Flink规则引擎实践分享
Posted oahaijgnahz
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink规则引擎实践分享相关的知识,希望对你有一定的参考价值。
Flink规则引擎实践分享
文章目录
- Flink规则引擎实践分享
一、实时规则引擎架构***
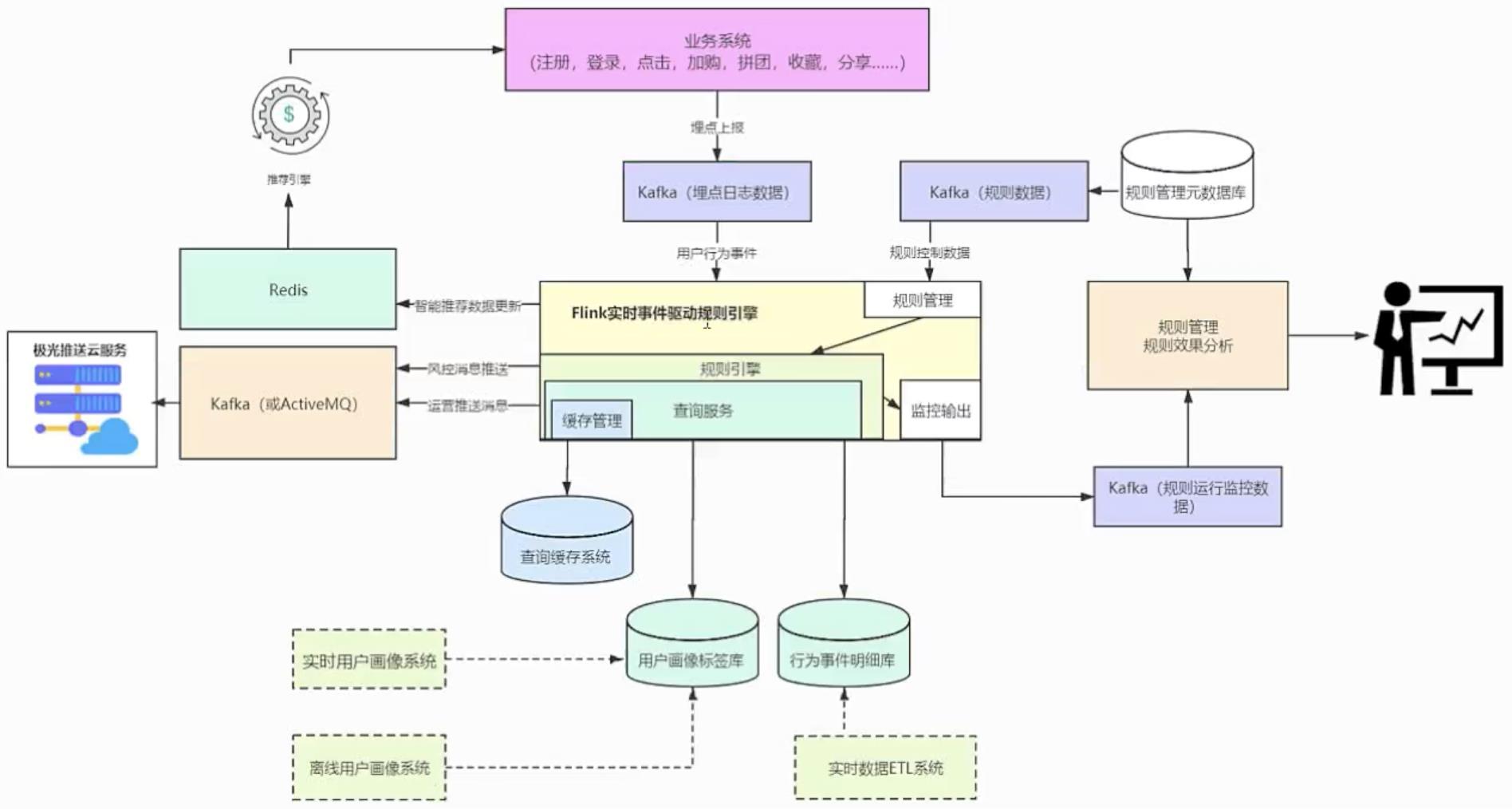
- 业务系统产生的行为日志数据被日志采集服务器收集,通过Flume将数据存入Kafka指定topic,由Flink消费Kafka对应的topic来进行用户行为事件分析【通过
FlinkKafkaComsumer传入参数(1)topic名称(2)反序列化模式DeserializationSchema(3)定义了Kafka集群地址和消费者组id的properties】。 - 通过查询路由、缓存系统的优化使得系统响应时间在毫秒级(实现的是数据磁盘离线存储与计算几乎在内存完成的方案)。在Flink解析用户行为时,用户行为满足了所制定规则中的触发条件(事件驱动),则去计算这个用户的用户属性条件(存在HBase的用户画像标签表1)、用户行为次数条件(存在ClickHouse中的行为事件明细表和State中2)和用户行为次序条件(同上)。对满足对应规则和条件的用户,将结果输出到Kafka交付。
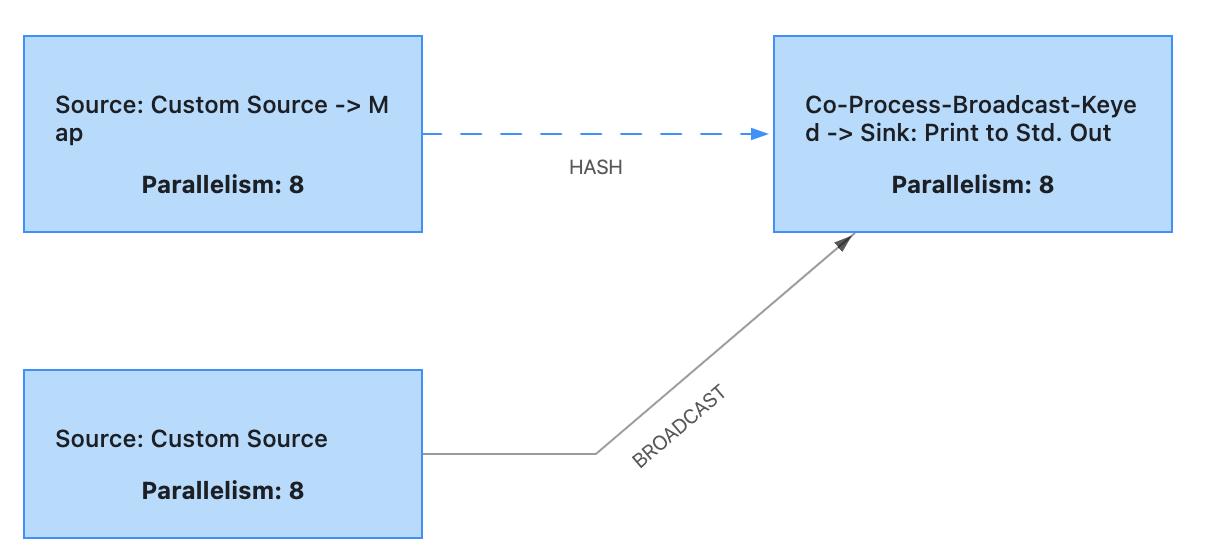
- 实现Flink中规则的动态更新。通过Canal监听存储发布规则的数据库,一旦有新的规则发布就将规则写入Kafka指定topic,Flink消费到对应topic的新的规则就作为广播流connect到事件流上。Flink物理执行图如下所示:
1用户画像为什么用Hbase存储?
