[ParseNet]ParseNet: Looking Wider to See Better
Posted 明天去哪
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[ParseNet]ParseNet: Looking Wider to See Better相关的知识,希望对你有一定的参考价值。
Abstract
北卡罗纳大学教堂山分校的文章, ICLR 2016. 本文的 Movitation 是看到FCN并没有结合全局信息,所以没有利用潜在的scene-level的语义上下文特征,所以提出一种结合average feature的网络结构来提高分割性能,最终在SiftFlow和PASCAL-Context上达到了SOTA, 在PASCAL VOC 2012上接近SOTA(Deeplab + CRF).
Framework
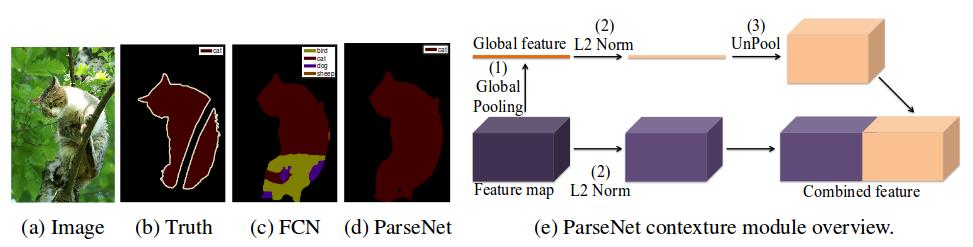
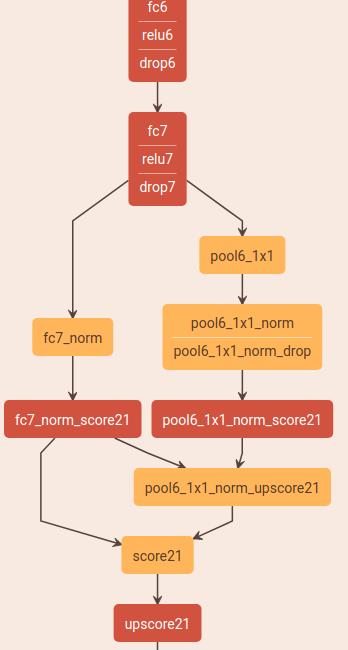
Global context
作者用一个滑动的噪声去干扰输入图像,观察网络的输出,用来探测一个网络的有效感受野具体有多大.这是个不错的想法,因为论文大都是以核等参数反推出感受野,但是真正有效的感受野到底有多大呢?作者实验发现,理论上VGG的fc7应该有 404×404的感受野,但是实际上只有图像的 1/4.作者发现,使用一个Gobal Pooling可以显著特高感受野,也可以提升分割效果.early fusion and late fusion
题也挺有趣的,特征有两种融合方式,一个是早期融合,然后放入分类器一起分类,另一种就是晚期融合,就是分类后再融合.如果没有额外的处理,则两种方式是一样的.一般来说,早期融合可以很好利用更多特征,这个是晚期融合做不到的.但是作者发现,如果加入了L2正则,那么他们是相似的.但是做特征融合的时候一定要注意的是不同层的数据scale是不一样的,所以需要正则化才能融合.而且需要注意的是不同层的数据尺寸也不同啊,所以也不能够直接融合.所以,作者使用了 L2 norm.L2 normalization layer
尽管可以通过直接融合不同层,然后进行学习以改善不同scale的问题,但是这种方法仍然太过生硬,而且对于fine-tuning来说很难做好.所以作者提出使用 L2 norm,然后在对正则化后的数据进行scale到一个比较大的数据.
