2021年下半年软件设计师上午真题答案及解析
Posted Zhang Jun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021年下半年软件设计师上午真题答案及解析相关的知识,希望对你有一定的参考价值。
41、采用三级模式结构的数据库系统中,如果对一个表创建聚簇索引,那么改变的是数据库的( )。
A、外模式
B、模式
C、内模式
D、用户模式
参考答案:C
答案解析:
对于三级模式,分为外模式,模式和内模式。
- 其中外模式对应视图级别,是用户与数据库系统的接口,是用户用到那部分数据的描述,比如说:用户视图;
- 对于模式而言,又叫概念模式,对于表级,是数据库中全部数据的逻辑结构和特质的描述,由若干个概念记录类型组成,只涉及类型的描述,不涉及具体的值;
- 而对于内模式而言,又叫存储模式,对应文件级,是数据物理结构和存储方式的描述,是数据在数据库内部表示的表示方法,定义所有内部的记录类型,索引和文件的组织方式,以及数据控制方面的细节。例如:B树结构存储,Hash方法存储,聚簇索引等等。
42、设关系模式R(U,F), U=A1,A2,A3,A4,函数依赖集F=A1→A2, A1→A3,A2→A4,关系R的候选码是(1)。下列结论错误的是(2)。
(1)
A、A1
B、A2
C、A1A2
D、A1A3
(2)
A、A1→A2A3为F所蕴涵
B、A1→A4为F所蕴涵
C、A1A2→A4为F所蕴涵
D、A2→A3为F所蕴涵
参考答案:A、D
答案解析:
本题考查候选键的求法和函数依赖的判断问题。
-
第一问求候选键,采用图示法,
能够遍历所有属性的即为候选键,首先应该找出入度为0的节点,只有A1,如果入度为0的节点,遍历不了所有节点,那么需要加入一些中间结点(既有入度又有出度)的结点进行遍历,以它们的组合键作为候选键。
根据方法,找到入度为0的节点A1,可以发现第一步能够通过A1决定所有属性A2(A1→A2),A3(A1→A3),A4(A1→A2,A2→A4,传递律得A1→A4)
得出A1为候选键。 -
第二问考查AmStrong公理进行求解相关:
A.A1→A2A3为F所蕴涵,通过A1→A2,A1→A3,得出A1→A2A3(合并规则)
B.A1- > A4为F所蕴涵,通过A1→A2,A2→A4,得出A1→A4(传递律)
C.A1A2→A4为F所蕴涵,通过A2→A4,A1→A4(传递律),那么两者的结合键为A1A2→A4自然能被F所蕴涵。
D.A2→A3为F所蕴涵,不能推导得出。
43、给定学生关系S(学号,姓名,学院名,电话,家庭住址)、课程关系C(课程号,课程名,选修课程号)、选课关系SC(学号,课程号,成绩)。查询“张晋”选修了“市场营销”课程的学号、学生名、学院名、成绩的关系代数表达式为: π1,2,3,7(π1,2,3(1) )∞(2) ))。
(1)
A、σ2=张晋(S)
B、σ2=‘张晋’(S)
C、o2=张晋(SC)
D、o2=‘张晋’(SC)
(2)
A、π2,3(σ2='市场营销’©)∞SC
B、π2,3(σ2=市场营销(SC))∞C
C、π1,2(σ2='市场营销’©∞SC
D、π1,2(σ2=市场营销(SC))∞C
参考答案:B、A
答案解析:
本题考查数据关系代数相关问题。
根据题干要求,查询“张晋”选修了“市场营销”课程的学号、学生名、学院名、成绩的关系代数表达式
给出以下三个关系表:
学生关系S(学号,姓名,学院名,电话,家庭住址)
课程关系C(课程号,课程名,选修课程号)
选课关系SC(学号,课程号,成绩)
根据题干的描述和选项的结合来看,这个表达式应该是由C和SC先进行自然连接,然后S再与 C和SC先自然连接后的关系再进行自然连接。
针对与表达式π1,2,3,7( π 1,2,3( ) ∞( ) )。