答:用户数量大(每个用户对应一行),每个用户的标签众多,这样的大数据量适合用Hbase这样的分布式数据库存储,并且Hbase是列式存储,标签扩展方便。并且本系统中是按照用户id查询Hbase对应rowkey来查找具体列的等值查询,可通过布隆过滤器进行优化,并且HFile有序存储的特征可以根据索引进行列信息的快速等值查找。而mysql,首先超过百万行的查询性能就会急剧下降;其次标签扩展不方便,增加一个标签所有行数据都要更改(行式存储的劣势);最后,查询需要进行索引的建立、优化、维护等工作不如HBase来的直接了当。
2用户行为明细为什么用ClickHouse?为什么存用户行为明细?用CK有什么缺点,怎么解决?
答:首先,用户行为明细的查询数据库要符合以下条件,响应速度快、支持复杂数据查询、并发查询能力强(这点CK不擅长),综合来看CK比较符合。其次,为存储用户行为明细是因为规则是动态的无法事先确定会有怎么样的规则发布,那么当新的规则出现时,行为查询的粒度将会发生不可预知的改变,这种场景就需要OLAP的即席查询来支持临时聚合和复杂分析。最后,CK的缺点在于并发能力不高,在Flink高并行度的数据处理场景下会导致CK性能骤降,解决方案为实际行为明细查询存在冗余查询,可以使用本地查询缓存机制来减少冗余查询,从而减少对CK查询的请求数。
ps:其实也可以用Hbase一站式解决,rowkey设计为用户id,日志中其他信息k-v形式存储在列族中。查询时根据rowkey查询,与需要查询的行为事件返回数据,再写逻辑进行统计次数或者次序统计。或者直接整合Phenix。但是:
1.Hbase还是定位为海量数据存储,在数据分析的上即使整合Phenix复杂查询的时间也是秒级的,并且对于复杂的计算SQL更加容易表达。
2. 从Hbase中查询根据rowkey和指定列查询很方便,但是查询后的需要将符合的数据都加载到内存中计算,进行复杂计算逻辑的编写,后期系统拓展需要给每个规则编写对应逻辑,没有SQL维护方便(并且系统将SQL生成与引擎截耦合更加利于后期系统规则扩展和维护)。
二、规则抽象模型
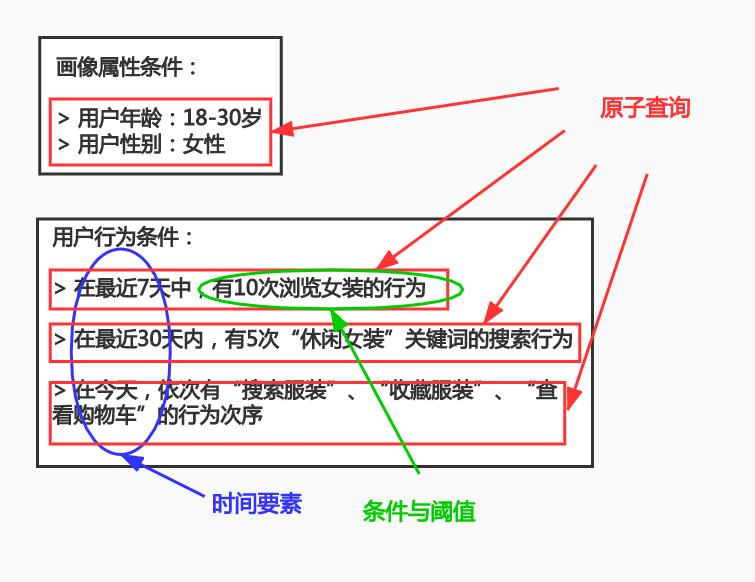
规则组成要素主要可以抽象成以下四个部分:
- 事实:被判断的主体和属性,如账号某项行为发生次数。
- 条件:判断的逻辑,某事实中的某属性。
- 阈值:判断的依据,某条件下属性的临界阈值。
- 时间要素:规则可由运营专家凭经验填写,也可由数据分析师根据历史数据发掘,但因为规则与现实需求的契合会随时间而变,所以无一例外都需要动态调整。
- 其他:为了方便开发的一些记录,比如规则拆分后的时间要素,规则原始的时间要素、CK的查询SQL语句、中间计算缓存等信息。
三、规则、条件查询封装**
3.1规则封装
原子规则可以被封装成包含触发事件、事件属性、阈值和事件要素的类来描述:
/**
* 规则参数中的【原子条件】封装实体
*/
@Data
@NoArgsConstructor
@AllArgsConstructor
public class RuleAtomicParam implements Serializable
