RepGhost:一个通过重新参数化实现硬件高效的Ghost模块
Posted AI浩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RepGhost:一个通过重新参数化实现硬件高效的Ghost模块相关的知识,希望对你有一定的参考价值。
文章目录
摘要
特征重用一直是轻量级卷积神经网络设计的关键技术。目前的方法通常使用连接运算符,通过重用来自其他层的特征映射来廉价地保持大的通道数量(从而获得大的网络容量)。尽管级联是无参数和flops的,但它在硬件设备上的计算成本是不可忽略的。针对这一问题,本文提出了一种利用结构再参数化技术实现特征重用的新视角。提出了一种新的硬件高效的RepGhost模块,通过重新参数化来实现隐式特征重用,而不是使用连接运算符。在RepGhost模块的基础上,开发了高效的RepGhost瓶颈和RepGhostNet。在ImageNet和COCO基准测试上的实验表明,所提出的RepGhostNet在移动设备上比GhostNet和MobileNetV3更有效。特别是,在基于arm的手机上,我们的RepGhostNet以较少的参数和相当的延迟,在ImageNet数据集上Top-1精度相比GhostNet 0.5X模型 提高了2.5%。代码可从https://github.com/ChengpengChen/RepGhost获得。
1、简介
随着移动和便携设备的普及,由于计算资源有限,高效的卷积神经网络(CNNs)变得不可或缺。为了达到提高cnn效率的目的,近年来提出了不同的方法,如轻量化架构设计[3,14,20,31,35,48]、神经架构搜索[13,27,38,44]、修剪[2,18,30,32]等,并取得了很大进展。
在体系结构设计领域,信道数量多往往意味着网络容量大[17,23,24],特别是对于轻量CNNs[14,19,31,35]。正如[31]中所述,给定固定的FLOPs,轻量级cnn更倾向于使用空闲连接(例如,组或深度卷积)和特性重用。这两者都得到了很好的研究,近年来提出了许多具有代表性的轻量cnn[5,14,15,19,20,31,35,47,48]。备用连接的目的是通过低浮点操作(flop)来保持大的网络容量,而特征重用的目的是通过简单地连接来自不同层的现有特征映射来显式地保持大量的通道(从而保持大的网络容量)[14,23,24,37]。例如,在DenseNet[24]中,在一个阶段中重用前一层的特征映射并将其发送到后续层,从而导致越来越多的通道。GhostNet[14,15]提出通过廉价的操作生成更多的特征图,并将其与原有的特征图连接,以保留大量通道。ShuffleNetV2[31]只处理一半的通道,保留另一半通道进行连接。它们都通过连接操作利用特性重用来扩大通道数量和网络容量,同时保持较低的flop。连接似乎已经成为特性重用的一种标准和优雅的操作。
连接是不受参数和FLOPs影响的,然而,它在硬件设备上的计算成本是不可忽略的,因为参数和FLOPs并不是机器学习模型实际运行时性能的直接成本指标[8,31]。为了验证这一点,我们在3.1节提供了详细的分析。我们发现,在硬件设备上,连接操作由于其复杂的内存拷贝,比添加操作效率要低得多。因此,在连接操作之外,探索一种更好的、硬件效率更高的特性重用方法是值得关注的。