内层表达式里面进行自然连接,对于第一空, π 1,2,3,投影1,2,3列,应该来源于题干描述的来着S学生关系的张晋, 正确表达应该是σ2=‘张晋’(S),人名字符串需要加引号。对于第二空来说,应该是选修课程号的“市场营销”的C表与选课关的SC表进行自然连接,首先排除B、D,对于A,C的区别再于两者的投影不同,A选项投影C表的2,3列即(课程名,选修课程号),而C选项投影C表的1,2列(课程号,课程名),针对与题干来看,市场营销是选修课程,所以投影选修号比较合适一点。正确表达为π2,3(σ2='市场营销’©)∞SC。
最后两层投影得到的表为A(学号,姓名,学院名,课程名,选修课程号,课程号,成绩),对于外层的投影1,2,3,7列恰好是学号,姓名,学院名,成绩
44、数据库的安全机制中,通过提供( )供第三方开发人员调用进行数据更新,从而保证数据库的关系模式不被第三方所获取。
A、触发器
B、存储过程
C、视图
D、索引
参考答案:B
答案解析:
本题考查的是数据库基础知识。
索引是数据库中提高查询效率的一种机制,不能进行数据更新。
视图一般是提供查询数据的,具有一定安全机制,但是不能进行数据更新。
触发器可以作为更新机制,但是无法避免数据库的关系模式被第三方所获取,并不安全。
存储过程方式,可以定义一段代码,从而提供给用户程序来调用,具体更新过程通过代码调用,避免了向第三方提供系统表结构的过程,体现了数据库的安全机制。所以本题选择B选项。
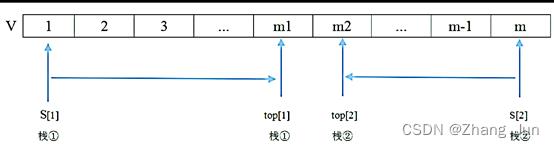
45、若栈采用顺序存储方式,现有两栈共享空间V[1…n], top[i]代表i(i=1,2)个栈的栈顶(两个栈都空时top[1]= 1、top[2]= n),栈1的底在V[1],栈2的底在V[n],则栈满(即n个元素暂存在这两个栈)的条件是( )
A、top[1]=top[2]
B、top[1]+top[2]==1
C、top[1]+top[2]==n
D、top[1]- top[2]==1
参考答案:D
答案解析:
本题考查栈的相关问题。
由题干描述可知,现有两栈共享空间V[1…n], top[i]代表i( i=1,2)个栈的栈顶(两个栈都空时top[1]= 1、top[2]= n),栈1的底在V[1],栈2的底在V[n]。
若按照顺序从底到上从V【1】到V【n】都将存入栈内,这个栈共享空间V【1…n】,可知该栈一分为二,栈1可以是开口向上,底为V【1】,栈2是开口向上,底为V【n】,要使栈满,就需要保持两个栈重合,即两个栈的开口位置相邻,有top【1】-top【2】==1,如下图所示:
46、采用循环队列的优点是( )
A、入队和出队可以在队列的同端点进行操作
B、入队和出队操作都不需要移动队列中的其他元素
C、避免出现队列满的情况
D、避免出现队列空的情况
参考答案:B
答案解析:
本题考查数据结构循环队列的问题。
1、循环队列的优点:
可以有效的利用资源。用数组实现队列时,如果不移动,随着数据的不断读写,会出现假满队列的情况。即尾数组已满但头数组还是空的;循环队列也是一种数组,只是它在逻辑上把数组的头和尾相连,形成循环队列,当数组尾满的时候,要判断数组头是否为空,不为空继续存放数据。
2、循环队列的缺点:
循环队列中,由于入队时尾指针向前追赶头指针;出队时头指针向前追赶尾指针,造成队空和队满时头尾指针均相等。因此,无法通过条件front==rear来判别队列是"空"是"满"。
3、拓展知识:
为充分利用向量空间,克服"假溢出"现象的方法是:将向量空间想象为一个首尾相接的圆环,并称这种向量为循环向量。存储在其中的队列称为循环队列。
综上所述,C,D都不属于其优点,B选项是循环队列的优点,A是对栈的描述。
47、二叉树的高度是指其层数, 空二叉树的高度为0,仅有根结点的二叉树高度为1,若某二叉树中共有1024个结点,则该二叉树的高度是整数区间( )中的任一值。
A、(10, 1024)
B、[10, 1024]
C、(11, 1024)
D、[11, 1024]
参考答案:D
答案解析:
本题考查关于二叉树的构造问题。
根据题干描述, 空二叉树的高度为0,仅有根结点的二叉树高度为1,当若某二叉树中共有1024个结点,求其取值范围?
