8.FLINK Transformation基本操作合并和连接拆分和选择rebalance重平衡分区其他分区操作API
Posted 涂作权的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了8.FLINK Transformation基本操作合并和连接拆分和选择rebalance重平衡分区其他分区操作API相关的知识,希望对你有一定的参考价值。
8.Transformation
8.1.基本操作
8.2.合并和连接
8.3.拆分和选择
8.4.rebalance重平衡分区
8.5.其他分区操作
8.5.1.API
8.Transformation
8.1.基本操作
map/flatMap/filter/keyBy/sum/reduce...
和之前学习的Scala/Spark里面的一样的意思。
需求
对流数据中的单词进行统计,排除敏感词TMD(Theater Missile Defense 战区导弹防御)
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* TODO
*
* @author tuzuoquan
* @date 2022/4/17 22:22
*/
public class TransformationDemo01
public static void main(String[] args) throws Exception
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//TODO 1.source
DataStream<String> lines = env.socketTextStream("node1", 9999);
//TODO 2.transformation
DataStream<String> words = lines.flatMap(new FlatMapFunction<String, String>()
@Override
public void flatMap(String value, Collector<String> out) throws Exception
String[] arr = value.split(" ");
for (String word : arr)
out.collect(word);
);
DataStream<String> filted = words.filter(new FilterFunction<String>()
@Override
public boolean filter(String value) throws Exception
return !value.equals("TMD"); //如果是TMD则返回false表示过滤掉
);
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = filted.map(
new MapFunction<String, Tuple2<String, Integer>>()
@Override
public Tuple2<String, Integer> map(String value) throws Exception
return Tuple2.of(value, 1);
);
KeyedStream<Tuple2<String, Integer>, String> grouped = wordAndOne.keyBy(t -> t.f0);
//SingleOutputStreamOperator<Tuple2<String, Integer>> result = grouped.sum(1);
SingleOutputStreamOperator<Tuple2<String, Integer>> result = grouped.reduce(
new ReduceFunction<Tuple2<String, Integer>>()
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception
// Tuple2<String, Integer> value1 : 进来的(单词,历史值)
// Tuple2<String, Integer> value2 : 进来的(单词, 1)
// 需要返回(单词,数量)
return Tuple2.of(value1.f0, value1.f1 + value2.f1);
);
//TODO 3.sink
result.print();
//TODO 4.execute
env.execute();
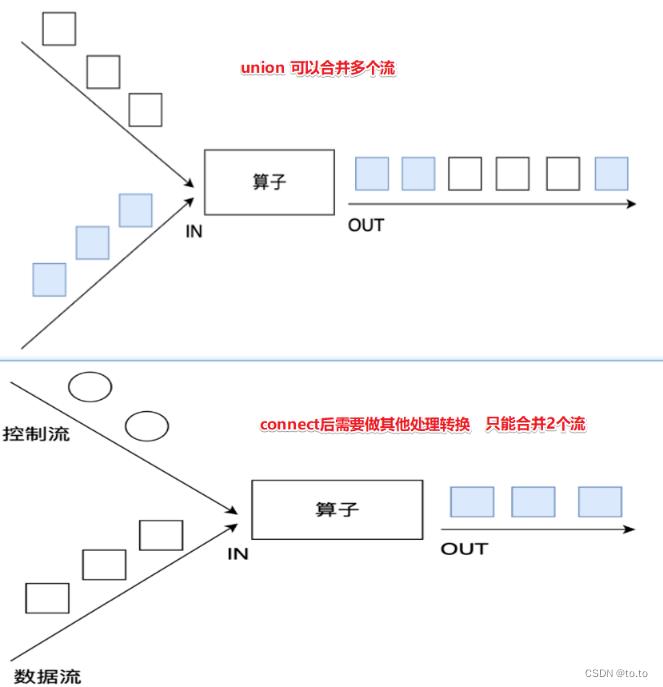
8.2.合并和连接
package demo5;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
import sun.awt.windows.WPrinterJob;
/**
* TODO
*
* @author tuzuoquan
* @date 2022/4/17 23:59
*/
public class TransformationDemo02
public static void main(String[] args) throws Exception
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//TODO 1.source
DataStream<String> ds1 = env.fromElements("hadoop", "spark", "flink");
DataStream<String> ds2 = env.fromElements("hadoop", "spark", "flink");
DataStream<Long> ds3 = env.fromElements(1L, 2L, 3L);
//TODO 2.transformation
//注意union能合并同类型
DataStream<String> result1 = ds1.union(ds2);
//ds1.union(ds3); //注意union不可以合并不同类型
//注意:connect可以合并同类型
ConnectedStreams<String,String> result2 = ds1.connect(ds2);
//注意connect可以合并不同类型
ConnectedStreams<String,Long> result3 = ds1.connect(ds3);
SingleOutputStreamOperator<String> result = result3.map(new CoMapFunction<String, Long, String>()
@Override
public String map1(String value) throws Exception
return "String:" + value;
@Override
public String map2(Long value) throws Exception
return "Long:" + value;
);
//TODO 3.sink
// System.out.println("result1.print:");
// result1.print();
// System.out.println("result2.print:");