近年来,结构再参数化在CNNs体系结构设计中的有效性得到了验证,包括direcnet[46]、ExpandNets[12]、ACNet[10]、RepVGG[11]等。该方法可以将复杂的训练时间结构转化为权空间中等价的更简单的推理时间结构,且不需要任何时间成本。受此启发,我们提出利用结构的再参数化,而不是广泛使用的连接,来实现特征的隐式重用,以实现硬件高效的架构设计。
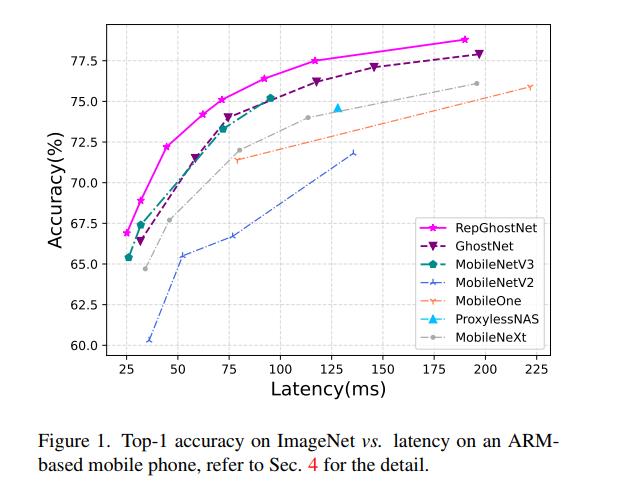
本文通过结构重新参数化,提出了一个硬件高效的RepGhost模块,实现了特征的隐式重用。注意,这不仅仅是将重参数化技术应用到Ghost模块中的现有层,而是为了改进模块以便更快地推断。具体来说,我们首先去掉了低效的拼接运算符,然后修改体系结构以满足结构重新参数化的规则。因此,在推断之前,特征重用过程可以从特征空间转移到权重空间,使我们的模块高效。最后,基于RepGhost模块,我们开发了一种硬件高效的cnn,称为RepGhostNet,它在精度-延迟权衡方面优于现有最先进的轻量级cnn,如图1所示。我们的贡献摘要如下:
-
说明了在硬件高效架构设计中,特征重用并非无成本且不可或缺的拼接操作,并提出了通过结构再参数化技术实现特征重用的新视角。
-
我们提出了一个具有隐式特性重用的新颖RepGhost模块,并开发了一个比GhostNet[14]和MobileNetV3[19]更有效的硬件RepGhostNet。
-
我们表明,与之前最先进的轻量级cnn相比,我们的RepGhostNet可以在多个视觉任务中实现更好的性能,并具有更低的移动延迟。
2、 相关工作
2.1. 轻量 CNNs
无论是人工设计的[3,20,35,47,48],还是基于神经结构搜索(NAS)[7,13,22,42,44]的轻型cnn,其设计目的都是为了获得更少参数和更低flop的竞争性能。其中,ShuffleNetV1[47]和MobileNetV2[35]通过使用大量的深度卷积而不是密集的卷积来建立基准。FBNet[42,44]采用复杂NAS技术自动设计轻量级架构。然而,参数和flop往往不能反映轻量级cnn的实际运行时性能(即:延迟)[8,31]。很少有模型是直接为低延迟设计的,如ProxylessNAS[27]、MNASNet[38]、MobileNetV3[19]和ShuffleNetV2[31]。本文以此为基础,设计了高效、低时延的cnn。
另一方面,cnn中的特征重用也激发了许多令人印象深刻的作品[14,15,23,24,31,37,45],这些作品成本低廉甚至免费。GhostNet[14]作为轻量CNNs,使用廉价的操作,以较低的计算成本产生更多的信道,ShuffleNetV2[31]只处理一半的特征信道,保留另一半进行连接。它们都使用连接操作来保持大的通道数,因为它是参数和flops自由的。但我们注意到,由于其复杂的内存复制过程,它在移动设备上的效率很低,这使得它在轻量级cnn的特性重用中不是不可或缺的。因此,在本文中,我们探索在轻量级cnn架构设计中利用特征重用,而不仅仅是串接操作。
2.2.重参数结构
结构重新参数化通常是将训练时表达能力更强、更复杂的体系结构转换为更简单的体系结构,以便快速推断。ExpandNets[12]在训练过程中将模型中的线性层重新参数化为几个连续的线性层。ACNet[10]和RepVGG[11]将单个卷积层分解为训练时多分支块。例如,RepVGG中的一个这样的训练时间块包含三个并行层,即:3x3卷积、1x1卷积和标识映射,以及一个add操作符来融合它们的输出特征。在推理过程中,融合过程可以从特征空间移动到权重空间,从而得到一个简单的推理块(只有一个3x3卷积)[11]。这促使我们使用该技术设计具有高效推理体系结构的轻量级cnn。
