HintonDALL-E 2 皆上榜,盘点 AI 图像 10 年合成史!
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HintonDALL-E 2 皆上榜,盘点 AI 图像 10 年合成史!相关的知识,希望对你有一定的参考价值。

整理 | 刘春霖 责编 | 张红月
出品 | CSDN(ID:CSDNnews)
现在,已是2022年底。
深度学习模型在生成图像上的表现已经非常出色。
很显然,未来还会给我们更多的惊喜。
这十年来,是如何走到今天这一步的?
在下面的时间线里,将会追溯一些里程碑式的时刻,例如 AI 图像合成的论文、架构、模型、数据集、实验登场的时候。
一切,都要从十年前的那个人工智能夏天说起。

开端( 2012 年 - 2015 年)
在深度神经网络面世之后,人们则意识到:它将彻底改变图像分类。同时,研究人员开始探索“相反”的方向,“如果使用一些对分类非常有效的技术(例如卷积层)来制作图像,会发生什么?”
2012 年 12 月,“人工智能之夏”诞生的开始。
在这一年,论文《深度卷积神经网络的 ImageNet 分类》发布。论文作者之一,就是 AI 三巨头之一的 Hinton。

这是第一次将深度卷积神经网络 (CNN)、GPU 和巨大的互联网来源数据集(ImageNet)结合在一起。
2014 年 12 月,Ian Goodfellow 等大佬发表了史诗性论文巨作《生成式对抗网络》。

GAN 是第一个致力于图像合成而不是分析的现代(即2012年后)神经网络架构。
它引入了一种基于博弈论的独特学习方法,其中两个子网络“生成器”和“鉴别器”进行竞争。
最终,只有“生成器”从系统中保留下来,并用于图像合成。

Hello World!来自 Goodfellow 等人 2014 年论文的 GAN 生成人脸样本。该模型是 在Toronto Faces 数据集上训练的,该数据集已从网络上删除。
2015 年 11 月,具有重大意义的论文《使用深度卷积生成对抗网络进行无监督代表学习》发表。其中,作者描述了第一个实际可用的 GAN 架构 (DCGAN)。

这篇论文首次提出了潜在空间操纵的问题——概念是否映射到潜在空间方向?

GAN 的五年( 2015 年 - 2020 年)
这五年内 GAN 被应用于各种图像处理任务,例如样式转换、修复、去噪和超分辨率。期间,GAN 架构的论文开始爆炸式井喷。

地址:https://github.com/nightrome/really-awesome-gan
与此同时,GAN 的艺术实验开始兴起,Mike Tyka、Mario Klingenmann、Anna Ridler、Helena Sarin 等人的第一批作品出现。
第一个“AI 艺术”丑闻发生在 2018 年。

在 2018 年 10 月 25 日,Christie's 的一场拍卖会上,正在拍卖 Edmond Belamy 的肖像,这是一副金色框架中的画布,展示了看起来像 18 世纪绅士的污迹人物。当拍卖槌落下时,也将标志着人工智能艺术在世界拍卖舞台上的到来。
同时,Transformer 架构彻底改变了 NLP。在不久的将来,这件事会对图像合成产生重大影响。
2017 年 6 月,《Attention Is All You Need》论文发布。

在《Transformers, Explained: Understand the Model Behind GPT-3, BERT, and T5》中有详实的解释。

自此,Transformer 架构(以BERT等预训练模型的形式)彻底改变了自然语言处理 (NLP) 领域。
2018 年 7 月,《概念性标注:用于自动图像字幕的清理、上位化、图像替代文本数据集》论文发表。

这个和其他多模态数据集对于 CLIP 和 DALL-E 等模型将变得极其重要。

MarioKlingenmann,MemoriesofPasserbyI,2018.Thebaconesquefaces是该地区AI艺术的典型代表,其中生成模型的非写实性是艺术探索的重点
2018-20年,NVIDIA 的研究人员对 GAN 架构进行了一系列彻底改进。在《使用有限数据训练生成对抗网络》论文中,介绍了最新的 StyleGAN2-ada。
GAN 生成的图像首次变得与自然图像无法区分,至少对于像 Flickr-Faces-HQ (FFHQ) 等这样高度优化的数据集来说是这样。
2020 年 5 月,论文《语言模型是小样本学习者》发表。OpenAI 的 LLM Generative Pre-trained Transformer 3(GPT-3)展示了变压器架构的强大功能。
2020 年 12 月,论文《用于高分辨率图像合成的 Taming transformers》发表。ViT 表明,Transformer 架构可用于图像。
论文中介绍的方法 VQGAN 在基准测试中产生了 SOTA 结果。