private String eventId;//事件类型要求
private HashMap<String,String> properties;//事件属性要求
private int cnts;//事件阈值要求
private long rangeStart;//要求事件发生的时间段起始
private long rangeEnd;//要求事件发生的时间段结束
整体规则可以被封装成包含触发条件(一个原子规则)、画像属性条件(画像属性kv对)、用户行为属性条件(原子条件的集合)、用户行为次序条件(原子条件的集合)的类来描述:
/**
* 规则【整体条件】的封装规则
*
* * 触发条件:触发事件E
* * 画像属性条件:k3=v3,k100=v80,k230=v20
* * 行为属性条件:U(p1=v3,p2=v2)>=2 且 G(p6=v8,p4=v5,p1=v2) >= 1
* * 行为次序条件:依次做过 W(p1=v4) -> R(p2=v3)
*/
@Data
@NoArgsConstructor
@AllArgsConstructor
public class RuleParam implements Serializable
private String ruleId;//每个规则的唯一id
private RuleAtomicParam triggerParam;//触发条件,用一个原子条件描述
private HashMap<String,String> userProfileParams;//用户画像属性条件描述
private List<RuleAtomicParam> userActionCountParams;//用户行为属性条件描述,一个原子条件的集合
private List<RuleAtomicParam> userActionSequenceParams;//用户行为次序条件描述,也是原子条件的集合
3.2 查询规则封装
将各个查询条件进行封装,提供统一的接口,并根据目前的数据来源进行相应的实现(系统设计要考虑将来的需求:比如以后的用户画像不是通过Hbase查询,因此设计时要考虑解耦合;再比如,用户行为明细的查询可能来自flink状态,也可能来自CK,都需要不同的实现)。
同时这个查询规则中的方法,要尽可能考虑计算缓存。比如查询次数条件,之前的查询结果是可以缓存起来从而减少重复查询请求。查询次序条件也是如此,可以缓存用户已经进行到的最大步骤序号。因此,设计时需要考虑查询结果返回是否满足条件外,还需要为缓存系统返回此次查询的数值结果(比如在原子规则中保存次数信息,在整体规则中保存次序当前进行到的最大步骤信息)。
四、基于ClickHouse实现用户行为明细查询服务支持
问题:用状态来保存用户事件明细看似是可以的,因为这个是KeyedState,每个用户有对应的状态来保存其行为明细,每个状态不至于过大(真实场景中用户产生行为数据是集中且少量的)。但是当规则的时间条件跨度较大,则状态就会膨胀,此时只用状态这个方案就不可行了。
解决方案:
- 时间跨度短的查询,在state中完成(减轻对ClickHouse的查询请求,且近期数据ClickHouse可能还未同步)