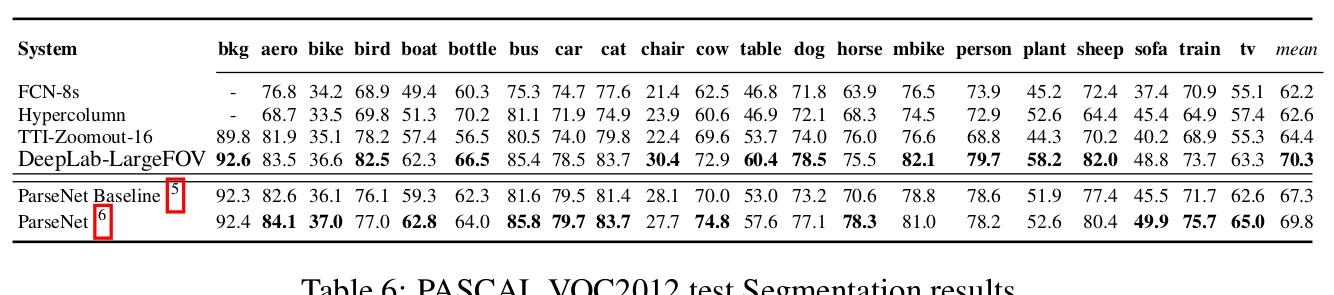
Result
这一部分实验在SiftFlow和PASCAL-Context上只和FCN进行了对比,感觉实验不是特别充分.
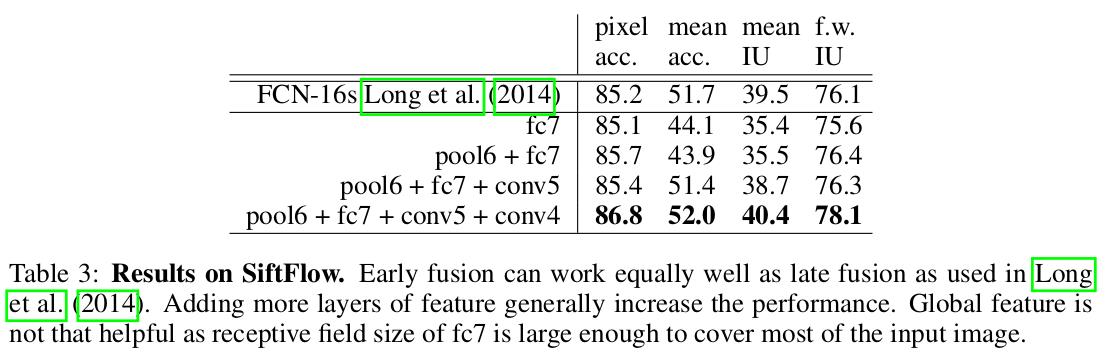
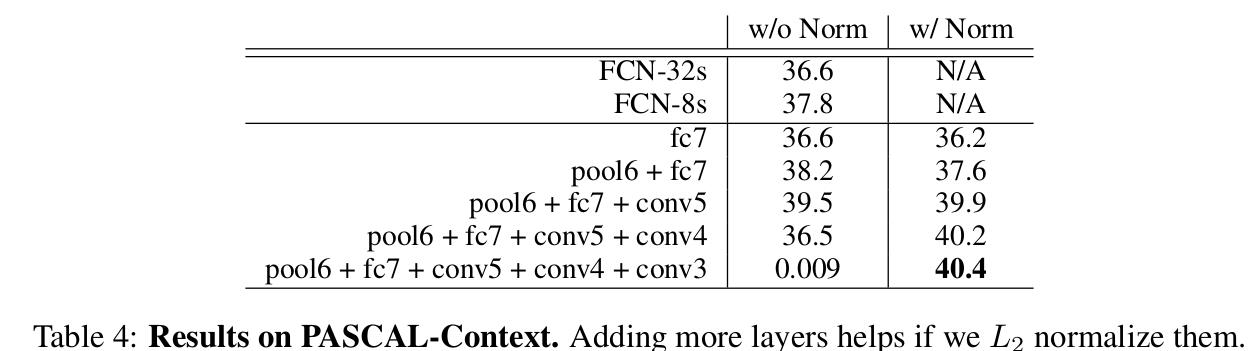
Thinking
总的来说,本文思想很简单,在后来的许多文章中也都是用global context的思想(pspnet , deeplab v3等),感慨在2015年发深度学习的文章好容易中…
Others
- Code: https://github.com/weiliu89/caffe/tree/fcn
- 后续会对代码进行分析
以上是关于[ParseNet]ParseNet: Looking Wider to See Better的主要内容,如果未能解决你的问题,请参考以下文章