//result2.print();//注意:connect之后需要做其他的处理,不能直接输出
//result3.print();//注意:connect之后需要做其他的处理,不能直接输出
System.out.println("result.print");
result.print();
//TODO 4.execute
env.execute();
8.3.拆分和选择
Split就是将一个流分成多个流
Select就是获取分流后对应的数据
注意:split函数已过期并移除
Side Outputs: 可以使用process方法对流中数据进行处理,并针对不同的处理结果将数据收集到不同的OutputTag中。
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
/**
* @author tuzuoquan
* @date 2022/4/18 18:38
*/
public class TransformationDemo03
public static void main(String[] args) throws Exception
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//TODO 1.source
DataStreamSource<Integer> ds = env.fromElements(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
//TODO 2.transformation
//需求:对流中的数据按照奇数和偶数拆分并选择
OutputTag<Integer> oddTag = new OutputTag<>("奇数", TypeInformation.of(Integer.class));
OutputTag<Integer> evenTag = new OutputTag<>("偶数", TypeInformation.of(Integer.class));
/*
public abstract class ProcessFunction<I, O> extends AbstractRichFunction
public abstract void processElement(I value, ProcessFunction.Context ctx, Collector<O> out) throws Exception;
*/
SingleOutputStreamOperator<Integer> result = ds.process(new ProcessFunction<Integer, Integer>()
@Override
public void processElement(Integer value, ProcessFunction<Integer, Integer>.Context ctx, Collector<Integer> out) throws Exception
//out收集完的还是放在一起的,ctx可以将数据放到不同的OutputTag
if (value % 2 == 0)
ctx.output(evenTag, value);
else
ctx.output(oddTag, value);
);
DataStream<Integer> oddResult = result.getSideOutput(oddTag);
DataStream<Integer> evenResult = result.getSideOutput(evenTag);
//TODO 3.sink
//OutputTag(Integer, 奇数)
System.out.println(oddTag);
//OutputTag(Integer, 偶数)
System.out.println(evenTag);
oddResult.print("奇数:");
evenResult.print("偶数:");
//TODO 4.execute
env.execute();
8.4.rebalance重平衡分区
解决数据倾斜的问题


package demo7;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.FileReadFunction;
/**
* TODO
*
* @author tuzuoquan
* @date 2022/4/18 19:16
*/
public class TransformationDemo04
public static void main(String[] args) throws Exception
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//TODO 1.source
DataStream<Long> longDS = env.fromSequence(0, 100);
//下面的操作相当于将数据随机分配一下,有可能出现数据倾斜
DataStream<Long> filterDS = longDS.filter(new FilterFunction<Long>()
@Override
public boolean filter(Long num) throws Exception
return num > 10;
);
//TODO 2.transformation
//没有经过rebalance有可能出现数据倾斜
SingleOutputStreamOperator<Tuple2<Integer, Integer>> result1 = filterDS
.map(new RichMapFunction<Long, Tuple2<Integer, Integer>>()
@Override
public Tuple2<Integer, Integer> map(Long value) throws Exception
//子任务id/分区编号
int subTaskId = getRuntimeContext().getIndexOfThisSubtask();
return Tuple2.of(subTaskId, 1);
//按照子任务id/分区编号分组,并统计每个子任务/分区中有几个元素
).keyBy(t -> t.f0).sum(1);
//调用了rebalance解决了数据倾斜
SingleOutputStreamOperator<Tuple2<Integer, Integer>> result2 = filterDS.rebalance()
.map(new RichMapFunction<Long, Tuple2<Integer, Integer>>()
@Override
public Tuple2<Integer, Integer> map(Long value) throws Exception
//子任务id/分区编号
int subTaskId = getRuntimeContext().getIndexOfThisSubtask();
return Tuple2.of(subTaskId, 1);
//按照子任务id/分区编号分组,并统计每个子任务/分区中有几个元素
).keyBy(t->t.f0).以上是关于8.FLINK Transformation基本操作合并和连接拆分和选择rebalance重平衡分区其他分区操作API的主要内容,如果未能解决你的问题,请参考以下文章