- 时间跨度长的查询,通过ClickHouse即席查询获得。
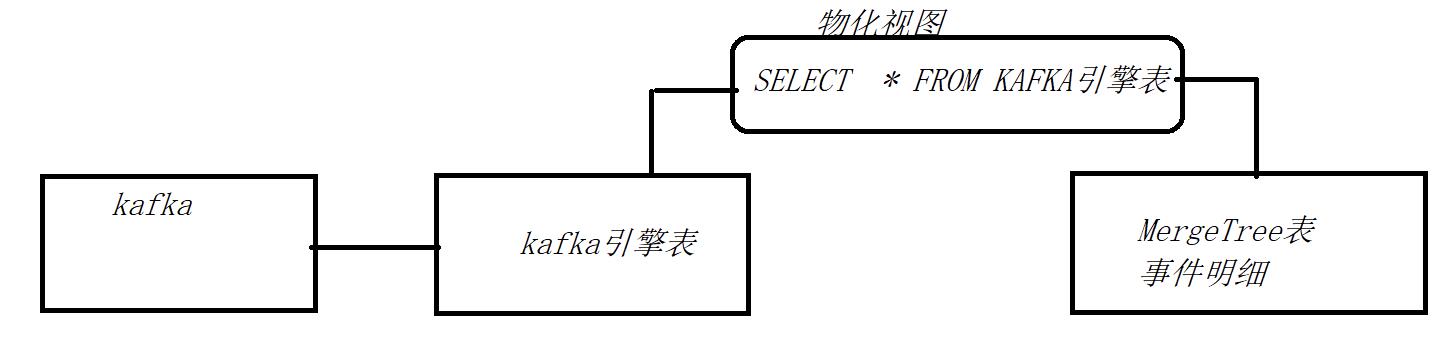
4.1 ClickHouse从Kafka摄取数据
此步骤是让ck中存有明细数据,而明细数据真正存入CK是由ETL时明细数据入库CK完成的!官方文档中集成->Kafka中有介绍
4.2 ClickHouse查询服务中的sql设计**
用于CK查询的sql语句是根据规则动态拼接生成的,那么sql查询语句应当在规则确定后就可以相应确定,而不必在Flink查询CK时再去生成。所以这里做了一个设计,在规则制定后,将对应sql查询语句封装在规则对象中(行为次数sql封装在原子条件中,行为次序sql封装在整体条件中)。ps:行为次序类sql用了CK中的sequenceMatch函数进行正则匹配序列
这样的做法好处在于:
- 解耦合了核心规则匹配模块,并减小了其在线拼接sql的运算压力。
- 便于后续sql语句的修改和优化(不必去修改核心规则匹配方法中的内容)
4.3 ClickHouse查询时间跨度问题与解决**
考虑一个问题,单纯使用一个时间分界点来区分数据近区远区查询的方案是比较粗暴的。当数据存在时间跨度是跨分界点的,在之前粗暴的想法中是直接交给CK来查询的。在这种情况下查询CK会有两个方面的问题:
- CK查询压力大
- CK数据是分批次入库的,在查询是可能还未入库
解决方案如下:

如上图所示,存粹的远期和近期查询就是通过CK和state完成。而跨分界点的查询这种情况,将规则划分为两部分,将分界点前的规则查询通过CK进行查询,而分界点后的查询通过state进行查询。
跨分界点规则拆分查询的好处在于:
- 先查询state中的规则是否符合,如果符合,就可以避免CK部分的查询(降低CK查询压力)。
- 避免近期数据查询CK未入库,这部分交给了state查询。
同时,分界点的设定也不应当是单纯时间前向退回一段时间,因为这样的做法分界点会随着时间漂移,导致缓存数据总是部分有效(产生一次短时间的远期CK查询)。所以,分界点的实际应当是对当前时间按小时向下取整后再退回设定时间,这样在一个小时内的远期数据都完全有效可以被复用的(但一小时后会有一次缓存雪崩),只需要查询近期来更新缓存即可: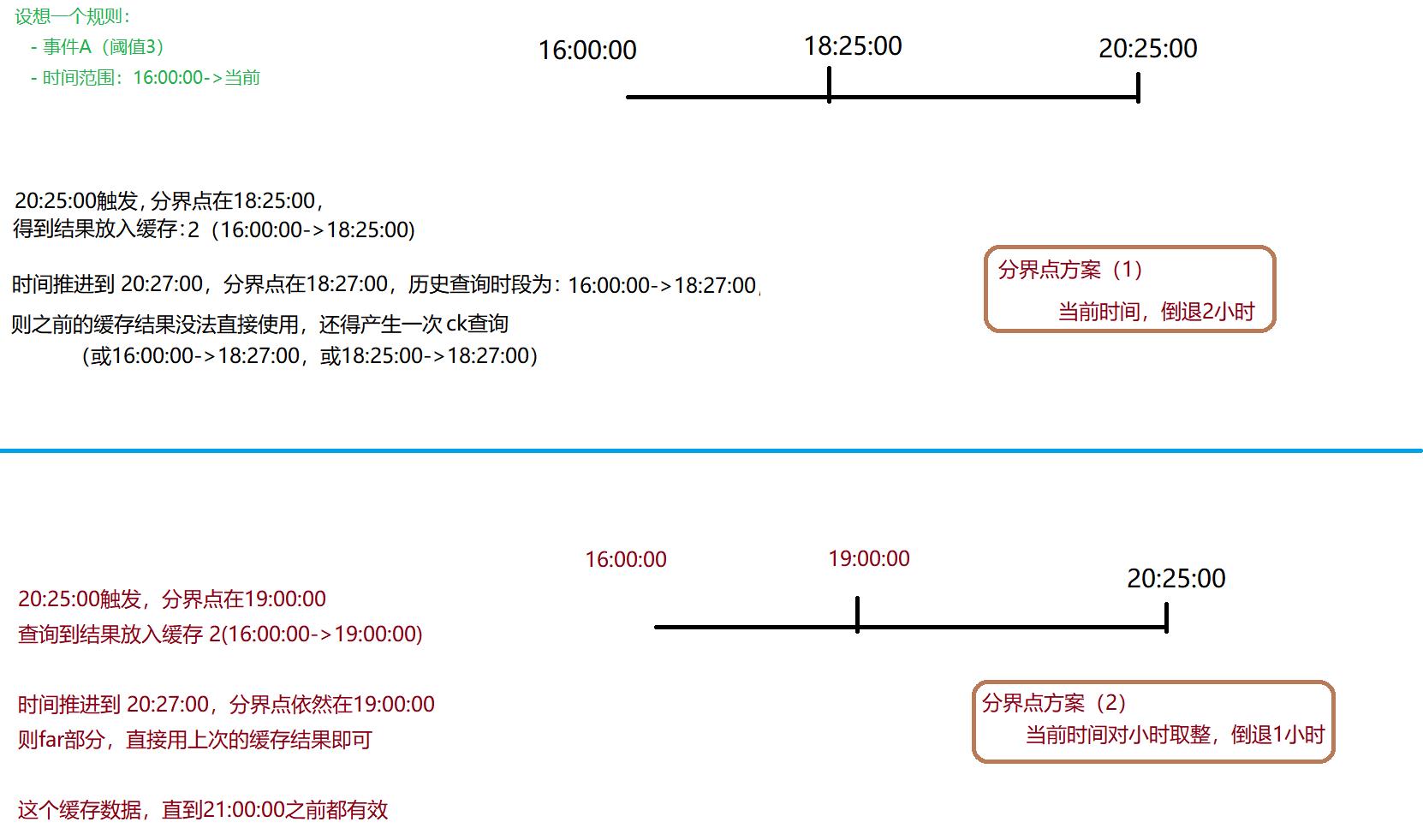
4.4 查询路由模块**
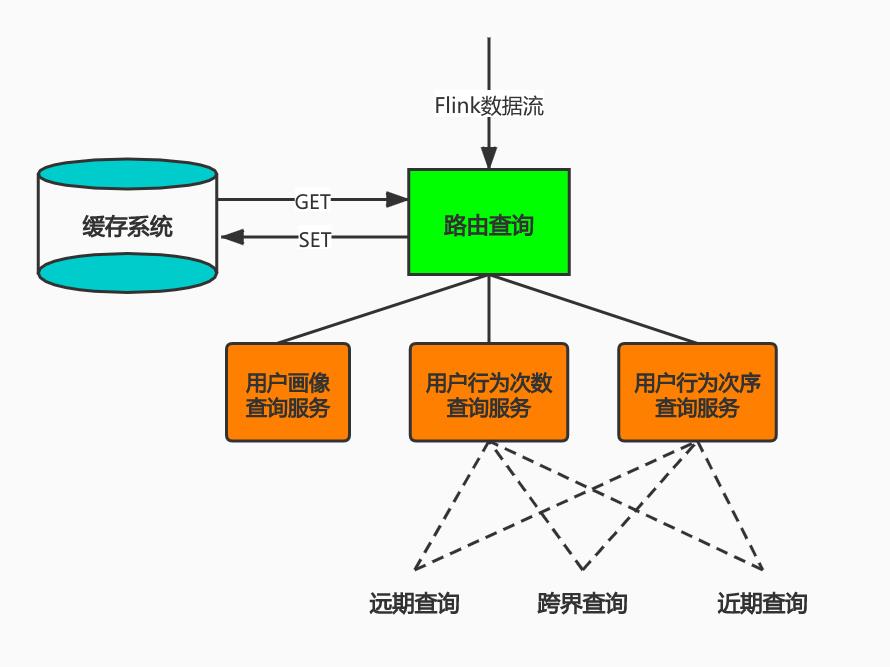
根据以上的问题的发现和解决方案的提出,现在查询服务的变得多样、并且每种查询触发的条件也变得复杂。直接在flink的processFuction中耦合查询的核心代码变得难以维护和修改,因此,封装一个查询路由模块来支持复杂多变的查询服务调用。
五、缓存模块的意义与设计
即使上面的一些设计已经有意降低对CK的查询请求,但是并不能从根本上解决查询压力大的问题。那么就需要设计一个缓存层来降低Flink对CK、Hbase和状态的查询压力(次数和并发)。