最近,MobileOne[41]还采用了结构重新参数化技术,为iPhone12中功能强大的NPU设计了具有大FLOPs的移动骨干,去除快捷键(或跳过连接)。然而,在本文中,我们注意到,在极其轻量级的cnn中,这种捷径是必要的,而且不会带来太多的时间成本(见第4.3节)。我们利用重参数化技术,替代了Ghost模块中低效的拼接运算符,隐式实现了特征重用,使我们的RepGhostNet在计算受限的移动设备上更加高效。
3.方法
在本节中,我们将首先回顾用于特征重用的连接操作,并介绍如何利用结构重新参数化来实现这一点。在此基础上,提出了一种用于隐式特征重用的新参数化模块RepGhost。在此之后,我们描述了在此模块上构建的硬件高效网络,称为RepGhostNet。
3.1. 通过重新参数化的特性重用
特征重用技术已广泛应用于CNNs中以扩大网络容量,如DenseNet[24]、ShuffleNetV2[31]和GhostNet[14]。大多数方法利用连接算子组合来自不同层的特征映射,以更低的成本产生更多的特征。连接是不受参数和flops影响的,但是由于硬件设备上复杂的内存拷贝,它的计算成本是不可忽略的。为了解决这个问题,我们提供了一种隐式实现特征重用的新视角:通过结构重新参数化实现特征重用。
连接成本。如上所述,串联的内存拷贝给硬件设备带来不可忽略的计算成本。例如,设 M 1 ∈ R N × C 1 × H × W M_1 \\in \\mathbbR^N \\times C_1 \\times H \\times W M1∈RN×C1×H×W和 M 2 ∈ R N × C 2 × H × W M_2 \\in \\mathbbR^N \\times C_2 \\times H \\times W M2∈RN×C2×H×W为数据布局NCHW 1中单独连接通道维的两个特征映射。在处理M1和M2时所需的最大连续内存块分别是 b 1 ∈ R 1 × C 1 × H × W b_1 \\in \\mathbbR^1 \\times C_1 \\times H \\times W b1∈R1×C1×H×W和 b 2 ∈ R 1 × C 2 × H × W b_2 \\in \\mathbbR^1 \\times C_2 \\times H \\times W b2∈R1×C2×H×W。连接b1和b2是直接的,这个过程会重复N次。对于布局NHWC[1]中的数据,最大的连续内存块要小得多,即 b 1 ∈ R 1 × 1 × 1 × C 1 b_1 \\in \\mathbbR^1 \\times 1 \\times 1 \\times C_1 b1∈R1×1×1×C1,这使得复制过程更加复杂。而对于像Add这样的元素操作符,最大的连续内存块是M1和M2本身,这使得操作更加容易。
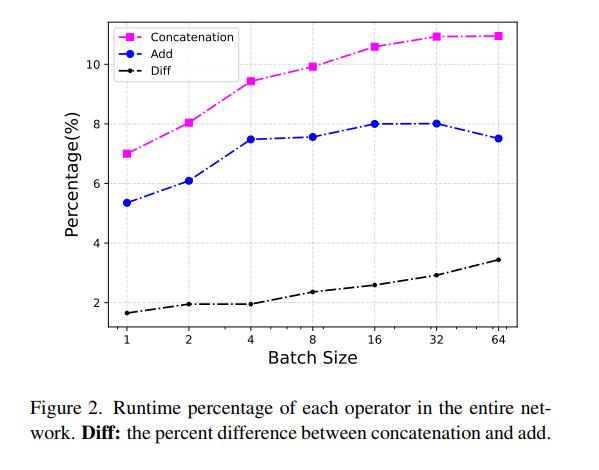
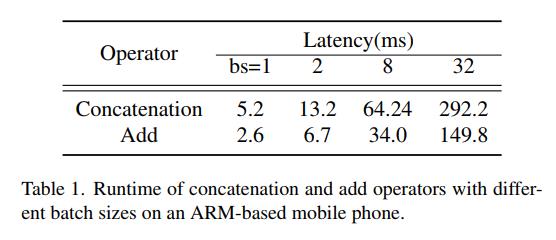