我们不妨求出取值范围的极限值,当1024个结点都为根结点的时候,表示1024个二叉树高度为1,高度累计为1024,区间能够取到1024,属于闭区间,排除A,C
再求出其最小值的情况,最小值应该是按照满二叉树进行排列,对于二叉树的规律如下:第一层的结点树20=1,第二层21=2,第3层2^2=4,依次类推。
对于1024而言,210=1024,所以我们不能取到11层,应该先到第10层29=512,此时10层共累计的节点有:20+21+…+2^9=1023,共有1024还缺少1个结点,只能存放到第11层,第11层仅有1个结点,但是它的层次已经到了11层,所以能取到11,属于闭区间,排除B选项,故表达式取值范围应该是[11, 1024]。
48、n个关键码构成的序列k,k2, …K,当且仅当满足下列关系时称其为堆。
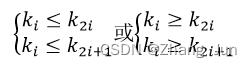
以下关键码序列中,( ) 不是堆。
A、15,25,21,53,73,65,33
B、15,25,21,33,73,65,53
C、73,65,25,21,15,53,33
D、73,65,25,33,53,15,21
参考答案:C
答案解析:
本题考查堆排序的算法问题。
堆分为大顶堆(根节点大于左孩子和右孩子节点)和小顶堆(根节点小于左孩子节点和右孩子节点)。
根据选项来看,共7个节点,应该是3层的满二叉树,符合堆的有A,B,D三个选项。
仅有C选项73,65,25,21,15,53,33,73作为根节点,根大于其左孩子节点65和右孩子节点25,是大顶堆的构造,第二层65作为左子树的根节点,大于了其左孩子节点21和右孩子节点15,符合大顶堆的构造;25作为右子树的根节点,却小于了其左孩子节点53和右孩子节点33,不符合大顶堆的构造了,故其不是堆。
49、对有向图G进行拓扑排序得到的拓扑序列中,顶点Vi在顶点Vj之前,则说明G中( )
A、一定存在有向弧 < Vi,Vj >
B、一定不存在有向弧< Vj,Vi >
C、必定存在从Vi到Vj的路径
D、必定存在从Vj到Vi的路径
参考答案:C
答案解析:
本题考查拓扑序列的相关问题。
对于拓扑序列,需要按照有向弧的指向,明确其先后顺序,例如:存在一条Vi指向Vj的有向弧,那么在拓扑序列中Vi需要写在Vj前面,其次对于属于同一层次或者毫无关联的两个结点可以不用在意先后顺序。
根据题干描述,对有向图G进行拓扑排序得到的拓扑序列中,顶点Vi在顶点Vj之前,我们试着对以下选项进行分析:
A、 一定存在有向弧<Vi, Vj>,说法错误,不一定存在,Vi和Vj可以是并列的,并不一定要存在Vi到Vj的有向弧。
B、一定不存在有向弧<Vj, Vi>,说法正确,如果存在有向弧<Vj, Vi>,那么Vj是需要在顶点Vi之前的,则与题干相悖,所以必定不存在。
C、必定存在从Vi到Vj的路径,说法错误,不一定存在,Vi和Vj可以是两个毫无关联没有指向的关系,不会存在相关的路径。
D、必定存在从Vj到Vi的路径,说法错误,如果存在Vj到Vi的路径,Vj就会出现在Vi前面
50、归并排序算法在排序过程中,将待排序数组分为两个大小相同的子数组,分别对两个子数组采用归并排序算法进行排序,排好序的两个子数组采用时间复杂度为0(n)的过程合并为一个大数组。根据上述描述,归并排序算法采用了(1)算法设计策略。归并排序算法的最好和最坏情况下的时间复杂度为(2)。
(1)
A、分治
B、动态规划
C、贪心
D、回溯
(2)
A、O(n)和O(nlgn)
B、O(n)和O(n^2)
C、O(nlgn)和O(nlgn)
D、O(nlgn)和O(n^2)
参考答案:A、C
答案解析:
本题考查归并排序相关算法。
归并排序(Merge Sort)是建立在归并操作上的一种有效,稳定的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。归并排序是运用分治法相关策略,其时间复杂度是由外层的n循环,与内层的归并过程log2n结合起来得到O(nlgn),归并排序没有所谓的最好和最坏排序算法,都为O(nlgn)
以上是关于2021年下半年软件设计师上午真题答案及解析的主要内容,如果未能解决你的问题,请参考以下文章