- 缓存层的意义在于,大量不同的规则中,可能存在相同或相似的原子查询条件,一旦一个原子规则被查询并保留结果,这个结果可以被多个规则公共实现重复利用。改善了以下两个维度:
- 不同规则间相同(相似)条件的查询结果复用。
- 同一个规则条件反复触发计算,复用前面已经缓存的结果。
5.1 缓存backend选择
使用Flink原生的state弊端在于每个job、subtask之间无法共享数据;系统故障重启后,缓存数据的存、续问题麻烦(checkpoint)。
使用Redis使得不同job、subtask之间使得共享;系统故障或人为重启后,数据自然存续(Redis持久化机制)。
5.2 缓存数据结构设计

将三要素整合到k、v中,key中存储对应用户、触发行为和各个事件;value中存储行为次数(或最大步骤号)和时间信息。
思考:但这样的缓存设计只是比较初步的,考虑规则间相同条件的缓存复用问题。但存在一个问题是,不同规则具有不同的时间范围但有相同的行为事件匹配序列(不相交或者部分有效),这个缓存的key对应的value会被这两个规则重复改写而导致下次匹配缓存未命中而产生CK查询。有个优化就是可以将规则id也写入缓存key中,但也有缺点是不同规则间缓存无法复用。
5.2 缓存数据有效性分析
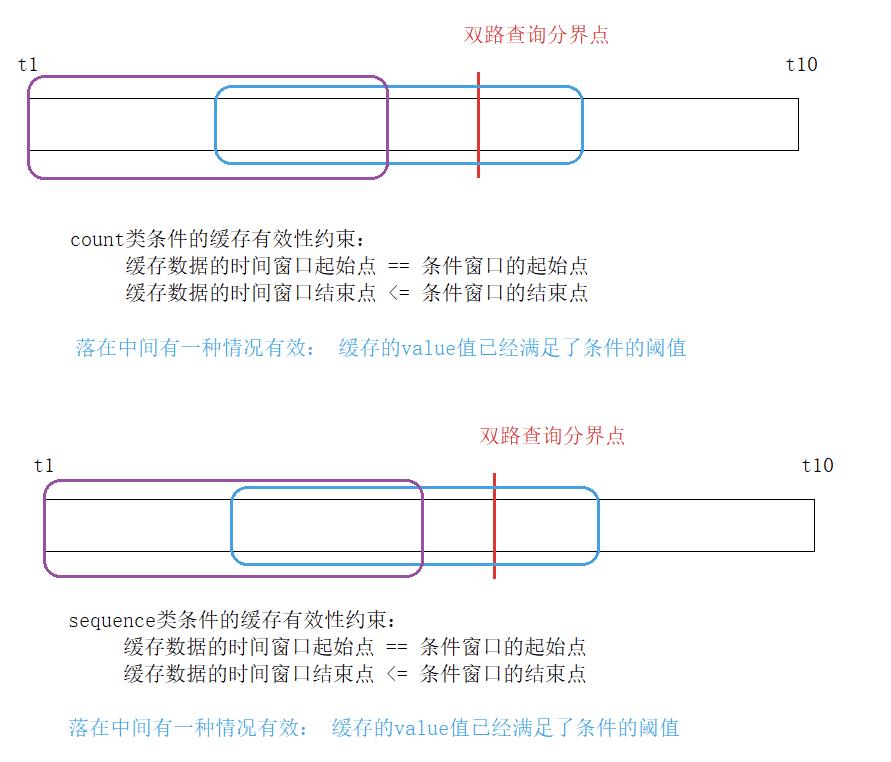
在缓存模块加入后,路由查询又增加了缓存查询的环节,这个查询是最先执行的。查询缓存后,根据缓存有效性对后续正常规则匹配造成以下影响:
1.缓存数据是全部有效的 。也就是缓存时间区间被规则完全包含,并且缓存中的值已经满足阈值要求:则行为次数类查询可以直接从原规则数组中剔除该原子规则;而行为序列类查询直接返回,不需要再继续向下进行常规查询。
2.缓存数据是部分有效的。也就是缓存时间区间的开始是和规则的开始时间对齐的(不对齐的话CK查询次数可能反而增加,不如直接认定为无效),但结束时间比规则区间短。在缓存查询后,会留下部分规则(成为新的规则)需要后续继续查询进行匹配。对于行为次数类查询,需要将规则的起始时间设置为缓存的结束时间,并将每个原子规则的缓存查询结果放入,后续查询在此基础上进行更新;对于行为次序类查询,同样要重置规则时间,并将缓存查询的最大序列查询步骤数保存,在后续查询中继续更新这个步骤数。
3.缓存数据完全无效。即缓存数据区间比规则查询区间大,则什么都不做,直接交给下面进行常规路由查询。
当然,每次常规查询后需要将查询到的数据重新写入缓存中。
5.3 加入缓存后的性能测试
测试环境为单机16G内存,4核8线程,分为三台虚拟机,HDFS、Hbase、Kafka分布在三台虚拟机上,同时二号机和三号机分别承载Redis和ClickHouse单机运行,规则为静态,40个线程每秒共产生8000条数据。在加入缓存前,在日志数据停止产生后,规则系统仍然在消费数据,说明数据产生积压(出现了反压),然而Hbase查询时间仍然较低(百万条数据平均每条查询小于10毫秒的级别),说明ClickHouse的查询压力使得数据积压产生。在加入缓存模块后,在引擎模块、Hbase预热后,Hbase查询速度仍然很快,虽然CK的查询时间需要20-30ms,但CK查询次数明显下降(埋点日志显示CK查询数量较少),同时在数据停止产生的瞬间引擎的判断也当即结束,说明数据积压问题解决了。
