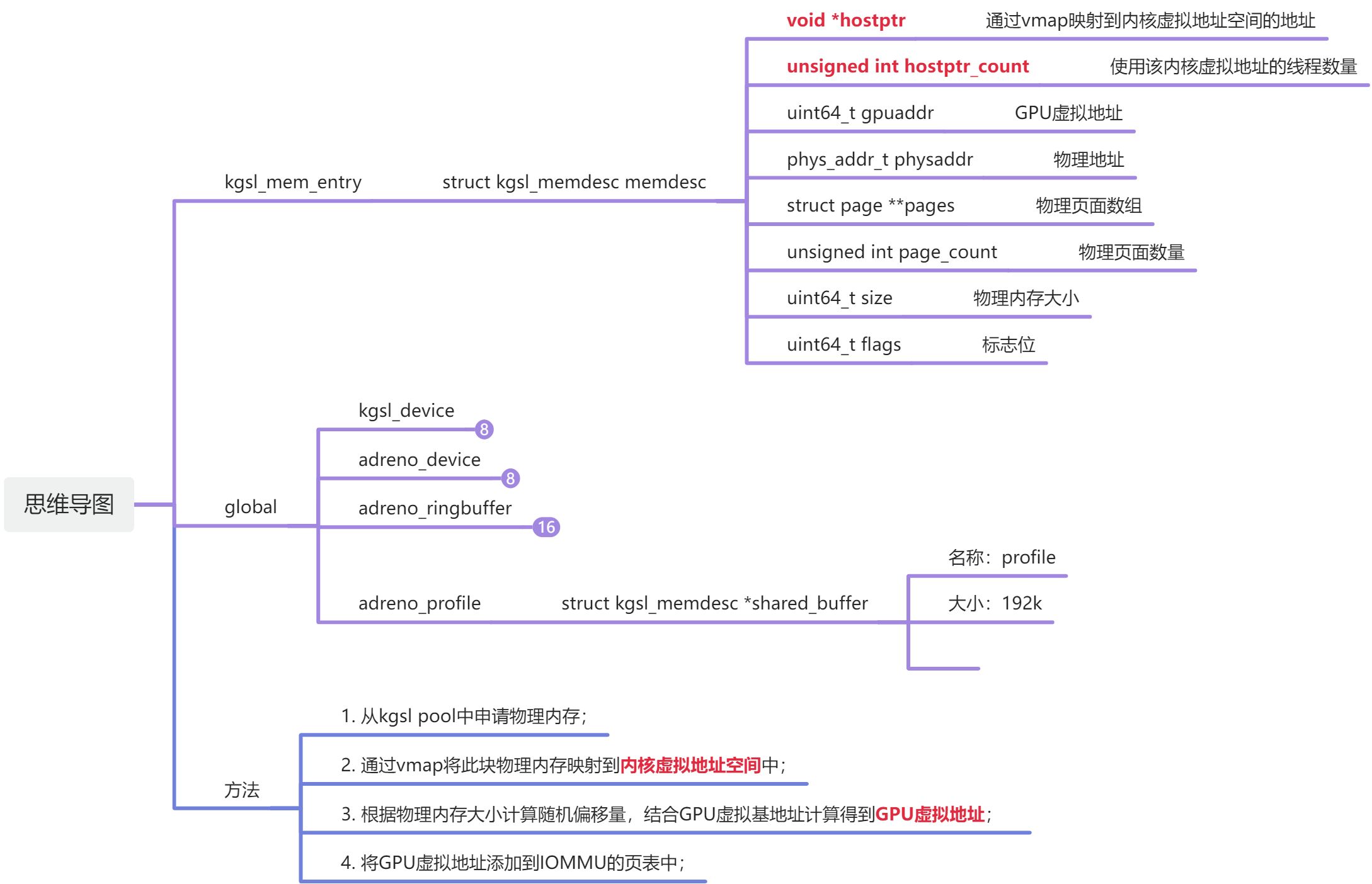
// 全局内存描述符[见1.1节]
struct kgsl_global_memdesc *md;
if (flags & KGSL_MEMFLAGS_SECURE)
return kgsl_allocate_secure_global(device, size, flags, priv,
name);
// 分配kgsl_global_memdesc
md = kzalloc(sizeof(*md), GFP_KERNEL);
if (!md)
return ERR_PTR(-ENOMEM);
/*
* Make sure that we get global memory from system memory to keep from
* taking up pool memory for the life of the driver
*/
// 设置私有标志位
priv |= KGSL_MEMDESC_GLOBAL | KGSL_MEMDESC_SYSMEM;
// 申请物理内存[见第2节]
ret = kgsl_allocate_kernel(device, &md->memdesc, size, flags, priv);
if (ret)
kfree(md);
return ERR_PTR(ret);
// 设置全局内存描述符的名称
md->name = name;
/*
* No lock here, because this function is only called during probe/init
* while the caller is holding the mute
*/
// 将其添加到kgsl_device->globals链表尾部
list_add_tail(&md->node, &device->globals);
// 分配GPU虚拟地址并映射到GPU页表[见第3节]
kgsl_mmu_map_global(device, &md->memdesc, padding);
kgsl_trace_gpu_mem_total(device, md->memdesc.size);
// 返回全局内存描述符的kgsl_memdesc成员
return &md->memdesc;
1.1 kgsl_global_memdesc
/**
* struct kgsl_global_memdesc - wrapper for global memory objects
*/
// 全局内存描述符:主要是对kgsl_memdesc的封装
struct kgsl_global_memdesc
/** @memdesc: Container for the GPU memory descriptor for the object */
struct kgsl_memdesc memdesc;
/** @name: Name of the object for the debugfs list */
const char *name;
/** @node: List node for the list of global objects */
struct list_head node;
;
2. kgsl_allocate_kernel
int kgsl_allocate_kernel(struct kgsl_device *device,
struct kgsl_memdesc *memdesc, u64 size, u64 flags, u32 priv)
int ret;
// kgsl_allocate_user[见2.1节]
ret = kgsl_allocate_user(device, memdesc, size, flags, priv);
if (ret)
return ret;
// 调用在kgsl_system_ops中定义的kgsl_paged_map_kernel[见2.4节]
if (memdesc->ops->map_kernel)
ret = memdesc->ops->map_kernel(memdesc);
if (ret)
kgsl_sharedmem_free(memdesc);
return ret;
return 0;
2.1 kgsl_allocate_user
int kgsl_allocate_user(struct kgsl_device *device, struct kgsl_memdesc *memdesc,
u64 size, u64 flags, u32 priv)
if (device->mmu.type == KGSL_MMU_TYPE_NONE)
