CSAPP-Revision-ch03
Posted 用七年单身换个PolyU.CSPhD
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CSAPP-Revision-ch03相关的知识,希望对你有一定的参考价值。
程序的机器级表示
上来就是chapter3属实是有点刚。
主要这门课也是6.30就考,感觉OS应该会较简单,多复习一下这个先。
先来张图心里有个13数。

因为老师留下了两份作业,所以会采取复习到哪对应到作业上写题的方式。
一次性当然也复习不完,好运!
## 程序转换概述
这个不是重点,就略微讲一哈……
下面是一张汇编/机器代码视图:

CPU是我们的核心处理器,我们需要去内存中寻址。数据可以在寄存器和内存中进行“流动”。内存需要把指令交由CPU来进行处理。
其中PC,代表的是程序计数器,x86-64中用%RIP来表示下一条指令的位置。
讲到“指令”,就会提到指令集架构ISA(instruction set architecture)。
它可以定义机器级程序的格式和行为。x86-64就是比较经典的ISA
【我们CSAPP重点教学的】,当然了还有什么MIPS等。
由于不是重点内容,这里直接附上ppt内容:

我们的程序从.c文件一步步转换到可执行文件的流程如下:

在Windows操作系统中,我们下载VS或者VS Code,(即使是Visual C++也就点三下……)点一下就全部完成了跳出一个黑黑的“Console”进行相应输入、计算结果然后打印。
在Linux下我们就要用到一个强大的GCC编译器,配合不同选项生成不同文件。
当然,绝大多数人用的最多的应该还是配合“-o”选项生成可执行文件,跑结果。
那,这一章讲的是汇编呀,汇编代码才是重头。
也就是我们上图中的“.s”文件,配合“-S”选项即可。
可以看见前面还有一个什么“Modified xxx”的,这个就是编译器最先做的处理。比如会把你注释删掉……
我们可以配合“-E”选项生成.i文件。
我们也可以配合“-c”选项生成.o文件。
最后链接器部分会放到ch07,链接,专门来讲。
我们有-Og来表示常规优化,-O1和-O2等都是高级别的优化。优化程度太高可能会使得编译器误读你的意思,所以要选适中的。
我们的GCC还有一个强大的功能就是反汇编,利用objdump工具。
没被bomb实验支配过,就等于没学过CSAPP?
可以对.o或者可执行文件执行 objdump -d file,就能获得汇编代码。
上面提到过指令,一条x86-64的指令长啥样子?

就像上面这样,包含了操作符(movq),源操作数和目的操作数。
mov很好理解,就是移动呗,源是rax寄存器,目的是rbx寄存器存储的地址对应到内存,那么就是把一个数移到一个内存地址中去而已。
至于q,是有渊源的一个后缀表示。
我们称一个字后缀为“w”, = 2Byte。 【可以理解为 word】
1Byte的后缀我们就用“b”。 【就是 byte】
双字,用后缀“l” = 4Byte。
四字,用后缀“q” = 8Byte。 【可以理解为 quodra】
C语言中比较神奇的两个,float,单精度浮点数,4Byte,但后缀为“s”。
double,双精度浮点数,8Byte,但后缀为“l”。
## 指令系统
这里内容比较多,但实际上困难度不高,主要在于要理解掌握,会做题!!
先通过一张图来认识我们x86-64指令集结构的寄存器:

上图中要记住的有栈指针rsp,还有参数调用的寄存器,rdi、rsi、rdx、rcx、r8、r9。rax用于函数的返回值。没那么难记哈。
ppt后面开始讲得有些杂,东一口西一下的,我就按书上的来吧。
一开始教的就是寻址!
寻址当然很重要啦,要不然内存里的数怎么取出来嘞?
我们只需要学,最难的 ,最通用的寻址方式即可。
就是下图里的“基址加比例变址加位移”的寻址方式。
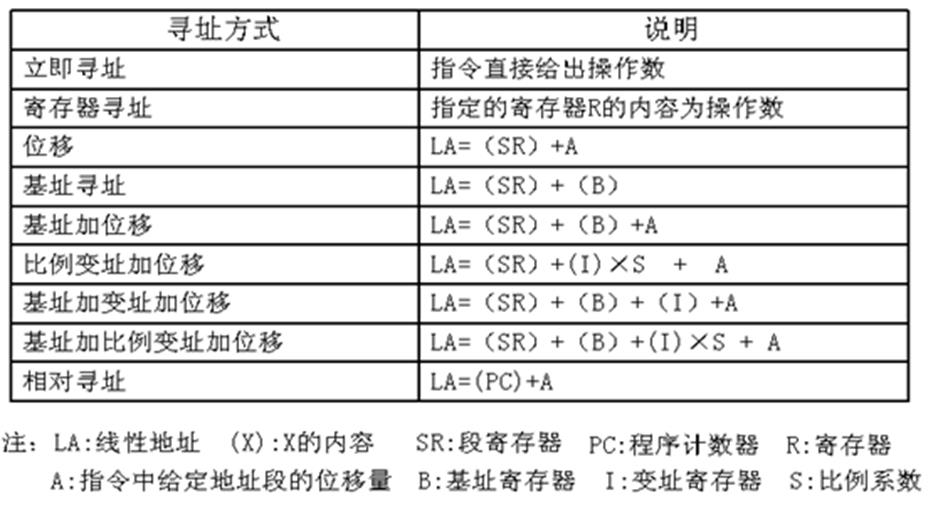
结合下面的提示应该不难理解。
A应该代表的是就是一个立即数【代表的就是一种偏移类型,就是位移】。
B可以设想为一个数组的首地址【代表的是一种偏移类型,是基质寻址】。
比例因子项你可以设想你是去一个数组里做偏移。
假如数组首地址存在B中,是一个double数组,你要去第二个,那么寻址中你要做的就是 B + sizeof(double) * 2才能正确找到他!
SR应该就是当前的地址呗。
寻址涉及的汇编指令就是我们的lea,直接就看这个最复杂的,如:

lea就是操作码,代表就是我们执行的是寻址操作。
edx就是基址,eax就是变址,1作为立即数就是比例因子。
后面的eax代表了我们将前面算出的有效地址放入到eax中。
所以最后eax包含的地址值就是:
eax <- edx + eax。
这个式子并不好,让我们看不到立即数位移的存在。
比如看这个:【rdx寄存器的数值为0xf000已知】

这个首先帮助我们知道,立即数这玩意儿写在括号前头哈。
还有就是我们的基址可以不写,但千万别忘了“,”,计算方式就按上图所示哈。不管基址就完事儿了。
下面的二进制对应的是就是8d 04 02这一条操作指令。
lea指令除了寻址,还可以用于基础的加法和乘法运算。只要你某个寄存器里是个立即数,你按照lea语法格式进行操作,不就是对那个立即数进行加法和乘法的操作吗?所以适当的时候可以不用mul乘法指令的。
寻址讲到这里就结束了,可以看一道题:

显然前两条指令要求我们寻到地址,最后要求我们将此地址的数进行转存。
还记得数据结构里的广义表怎么为二维数组寻址么??
B[i][j] = B[0][0] + (i * 5 + j) * sizeof(int)
还有一点要注意的是movl中第一个源操作数带了括号,这代表了这里包含了一个去内存地址取数的过程,同时是三个空!
那么合适的分配如下:
第一个算出5 × i
第二个另rax自身变为,5 × i + j
最后基址 + rax × 4即可。所以自己填的样子如下:
leaq ( %rsi ,%rsi, 4),%rax -》 rax = 5 × i
leaq ( %rax, %rdx, 1),%rax -》 rax = j + 5 × i
movl ( %rdi, %rax, 4),%eax -》 eax =*(B[0][0] + 4 * (j + 5 * i)) = B[i][j]
刚刚的mov可能还是囫囵吞枣,现在就着重来看看它。
数据传送指令。
MOV的传送方向千万别搞反:
MOV Source Destination : ->> Source to Destination
mov后面可以跟上我们前边讲的不同后缀来表示数据的大小。
我觉得这个指令老师的ppt做的好,简单易懂!

mov指令设计的操作数类型:
立即数,寄存器数,内存里的数。
注意看上图,内存数有一个特点就是带了括号可以从翻译成的c语言看出:
相当于一个指针,即寄存器存储的是一个地址,此地址映射到的内存位置才是我们要操作的真正的位置。
同时我们会发现一条规则,不允许将数从内存直接转到内存!
这里还有一个惯例性的条例,利用movl传送双字且以寄存器为目的地址时会将目的寄存器的高4Byte置为0。其他情况均只管传输部分,其余部分不会管。
还有值得注意一点的是movq虽说是移动四字8Byte,但实际上只能表示32bit补码的数字,后续进行符号位扩展到64bit。如果想应用真正的64bit的立即数,可以使用指令 movabsq,规则一样。
我们在数据传送时会发生的一种情况就是将一个较小的源数放到了一个比他大的寄存器中。这种情况下我们有两类指令:
MOVZ 和 MOVS分别进行0扩展和符号位扩展。
两类指令后面都会跟上两个字母,分别代表后缀。
比如“bw”,表示字节->字,以此类推。
数据传输指令的内存数也可以有立即数的偏移哦。

那么好了,数据传输指令到这儿也结束了。可以说非常简单!
看一个比较典型的例子吧(没有纯mov的题,太容易)。
第一条指令:将rdi映射到的内存所存的数给到rax,显然rax = 123。
第二条指令:类似的操作,会令rdx = 456。
然后将456放回到0x120内存段位置,将123放到0x100内存段位置。
显然,进行了一次swap操作!