这是由于缓存模块的加入,CK查询的历史数据被缓存到Redis中(实现了数据存储在磁盘,稳定后计算却几乎在内存中进行),并且近期的数据是查询state并更新到缓存中的,那么最后随着系统运行,会出现的情况是缓存中保存了用户的从远期到近期的数据,而对CK的查询变得极少,实现了长时间运行后计算几乎都在内存进行的目标(新规则上线会有一段波动)。
六、动态规则改造
动态规则模块设计初衷就是将规则计算与Flink剥离,规则自己去包装运算过程路由模块的调用、CK查询sql等。Flink的process方法中只去获取广播流数据,获取到规则后,根据用户行为日志分别对规则进行匹配。这样的设计能使得规则制定更加灵活,可扩展性更强(比如后期有新的形式的规则拓展,新增的规则路由可以即时编译形成新的规则)。
6.1 Drools与选择的原因
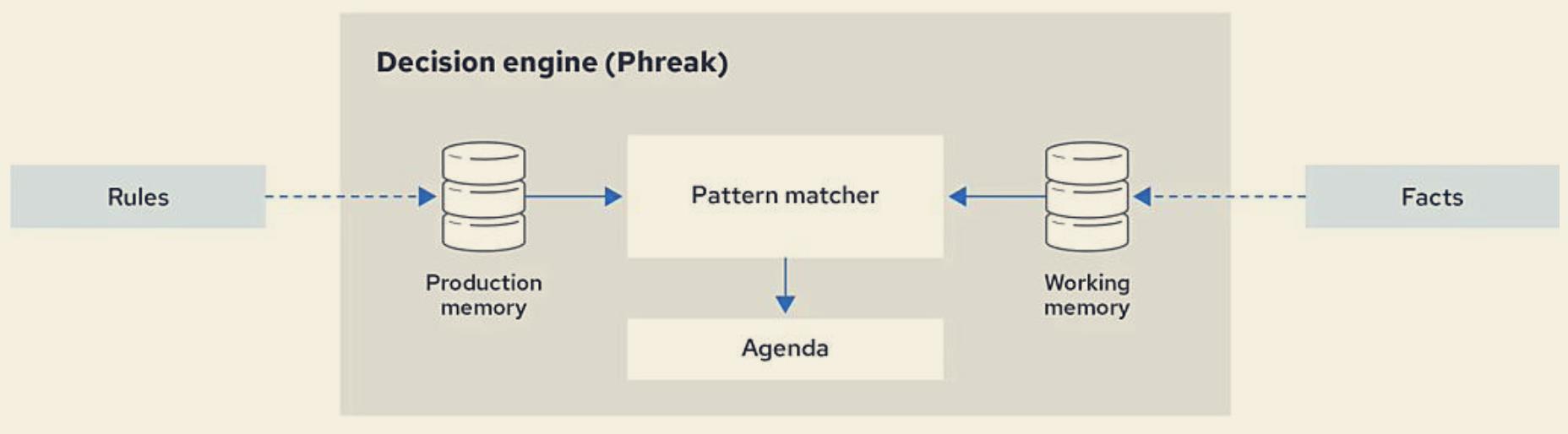 Drools的基本工作机制在于,将规则和行为都set进入引擎中各自的内存中,规则引擎会将事实和规则库进行模式匹配。Facts是我们向规则引擎传递的参数,规则匹配的结果可以通过修改Facts中的属性实现。
Drools的基本工作机制在于,将规则和行为都set进入引擎中各自的内存中,规则引擎会将事实和规则库进行模式匹配。Facts是我们向规则引擎传递的参数,规则匹配的结果可以通过修改Facts中的属性实现。
在本项目中规则的形成是通过,外部规则制定后获取到drl文件的字符串格式(Rule),由Flink获取到字符串后构建kiesession(此时kiesession中封装了整体规则和各个原子规则,但没有CK的查询sql这个问题下文解决)。构建完成的kiesession等待行为日志logbean(Fact)的到来,每来一条就就从mapstate中遍历所有规则并与行为匹配。
- 选择Drools的原因:
- 首先要清楚的是为什么用规则引擎?将规则业务逻辑与数据处理解耦合(Fact的生成与kiesession的规则封装)
- Flink原生的Flink CEP目前只能对规则进行参数化的变更,不能支持规则大变更。而Drools将复杂多变的规则从硬编码中解放出来,以规则脚本的形式存放在文件中,使得规则的变更不需要修正代码重启机器就可以立即在线上环境生效。
6.2 Flink整合Drools的项目实现
规则是在web界面等地方制定的,制定完成将存储于MySQL中。通过Canal监听MySQL中对应规则表的增删改操作,动态地将改动写入Kafka中对应的topic中。Flink会消费这个topic的,并将获得的规则变化信息通过广播state的形式广播给各个subtask,实现规则的动态感知。
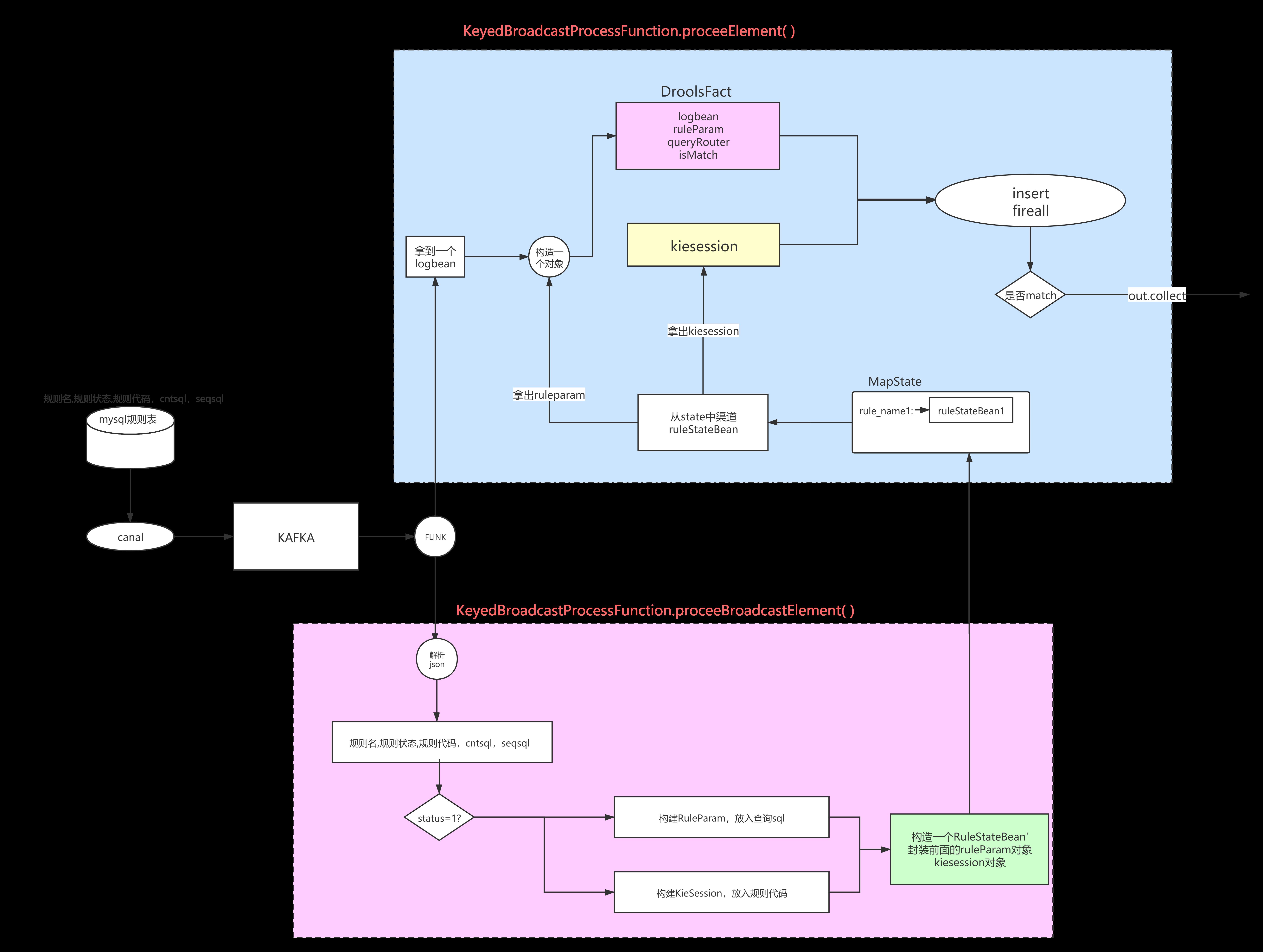