return kgsl_alloc_contiguous(device, memdesc, size, flags,
priv);
else if (flags & KGSL_MEMFLAGS_SECURE)
return kgsl_allocate_secure(device, memdesc, size, flags, priv);
// 分配物理页面[见2.2节]
return kgsl_alloc_pages(device, memdesc, size, flags, priv);
2.2 kgsl_alloc_pages
static int kgsl_alloc_pages(struct kgsl_device *device,
struct kgsl_memdesc *memdesc, u64 size, u64 flags, u32 priv)
struct page **pages;
int count;
size = PAGE_ALIGN(size);
if (!size || size > UINT_MAX)
return -EINVAL;
kgsl_memdesc_init(device, memdesc, flags);
memdesc->priv |= priv;
// 标志位包含KGSL_MEMDESC_SYSMEM
if (priv & KGSL_MEMDESC_SYSMEM)
// kgsl_memdesc的操作函数
memdesc->ops = &kgsl_system_ops;
// 从系统而非kgsl内存池分配页面[见2.3节]
count = kgsl_system_alloc_pages(size, &pages, device->dev);
else
memdesc->ops = &kgsl_pool_ops;
count = kgsl_pool_alloc_pages(size, &pages, device->dev);
if (count < 0)
return count;
// 分配的物理页面
memdesc->pages = pages;
// 分配的物理内存大小
memdesc->size = size;
// 分配的物理页面数量
memdesc->page_count = count;
KGSL_STATS_ADD(size, &kgsl_driver.stats.page_alloc,
&kgsl_driver.stats.page_alloc_max);
return 0;
2.3 kgsl_system_alloc_pages
static int kgsl_system_alloc_pages(u64 size, struct page ***pages,
struct device *dev)
struct scatterlist sg;
struct page **local;
// 将内存大小转换为页面数量
int i, npages = size >> PAGE_SHIFT;
int order = get_order(PAGE_SIZE);
local = kvcalloc(npages, sizeof(*pages), GFP_KERNEL);
if (!local)
return -ENOMEM;
for (i = 0; i < npages; i++)
// 分配掩码
gfp_t gfp = __GFP_ZERO | __GFP_HIGHMEM |
GFP_KERNEL | __GFP_NORETRY;
// 从伙伴系统申请物理页面
local[i] = alloc_pages(gfp, get_order(PAGE_SIZE));
if (!local[i])
for (i = i - 1; i >= 0; i--)
#ifdef CONFIG_MM_STAT_UNRECLAIMABLE_PAGES
mod_node_page_state(page_pgdat(local[i]),
NR_UNRECLAIMABLE_PAGES, -(1 << order));
#endif
__free_pages(local[i], order);
kvfree(local);
return -ENOMEM;
/* Make sure the cache is clean */
sg_init_table(&sg, 1);
sg_set_page(&sg, local[i], PAGE_SIZE, 0);
sg_dma_address(&sg) = page_to_phys(local[i]);
dma_sync_sg_for_device(dev, &sg, 1, DMA_BIDIRECTIONAL);
#ifdef CONFIG_MM_STAT_UNRECLAIMABLE_PAGES