为了做下一个题目,先来看一些简单的逻辑和算术运算指令。
老师的表做的好,还是抄他的:


应该是挺简单的,可以直接综合题目来看:

**这里要牢记一开始寄存器块就讲的东西“rdi rsi”分别是传参的两个寄存器!**
第一条指令做的就是数据搬移:
**%edx = %edi(%rdi的32bit寄存器) = i**
因此看第二条shl,做的实际就是:
**%edx = %edx << 2 = 4 × %edx = 4i**
add指令,进行的操作就是,%esi就是%rsi的32bit版本:
**%edx = %edx + %esi = 4i + j**
然后另eax保存 j。
再次调用shll,产生如下结果:
**%eax = j << 2 = 4 × j = 4j**
再次进行add,结果如下:
**%edi = 4j + i **
所以最后的情况:
Q[i][j] = *(Q[0][0] + 4 * (4 * j + i))
P[i][j] = *(P[0][0] + 4 * (4 * i + j))
**因此很显然,N = M = 4。**
算术和逻辑运算的话,我觉得就是也是操作数含义不要搞错。比如得到的结果你保存进了源,就错了,其实都是进行相应的操作保存在目的,即后面那个数里。
还有就是减法别搞错吧,减法也是“ 目的 - 源 ”保存进目的。
总结一下规律:
后面的数 操作符 前面的数 -》 后面的数 即可。
移位操作中需要注意的是右移操作,其算术和逻辑形式是不同的。
SAR,算术右移,高位会补上符号位。
SHR,逻辑右移,高位直接补0。
乘法除法操作涉及到了一些比较麻烦的点。
如64位乘以64位的操作,最后会得到128位的答案。128位我们就称为8字,显然得64位的机器没法支持我们直接存放。
最后的操作方式我们是通过“单操作数”乘法指令进行的。
我们将一个64位的数作为源操作数,另一个数必须得存放在%rax中。两者得到的结果就是128位的结果,高64位会放在%rdx中,低64位会放在%rax中。
值得注意的是,这条“单操作数”指令的imul和前面表中“imul双操作数”指令是一致的。但只要汇编器会根据指令自动进行辨别。
还有就是除法了。除法我们也是“单操作数”,指令为“idiv<有符号>”,
“div<无符号>”。
寄存器%rdx为高64位,%rax为低64位,这么一个128位数就是我们的被除数。除数就是我们指令的“操作数”。除法的结果会将商存于%rax中,余数存放于%rdx中。
控制结构
说的高深了点,其实就是比比大小……
常用的比较指令,CMP、TEST系列的指令。
图示:

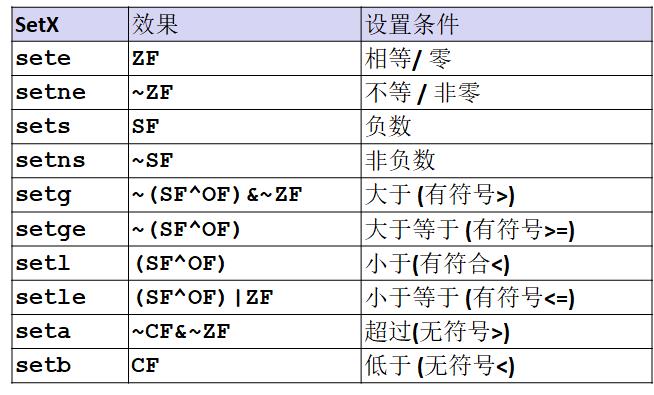
比较完我们需要访问条件码,用到SET系列指令:
栈操作
指令也很简单,就是push和pop。
为什么需要栈呢?因为我们要保存一些信息,我们会在栈帧结构着重讲。 比如,传参寄存器不够用时,就可以先保存进栈中……
又是那句俗话,栈是“后进先出”的一种数据结构。push代表进栈,pop代表出栈。两条指令都只要单操作数,push的操作数代表数据源,pop的操作数代表数据目的。
pushq代表压入一个4字数据,那么首先我们会先把栈顶指针减去8,然后再将数据传输到栈指针位置。
其实就是先空出8Byte,然后把8Byte的数据写入。
popq刚好就是反过来的操作,先把当前栈指针%rsp的8Byte内容读出来。读出来之后这8Byte的空间就没用了,我们把栈指针加上8,就相当于覆盖了这块内容。
以上是关于CSAPP-Revision-ch03的主要内容,如果未能解决你的问题,请参考以下文章