首先,在processBroadcastElement方法中,由于Canal监听MySQL发送到Kafka的数据是JSON格式,我们主要解析其中的data(数据)和type(操作类型)两个参数封装成bean对象,其中data类型封装成也是一个bean对象,字段对应的是MySQL规则表的字段(其中比较重要的是rule_name、drools规则代码rule_code、规则状态rule_status、次数类sql语句cnt_sqls、次序类sql语句seq_sqls等)。
接下来在processBroadcastElement方法中判断规则的状态rule_status来控制对广播state的增删(状态为1就插入规则,状态为0就删除规则)。在插入规则时,需要考虑一件事情,根据rule_code可以构建kiesession,但是要将cnt_sql和seq_sql在processElement方法中放入整体规则和次序类原子规则的sql语句无处安放。这时候可以再包装一层bean,JSON解析后的结果构建完对应的kiesession后将其与sql一同放入RuleStateBean中(此处与流程图中有所区别,但不妨碍大的逻辑)。这样在processElement中将RuleParam(对象目前只有次数规则序列并且里面的原子规则只有sql和最外层规则的次序类sql)、logBean、queryRouter等封装成Fact一同insert进入规则kiesession中,kiesession中的逻辑会补全RuleParam中规则除了sql外的所有字段,并调用queryRouter执行对应的查询逻辑对logBean进行匹配,各个规则全部匹配后可以通过修改Fact对象中的标记字段,主程序在后续能通过此字段得知此条行为日志是否符合规则。
ps:sql语句和drl语句在存入MySQL前的生成可以用FreeMarker来实现,但本系统只通过人工生成sql和drl语句进行测试。
七、项目中问题
7.1 集合数组删除元素问题
规则集合数组在剔除其中某些原子规则(缓存中完全可用情况)时,需要fori循环遍历集合并删除其中指定角标的元素,直接ArrayList.remove(i)会导致数组长度变小。此时i指向的是删除规则的下一个规则,这个规则就直接被跳过了。后续发现问题后,优化为ArrayList.remove(i)后将i--来纠正角标指向。
7.2 原子规则截断原始时间保存问题
规则在缓存截断、分段查询的过程中都会不断改变规则起始和结束的时间。但无论怎么截断,实际在规则更新缓存时都是需要将最原始的规则起始时间和结束时间保存下来(写缓存要哟用)。优化是直接在原子条件中保存规则原始起始时间和原始结束时间,避免在截断过程中额外保存这两个信息。
7.3 缓存存储中条件时间“目前为止”的问题***
在缓存存储时,原自规则中定义LONG.MAX_VALUE为“到目前为止”。如果不经处理直接将这个边界值存入缓存,缓存中的值中时间边界变为了最大值。这明显不符合逻辑,但最开始没有考虑到,在测试过程中,观察缓存的值时发现这个问题。后续将其修改,当时间边界为最大值时,缓存为日志中的时间戳来解决时间窗口“到目前为止”的需求。
7.4 Flink消费Kafka的一致性问题考虑***
Kafka是支持Producer的事务的,但是Consumer的事务需要Flink自己解决。Flink如何实现数据的一致性消费的?