2010 年代后期的 GAN 架构的质量主要根据对齐的面部图像进行评估,对于更多异构数据集的效果很有限。因此,在学术/工业和艺术实验中,人脸仍然是一个重要的参考点。

Transformer 的时代( 2020 年 - 2022 年)
Transformer 架构的出现,彻底改变了图像合成的历史。从此,图像合成领域开始抛下 GAN。“多模态”深度学习整合了 NLP 和计算机视觉的技术,“即时工程”取代了模型训练和调整,成为图像合成的艺术方法。
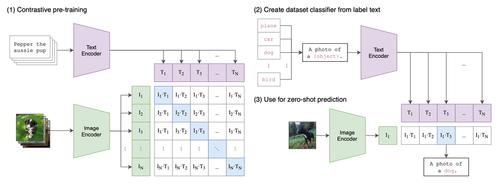
《从自然语言监督中学习可迁移视觉模型》论文中提出了 CLIP 架构。可以说,当前的图像合成热潮,是由 CLIP 首次引入的多模态功能推动的。
2021 年 1 月,论文《零样本文本到图像生成》发表(另请参阅OpenAI 的博客文章),其中介绍了 DALL-E 的第一个版本。

此版本的工作原理是通过将文本和图像(由 VAE 压缩为「TOKEN」)组合在单个数据流中。该模型只是“continues”和“sentence”。数据(250M 图像)包括来自维基百科的文本图像对、概念说明和 YFCM100M 的过滤子集。CLIP 为图像合成的“多模态”方法奠定了基础。
2021 年 1 月,论文《从自然语言监督学习可迁移视觉模型》发表。论文中介绍了 CLIP,这是一种结合了 ViT 和普通 Transformer 的多模态模型。
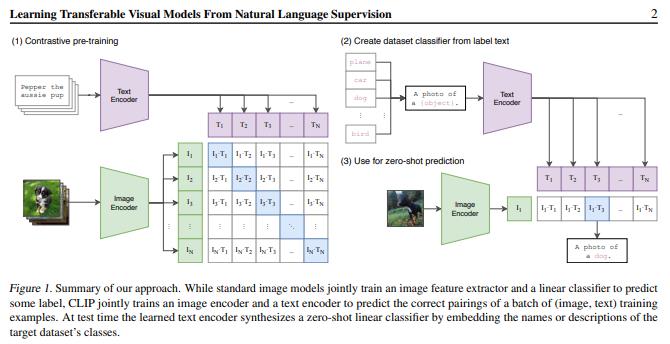
CLIP 会学习图像和标题的“共享潜在空间”,因此可以标记图像。模型在论文附录A.1中列出的大量数据集上进行培训。
2021 年 6 月,论文《扩散模型的发布在图像合成方面击败了 GAN》发表。