为了定量地评估连接操作,我们分析了它在移动设备上的实际运行时。我们以GhostNet 1.0x[14]为例,将其所有的拼接操作符替换为添加操作符进行比较,这也是一种处理不同特征的简单操作符,成本较低[17,36]。注意这两个算符作用于形状完全相同的张量上。表1给出了对应网络中所有32个对应算子的累计运行时间。连接成本是添加的2倍。我们还在图2中绘制了不同批次大小下的时间百分比。随着批处理大小的增加,concatation和add之间的runtime百分比差距越大,这与我们的数据布局分析是一致的。
重新参数化vs.连接 设
y
∈
R
N
×
C
out
×
H
×
W
y \\in \\mathbbR^N \\times C_\\text out \\times H \\times W
y∈RN×Cout ×H×W表示带有
C
o
u
t
C_out
Cout通道的输出,
x
∈
R
N
×
C
i
n
×
H
×
W
x \\in \\mathbbR^N \\times C_i n \\times H \\times W
x∈RN×Cin×H×W表示要处理和重用的输入。
Φ
i
(
x
)
,
∀
i
=
1
,
…
,
s
−
1
\\Phi_i(x), \\forall i=1, \\ldots, s-1
Φi(x),∀i=1,…,s−1表示应用于x的其他神经网络层,如卷积或BN。在不丧失一般性的情况下,通过拼接的特征重用可以表示为:
y
=
Cat
(
[
x
,
Φ
1
(
x
)
,
…
,
Φ
s
−
1
(
x
)
]
)
y=\\operatornameCat\\left(\\left[x, \\Phi_1(x), \\ldots, \\Phi_s-1(x)\\right]\\right)
y=Cat([x,Φ1(x),…,Φs−1(x)])
其中Cat是拼接操作。它只保留现有的特征映射,将信息处理留给其他操作员。例如,在连接层之后通常会有一个1×1密集卷积层来处理信道信息[14,24,37]。然而,如表1所示,对于硬件设备上的特性重用,连接并不是没有成本的,这促使我们寻找一种更有效的方法。
近年来,结构重新参数化被视为一种无成本的技术来提高cnn的性能[10,11,41]。受此启发,我们注意到结构重新参数化也可以被视为隐式特征重用的一种有效技术,从而设计出更高效的硬件cnn。例如,结构重参数化通常在训练过程中利用多个线性算子生成不同的特征映射,并通过参数融合将所有算子融合为一个,实现快速推理。也就是说,它将融合过程从特征空间转移到权重空间,这可以被视为特征重用的一种隐式方式。根据等式1中的符号,通过结构重新参数化的特征重用可表示为:
y
=
Add
(
[
x
,
Φ
1
(
x
)
,
…
,
Φ
s
−
1
(
x
)
]
)
=
Φ
∗
(
x
)
y=\\operatornameAdd\\left(\\left[x, \\Phi_1(x), \\ldots, \\Phi_s-1(x)\\right]\\right)=\\Phi^*(x)
y=Add([x,Φ1(x),…,Φs−1(x)])=Φ∗(x)
与拼接不同,添加还具有特征融合的作用。所有操作 Φ i ( x ) , ∀ i = 1 , … , s − 1 \\Phi_i(x), \\forall i=1, \\ldots, s-1 Φi(x),∀i=1,…,s−1结构再参数化的S−1为线性函数,最终融合为 Φ ∗ ( x ) \\Phi * (x) Φ∗(x)。特征融合过程是在权值空间中完成的,不会引入额外的推理时间,使得最终的体系结构比拼接更高效。如图2所示,通过结构重新参数化实现特征重用比连接节省7% ~ 11%的时间,增加5% ~ 8%的时间。基于这一概念,我们在下一小节中提出了一个硬件高效的RepGhost模块,通过结构重新参数化实现特征重用。