讨论这个问题,首先要分为 Flink如何保证自身数据的一致性 和 Flink如何实现端到端的数据一致性 两个方面来讨论。
- Flink自身数据一致性的保证——状态与checkpoint:
Flink采用轻量级分布式快照实现应用容错。Flink的分布式快照实现是通过向数据流中注入隶属于不同快照的Barrier(屏障)来切分数据流,从而实现并发异步分布式快照。Barrier周期性注入数据流中,作为数据流的一部分,从上游至下游被算子处理。
Barrier(携带ID)会在数据流Source中被注入并行数据流中。对于Kafka作为数据源的情况,Barrier注入位置就是Source消费Kafka对应分区的数据的最后一个偏移量,Source算子在读取到对应Barrier后会携带当前读到的偏移量做checkpoint,由此,任务恢复时也是从保存的checkpoint中记录的偏移量再继续从Kafka读取数据。
引擎内Exactly-Once的实现:当Sink算子收到了上游算子的某个Barrier,Sink算子对自己的状态进行checkpoint,然后通知JobMaster(其中的CheckpointCoordinator),当所有并行算子都向JobMaster汇报成功后,JobMaster向所有算子确认本次快照完成。当其中某个Task出现故障,那么Flink的次作业暂停,并将各个算子的状态恢复到上一个检查点的状态,并重新从检查点保存的Kafka偏移量开始消费数据。(可以看到,虽然Kafka Consumer是没有实现事务的,但Flink可以通过自己的checkpoint机制来实现消费Kafka的事务保证)
当某个算子上游有多个数据流时,需要进行barrier对齐,做法是barrier先到达的数据流之后的数据缓存在内存中不处理,等到其他barrier到达后,将barrier向后传递并进行异步快照。
- Flink端到端数据一致性的保证(一般Flink都是用Kafka作为Source和Sink):
由于Flink内部由checkpoint机制保证了数据的一致性,Source状态的持久化能够记录读取到数据源的位置,当然这需要数据源可重设数据读取位置(Kafka、Flume的taildir Source)。而Flink的Sink需要保证事务避免数据重复写入,能够支持Flink的端到端一致性要求Sink满足支持回滚机制或者满足幂等写入(Kafka、Redis、HBase)。
真正实现Sink写入的Exactly-Once是通过Sink的两阶段提交(2PC)实现的。如前面checkpoint流程所说,当Barrier到达Sink后,Sink会做checkpoint并开启下游设备的一个事务将接下来的数据写入该事务中(预提交,根据事务的隔离性当前的数据对存储系统不可见)。然后,JobMaster收到Sink的checkpoint完成后向所有并行算子发送确认检查点完成的通知,如果收到所有算子都完成则正式提交。如果正式提交过程中,如果因为网络原因commit请求失败,那么Flink会回滚到预提交的那个checkpoint后重新进行commit请求。
实际当Kafka是数据输出的Sink,Flink保证了数据的端到端一致性,即使Flink不能保证,Kafka如果开启事务也能保证写入数据的Exactly-Once
7.5 在缓存系统未加入前Flink出现的反压问题***
在缓存系统加入前,Flink数据处理流程中同步查询CK延迟较高,且次数较多。导致下游数据处理速度慢,造成反压机制的触发,压力反向传递直至KafkaSource端,导致消费Kafka数据速率下降甚至停止消费,导致Kafka数据积压(明显的现象就是数据停止写入Kafka,系统仍然在一段时间内继续消费数据)。严重影响了系统实时性。
7.6 远近期查询分界点设定对缓存系统有效性的影响分析***
远近期查询的分界点的设定对缓存的有效性有很大的影响。
- 当分界点为
当前时间-2小时,那么这个分界点会不断随时间漂移,导致缓存总是部分有效,而持续不断产生对CK的远期查询。 - 当分界点设定为
当前时间对小时向下取整-1小时,那么分界点在一个小时内会保持不变,远期查询的缓存也会保持长时间全部有效,但是还是有问题存在,每个整点的时间会产生缓存雪崩,此时的缓存会大面积变为部分有效而瞬间加剧CK查询压力(产生周期性的波动)。
目前采用了方法二,思考是否有更好的解决方法?
个人的一些拙见——要么分界点时间粒度切分更细,也更加随机一些,或者TTL设置随机一些,这个需要后期系统运行期根据其配套的监控系统来查看缓存命中率再进行更加细致的调整。
7.7 Context的设计(设想)
项目各个模块实际有许多模块会用到相同的对象、字段等,比如常规参数、规则参数、查询结果都可以效仿Flink、MR等将常用参数封装到Context中并将这个对象发放给所有的方法,来做到更加高层的常量封装。
7.8 行为明细规则匹配查询CK并发过高的解决方案(部分解决)
CK并发能力弱,首先在实际场景中应当建立分布式表来提高CK的并发访问能力(没有实际实施)。其次,应当尽量减少对CK的查询请求,比如先从缓存中查看是否已有缓存数据、短时间跨度数据从状态匹配等(已经实现)。
这也是后期如何再提高系统性能的问题,CK分布式表用集群来提高并发查询的能力,Flink算子并行度增大,让并行任务分散到更多的机器中计算(比如按key分组的算子每个任务负责的id更少,减轻单台机器checkpoint压力)。再问答到除了集群扩展层面的优化提升系统性能,则可以说后续建立该系统的监控系统,来监控系统各类查询的时间、次数,缓存命中率、Flink任务的执行信息等,再从中发现系统薄弱的环节进行优化,目前本人经验不足以想到性能级的优化方法,期待在工作以后能够发现系统优化的更多方法。
7.9 查询规则形态的扩展(设想)***
后期系统设计还可以通过扩展规则组来动态加入新的查询路由和查询服务,通过java动态加载机制实现。在构建Fact之前,通过数据库获取的规则得到对应的查询路由类的全限定名,然后Class c = Class.forName(全限定名)后QueryRouter queryRouter = (QueryRouter) c.newInstance()得到对应的对象。
并且后期查询路由模块的设计可以采用责任链设计模式来进行设计,定义一系列规则查询的Handler,将行为数据与规则的匹配向下传递。这样的设计能够通过扩展查询路由模块的责任链与其Handler来达到适配所有规则匹配请求的效果。
以上是关于Flink规则引擎实践分享的主要内容,如果未能解决你的问题,请参考以下文章