mod_node_page_state(page_pgdat(local[i]), NR_UNRECLAIMABLE_PAGES,
(1 << order));
#endif
// 返回page数组
*pages = local;
return npages;
2.4 kgsl_paged_map_kernel
static int kgsl_paged_map_kernel(struct kgsl_memdesc *memdesc)
int ret = 0;
/* Sanity check - don't map more than we could possibly chew */
if (memdesc->size > ULONG_MAX)
return -ENOMEM;
mutex_lock(&kernel_map_global_lock);
if ((!memdesc->hostptr) && (memdesc->pages != NULL))
pgprot_t page_prot = pgprot_writecombine(PAGE_KERNEL);
// kgsl_memdesc->hostptr用于表示内核空间虚拟地址:可以被所有进程共享
// 这里通过vmap在内核虚拟地址空间中映射一块page_count个页面的连续空间
memdesc->hostptr = vmap(memdesc->pages, memdesc->page_count,
VM_IOREMAP, page_prot);
// 映射成功:更新内存数据统计
if (memdesc->hostptr)
KGSL_STATS_ADD(memdesc->size,
&kgsl_driver.stats.vmalloc,
&kgsl_driver.stats.vmalloc_max);
else
ret = -ENOMEM;
// 使用此内核虚拟地址的线程数量加1
if (memdesc->hostptr)
memdesc->hostptr_count++;
mutex_unlock(&kernel_map_global_lock);
return ret;
3. kgsl_mmu_map_global
void kgsl_mmu_map_global(struct kgsl_device *device,
struct kgsl_memdesc *memdesc, u32 padding)
struct kgsl_mmu *mmu = &(device->mmu);
// 支持IOMMU: 调用在kgsl_iommu_ops中定义的kgsl_iommu_map_global[见3.1节]
if (MMU_OP_VALID(mmu, mmu_map_global))
mmu->mmu_ops->mmu_map_global(mmu, memdesc, padding);
3.1 kgsl_iommu_map_global
// 32位系统GPU虚拟地址基地址
#define KGSL_IOMMU_GLOBAL_MEM_BASE32 0xf8000000
// 64位系统GPU虚拟地址基地址
#define KGSL_IOMMU_GLOBAL_MEM_BASE64 0xfc000000
#define KGSL_IOMMU_GLOBAL_MEM_BASE(__mmu) \\
(test_bit(KGSL_MMU_64BIT, &(__mmu)->features) ? \\
KGSL_IOMMU_GLOBAL_MEM_BASE64 : KGSL_IOMMU_GLOBAL_MEM_BASE32)
static void kgsl_iommu_map_global(struct kgsl_mmu *mmu,
struct kgsl_memdesc *memdesc, u32 padding)
struct kgsl_device *device = KGSL_MMU_DEVICE(mmu);
struct kgsl_iommu *iommu = _IOMMU_PRIV(mmu);
if (memdesc->flags & KGSL_MEMFLAGS_SECURE)
kgsl_iommu_map_secure_global(mmu, memdesc);
return;
// kgsl_memdesc->gpuaddr用于表示GPU虚拟地址
if (!memdesc->gpuaddr)
u64 offset;
u64 base;
/* Find room for the memdesc plus any padding */
// 根据物理内存大小以及priv标志位(KGSL_MEMDESC_RANDOM:随机地址)计算偏移量