3.2. RepGhost模块
为了通过重新参数化来利用特性重用,本小节将介绍Ghost模块如何演变为RepGhost模块。由于连接运算符的存在,直接对原始Ghost模块进行重参数化并非易事。为了派生RepGhost模块,我们做了一些调整。如图3所示,我们从图3a的Ghost模块开始,逐步调整内部组件。
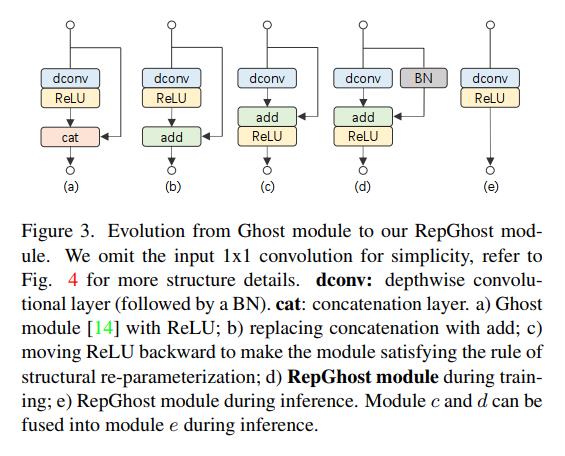
添加操作。 由于3.1节讨论的拼接对特征重用的效率不高,我们首先用添加算子[17,36]替换拼接算子,得到图3b中的模块b。它应该提供如表1和图2所示的更高的效率。
向后移动ReLU。 本着结构重新参数化的精神[10,11],我们将深度卷积层后的ReLU在添加算子后向后移动,即i:e:,如图3c所示模块c。这种移动使模块满足结构再参数化规则[10,11],从而可以融合到模块e中进行快速推理。将ReLU向后移动的效果将在第4.3节讨论。
Re-parameterization。 c模块作为一个重参数化模块,在重参数化结构上比恒等映射更灵活[10,41]。如图3d所示的d模块,我们简单地在identity分支中加入了Batch Normalization(BN)[25],这在训练过程中带来了非线性,可以融合快速推理。这个模块被标记为我们的RepGhost模块。我们还将在第4.3节探讨其他的重新参数化结构。
快速推理。 模块c和模块d作为重新参数化的模块,可以融合到图3e中的模块e中进行快速推断。我们的RepGhost模块有一个简单的推理结构,只包含规则的卷积层和ReLU,使其硬件高效[11]。具体来说,特征融合过程是在权重空间中进行的,而不是在特征空间中,即每个分支的融合参数,并产生一个简化的结构,以快速推断,这是无成本的。由于每个算子的线性性,参数融合过程是直接的(详见[10,11])。
与Ghost模块的比较。 GhostNet[14]提出通过低成本的操作生成更多的特征图,从而以低成本的方式扩大网络容量。在RepGhost模块中,我们进一步提出了一种更有效的方法,通过重参数化来生成和融合不同的特征映射。与Ghost模块不同的是,RepGhost模块去掉了低效的拼接运算符,节省了大量的推理时间。信息融合过程由隐式添加算子执行,而不依赖于其他卷积层。
在GhostNet[14]中,Ghost模块有一个比率s来控制复杂度。根据等式1, C in = 1 s ∗ C out C_\\text in =\\frac1s * C_\\text out Cin =s1∗Cout 和其余 s − 1 s ∗ C out \\fracs-1s * C_\\text out ss−1∗Cout 通道由深度卷积 Φ i , ∀ i = 1 , … , s − 1 \\Phi_i, \\forall i=1, \\ldots, s-1 Φi,∀i=1,…,s−1产生。而RepGhost的最终输出 C o u t C_out Cout等于 C i n C_in Cin。RepGhost模块在训练过程中产生 s ∗ C i n s * C_in s∗Cin通道,并将它们
以上是关于RepGhost:一个通过重新参数化实现硬件高效的Ghost模块的主要内容,如果未能解决你的问题,请参考以下文章