扩散模型引入了一种不同于 GAN 方法的图像合成方法。研究者通过从人工添加的噪声(“去噪”)中重建图像来学习。它们与变分自动编码器 (VAE) 相关。

“金发女郎的人像照片,用数码单反相机拍摄,中性背景,高分辨率”,使用 DALL-E 2 生成。基于 Transformer 的生成模型与后来的 GAN 架构(如 StyleGAN 2)的照片级真实感相匹配,但允许创建广泛的各种主题和图案。
2021 年 7 月,DALL-E mini 发布。
 这是 DALL-E 的复制品(体积更小,对架构和数据的调整很少)。数据包括 Conceptual 12M、Conceptual Captions 以及 OpenAI 用于原始 DALL-E 模型的 YFCM100M 相同过滤子集。因为没有任何内容过滤器或 API 限制,DALL-E mini 为创造性探索提供了巨大的潜力,并导致推特上“奇怪的 DALL-E”图像呈爆炸式增长。
这是 DALL-E 的复制品(体积更小,对架构和数据的调整很少)。数据包括 Conceptual 12M、Conceptual Captions 以及 OpenAI 用于原始 DALL-E 模型的 YFCM100M 相同过滤子集。因为没有任何内容过滤器或 API 限制,DALL-E mini 为创造性探索提供了巨大的潜力,并导致推特上“奇怪的 DALL-E”图像呈爆炸式增长。
2021-2022 年,Katherine Crowson 发布了一系列 CoLab 笔记,探索制作 CLIP 引导生成模型的方法。例如 512x512 CLIP-guided diffusion 和 VQGAN-CLIP(Open domain image generation and editing with natural language guidance,仅在 2022 年作为预印本发布,但 VQGAN 发布后就出现了公共实验)。
就像在早期的 GAN 时代一样,艺术家和开发者以非常有限的手段对现有架构进行重大改进,然后由公司简化,最后由 wombo.ai 等“初创公司”商业化。
2022 年 4 月,论文《具有 CLIP 潜能的分层文本条件图像生成》发表。本论文介绍了 DALL-E 2,它建立在仅几周前发布的 GLIDE 论文(《 GLIDE:使用文本引导扩散模型实现逼真图像生成和编辑》的基础上。
同时,由于DALL-E2的访问受限和有意限制,人们对DALL-Emini重新产生了兴趣。
根据模型卡,数据由“公开可用资源和我们许可的资源的组合”组成,以及根据该论文的完整 CLIP 和 DALL-E 数据集。
2022 年 5-6 月,5 月发布论文《具有深度语言理解的真实感文本到图像扩散模型》。

6 月论文《用于内容丰富的文本到图像生成的缩放自回归模型》发表。

这两篇论文中介绍了 Imagegen 和Parti ,以及谷歌对 DALL-E 2 的回答。

“你知道我今天为什么阻止你吗?” 由DALL-E 2 生成,“prompt engineering”从此成为艺术图像合成的主要方法。

AI Photoshop( 2022 年至今)
虽然 DALL-E 2 为图像模型设定了新标准,但它迅速商业化,也意味着在使用上从一开始就受到限制。用户仍继续尝试 DALL-E mini 等较小的模型。
随着 Stable Diffusion 的发布,所有这一切都发生了变化。这可以说,Stable Diffusion 标志着图像合成“Photoshop时代”的开始。

“有四串葡萄的静物,试图创造出像古代画家 Zeuxis Juan El Labrador Fernandez,1636 年,马德里普拉多的葡萄一样栩栩如生的葡萄”,Stable Diffusion 产生的六种变化。
2022 年 8 月,Stability.ai 发布了 Stable Diffusion 模型。在论文《具有潜在扩散模型的高分辨率图像合成》中,Stability.ai 隆重推出了 Stable Diffusion,这个模型可以实现与 DALL-E 2 同等的照片级真实感。

除了 DALL-E 2,该模型几乎可以立即向公众开放,并且可以在 CoLab 和 Huggingface 平台上运行。
2022 年 8 月,谷歌发表论文《DreamBooth:为主题驱动生成微调文本到图像扩散模型》。DreamBooth 提供了对扩散模型越来越细粒度的控制。

然而,即使没有这些额外的技术干预,使用像 Photoshop 这样的生成模型也变得可行,从粗略的草图开始,逐层添加生成的修改。
2022 年 10 月,最大的图库公司之一 Shutterstock 宣布与 OpenAI 合作提供/许可生成图像,预计图库市场将受到 Stable Diffusion 等生成模型的严重影响。
参考链接:
https://zentralwerkstatt.org/blog/ten-years-of-image-synthesis

以上是关于HintonDALL-E 2 皆上榜,盘点 AI 图像 10 年合成史!的主要内容,如果未能解决你的问题,请参考以下文章
2019 深度学习框架大盘点!看 PyTorchTensorFlow 如何强势上榜?
盘点NBA三分球最准组合,水花齐上榜,这套阵容能拿总冠军么?