offset = global_get_offset(device, memdesc->size + padding,
memdesc->priv);
if (IS_ERR_VALUE(offset))
return;
if (kgsl_iommu_split_tables_enabled(mmu))
base = KGSL_IOMMU_SPLIT_TABLE_BASE;
else
// 64位GPU虚拟地址基地址 = 0xfc000000
base = KGSL_IOMMU_GLOBAL_MEM_BASE(mmu);
// GPU虚拟地址 = 全局内存基地址 + 偏移量 = 0xfc000000 + 偏移量
memdesc->gpuaddr = base + offset;
/*
* Warn if a global is added after first per-process pagetables have
* been created since we do not go back and retroactively add the
* globals to existing pages
*/
WARN_ON(!kgsl_iommu_split_tables_enabled(mmu) && iommu->ppt_active);
// 将GPU虚拟地址添加到默认页表中[见1.7节]
kgsl_iommu_map_global_to_pt(mmu, memdesc, mmu->defaultpagetable);
kgsl_iommu_map_global_to_pt(mmu, memdesc, mmu->lpac_pagetable);
3.2 kgsl_iommu_map_global_to_pt
static void kgsl_iommu_map_global_to_pt(struct kgsl_mmu *mmu,
struct kgsl_memdesc *memdesc, struct kgsl_pagetable *pt)
/* If the pagetable hasn't been created yet, do nothing */
if (IS_ERR_OR_NULL(pt))
return;
kgsl_mmu_map(pt, memdesc);
3.3 kgsl_mmu_map
int
kgsl_mmu_map(struct kgsl_pagetable *pagetable,
struct kgsl_memdesc *memdesc)
int size;
struct kgsl_device *device = KGSL_MMU_DEVICE(pagetable->mmu);
if (!memdesc->gpuaddr)
return -EINVAL;
/* Only global mappings should be mapped multiple times */
// 只有全局的内存才能够映射多次
if (!kgsl_memdesc_is_global(memdesc) &&
(KGSL_MEMDESC_MAPPED & memdesc->priv))
return -EINVAL;
// 计算该块内存描述符的大小
size = kgsl_memdesc_footprint(memdesc);
if (PT_OP_VALID(pagetable, mmu_map))
int ret;
// 支持IOMMU: 调用在iommu_pt_ops中定义的kgsl_iommu_map将该块内存添加到页表中
ret = pagetable->pt_ops->mmu_map(pagetable, memdesc);
if (ret)
return ret;
// 更新内存数据统计
atomic_inc(&pagetable->stats.entries);
KGSL_STATS_ADD(size, &pagetable->stats.mapped,
&pagetable->stats.max_mapped);
kgsl_mmu_trace_gpu_mem_pagetable(pagetable);
if (!kgsl_memdesc_is_global(memdesc)
&& !(memdesc->flags & KGSL_MEMFLAGS_USERMEM_ION))
kgsl_trace_gpu_mem_total(device, size);
// KGSL_MEMDESC_MAPPED标记该内存描述符已被映射到页表
memdesc->priv |= KGSL_MEMDESC_MAPPED;
return 0;
以上是关于adreno源码系列全局内存申请的主要内容,如果未能解决你的问题,请参考以下文章